多线程电影天堂最新资源爬取脚本、电影搜索脚本
PS:方便大家使用写到了HTML中生成表格。
线程可以在脚本里直接改,测试线程为30时IP可能会被限制访问。[阳光电影是电影天堂的马甲]
环境: Python3
最新电影爬取代码
# -*- coding: utf-8 -*- import random import threading import requests as req from lxml import etree from queue import QueueBASE_URL_COM = 'http://www.ygdy8.com' BASE_URL_NET = 'http://www.ygdy8.net' THREADS = 20 PAGE_TOTAL = 100HEAD = '<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>阳光电影 - 电影天堂</title><link href="https://cdn.bootcss.com/bootstrap/4.0.0/css/bootstrap.min.css" rel="stylesheet"></head><body><table class="table"><thead class="thead-dark"><tr><th scope="col">#</th><th scope="col">电影名</th><th scope="col">下载地址</th></tr></thead><tbody class="table-hover">' FOOT = '</tbody></table></body></html>'count = 1def get_headers():user_agent_list = ['Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1','Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6','Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6','Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1','Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5','Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3','Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3','Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3','Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3','Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3','Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3','Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24','Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24']UA = random.choice(user_agent_list)headers = {'User-Agent': UA}return headersdef get_url(list_queue, url_queue):while True:url = list_queue.get()try:res = req.get(url, headers=get_headers())res.encoding = res.apparent_encodinghtml = etree.HTML(res.text)tags = html.xpath('//div[@class="co_content8"]/ul//a')for tag in tags:href = tag.get('href')url_queue.put(href, 1)print('[Subscribe] [%s]' % href)except:print('[Subscribe Error] %s' % url)list_queue.task_done()def get_list(list_queue):lists = [i for i in range(1, PAGE_TOTAL + 1)]list_url = 'http://www.ygdy8.com/html/gndy/dyzz/list_23_%d.html'for i in lists:url = list_url % ilist_queue.put(url, 1)def parse_download(url):res = req.get(url, headers=get_headers())res.encoding = res.apparent_encodinghtml = etree.HTML(res.text)title = html.xpath('//div[@class="bd3r"]//div[@class="title_all"]/h1/font')[0].textdownloads = html.xpath('//div[@id="Zoom"]//table//a/@href')return title, downloadsdef parse_html(url_queue, result_file):while True:global counturl_path = url_queue.get()try:try:url = BASE_URL_COM + url_path(title, downloads) = parse_download(url)except:url = BASE_URL_NET + url_path(title, downloads) = parse_download(url)download = '<hr>'.join(downloads)tr = '<tr><th scope="row">%d</th><td>%s</td><td>%s</td></tr>' % (count, title, download)result_file.write(tr)print('[OK][%d] %s' % (count, title))count = count + 1except:print('[Parse error] %s' % url_path)url_queue.task_done()def thread(thread_name, target, args):for i in range(THREADS):t = threading.Thread(target=target, args=args)t.setDaemon(True)t.start()thread_name.join()def main():list_queue = Queue()url_queue = Queue()get_list(list_queue)thread(list_queue, get_url, (list_queue, url_queue))result_file = open('result.html', 'w')result_file.write(HEAD)thread(url_queue, parse_html, (url_queue, result_file))result_file.write(FOOT)result_file.close()print('End... 老铁记得顶我(TieZi)\nEnd... 老铁记得顶我(TieZi)\nEnd... 老铁记得顶我(TieZi)')if __name__ == '__main__':main()
搜索电影代码
# -*- coding: utf-8 -*- import sys import random import requests as req from urllib import parse from lxml import etree from multiprocessing import PoolBASE_URL = 'http://www.ygdy8.com' SEARCH_URL = 'http://s.ygdy8.com/plus/so.php?kwtype=0&searchtype=title&pagesize=1000&keyword='# 关键字需要URL字符编码 def get_headers():user_agent_list = ['Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1','Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6','Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6','Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1','Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5','Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3','Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3','Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3','Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3','Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3','Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3','Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24','Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24']ua = random.choice(user_agent_list)headers = {'User-Agent': ua}return headersdef search(keyword):keyword = parse.quote(keyword.encode("gbk"))url = SEARCH_URL + keywordres = req.get(url, headers=get_headers())res.encoding = res.apparent_encodinghtml = etree.HTML(res.text)tags = html.xpath('//div[@class="co_content8"]/ul//a')result_urls = []for tag in tags:url = BASE_URL + tag.get('href')result_urls.append(url)return result_urlsdef parse_html(url):res = req.get(url, headers=get_headers())res.encoding = res.apparent_encodinghtml = etree.HTML(res.text)title = html.xpath('//div[@class="bd3r"]//div[@class="title_all"]/h1/font')[0].textdownloads = html.xpath('//div[@id="Zoom"]//table//a/@href')print('[%s]' % title)for download in downloads:print('[下载链接] [%s]' % download)print('\n|----------------------------------------------------------|\n')if __name__ == '__main__':if len(sys.argv) < 2:print("Usage: python %s movie_name" % sys.argv[0])exit(-1)urls = search(sys.argv[1])pool = Pool()pool.map(parse_html, urls)
最新电影爬取效果

生成后的HTML表格

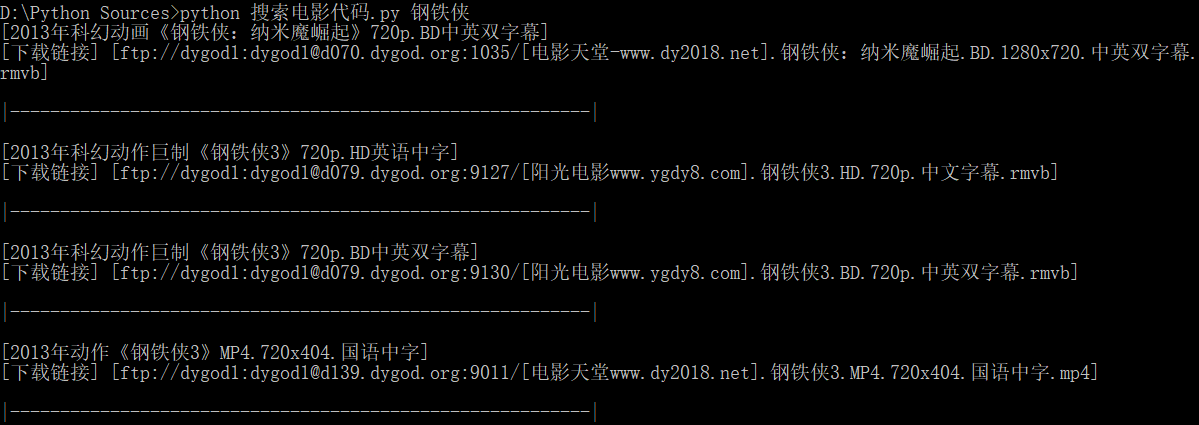
电影搜索效果

[补图]爬取的下载链接含FTP和磁力链接,片源有磁力链接就会被爬取
爬取结果

搜索结果