零代码爬虫平台SpiderFlow的安装

什么是 Spider Flow ?
Spider Flow是一个高度灵活可配置的爬虫平台,用户无需编写代码,以流程图的方式,即可实现爬虫。该工具支持多数据源、自动保存至数据库、任务监控、抓取JS动态渲染页面、插件扩展(OCR识别、邮件发送)等功能。

是不是和 n8n 有点像,不过目前 SpiderFlow 项目似乎已经停止开发了
构建镜像
如果你不想自己构建,可以跳过,直接阅读下一章节
官方提供了 Dockerfile,但没有提供镜像,想用现成的,但是不确定代码是不是最新的,所以还是自己编了一下,发现这个 Dockerfile 存在两个问题:
- 现在已经找不到
java:8镜像了;
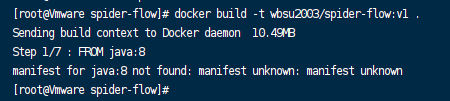
Release中并没有提供编译好的jar包,需要自己从源代码编译;
所以老苏重新改写了 Dockerfile ,选择了多阶段构建方式
# 源码构建
FROM maven:3.6.0-jdk-11-slim AS builder
COPY . ./
RUN mvn clean install# 镜像打包
FROM openjdk:8-jdk-alpine
LABEL maintainer=laosu<wbsu2003@gmail.com> RUN mkdir -p /spider-flow
WORKDIR /spider-flow
EXPOSE 8088
COPY --from=builder ./spider-flow-web/target/spider-flow.jar ./
CMD sleep 30;java -Djava.security.egd=file:/dev/./urandom -jar spider-flow.jar
源码编译的时间还是比较长的
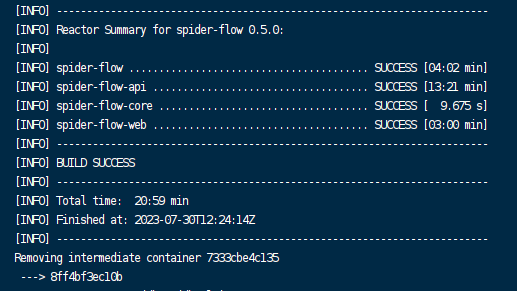
构建镜像和容器运行的基本命令如下👇
# 下载代码
git clone https://github.com/ssssssss-team/spider-flow.git# 或者加个代理
git clone https://ghproxy.com/github.com/ssssssss-team/spider-flow.git# 进入目录
cd spider-flow# 将 Dockerfile 放入当前目录# 构建镜像
docker build -t wbsu2003/spider-flow:v1 .
数据库设置
本文老苏演示了 2 种数据库安装方式:
- 一种是采用了群晖自带的
MariaDB 10,对于群晖用户来说,会节省一点点空间;

- 另一种是独立安装数据库,
docker-compose安装就采用了这种方式,更适合非群晖用户使用;
导入脚本
首先要下载 SQL 文件来完成数据库的初始化,不管采用上面方式,这一步都是必不可少的
SQL文件的下载地址:https://github.com/ssssssss-team/spider-flow/blob/master/db/spiderflow.sql

在 phpMyAdmin 中 导入 下载的 spiderflow.sql

导入成功

创建用户
接下来在 phpMyAdmin 中创建名为 spiderflow 的用户
为便于说明,假设数据库密码为
123456
往常我们会勾选 创建与用户同名的数据库并授予所有权限,但这次没有,因为数据库已经通过 spiderflow.sql 建好了
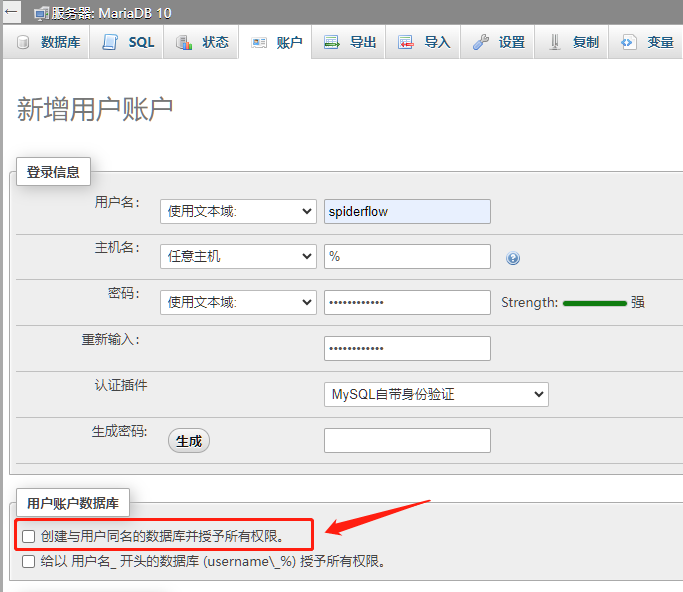
这次只是单纯的建了用户

所以我们还需要给用户操作对应的数据库的权限,找到 spiderflow 库

勾选 全选
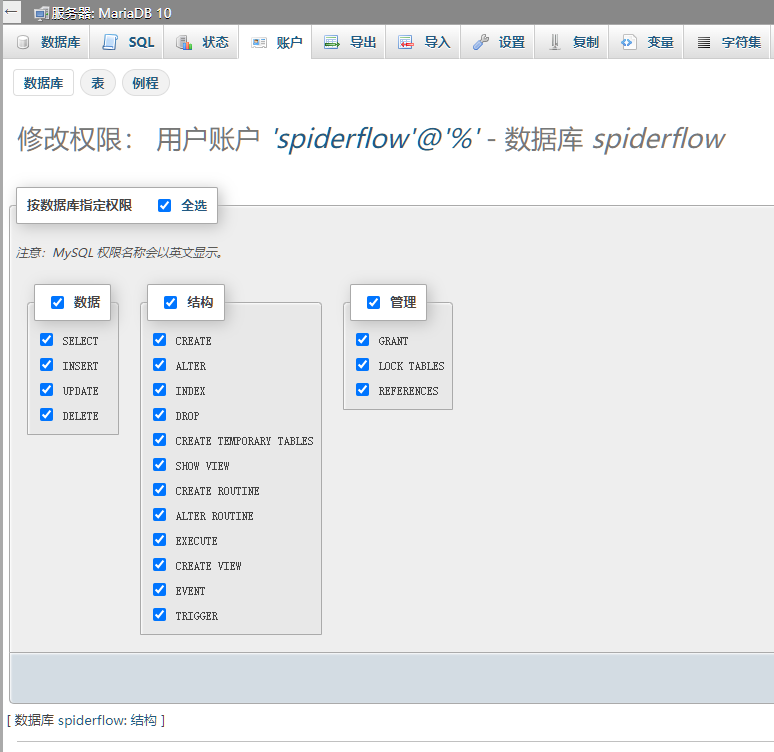
所以根据上面的设置,最后得到的数据库相关的参数如下:
- 数据库主机:
192.168.0.197,与群晖主机IP一致; - 数据库端口:
3307; - 数据库用户:
spiderflow; - 数据库密码:
123456; - 数据库库名:
spiderflow;
安装
在群晖上以 Docker 方式安装。
在注册表中搜索 spider-flow ,选择第三个 wbsu2003/spider-flow,版本选择 latest。

端口
本地端口不冲突就行,不确定的话可以用命令查一下
# 查看端口占用
netstat -tunlp | grep 端口号
| 本地端口 | 容器端口 |
|---|---|
3818 | 8088 |

环境
| 可变 | 值 |
|---|---|
SPRING_DATASOURCE_DRIVER-CLASS-NAME | 数据库类型 |
SPRING_DATASOURCE_USERNAME | 数据库用户 |
SPRING_DATASOURCE_PASSWORD | 数据库密码 |
SPRING_DATASOURCE_URL | 数据库地址 |
SPRING_DATASOURCE_DRIVER-CLASS-NAME:因为使用的是MySQL或者MariaDB,所以设为com.mysql.jdbc.Driver;SPRING_DATASOURCE_USERNAME:按前面的设置,应该为spiderflow;SPRING_DATASOURCE_PASSWORD:按前面的设置,应该为123456;SPRING_DATASOURCE_URL:是一个由多个参数拼接出来的地址,jdbc:mysql://<数据库IP>:<数据库端口>/<数据库库名>?useSSL=false&useUnicode=true&characterEncoding=UTF8&autoReconnect=true,所以这里应该是jdbc:mysql://192.168.0.197:3307/spiderflow?useSSL=false&useUnicode=true&characterEncoding=UTF8&autoReconnect=true
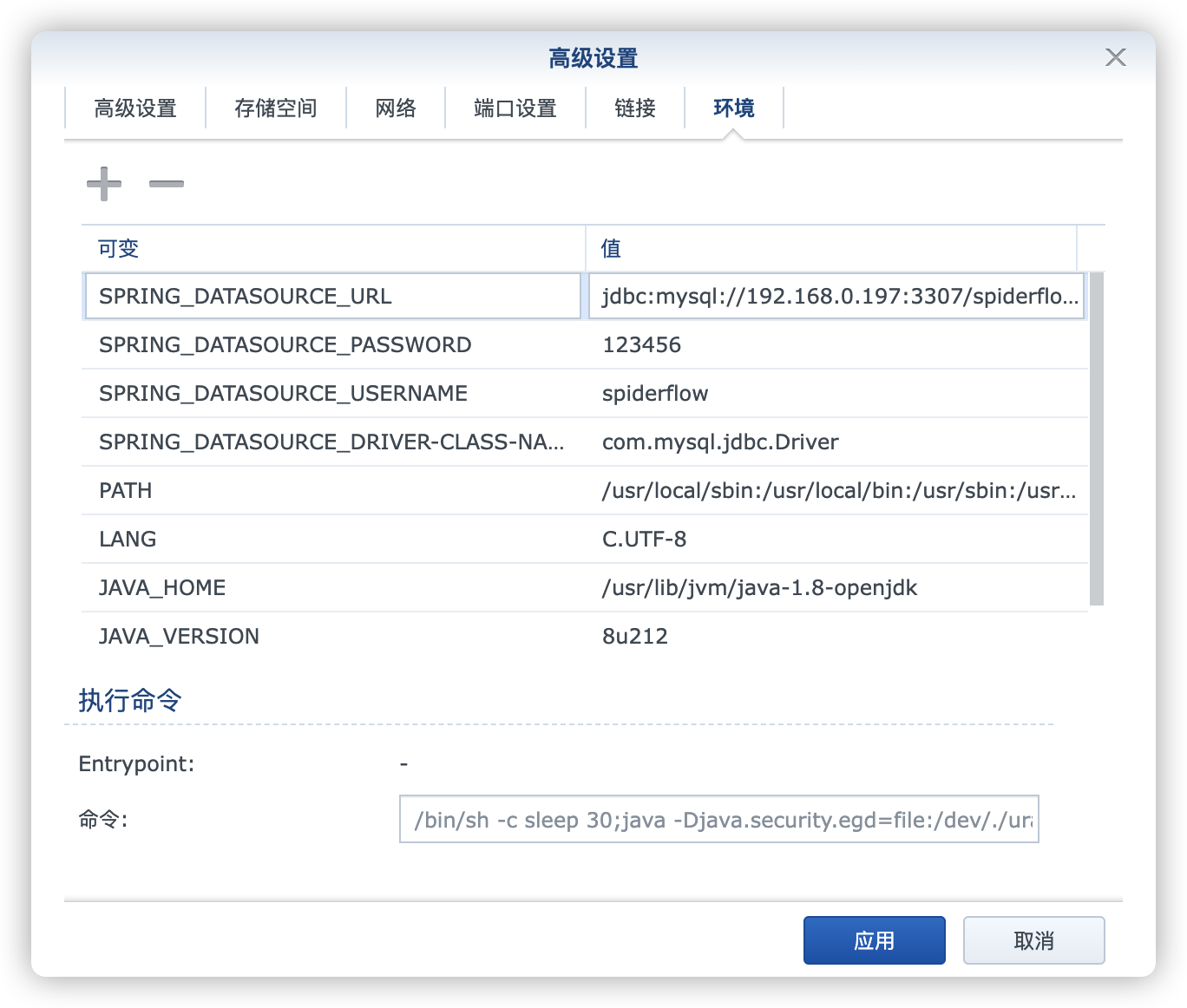
更多的环境变量可以参考 application.properties 文件:https://github.com/ssssssss-team/spider-flow/blob/master/spider-flow-web/src/main/resources/application.properties
命令行安装
docker cli 安装
如果你熟悉命令行,可能用 docker cli 更快捷
# 运行容器
docker run -d \--name spider-flow \-p 3818:8088 \-e SPRING_DATASOURCE_DRIVER-CLASS-NAME=com.mysql.jdbc.Driver \-e SPRING_DATASOURCE_USERNAME=spiderflow \-e SPRING_DATASOURCE_PASSWORD=123456 \-e SPRING_DATASOURCE_URL="jdbc:mysql://192.168.0.197:3307/spiderflow?useSSL=false&useUnicode=true&characterEncoding=UTF8&autoReconnect=true" \wbsu2003/spider-flow
docker-compose 安装
也可以用 docker-compose 安装,将下面的内容保存为 docker-compose.yml 文件
这里使用了独立的
MySQL数据库容器,而不是群晖自带的MariaDB
version: '3'services:spider-flow:image: wbsu2003/spider-flowcontainer_name: spider-flowrestart: alwaysports:- 3818:8088environment:- SPRING_DATASOURCE_DRIVER-CLASS-NAME=com.mysql.jdbc.Driver- SPRING_DATASOURCE_USERNAME=root- SPRING_DATASOURCE_PASSWORD=123456- SPRING_DATASOURCE_URL=jdbc:mysql://spider-mysql/spiderflow?useSSL=false&useUnicode=true&characterEncoding=UTF8&autoReconnect=true&allowPublicKeyRetrieval=truedepends_on:- spider-mysqlspider-mysql:image: mysql:8.0container_name: spider-mysqlrestart: alwaysvolumes:- ./data:/var/lib/mysql- ./sql:/docker-entrypoint-initdb.d:roenvironment:- MYSQL_ROOT_PASSWORD=123456- LANG=C.UTF-8- LC_ALL=C.UTF-8- TZ=Asia/Shanghai- MYSQL_INITDB_SKIP_TZINFO=truecommand: --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci
因为使用了
mysql:8.0,相比前面的SPRING_DATASOURCE_URL,这里新增了AllowPublicKeyRetrieval=True,为 允许客户端自动从服务器请求公钥,否则数据库连接会被拒绝
然后执行下面的命令
# 新建文件夹 spiderflow 和 子目录
mkdir -p /volume1/docker/spiderflow/{data,sql}# 进入 spiderflow 目录
cd /volume1/docker/spiderflow# 将 docker-compose.yml 放入当前目录
# 将 spiderflow.sql 放入 /sql 目录# 一键启动
docker-compose up -d
根目录下文件

sql 目录下文件

运行
在浏览器中输入 http://群晖IP:3818 就能看到主界面

测试可以试试第三个 抓取每日菜价
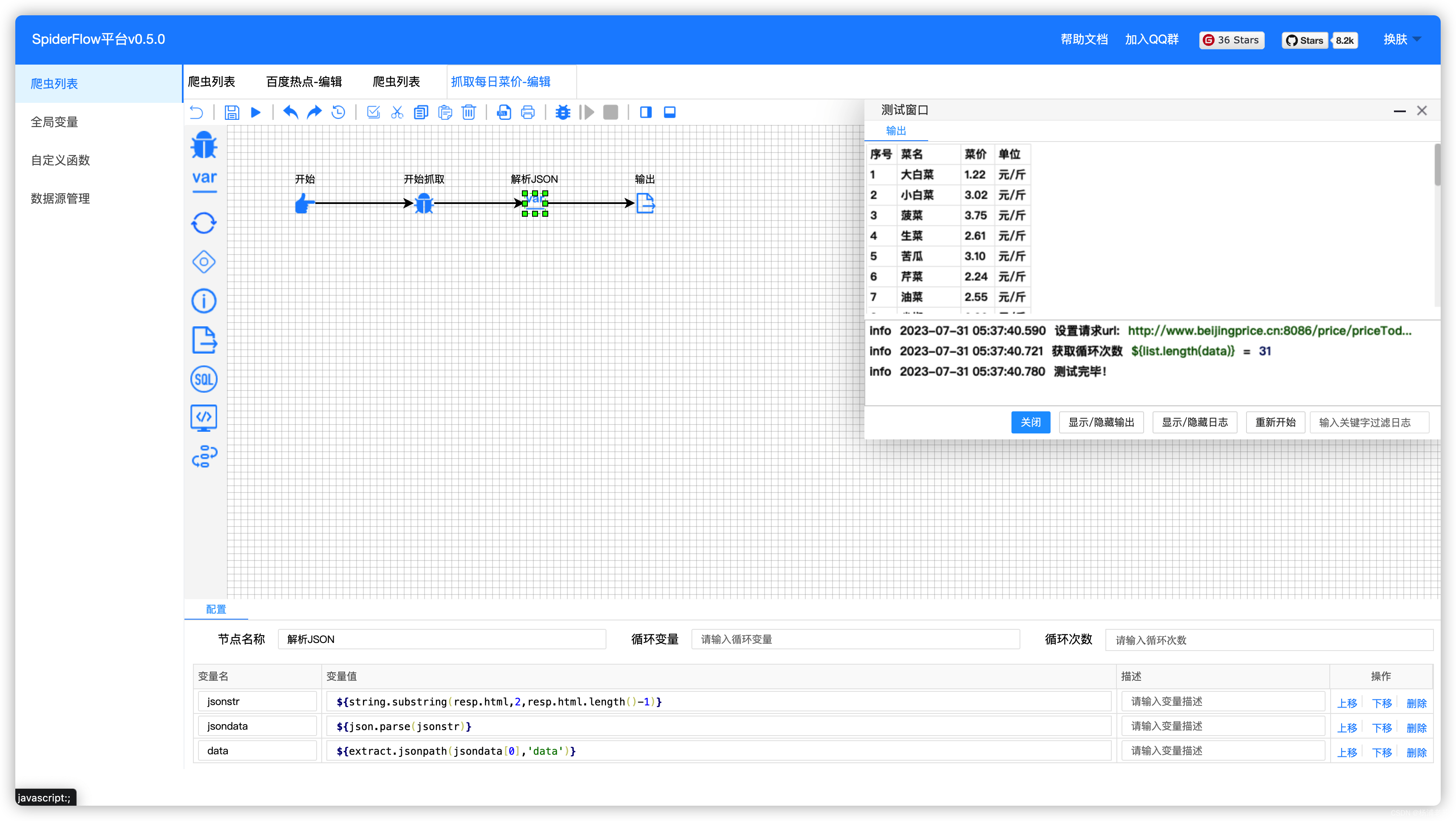
具体使用方法,网上搜搜一大把,这里就略过了
参考文档
ssssssss-team/spider-flow: 新一代爬虫平台,以图形化方式定义爬虫流程,不写代码即可完成爬虫。
地址:https://github.com/ssssssss-team/spider-flow
spider-flow: 新一代爬虫平台,以图形化方式定义爬虫流程,不写代码即可完成爬虫。
地址:https://gitee.com/ssssssss-team/spider-flow