集成学习三种框架
集成学习通过组合多个弱学习器构建强学习器,常见框架包括Bagging(装袋)、Boosting(提升) 和Stacking(堆叠)
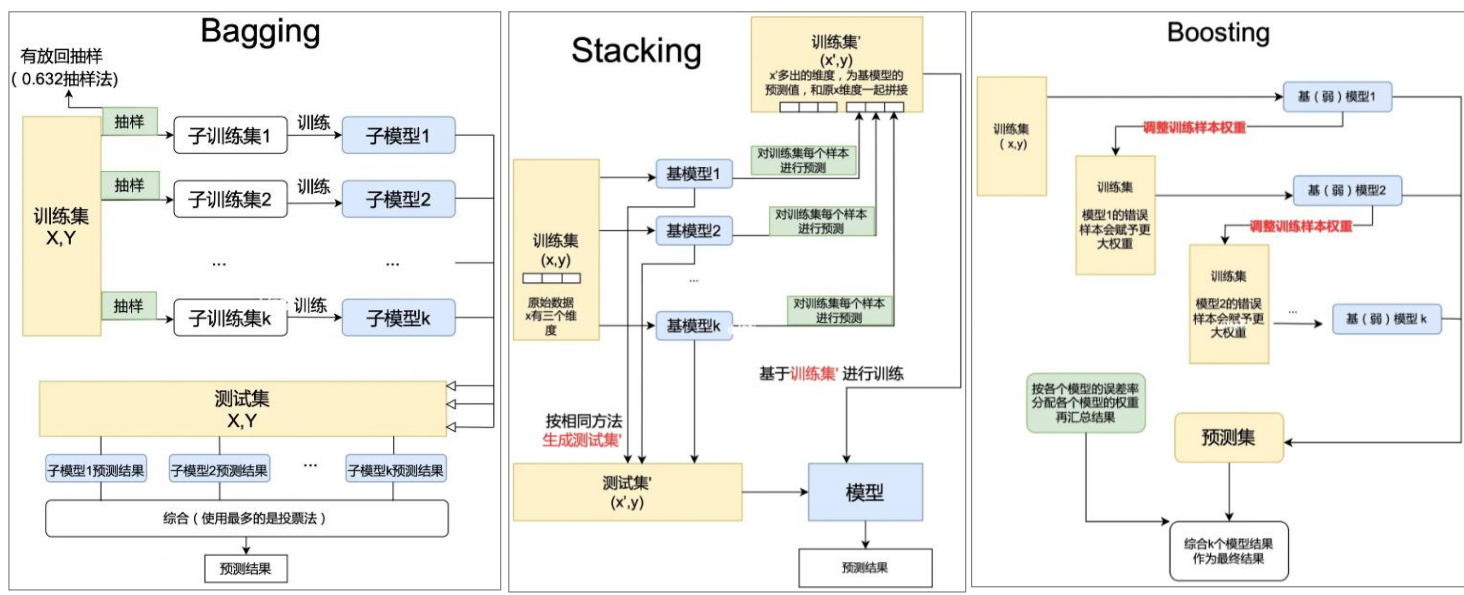
一、Bagging(自助装袋法)
核心思想
- 从原始数据中通过有放回抽样生成多个子集,每个子集训练一个基学习器,最终通过投票(分类)或平均(回归) 整合结果。
- 典型代表:随机森林(Random Forest)。
关键特点
- 并行训练:基学习器可独立训练,计算效率高。
- 降低方差:通过样本扰动减少模型对特定数据的过拟合,提升泛化能力。
- 对噪声不敏感:适合处理高方差模型(如决策树)。
应用场景
- 分类与回归任务(如房价预测、文本分类)。
二、Boosting(提升法)
核心思想
- 串行训练基学习器,逐步优化前一个学习器的错误:给错误样本更高权重,迫使后续学习器重点关注难分样本,最终通过加权组合提升整体性能。
- 典型代表:AdaBoost、GBDT、XGBoost、LightGBM。
关键特点
- 串行训练:基学习器依赖前序结果,计算复杂度较高。
- 降低偏差:通过迭代优化,逐步逼近真实模型,适合处理复杂任务。
- 对噪声敏感:若基学习器过拟合,易放大噪声影响。
应用场景
- 高精度预测任务(如金融风险评估、推荐系统)。
三、Stacking(堆叠法)
核心思想
- 通过两层学习结构整合基学习器:
- 第一层用原始数据训练多个基学习器,生成预测结果;
- 第二层以第一层的预测结果为输入,训练一个元学习器(如逻辑回归),最终由元学习器输出结果。
关键特点
- 层次化整合:可捕获基学习器之间的互补信息,灵活性高。
- 需避免过拟合:第二层训练数据为第一层的预测值,需注意数据量和正则化。
应用场景
- 竞赛场景(如 Kaggle)或需要高精度集成的复杂任务。