尚硅谷大数据项目《在线教育之采集系统》笔记002
视频地址:尚硅谷大数据项目《在线教育之采集系统》_哔哩哔哩_bilibili
目录
P032
P033
P033
P034
P035
P036
P032
P033

# 1、定义组件,为各组件命名
a1.sources = r1
a1.channels = c1
a1.sinks - k1# 2、配置sources,描述source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/data_mocker/01-onlineEducation/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/flume-1.9.0/taildir_position.json
a1.sources.r1.batchSize = 100# 3、配置channels,描述channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = node001:9092,node002:9092,node003:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false# 4、组装,绑定source和channel以及sink和channel的关系
a1.sources.r1.channels = c1
P033
2023-07-26 11:13:42,136 (kafka-producer-network-thread | producer-1) [WARN - org.apache.kafka.clients.NetworkClient.processDisconnection(NetworkClient.java:671)] [Producer clientId=producer-1] Connection to node -1 could not be established. Broker may not be available.
2023-07-26 11:13:42,139 (kafka-producer-network-thread | producer-1) [WARN - org.apache.kafka.clients.NetworkClient.processDisconnection(NetworkClient.java:671)] [Producer clientId=producer-1] Connection to node -3 could not be established. Broker may not be available.
2023-07-26 11:13:42,241 (kafka-producer-network-thread | producer-1) [WARN - org.apache.kafka.clients.NetworkClient.processDisconnection(NetworkClient.java:671)] [Producer clientId=producer-1] Connection to node -2 could not be established. Broker may not be available.
2023-07-26 11:13:43,157 (kafka-producer-network-thread | producer-1) [WARN - org.apache.kafka.clients.NetworkClient.processDisconnection(NetworkClient.java:671)] [Producer clientId=producer-1] Connection to node -3 could not be established. Broker may not be available.
2023-07-26 11:13:43,164 (kafka-producer-network-thread | producer-1) [WARN - org.apache.kafka.clients.NetworkClient.processDisconnection(NetworkClient.java:671)] [Producer clientId=producer-1] Connection to node -2 could not be established. Broker may not be available.

[2023-07-26 11:03:06,989] INFO Opening socket connection to server node002/192.168.10.102:2181. (org.apache.zookeeper.ClientCnxn)
[2023-07-26 11:03:06,989] INFO SASL config status: Will not attempt to authenticate using SASL (unknown error) (org.apache.zookeeper.ClientCnxn)
[2023-07-26 11:03:06,992] WARN Session 0x0 for sever node002/192.168.10.102:2181, Closing socket connection. Attempting reconnect except it is a SessionExpiredException. (org.apache.zookeeper.ClientCnxn)
java.net.ConnectException: 拒绝连接
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:344)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1290)
flume生效!

node001
启动hadoop、zookeeper、kafka,再启动flume。[atguigu@node001 ~]$ cd /opt/module/flume/flume-1.9.0/
[atguigu@node001 flume-1.9.0]$ bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf
Info: Sourcing environment configuration script /opt/module/flume/flume-1.9.0/conf/flume-env.sh
Info: Including Hadoop libraries found via (/opt/module/hadoop/hadoop-3.1.3/bin/hadoop) for HDFS access
Info: Including Hive libraries found via () for Hive access
...
[atguigu@node001 ~]$ jpsall
================ node001 ================
6368 NodeManager
5793 NameNode
2819 QuorumPeerMain
6598 JobHistoryServer
5960 DataNode
6681 Application
4955 Kafka
7532 Jps
================ node002 ================
4067 NodeManager
2341 Kafka
3942 ResourceManager
4586 ConsoleConsumer
5131 Jps
1950 QuorumPeerMain
3742 DataNode
================ node003 ================
3472 NodeManager
3235 DataNode
1959 QuorumPeerMain
3355 SecondaryNameNode
2347 Kafka
3679 Jps
[atguigu@node001 ~]$ [atguigu@node002 ~]$ kafka-console-consumer.sh --bootstrap-server node001:9092 --topic topic_log[atguigu@node001 ~]$ mock.sh
[atguigu@node001 ~]$ P034
# /opt/module/flume/flume-1.9.0/job# 1、定义组件,为各组件命名
a1.sources = r1
a1.channels = c1
a1.sinks - k1# 2、配置sources,描述source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/data_mocker/01-onlineEducation/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/flume-1.9.0/taildir_position.json
a1.sources.r1.batchSize = 100a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.ETLInterceptor$Builder# 3、配置channels,描述channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = node001:9092,node002:9092,node003:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false# 4、组装,绑定source和channel以及sink和channel的关系
a1.sources.r1.channels = c1package com.atguigu.flume.interceptor;import com.atguigu.flume.interceptor.utils.JSONUtil;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;public class ETLInterceptor implements Interceptor {@Overridepublic void initialize() {}/*** 过滤掉脏数据(不完整的json)** @param event* @return*/@Overridepublic Event intercept(Event event) {//1、获取body当中的数据byte[] body = event.getBody();String log = new String(body, StandardCharsets.UTF_8);//2、判断数据是否为完整的jsonif (JSONUtil.isJSONValidate(log)) {return event;}return null;}@Overridepublic List<Event> intercept(List<Event> list) {Iterator<Event> iterator = list.iterator();while (iterator.hasNext()) {Event event = iterator.next();if (intercept(event) == null) {iterator.remove();}}return list;}@Overridepublic void close() {}public static class Builder implements Interceptor.Builder {@Overridepublic Interceptor build() {return new ETLInterceptor();}@Overridepublic void configure(Context context) {}}
}package com.atguigu.flume.interceptor.utils;import com.alibaba.fastjson.JSONObject;public class JSONUtil {public static boolean isJSONValidate(String log) {try {JSONObject.parseObject(log);return true;} catch (Exception e) {e.printStackTrace();return false;}}
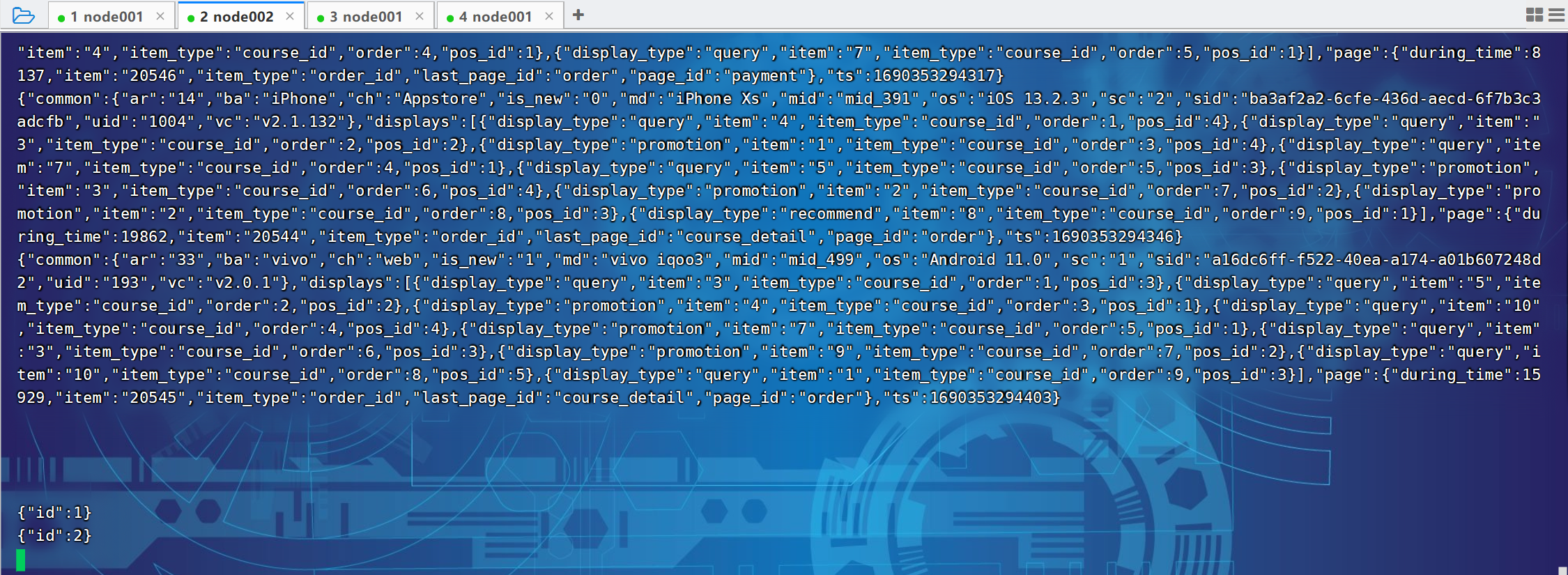
}[atguigu@node001 log]$ echo '{"id":1}' >> app.log
[atguigu@node001 log]$ echo '{"id": }' >> app.log
[atguigu@node001 log]$ echo '{"id":2}' >> app.log
[atguigu@node001 log]$ 


P035
#! /bin/bashcase $1 in
"start"){for i in hadoop102 hadoop103doecho " --------启动 $i 采集flume-------"ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/job/file-flume-kafka.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/log1.txt 2>&1 &"done
};;
"stop"){for i in hadoop102 hadoop103doecho " --------停止 $i 采集flume-------"ssh $i "ps -ef | grep file-flume-kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "done};;
esac#! /bin/bashcase $1 in
"start"){for i in node001 node002doecho " --------启动 $i 采集flume-------"ssh $i "nohup /opt/module/flume/flume-1.9.0/bin/flume-ng agent --conf-file /opt/module/flume/flume-1.9.0/job/file_to_kafka.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/flume-1.9.0/log1.txt 2>&1 &"done
};;
"stop"){for i in node001 node002doecho " --------停止 $i 采集flume-------"ssh $i "ps -ef | grep file-flume-kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "done
};;
esac#! /bin/bashcase $1 in
"start") {echo " --------采集flume启动-------"ssh node001 "nohup /opt/module/flume/flume-1.9.0/bin/flume-ng agent -n a1 -c /opt/module/flume/flume-1.9.0/conf/ -f /opt/module/flume/flume-1.9.0/job/file_to_kafka.conf >/dev /null 2>&1 &"
};;
"stop") {echo " --------采集flume关闭-------"ssh node001 "ps -ef | grep file_to_kafka | grep -v grep | awk '{print \$2}' | xargs -n1 kill -9"
};;
esacP036
## 1、定义组件
a1.sources = r1
a1.channels = c1
a1.sinks = k1## 2、配置sources
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.kafka.bootstrap.servers = node001:9092,node002:9092,node003:9092
a1.sources.r1.kafka.consumer.group.id = topic_log
a1.sources.r1.kafka.topics = topic_log
a1.sources.r1.batchSize = 1000
a1.sources.r1.batchDurationMillis = 1000
a1.sources.r1.useFlumeEventFormat = false## 3、配置channels
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/flume-1.9.0/checkpoint/behavior1
a1.channels.c1.useDualCheckpoints = false
a1.channels.c1.dataDirs = /opt/module/flume/flume-1.9.0/data/behavior1/
a1.channels.c1.capacity = 1000000
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.keep-alive = 3## 4、配置sinks
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/edu/log/edu_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log
a1.sinks.k1.hdfs.round = false## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip#a1.sinks.k1.hdfs.rollInterval = 10
#a1.sinks.k1.hdfs.rollSize = 134217728
#a1.sinks.k1.hdfs.rollCount = 0## 5、组装 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1[atguigu@node001 ~]$ cd /opt/module/flume/flume-1.9.0/
[atguigu@node001 flume-1.9.0]$ bin/flume-ng agent -n a1 -c conf/ -f job/kafka_to_hdfs_log.conf