【深度学习Week3】ResNet+ResNeXt
ResNet+ResNeXt
- 一、ResNet
- Ⅰ.视频学习
- Ⅱ.论文阅读
- 二、ResNeXt
- Ⅰ.视频学习
- Ⅱ.论文阅读
- 三、猫狗大战
- Lenet网络
- Resnet网络
- 四、思考题
一、ResNet
Ⅰ.视频学习
ResNet在2015年由微软实验室提出,该网络的亮点:
1.超深的网络结构(突破1000层)
简单堆叠卷积层和池化层,会导致梯度消失或梯度爆炸和退化问题;
ResNet使用深度残差学习框架来解决退化问题。
2.提出residual模块
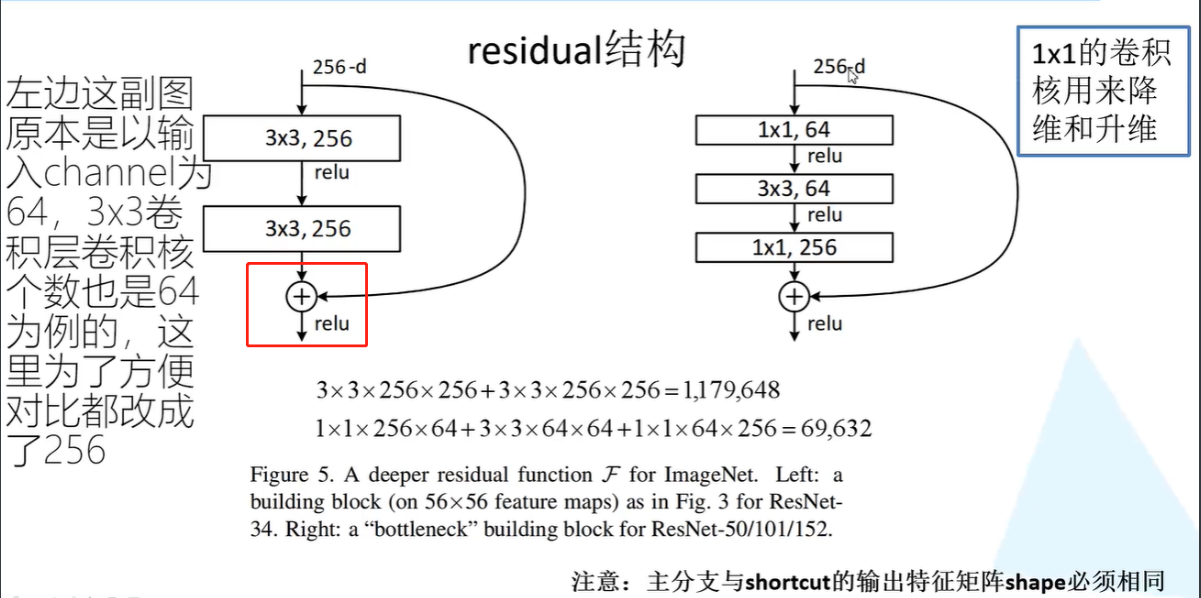
3.使用Batch Normalization加速训练(丢弃dropout)

Ⅱ.论文阅读
Deep Residual Learning for Image Recognition,CVPR2016
深度学习论文:Deep Residual Learning for Image Recognition
深度学习经典论文分析(六)
网络不是越深越好,随着网络深度的增加,精度会饱和,然后迅速退化,且这并不是由过拟合引起的。文中通过引入一个深度残差学习框架来解决退化问题。不是让网络直接拟合原先的映射,而是拟合残差映射。实际上,把残差推至0和把此映射逼近另一个非线性层相比要容易的多。
二、ResNeXt
Ⅰ.视频学习
1.更新block
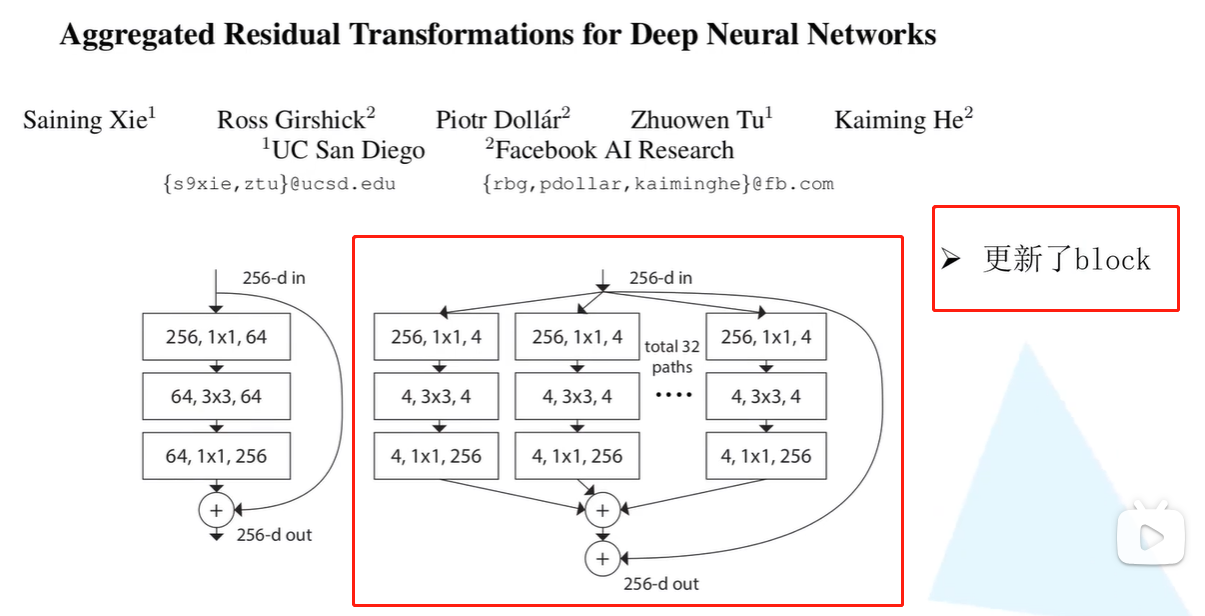
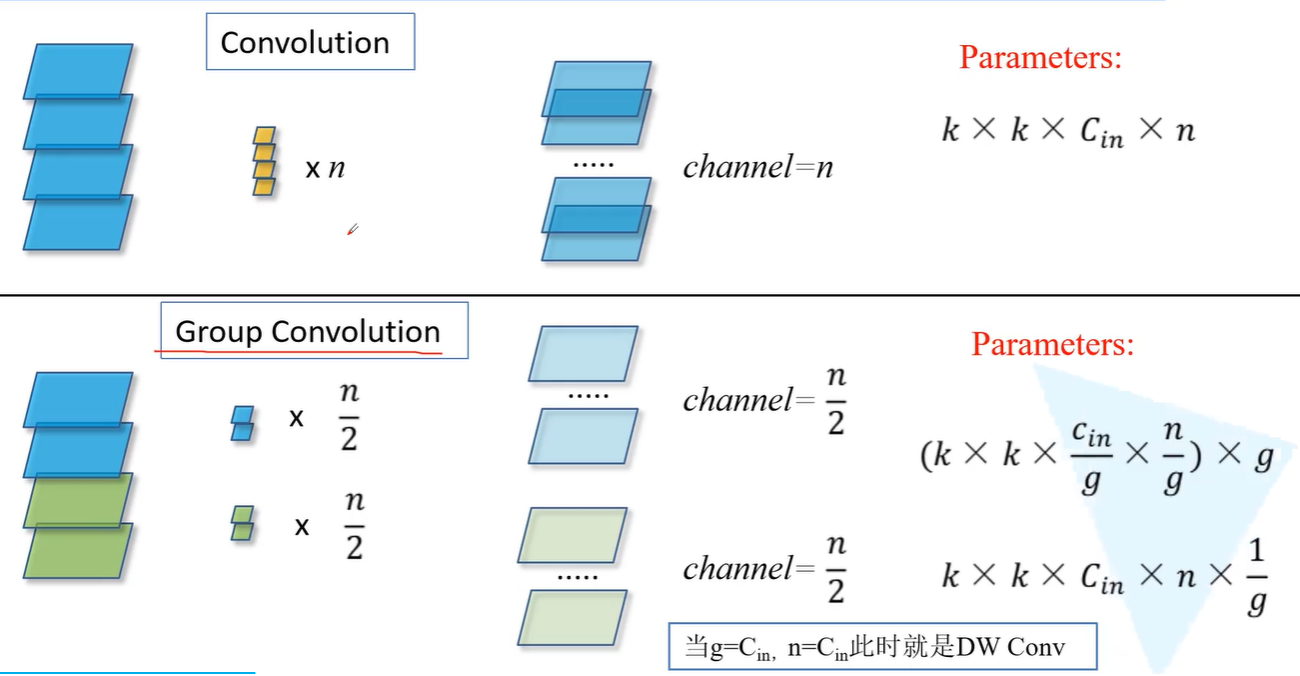
2.组卷积
Ⅱ.论文阅读
Aggregated Residual Transformations for Deep Neural Networks, CVPR 2017
Aggregated Residual Transformations for Deep Neural Networks(论文翻译)
【论文阅读】Aggregated Residual Transformations for Deep Neural Networks Saining(ResNext)
现代的网络设计中通常会次堆叠类似结构,从而减少网络中超参数的数量,简化网络设计。
Inception使用了split-transform-merge策略,即先将输入分成几部分,然后分别做不同的运算,最后再合并到一起。这样可以在保持模型表达能力的情况下降低运算代价。但是Inception的结构还是过于复杂了。
本文中提出了一个简单的架构,它采用了 VGG/ResNets 的重复层策略,同时以一种简单、可扩展的方式利用了 split-transform-merge 策略。网络中的一个模块执行一组转换,每个转换都在一个低维嵌入上,其输出通过求和聚合现——要聚合的变换都是相同的拓扑结构(例如,图 1(右))。这种设计允许我们在没有专门设计的情况下扩展到任何大量的转换。这种结构可以在保持网络的计算量和参数尺寸的情况下,提高分类精度。
三、猫狗大战
猫狗大战–经典图像分类题 - AI算法竞赛-AI研习社
使用ResNet进行猫狗大战
使用Google的Colab+pytorch
Google Colab 中运行自己的py文件
Lenet网络
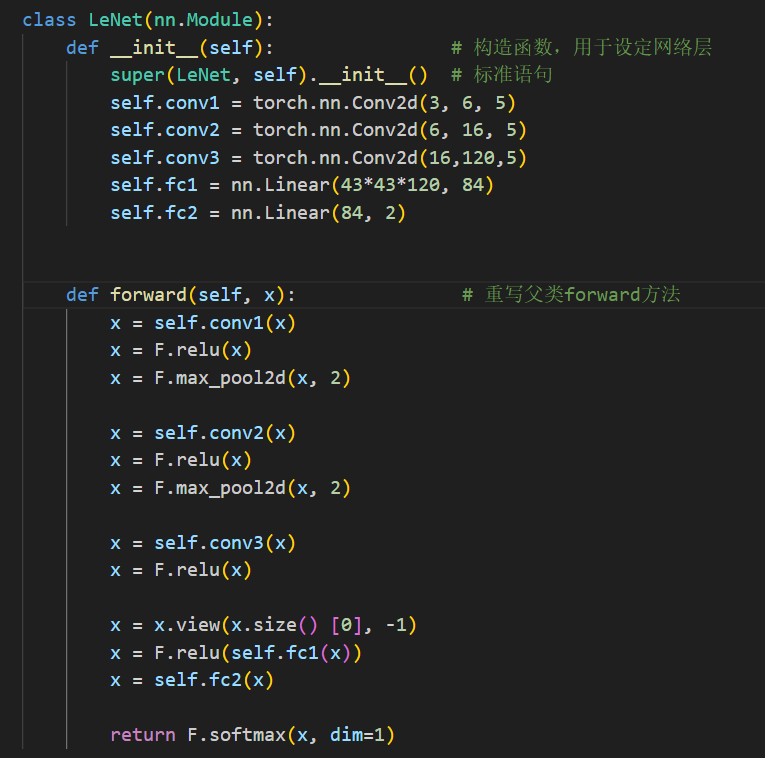
Resnet网络
四、思考题
1、Residual learning 的基本原理?
Residual learning的基本原理是通过引入残差连接,让神经网络可以学习残差,而不是直接学习映射函数。这样可以解决深层网络训练中的退化问题。
2、Batch Normailization 的原理,思考 BN、LN、IN 的主要区别。
Batch Normalization(批归一化)的原理是通过在网络的每个层输入前对其进行归一化,使得输入的均值接近于0,标准差接近于1。这有助于缓解梯度消失问题,加速训练过程,并且可以允许使用更高的学习率。
主要区别如下:
BN(Batch Normalization):对每个Batch的数据进行标准化,使其均值为0,方差为1。该方法在网络训练时对每个batch的数据都进行标准化,且归一化的均值和方差不固定,是最常用的一种批标准化方法。
LN(Layer Normalization):对每一层的数据进行标准化,使其均值为0,方差为1。LN不采用批次维度计算均值和方差,而是将整个层的数据作为一个标准化的对象。
IN(Instance Normalization):对每个样本的每个通道的数据进行标准化,使其均值为0,方差为1。IN是针对图像生成任务提出的一种标准化方法,将每个样本的所有像素点作为标准化的对象,对每个通道的数据进行归一化。
3、为什么分组卷积可以提升准确率?即然分组卷积可以提升准确率,同时还能降低计算量,分数数量尽量多不行吗?
分组卷积将输入分成多个组,每组内部进行卷积运算,可以减少卷积层参数数量。 此外,将卷积层的输入分成多个组,可以让不同组之间学习不同的特征表示,提取更多的信息。
过多的分组会导致每个子组的特征表达能力不足,不利于关键特征的提取,从而降低准确率。