小研究 - 基于解析树的 Java Web 灰盒模糊测试(二)
由于 Java Web 应用业务场景复杂, 且对输入数据的结构有效性要求较高, 现有的测试方法和工具在测试Java Web 时存在测试用例的有效率较低的问题. 为了解决上述问题, 本文提出了基于解析树的 Java Web 应用灰盒模糊测试方法. 首先为 Java Web 应用程序的输入数据包进行语法建模创建解析树, 区分分隔符和数据块, 并为解析树中每一个叶子结点挂接一个种子池, 隔离测试用例的单个数据块, 通过数据包拼接生成符合 Java Web 应用业务格式的输入, 从而提高测试用例的有效率; 为了保留高质量的数据块, 在测试期间根据测试程序的执行反馈信息, 为每个数据块种子单独赋予权值; 为了突破深度路径, 会在相应种子池中基于条件概率学习提取数据块种子特征. 本文实现了基于解析树的 Java Web 应用灰盒模糊测试系统 PTreeFuzz, 测试结果表明, 该系统相较于现有工具取得了更好的测试准确率.
目录
2 系统设计
2.1 基于语法解析树的 Java Web 测试方法
2.2 面向数据包拼接的种子调度权值分配算法
2 系统设计
2.1 基于语法解析树的 Java Web 测试方法
Java Web 现有的传输数据格式主要是两种: XML与 JSON, 以 JSON 格式为例, 进行具体的介绍: JSON数据的书写格式是键/值对; JSON 值可以是: 字符串、数字 (整数或浮点数)、逻辑值等; 它有两种结构, 对象和数组; 通过这两种结构可以表示各种复杂的数据. 从数据包中字段的角度来看, 包含了多个键值对, 其对应的数据类型也不尽相同, 在目标 Java Web 程序里面对这些不同的数据块大部分采用不同的处理方式, 触发不同的执行路径.
如图 2 中给出了一个程序对数据包处理的控制流图的例子. 不同类型, 不同内容的数据部分 (在图 2 中用 α, β, γ, δ 等表示) 会产生不同的执行路径 (用不同的英文字母以及不同的颜色表示), 这些执行路径也可能包含具有公共功能的共享代码块如 d、e. Java Web 程序在对报文进行处理的时候, 针对不同的数据部分给出不同的处理方式和代码逻辑, 如用户名查询、数据切片等操作. 虽然数据包的处理相互独立, 但数据块之间会相互影响, 如 d 代码块会同时处理 a 与 β, 因此即使 a 数据块具有很高的可用性和利用价值, 受 β 数据块影响可能会在后续的测试中受阻, 因此如果模糊测试器将输入报文数据部分视为一个整体, 将会影响变异数据的有效性.
根据上述分析可知, Java Web 应用程对于报文的不同数据部分, 采用的处理方式和执行路径并不相同, 通过解析树对不同类型, 不同功能的数据块设置对应的种子池, 并且通过变异组合成输入数据包, 可以更加有效地提升测试用例的整体质量, 测试到深层次的代码区域.

解析树与数据包拼接, 每一个 leaf 叶子节点为一个单独的结构体, 它挂载对应的种子池, 而种子池中存放的是该数据部分所对应的一些种子, 每一个种子都有一个记录自己相关信息的结构体, 以便后续进行种子权值计算. 其相关信息包括: 该种子的权值, 种子可以覆盖的代码块, 执行路径等. leaf 叶子节点中的节点数据块以及结构体信息通过数据包拼接算法产生测试用例, 设计的数据包拼接算法如算法 1:

生成数据包的过程中, 需要进行种子的变异. 本文针对不同数据类型的数据有不同的变异方式, 使得种子变异会更具针对性. 当有新路径产生的时候, 需要将数据块添加到对应的种子池中. 此时需要先创建一个该种子对应的结构体, 并修正其可以覆盖的代码块, 然后将它加入种子池中. 此处的种子记录下自己可以覆盖到的代码块便于后续的权值计算, 其主要的思想在于将各个数据块与程序中的代码块进行绑定, 理清数据部分与代码块之间的关系. 因此设计了种子添加算法, 如算法 2 所示:

2.2 面向数据包拼接的种子调度权值分配算法
模糊测试的种子调度权值分配是影响测试效果的关键, 代码覆盖率信息是一种被广泛应用于传统软件模糊测试的反馈信息, 并已被证实是有效的. 因此, 本文使用反馈循环来优化基于模糊测试, 并使用代码覆盖率以及执行路径作为反馈评估种子是否有价值, 通过在目标测试程序的分支点插桩来获取这一信息.
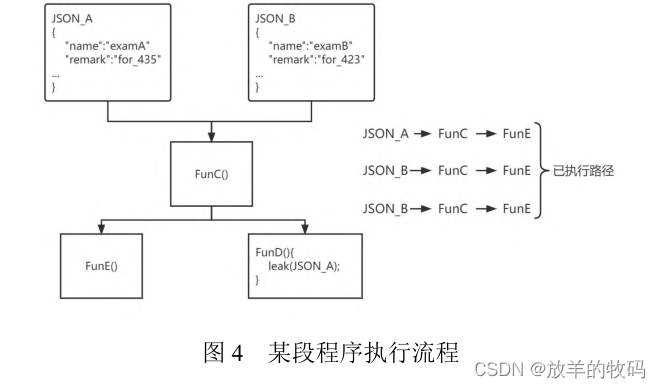
但仅考虑到代码的边缘覆盖不能满足解析树拼接实际情况. 图 4 代表了某个程序代码处理 JSON 格式数据流程, JSON_A 和 JSON_B 数据经过 FunC, 在FunD 中存在一个可能的漏洞点 leak, 且已存在执行路径: JSON_A→FunC→FunE, JSON_B→FunC→FunE,JSON_B→FunC→FunD: