【Hive】窗口函数(开窗函数部分)
目录
一、概念
二、窗口函数
窗口函数(1) ROW_NUMBER,RANK,DENSE_RANK,NTILE
窗口函数(2) SUM,AVG,MIN,MAX(常用)
窗口函数(3) GROUPING SETS,GROUPING__ID,CUBE,ROLLUP
一、概念
hive中的窗口函数和sql中的窗口函数相类似,都是用来做一些数据分析类的工作,一般用于OLAP分析(在线分析处理)。
我们都知道在sql中有一类函数叫做聚合函数,例如sum()、avg()、max()等等,这类函数可以将多行数据按照规则聚集为一行,一般来讲聚集后的行数是要少于聚集前的行数的.但是有时我们想要既显示聚集前的数据,又要显示聚集后的数据,这时我们便引入了窗口函数.
在深入研究Over字句之前,一定要注意:在SQL处理中,窗口函数都是最后一步执行,而且仅位于Order by字句之前。
窗口函数应用场景:
(1)用于分区排序
(2)动态Group By
(3)Top N
(4)累计计算
(5)层次查询
二、窗口函数
窗口函数(1) ROW_NUMBER,RANK,DENSE_RANK,NTILE
数据准备 ROW_NUMBER ---常用
cookie1,2018-04-10,1
cookie1,2018-04-11,5
cookie1,2018-04-12,7
cookie1,2018-04-13,3
cookie1,2018-04-14,2
cookie1,2018-04-15,4
cookie1,2018-04-16,4
cookie2,2018-04-10,2
cookie2,2018-04-11,3
cookie2,2018-04-12,5
cookie2,2018-04-13,6
cookie2,2018-04-14,3
cookie2,2018-04-15,9
cookie2,2018-04-16,7CREATE TABLE kangna_t2 (
cookieid string,
createtime string, --day
pv INT
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
stored as textfile;加载数据:
load data local inpath '/export/bigdata/kangna_t2.dat' into table kangna_t2;
select * from kangna_t2;查看所有的数据
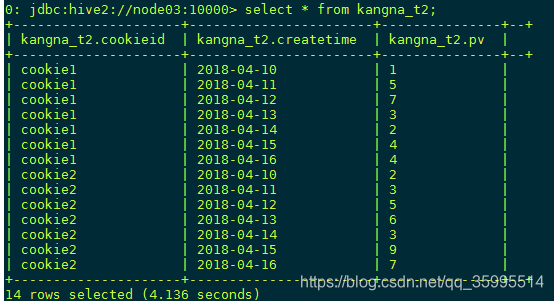
ROW_NUMBER() 从1开始,按照顺序,生成分组内记录的序列(分组内的 topN 使用场景,常用)
SELECT cookieid,createtime,pv,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn
FROM kangna_t2;查询结果
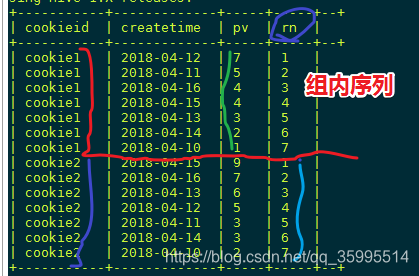
使用 row_number() 意味着 生成一个新的字段(rn),此字段对分组内 记录 打标记。
RANK 和 DENSE_RANK
RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位
DENSE_RANK() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
SELECT cookieid,createtime,pv,
RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1,
DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3
FROM kangna_t2
WHERE cookieid = 'cookie1';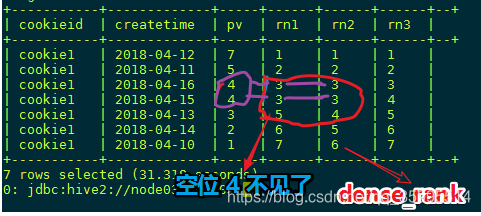
具体的使用 还要看场景了,到底我们要不要 相等排名的留下空位, 个人 感觉 dense_rank () over() 更好一点吧。看场景,学习中。
NTILE
背景:
有时会有这样的需求:如果数据排序后分为三部分,业务人员只关心其中的一部分,如何将这中间的三分之一数据拿出来呢? NTILE函数即可以满足。
ntile可以看成:把有序的数据集合平均分配到指定的数量(num)个桶中, 将桶号分配给每一行。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。
语法是:
ntile (num) over ([partition_clause] order_by_clause) as xxx然后可以根据桶号,选取前或后 n分之几的数据。数据会完整展示出来,只是给相应的数据打标签;具体要取几分之几的数据,需要再嵌套一层根据标签取出。NTILE不支持ROWS BETWEEN,比如 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)
比如,统计一个cookie,pv数最多的前1/3的天,其中rn2= 1 的记录,就是我们想要的结果,如下:
SELECT cookieid,createtime,pv,NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn1,NTILE(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn2,NTILE(4) OVER(ORDER BY createtime) AS rn3FROM kangna_t2 ORDER BY cookieid,createtime;
如果想要 排序后的 几分之几 ,只需要在 where 中过滤 即可
窗口函数(2) SUM,AVG,MIN,MAX(常用)
数据准备
cookie1,2018-04-10,1
cookie1,2018-04-11,5
cookie1,2018-04-12,7
cookie1,2018-04-13,3
cookie1,2018-04-14,2
cookie1,2018-04-15,4
cookie1,2018-04-16,4
cookie2,2018-04-10,2
cookie2,2018-04-11,3
cookie2,2018-04-12,5
cookie2,2018-04-13,6
cookie2,2018-04-14,3
cookie2,2018-04-15,9
cookie2,2018-04-16,7
SET hive.exec.mode.local.auto=true;create table kangna_t1(
cookieid string,
createtime string, --day
pv int
) row format delimited
fields terminated by ',';load data local inpath '/export/bigdata/kangna_t1.dat' into table kangna_t1;
select * from kangna_t1;SUM(结果和ORDER BY相关,默认为升序) -----比如统计每个用户月的累积访问量
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime) as pv1
from kangna_t1;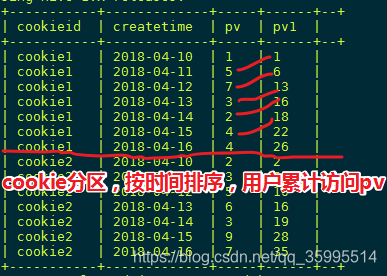
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and current row) as pv2
from kangna_t1;- 上面2条SQL的效果是一样的,累加函数默认是从将当前和前面所有行的某个字段值累加在一起:
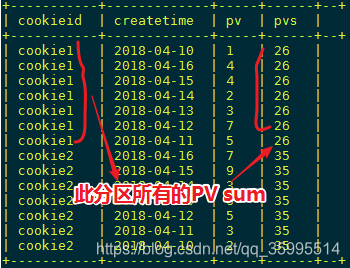
select cookieid,createtime,pv,
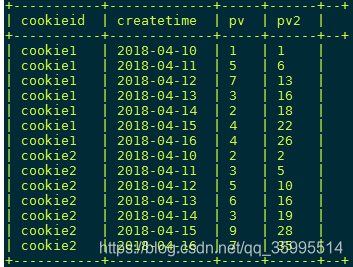
sum(pv) over(partition by cookieid) as pv3
from kangna_t1;- 如果没有order by排序语句 默认把分组内的所有数据进行sum操作
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and current row) as pv4
from kangna_t1;- rows between 用来指定累加的范围,上面的语句是当前行和前面3行的总和(4行)索引的 0 1 2 3
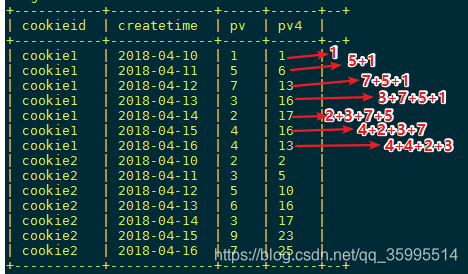
关于指定累加范围 的,不管是是指定当前 行的 前多少个还是后多少个 相加道理都是一样的,跟上图的道理一样,认准当前行相加就可以了。
下面我们再看几个
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5
from kangna_t1;select cookieid,createtime,pv, // 当前到后边所有 从第一条 记录开始算
sum(pv) over(partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from kangna_t1;此处就 不 贴图了,占地方,呵呵,小结一下
- 如果不指定rows between,默认为从起点到当前行; 一般也不指定看场景
- 如果不指定order by,则将分组内所有值累加;、
- 关键是理解rows between含义,也叫做window子句(单词意思喽)
preceding: 往前 , following: 往后 , current row: 当前行 , unbounded: 起点 , unbounded preceding: 表示从前面的起点, unbounded following: 表示 到后面的起点
AVG,MIN,MAX,和SUM用法一样
select cookieid,createtime,pv,
avg(pv) over(partition by cookieid order by createtime rows between unbounded preceding and current row) as pv2
from kangna_t1;
// 也就是
select cookieid, createtime, pv,
avg(pv) over(partition by cookieid order by createtime) from kangna_t1;select cookieid,createtime,pv,
max(pv) over(partition by cookieid order by createtime) as pv2
from kangna_t1;select cookieid,createtime,pv,
min(pv) over(partition by cookieid order by createtime) as pv2
from kangna_t1;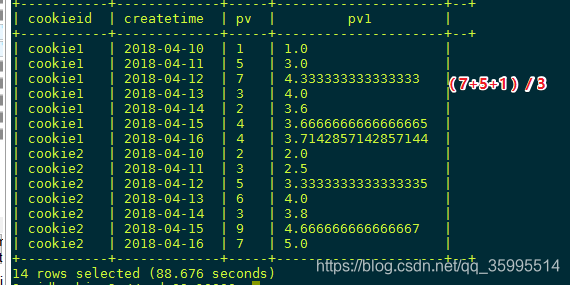
窗口函数(3) GROUPING SETS,GROUPING__ID,CUBE,ROLLUP
数据准备
2018-03,2018-03-10,cookie1
2018-03,2018-03-10,cookie5
2018-03,2018-03-12,cookie7
2018-04,2018-04-12,cookie3
2018-04,2018-04-13,cookie2
2018-04,2018-04-13,cookie4
2018-04,2018-04-16,cookie4
2018-03,2018-03-10,cookie2
2018-03,2018-03-10,cookie3
2018-04,2018-04-12,cookie5
2018-04,2018-04-13,cookie6
2018-04,2018-04-15,cookie3
2018-04,2018-04-15,cookie2
2018-04,2018-04-16,cookie1CREATE TABLE kangna_t5 (
month STRING,
day STRING,
cookieid STRING
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
stored as textfile;load data local inpath '/export/bigdata/kangna_t5.dat' into table kangna_t5;GROUPING SETS
grouping sets是一种将多个group by 逻辑写在一个sql语句中的便利写法。等价于将不同维度的GROUP BY结果集进行UNION ALL。
GROUPING__ID,表示结果属于哪一个分组集合。
SELECT month,day,COUNT(DISTINCT cookieid) AS uv, GROUPING__ID
FROM kangna_t5
GROUP BY month,day
GROUPING SETS (month,day)
ORDER BY GROUPING__ID;-- grouping_id表示这一组结果属于哪个分组集合,
-- 根据grouping sets中的分组条件month,day,1是代表month,2是代表day
-- 等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM kangna_t5 GROUP BY month UNION ALL
SELECT NULL as month,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM kangna_t5 GROUP BY day 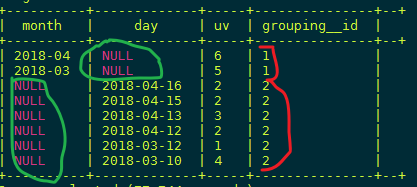
CUBE(立方体 数据立方体 多维数据分析)---kylin
举个栗子:某个事情有A、B、C三个维度,根据这三个维度进行组合分析,共有多少种情况?
这些情况加起来就是所谓多维分析中数据立方体。 多维度的预处理 框架 kylin 的计算模型就是 cube。
- 没有维度:[]
- 一个维度:[A] [B] [C]
- 两个维度:[AB] [AC] [BC]
- 三个维度:[ABC]
共有8个结果。
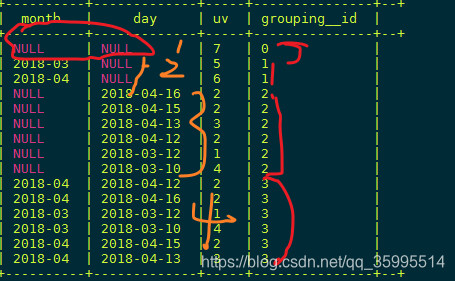
SELECT month,day,COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM kangna_t5
GROUP BY month,day
WITH CUBE
ORDER BY GROUPING__ID;规律:假如有n个维度 所有的维度组合情况是2的n次方
目前,我用的多的就是 row_number() , sum(), 解决topN 问题,分区排序,累积计数。遇到新的再总结。