CKEditor5导入并解析word功能的集成,实现word转html
概述
说起富文本编辑器,我们大都遇到过,甚至使用过,这种所见即所得的书写方式,以及它灵活的排版,让我们的创作更加流畅和美观。其实你可以把它理解成是把word等软件的功能转成在浏览器里面使用,这样就能通过其他的一些手段进行管理,并融入到相应系统中。但是由于实现方式和语言等的不同,存在着一些出入。
比如我现在正在使用的,也就是此刻我写这篇文章的工具,就是一个富文本编辑器。其实富文本编辑器有很多种,它们的功能类似、产出目的类似、使用方式也类似,只不过在丰富程度上稍有差别,今天的CKEditor5就是其中的一款。
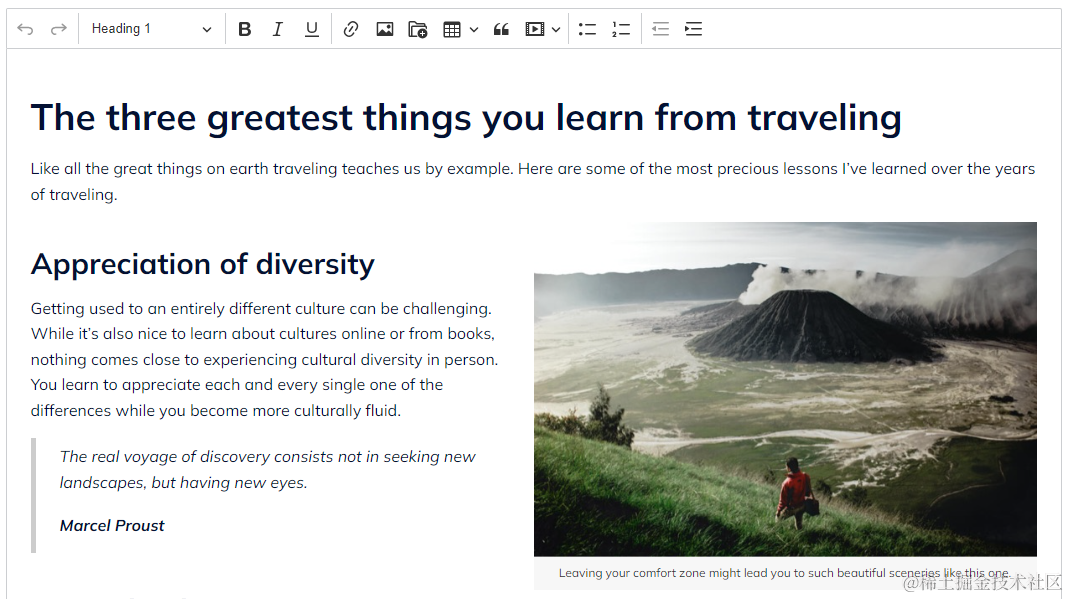
可以看到,还是很好看的,美而不失实用。它的功能特别多,只不过有一些功能是要收费的,也就是说它只开源了一部分,或者说对于一些更高级的吊吊的功能你需要少买一点零食或者玩具。不过这些基础功能已经足够用了,它的可插拔式插件集成功能非常强大。
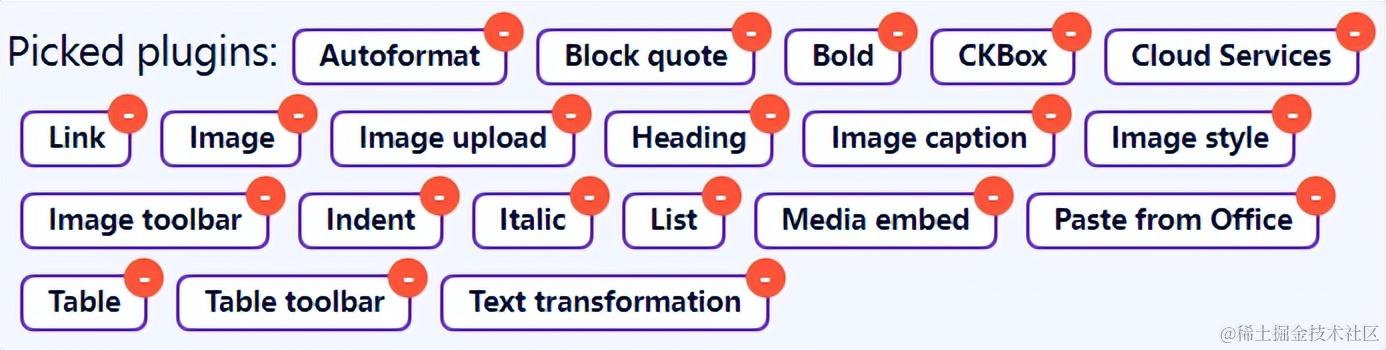
就像上面所示,你可以随意的添加或删除一个扩展功能,下面有非常多的待继承插件供你选择。
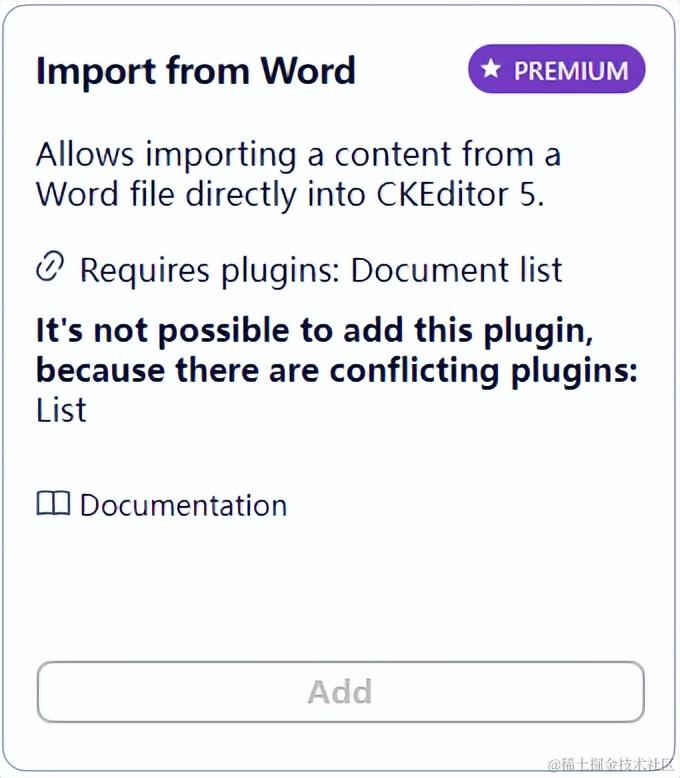
但是像上面这种的,带有premium的插件,那你就需要支付一定的费用才可以使用啦。
细心的你相信一眼就看出来了,这就是我们今天要讲的内容:从word中导入。
这是一个高级功能,虽然不是很常用,但是有一些特殊的场景或者需求,我们可能希望从编辑好的word中,通过导入的方式来让用户在网页中继续编辑它,并尽可能的保留内容和格式。
一个是自己资金不是很充裕,再一个是想自己去动手做做,因此就决定独立实现这样一个功能。自己做的,当然可以随便免费用。
示例
在开始之前,我们先看下做这个功能在完成之后需要满足的效果,虽然这个功能官网是收费的,但是为了给大家演示,官网也提供了示例,我们先看下官网的成品:

我们先根据提示,在官网示例上面下载了它提供的一个word,然后用CKEditor5的导入word功能,把这个word导入到编辑器中,解析完成之后就看到了效果,它的还原度很高了,官网应该是特意制作的示例word文件,里边包含了段落、列表、图片、表格等等多个技术点。这些都是我们接下来要实现的内容,官网这复杂程度,钱花的挺值。
为了能让大家有一个对比,这里我把原版word也展示出来给你们看一下:

可以对比着感受下,不过还是有一些地方不太一样的,比如我对这个原文档做一点点更改。体现就稍微有一点略微的不同,但是这个不是毛病,只是看着有点别扭,我给两张图,先来原word的图,这是我改过的列表:

再来一张官网导入之后渲染的效果图:

主要有:1.列表距左边的距离。2.列表项之间多出空白。3.不能显示中文序号。
实现
我们要想实现这样一个插件,首先想到有没有现成的word转html的前端或者后端插件,因为富文本编辑器是可以设置内容的,并且这个内容实质就是html代码,然后再在这个基础上进行集成开发。
因为我有自己的node后端,所以如果用后端做的话就找了一些关于node的word转html插件,一共找到了docx2html、mammoth、word2html等,但是经过测试都不太理想,于是决定放弃,换一个思路,我们可以解析word,然后根据word规范,自己生成出html。
word是流式文件,能任意编辑并且回显,那么肯定有一套约定在里边,能够保存格式并重新读取,就看它有没有开放给我们,幸好,docx这个x就是告诉我们,可以的,因为它就是xml的意思,符合xml规范。
好了,我们可以找出两个辅助插件:
第一个就是用来解压缩用的adm-zip包。
第二个就是用来解析xml文件的xml-js包。
为什么这样呢?这是因为一个docx文件,就是一个压缩包,我们把docx文件重命名为zip格式。然后就可以解压看下里面的内容:
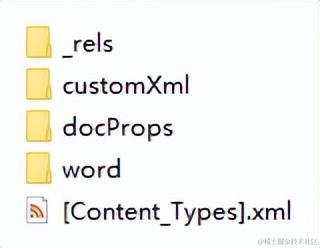
这就是解压之后的目录,里面包含着所有的word内容,我们一会揭开它的面纱。其中一个关键目录就是word文件夹:
可以看到有很多的xml文件,它们就规定了word的回显机制和渲染逻辑。
还有一个media文件夹,我们看下它里面有什么:
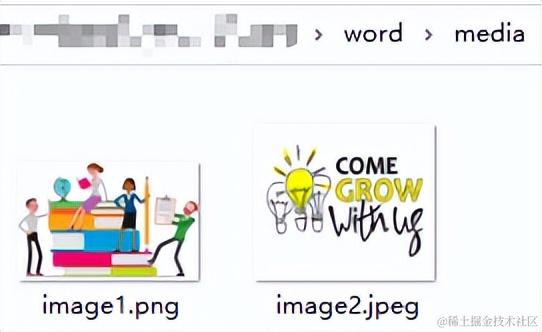
可以明显的看到有两张图片,这两张图片就是我们在原word中使用的图片,它就隐藏在这里。
另外,其中document.xml文件存储了整个word的结构和内容,numbering.xml文件规定了列表如何渲染,styles.xml告诉了需要应用哪些样式。
我们就以document.xml文件做一个简单的说明,其余不做过多展开:
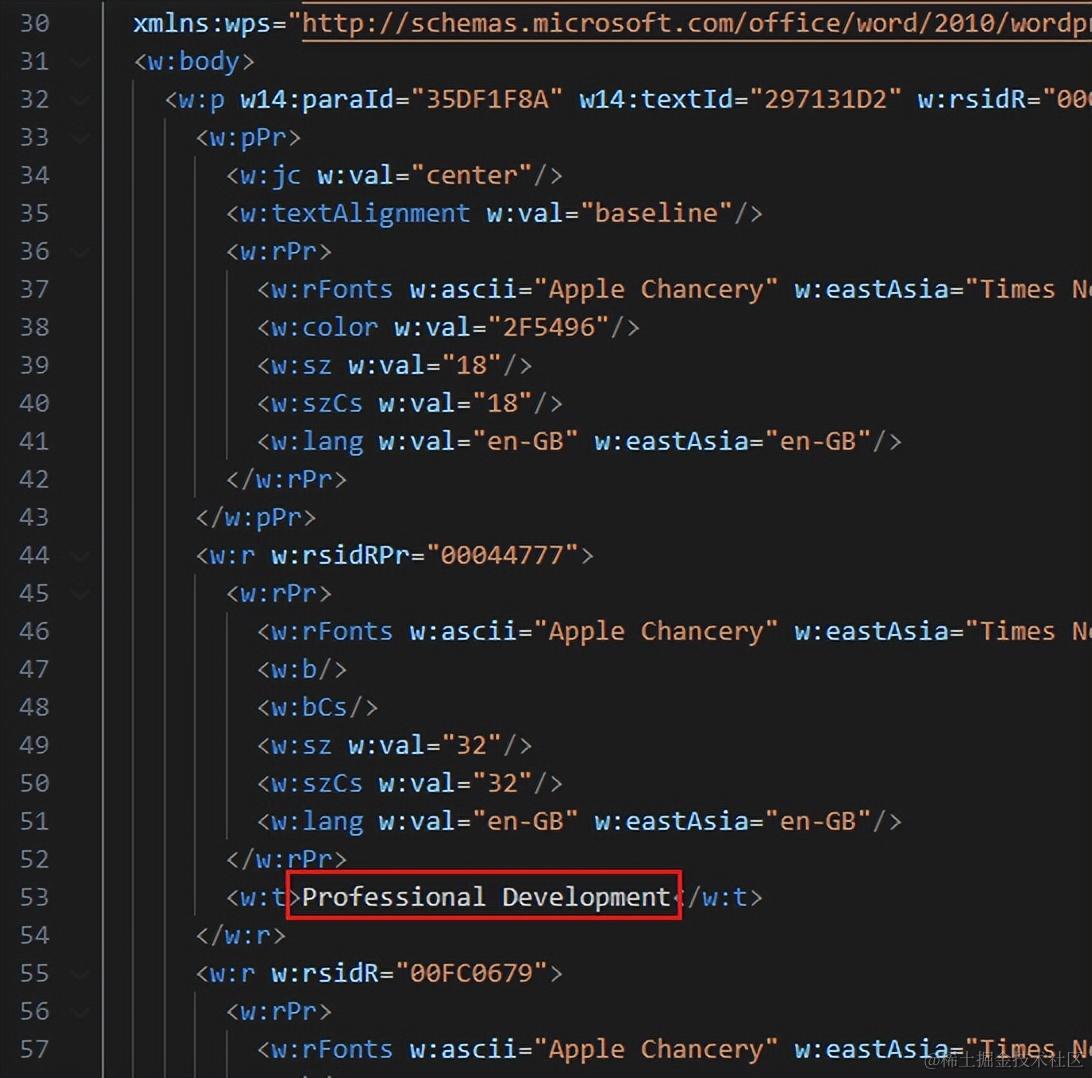
文件前面是对该xml的一些声明,body中包含了一个个的段落,也就是w:p。其中又包含了多个系列w:r,系列中就存储着我们的文本,比如上图红框中我圈出的部分。
而且里面还存储着段落属性w:pPr和系列属性w:rPr。我们就是通过对这些一对对的xml标签,来对word进行解析,找出它的渲染规则。
首先使用上面提到的两个包,非常简单:
const dir = join(process.cwd(), 'public/temp/word/' + fn)
const zip = new AdmZip(dir)
let contentXml = zip.readAsText('word/document.xml')
const documentData = xml2js(contentXml)
contentXml = zip.readAsText('word/numbering.xml')
const numberingData = contentXml ? xml2js(contentXml) : {elements: ''
}
contentXml = zip.readAsText('word/_rels/document.xml.rels')
const relsData = xml2js(contentXml)
contentXml = zip.readAsText('word/styles.xml')
const styleData = xml2js(contentXml)
let ent = zip.getEntries()
let ind = fn.lastIndexOf('.')
let flag = false
for(let i = 0; i < ent.length; i++) {let n = ent[i].entryNameif(n.substring(0, 11) === 'word/media/') {flag = truezip.extractEntryTo(n, join(process.cwd(), 'public/temp/word/' + fn.substring(0, ind)), false, true)}
}
return {documentXML: documentData?.elements[0]?.elements[0]?.elements,numberingXML: numberingData?.elements[0]?.elements,relsXML: relsData?.elements[0]?.elements,styleXML: styleData?.elements[0]?.elements.slice(2),imagePath: fn.substring(0, ind),
}
简单对上面的代码做一下说明:
- 先说返回值,由于我们解析完word之后,需要将xml文件读取出来,根据语义再转成html,因此我们需要整个document.xml中的内容,因此返回documentXML,而且还要知道列表的渲染机制,因此也需要返回numberingXML,同样我们需要获取到文档中用了哪些图片,以及它们的位置,所以要返回relsXML,并且我要把对应的图片放到另一个地方存储起来以供使用,所以也要返回imagePath,最后整个文档的样式,也就是styleXML也要返回。
- 第1行就是获取到上传的word路径,这里是我自己做了一个上传方法。
- 第2行通过adm-zip插件对文件进行解压和读取。
- 第3行就是指定获取document.xml文件的内容。
- 第4行就是用xml-js对读取到的内容进行解析,之后的代码同理,只是去解析不同的文件而已。
- 第13行读取该压缩文件中的目录结构。
- 第16行至第22行就是找出word里面用到的所有图片,并将它们存储在其他位置。
至此,我们看一下目前解析完成之后,形成的数据结构。

很好,现在开始集成:
import { Editor } from '/lib/ckeditor5/ckeditor'
import loadConfig from './config'
import filePlugin from './file'
import './style.scss'
loadConfig(Editor)
const container: any = ref(null)
let richEditor: any = null
onMounted(() => {Editor.create(container.value, {extraPlugins: [filePlugin]}).then((editor: any) => {richEditor = editor}).catch((error: any) => {console.log(error.stack)})
})
第1行,导入Editor,也就是我们一会要用的富文本编辑器,然后第9行通过create方法创建它,接收的两个参数分别表示:渲染的容器与配置的插件。
因为CKEditor5填入图片的时候,需要自己手动实现一个插件方法,因此我们要把它配置进来,因为跟咱们要讲的内容无关,就不展开了,官方文档说的很清楚了。
第5行,我在初始化编辑器之前,先去加载了一些配置,其中一个就是引入word转pdf的功能,由于CKEditor5插件扩展很容易,直接在Editor的builtinPlugins属性数据里面加上我们实现的插件就可以,所以我们直接讲插件的开发:
import { ButtonView, Plugin } from '/lib/ckeditor5/ckeditor'
import { postData } from '@/request'
import { DocumentWordProcessorReference } from '@/common/svg'
import { serverUrl } from '@/company'
import { ElMessage } from 'element-plus'
import { arrayToMapByKey } from '@/utils'
let numberingList: any = null
let relsList: any = null
let styleList: any = null
let imageUrl: any = null
let docInfo: any = {author: {},currentAuthor: '',currentIndex: -1
}
const colorList = ['#d13438', '#0078d4', '#5c2e91', 'chocolate', 'aquamarine', 'lawngreen', 'hotpink', 'darkblue', 'darkslateblue', 'blueviolet', 'firebrick', 'coral', 'darkcyan', 'indigo', 'greenyellow', 'deeppink', 'indianred', 'blue', 'darkgray', 'darkmagenta', 'darkgreen', 'chartreuse', 'darksalmon', 'dimgray', 'crimson', 'darkolivegreen', 'gold', 'aqua', 'lightcoral', 'goldenrod', 'burlywood', 'green', 'darkkhaki', 'forestgreen', 'fushcia', 'darkorchid', 'deepskyblue', 'darkgoldenrod', 'cyan', 'cornflowerblue', 'brown', 'cadetblue', 'darkviolet', 'dodgerblue', 'darkred', 'gray', 'khaki', 'bisque', 'darkorange', 'darkslategray', 'lightblue', 'darkturquoise', 'darkseagreen']
let BlockType = ''
引入一些必要的组件和方法等,然后定义我们的插件,一定要继承ckeditor5的Plugin:
export default class importFromWord extends Plugin {
}
然后首先在里面实现它的init方法,做一些初始化操作:
init() {const editor = this.editoreditor.ui.componentFactory.add('importFromWord', () => {const button = new ButtonView()button.set({label: '从word导入',icon: DocumentWordProcessorReference,tooltip: true})button.on('execute', () => {this.input.click()})return button})
}
this.editor就是我们之前使用create创建好的编辑器,通过editor.ui.componentFactory.add给工具栏添加一个按钮,也就是我们要点击导入word的按钮。
这里面用到了ckeditor5的ButtonView按钮组件生成器,设置它的名称和图标,然后添加一个暴露出来的事件,当点击按钮的时候,触发选择文件弹窗,这个input是我自己写的一个文件上传输入框。
接下来,我们去构造函数中做一些事情,当实例化这个组件的时候,初始化好我们需要的东西:
constructor(editor: any) {super(editor)this.editor = editorthis.input = document.createElement('input')this.input.type = 'file'this.input.style.opacity = 0this.input.style.display = 'none'this.input.addEventListener('change', (e: any) => {const formData: any = new FormData()formData.append("upload", this.input.files[0])formData.Headers = {'Content-Type':'multipart/form-data'}let ms = ElMessage({message: "正在解析...",type: "info",})postData({service: "lc",url: `file/word`,data: formData,}).then(res => {ms.close()if (res.data) {ElMessage({message: "上传文件成功",type: "success",})const { documentXML, numberingXML, relsXML, styleXML, imagePath } = res.datanumberingList = numberingXMLrelsList = relsXMLstyleList = styleXMLimageUrl = imagePathmarkList(documentXML)const html = listToHTML(documentXML)const ckC = this.editor.ui.view?.editable?.elementconst ckP = this.editor.ui.view?.stickyPanel?.elementif(ckC) {let rt = ckC.parentNode.parentNode.parentNodert.style.setProperty('--content-top', docInfo.paddingTop + 'px')rt.style.setProperty('--content-right', docInfo.paddingRight + 'px')rt.style.setProperty('--content-bottom', docInfo.paddingBottom + 'px')rt.style.setProperty('--content-left', docInfo.paddingLeft + 'px')rt.style.setProperty('--content-width', docInfo.pageWidth - docInfo.paddingLeft - docInfo.paddingRight + 'px')}if(ckP) {let rt = ckP.parentNode.parentNode.parentNodert.style.setProperty('--sticky-width', docInfo.pageWidth + 'px')}const div = document.createElement('div')div.style.display = 'none'div.innerHTML = htmlsplitList(div.firstElementChild)insertDivToList(div)document.body.appendChild(div)document.body.removeChild(div)this.editor.setData(div.innerHTML)} else {ElMessage({message: "上传文件失败",type: "error",})}})})}
在这里我们主要做了几件事:
首先第4行到第7行定义了一个文件选择器。
然后给这个输入框添加了一个事件。
第9行到第20行我们读取到选择的文件并上传到服务器进行解析。
对返回回来的文档数据,我们首先做一个标记,以方便我们接下来的操作:
function markList(list: any) {let cache: any = []list.forEach((item: any, index: number) => {let isList = falseif(item.name === 'w:p') {let pPr = findByName(item.elements, 'w:pPr')if(pPr) {let numPr = findByName(pPr.elements, 'w:numPr')if(numPr) {isList = truelet ilvl = numPr.elements[0].attributes['w:val']let numId = numPr.elements[1].attributes['w:val']let c = cache.at(-1)numPr.level = ilvlif(c) {if(c.ilvl === ilvl && c.numId === numId) {cache.pop()}else if(c.ilvl === ilvl && c.numId !== numId) {numPr.start = truec.numPr.end = truecache.pop()}else if(c.ilvl < ilvl && c.numId === numId) {numPr.start = truecache.pop()}else if(c.ilvl > ilvl && c.numId === numId) {c.numPr.end = truecache.pop()}else if(c.numId !== numId) {while(c.ilvl >= ilvl) {c.numPr.end = truec = cache.pop()if(!c) {break}}}}else {numPr.start = true}cache.push({ilvl,numId,index,numPr})}}}})cache.forEach((c: any) => {c.numPr.end = true})
}
主要就是对列表进行标记,因为它要做一些特殊化的处理。
拿到数据之后,我们的核心逻辑都在第33行,实现listToHtml进行处理:
function listToHTML(list: any) {let html = ''list.forEach((item: any, index: number) => {let info = getContainer(item)html += info})return html
}
遍历每一项,然后把它们生成的html拼接起来:
function getContainer(item: any) {let html = ''if(item.name === 'w:p') {let n = findByName(item.elements, 'w:pPr')let el: any = nulllet pEl: any = nulllet attr: any = {}let style = nullif(n) {let ps = findByName(n.elements, 'w:pStyle')if(ps) {let styleId = getAttributeVal(ps)let sy = styleList.find((item: any) => {return item.attributes['w:styleId'] === styleId})let ppr = findByName(sy.elements, 'w:pPr')let rpr = findByName(sy.elements, 'w:rPr')if(ppr) {ppr.elements.forEach((p: any) => {if(!findByName(n.elements, p.name)) {n.elements.push(p)}})}if(rpr) {let rs = findsByName(item.elements, 'w:r')rs.forEach((r: any) => {let rr = findByName(r.elements, 'w:rPr')rpr.elements.forEach((p: any) => {if(!findByName(rr.elements, p.name)) {rr.elements.push(p)}})})}}let info = getPAttribute(n.elements)attr = info.attrstyle = info.styleif(attr.list) {let s1: any = {}let s2: any = {}for(let t in info.style) {if(t === 'list-style-type') {s1[t] = info.style[t]}else{s2[t] = info.style[t]}}for(let t in info.liStyle) {s1[t] = info.liStyle[t]}if(attr.order) {if(attr.start) {if(attr.level !== '0') {html += '<li style="list-style-type:none;">'}html += '<ol'html += addStyle(s1)html += '<li>'html += '<p'html += addStyle(s2)}else {html += '<li>'html += '<p'html += addStyle(s2)}}else{if(attr.start) {if(attr.level !== '0') {html += '<li style="list-style-type:none;">'}html += '<ul'html += addStyle(s1)html += '<li>'html += '<p'html += addStyle(s2)}else {html += '<li>'html += '<p'html += addStyle(s2)}}}else{html += '<p'html += addStyle(info.style)}}else{el = document.createElement('p')}item.elements.forEach((r: any) => {if(r.name === 'w:ins') {setAuthor(r.attributes['w:author'])r.elements.forEach((ins: any) => {html += dealWr(ins, 'ins')})}else if(r.name === 'w:hyperlink') {r.elements.forEach((hyp: any) => {html += dealWr(hyp)})}else if(r.name === 'w:r') {html += dealWr(r)}else if(r.name === 'w:commentRangeStart') {BlockType = 'comment'}else if(r.name === 'w:commentRangeEnd') {BlockType = ''}else if(r.name === 'w:del') {setAuthor(r.attributes['w:author'])r.elements.forEach((hyp: any) => {html += dealWr(hyp, 'del')})}})if(attr.list) {if(attr.order) {if(attr.end) {html += '</p></li></ol>'if(attr.level !== '0') {html += '</li>'}}else {html += '</p></li>'}}else{if(attr.end) {html += '</p></li></ul>'if(attr.level !== '0') {html += '</li>'}}else {html += '</p></li>'}}}else {html += '</p>'}}else if(item.name === 'w:tbl') {let n = findByName(item.elements, 'w:tblPr')if(n) {let info = getTableAttribute(n.elements)html += '<figure class="table"'html += addStyle(info.figureStyle)html += '<table'html += addStyle(info.tableStyle)html += '<tbody>'}item.elements.forEach((r: any) => {if(r.name === 'w:tr') {html += dealWtr(r)}})html += '</tbody></table></figure>'}else if(item.name === 'w:sectPr') {let ps = findByName(item.elements, 'w:pgSz')let pm = findByName(item.elements, 'w:pgMar')if(ps) {docInfo.pageWidth = Math.ceil(ps.attributes['w:w'] / 20 * 96 / 72) + 1}if(pm) {docInfo.paddingTop = pm.attributes['w:top'] / 1440 * 96docInfo.paddingRight = pm.attributes['w:right'] / 1440 * 96docInfo.paddingBottom = pm.attributes['w:bottom'] / 1440 * 96docInfo.paddingLeft = pm.attributes['w:left'] / 1440 * 96}}return html
}
做了一些逻辑判断,和不同标签的特殊处理。
在刚才input事件中的第34行到47行,主要是做一些编辑器大小等外观设置,因为要配置成word中的宽度与边距。
还需要考虑到,列表可能不是连续的,中间可能被一些段落所隔开,因此到这里还需要对生成的html中的列表进行分割,并修复索引问题:
function splitList(el: any) {while(el) {if(el.tagName === 'OL' || el.tagName === 'UL') {let a = el.querySelectorAll('ol > p, ul > p')let path: any = []a.forEach((item: any) => {let p: any = []while(item) {p.push(item)item = item.parentNodeif(item === el) {break}}path.push(p.reverse())})let cur = ellet t: number = 0path.forEach((p: any) => {let list = cur.cloneNode(false)let list2 = listcur.parentNode.insertBefore(list, cur)p.forEach((l: any, ind: number) => {let chi = cur.childrenlet t = 0for(let i = 0; i < chi.length; i++) {if(chi[i] !== l) {list.append(chi[i])t++i--}else{if(cur.tagName === 'OL') {let s = cur.getAttribute('start')cur.setAttribute('start', s ? (+s + t) : (t + 1))}if(ind === p.length - 1) {let par = chi[i].parentNodeel.parentNode.insertBefore(chi[i], el)if(par.children.length === 0) {par.remove()}cur = el}else{cur.setAttribute('start', cur.getAttribute('start') - 1)let cl = chi[i].cloneNode(false)list.append(cl)list = clcur = chi[i]}break}}})})}el = el.nextElementSibling}
}
并且由于CKEditor5会对相邻的列表进行合并等处理,这不是我们想要的,可以在它们中间插入一些div:
function insertDivToList(div: any) {let f = div.firstElementChildlet k = f.nextElementSiblingwhile(k) {if(f.tagName === 'UL' && k.tagName === 'UL') {let d = document.createElement('div')f = kdiv.insertBefore(d, f)k = f.nextElementSibling}else if(f.tagName === 'OL' && k.tagName === 'OL') {let d = document.createElement('p')d.setAttribute('list-separator', "true")f = kdiv.insertBefore(d, f)k = f.nextElementSibling}else {f = kk = f.nextElementSibling}}
}
最后我们用this.editor.setData方法,将刚才生成的html设置到编辑器中去。
到此我们基本就已经把需要的功能实现了。
效果
该来看一下我们所做的工作成果了,首先同样导入CKEditor5官网中的文档:
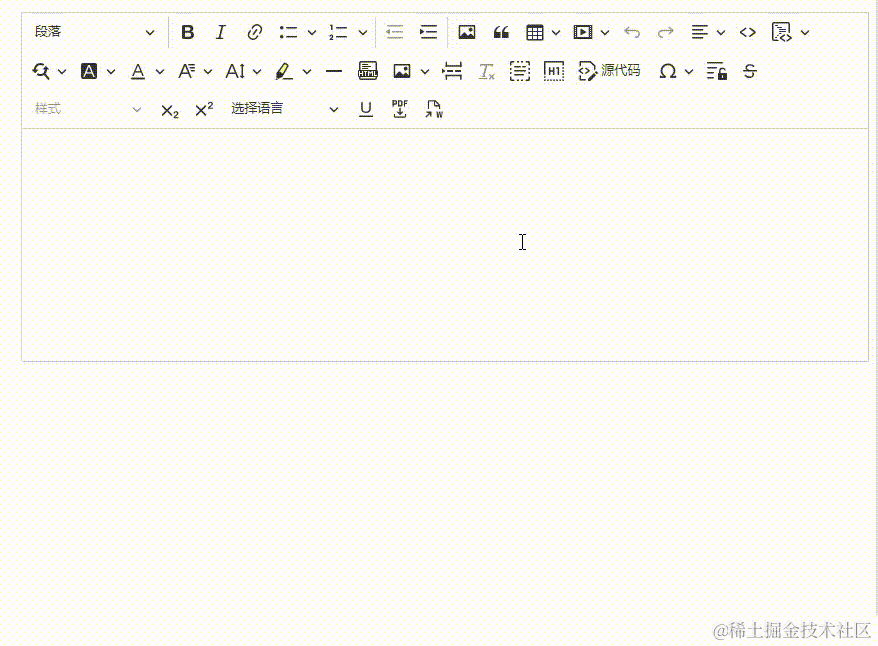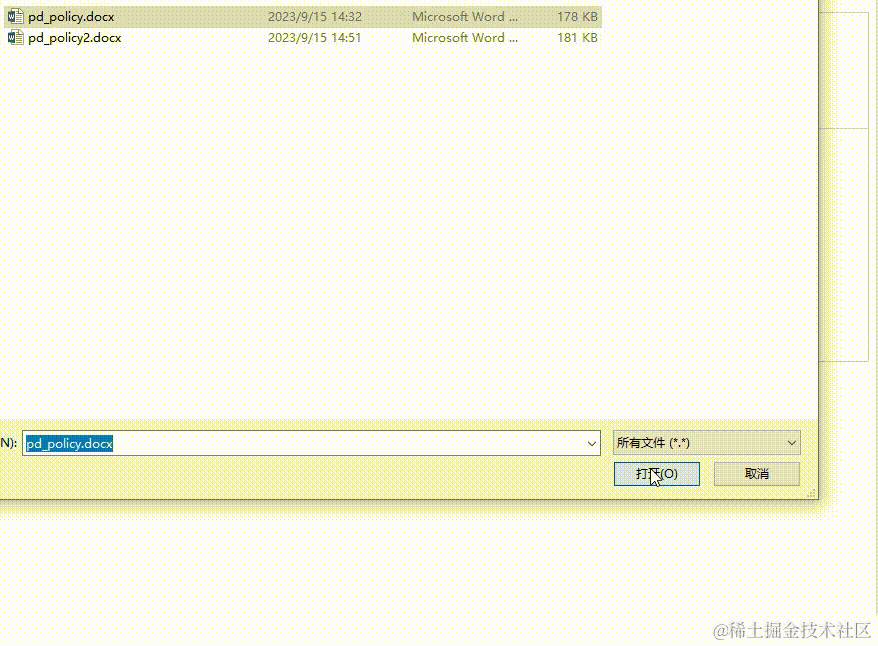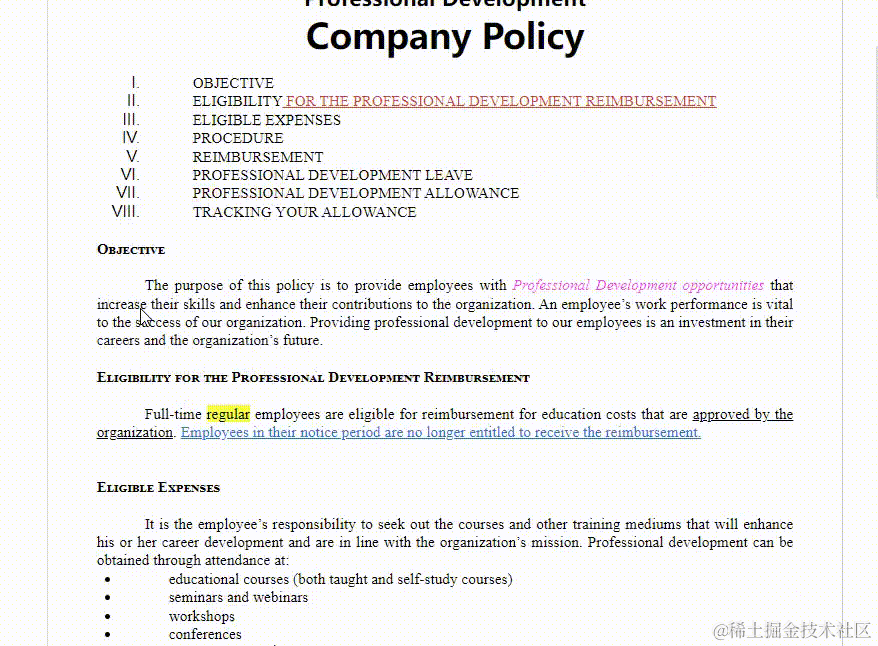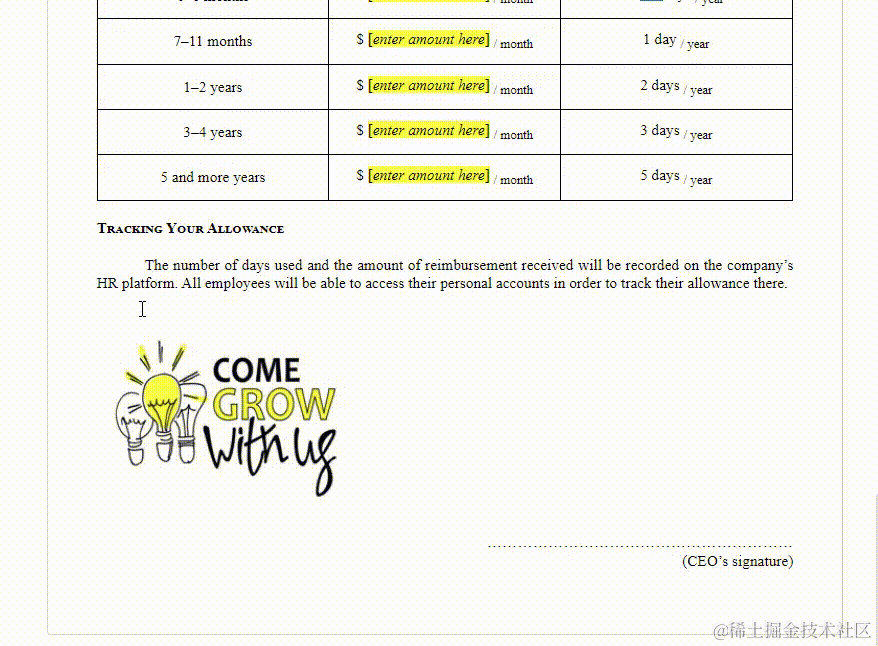
可以看到,内容与格式等,基本跟原word一样,与CKEditor5官网的示例也相同。然后我们再用另一个刚才修改过的文件测试一下:

这个是用咱们刚才开发的插件导入的word的效果图,几乎与原word一模一样,也没有了CKEditor官网中的那几个小问题。
至此,我们针对CKEditor5导入word的功能已经开发完毕,同时我又找了各种类型的word测试,均未发现问题,还原度都非常高。
结语
感谢docx的规范,使得我们自己解析word成为可能,虽然不可能100%还原word的格式,但是能够将它导入到我们的富文本编辑器中,以进行二次创作,这对我们来说是非常方便的。
本次word转html,并导入富文本编辑器的开发过程,希望能给大家带来启发。
每一次创作都是快乐的,每一次分享也都是有益的,希望能够帮助到你!
