自然语言处理学习笔记(二)————语料库与开源工具
目录
1.语料库
2.语料库建设
(1)规范制定
(2)人员培训
(3)人工标注
3.中文处理中的常见语料库
(1)中文分词语料库
(2)词性标注语料库
(3)命名实体识别语料库
(4)句法分析语料库
(5)文本分类语料库
4.NLP开源工具
1.语料库
语料库就是自然语音处理中的数据集。
2.语料库建设
语料库建设指的是构建一份语料库的过程,分为规范制定、人员培训与人工标注这 3个阶段。
(1)规范制定
指的是由语言学专家分析并制定一套标注规范,这份规范包括标注集定义、样例和实施方法。
在中文分词和词性标注领域比较著名的规范有
- 北京大学计算语言学研究所发布的《现代汉语语料库加工规范-——词语切分与词性标注》
- 中国国家标准化管理委员会发布的《信息处理用现代汉语词类标记规范》
(2)人员培训
指的是对标注员的培训,由于人力资源的限制,制定规范与执行规范的未必是同一批人。大型语料库往往需要多人协同标注
这些标注员对规范的理解必须达到一致,否则会导致标注员内部冲突,影响语料库的质量
(3)人工标注
针对不同类型的任务,人们开发出许多标注软件,其中比较成熟的一款是 brat ( brat rapidannotation tool ),它支持词性标注、命名实体识别和句法分析等任务,brat是典型的B/S架构,服务端用Python编写,客户端运行于浏览器,相较于其他标注软件,brat最大的亮点是多人协同标注功能,此外,拖曳式的操作体验也为brat增色不少。
3.中文处理中的常见语料库
(1)中文分词语料库
由人工正确切分后的句子集合。以著名的“ 1998年《人民日报》语料库 ”为例,该语料库由北京大学计算语言学研究所联合富士通研究开发中心有限公司,在人民日报社新闻信息中心的许可下,从 1999 年4月起到 2002 年 4 月底,共同标注完成,语料规模达到2600万汉字。
先 有 通货膨胀 干扰,后 有 通货 紧缩 叫板。
(2)词性标注语料库
它指的是切分并为每个词语指定一个词性的语料。依然以《人民日报》语料库为例,“ 1998年的《人民日报》”一共含有 43 种词性,这个集合称作“ 词性标注集 ”
迈向/v 充满/v 希望/n 的/u 新/a 世纪/n ——/w 一九九八年/t 新年/t 讲话/n
(3)命名实体识别语料库
这种语料库人工标注了文本内部制作者关心的“ 实体名词 ”以及“ 实体类别 ”。比如《人民日报》语料库中一共含有人名、地名和机构名3种命名实体。这个句子中的加粗词语分别是“ 人名 ”、“ 地名 ”和“ 机构名 ”,中括号括起来的是“ 复合词 ”我们可以观察到 :有时候机构名和地名复合起来会构成更长的机构名,这种构词法上的嵌套现象增加了命名实体识别的难度
萨哈夫/nr 说/v ,/w 伊拉克/ns 将/d 同/p [联合国/nt 销毁/v 伊拉克/ns 大规模/b 杀伤性/n 武器/n 特别/a 委员会/n] /nt 继续/v 保持/v 合作/v 。/w
(4)句法分析语料库
汉语中常用的句法分析语料库有 CTB ( Chinese Treebank,中文树库 ),这份语料库的建设工作始于1998年,历经宾夕法尼亚大学、科罗拉多大学和布兰迪斯大学的贡献,一直在发布多个改进版本。以 CTB 8.0 版为例,一共含有来自新闻、广播和互联网的3007篇文章,共计 71369 个句子、1620 561 个单词和 2589848 个字符,每个句子都经过了分词、词性标注和句法标注,其中一个句子可视化后如图1-6所示。
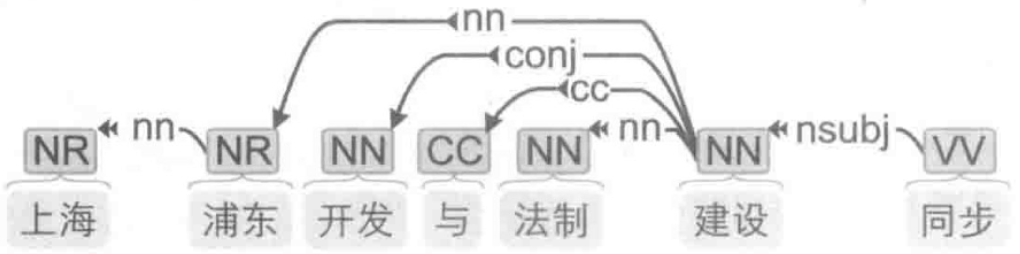
中文单词上面的英文标签表示“ 词性 ”,而箭头表示“ 有语法联系 ”的两个单词,具体是何种联系由箭头上的标签表示。
(5)文本分类语料库
它指的是人工标注了“ 所属分类 ”的文章构成的语料库。相较于上面介绍的 4 种语料库,文本分类语料库的数据量明显要大很多。
eg)以著名的搜狗文本分类语料库为例 :一共包含汽车、财经、IT、健康、体育、旅游、教育、招聘、文化、军事 10 个类别,每个类别下含有8000篇新闻。
另外,一些新闻网站上的栏目经过了编辑的手工整理,相互之间的区分度较高,也可作为文本分类语料库使用。
“ 情感分类语料库 ”则是文本分类语料库的一个子集,无非是类别限定为“ 正面 ”“ 负面 ”等而已。
notes:
如果这些语料库中的类目、规模不满足实际需求,我们还可以按需自行标注
标注的过程实际上就是把许多文档整理后放到不同的文件夹中
4.NLP开源工具
目前开源界贡献了许多优秀的NLP工具,它们为我们提供了多种选择。下边介绍最为主流的几种。比如教学常用的NLTK ( Natural Language Toolkit )、斯坦福大学开发的CoreNLP,以及国内哈工大开发的 LTP ( Language Technology Platform )、何晗开发的HanLP ( Han Language Processing ),下面是上述工具的比较。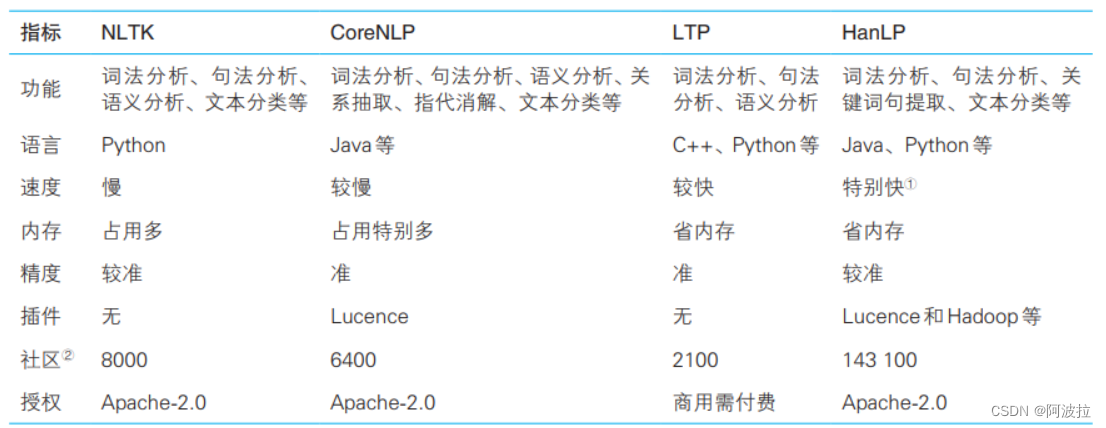
我们将使用hanlp进行学习,具体安装使用会记录在下一笔记。