Redis底层数据结构之深入理解跳表(1)
在上一篇文章中我们详细的介绍了一下Redis中跳表的结构以及为什么Redis要引入跳表而不是平衡树或红黑树。这篇文章我们就来详细梳理一下跳表的增加、搜索和删除步骤。
SkipList的初始化
跳表初始化时,将每一层链表的头尾节点创建出来并使用集合将头尾节点进行存储,头尾节点的层数随机指定,且头尾节点的层数就代表当前跳表的层数。初始化之后,跳表的结构如下所示:

跳表初始化的相关代码如下所示:
public class SkiplistNode {public int data;public SkiplistNode next;public SkiplistNode down;public int level;public SkiplistNode(int data, int level) {this.data = data;this.level = level;}
}public LinkedList<SkiplistNode> headNodes;
public LinkedList<SkiplistNode> tailNodes;public int curLevel;public Random random;public Skiplist() {random = new Random();headNodes = new LinkedList<>();//headNodes用于存储每一层的头节点tailNodes = new LinkedList<>();//tailNodes用于存储每一层的尾节点curLevel = getRandomLevel();//初始化跳表时,跳表的层数随机指定//指定了跳表的初始的随机层数后,就需要将每一层的头节点和尾节点创建出来并构建好关系SkiplistNode head = new SkiplistNode(Integer.MIN_VALUE, 0);SkiplistNode tail = new SkiplistNode(Integer.MAX_VALUE, 0);for (int i = 0; i <= curLevel; i++) {head.next = tail;headNodes.addFirst(head);tailNodes.addFirst(tail);SkiplistNode headNew = new SkiplistNode(Integer.MIN_VALUE, head.level + 1);SkiplistNode tailNew = new SkiplistNode(Integer.MAX_VALUE, tail.level + 1);headNew.down = head;tailNew.down = tail;head = headNew;tail = tailNew;}
}SkipList的添加方法
每一个元素添加到跳表中时,首先需要随机指定这个元素在跳表中的层数,如果随机指定的层数大于了原有跳表的层数,那么在将新元素加入到跳表之前,还要对跳表的层数进行扩大,而跳表层数的扩大就是将头尾节点的层数进行扩大。下面给出需要扩大跳表层数的依次添加过程。
初始状态,跳表的层数为2,如下图所示:
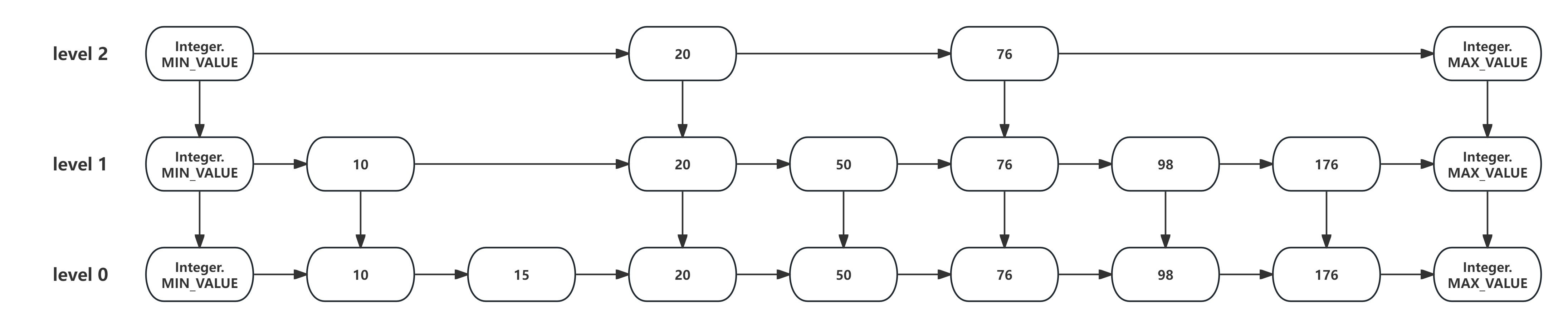
现在要向跳表中添加元素80,并随机指定了其层数为3,大于了当前跳表的层数2,此时需要先将跳表的层数扩充到3,如下图所示:
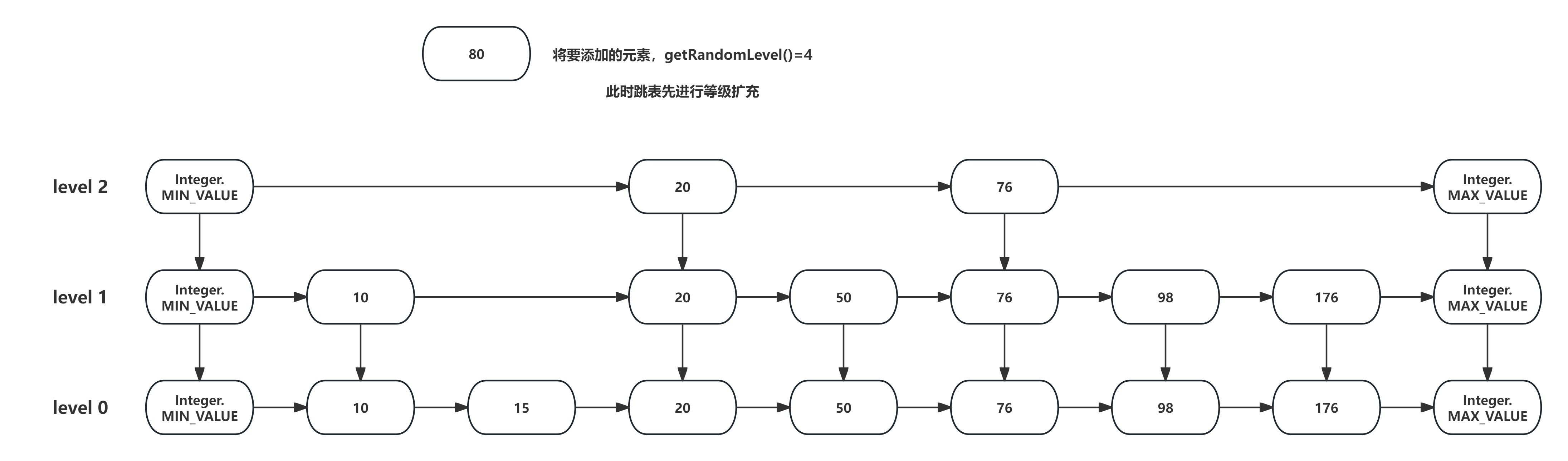
最后将元素80插入到跳表中,插入时从顶层向下逐层插入,如下图所示:
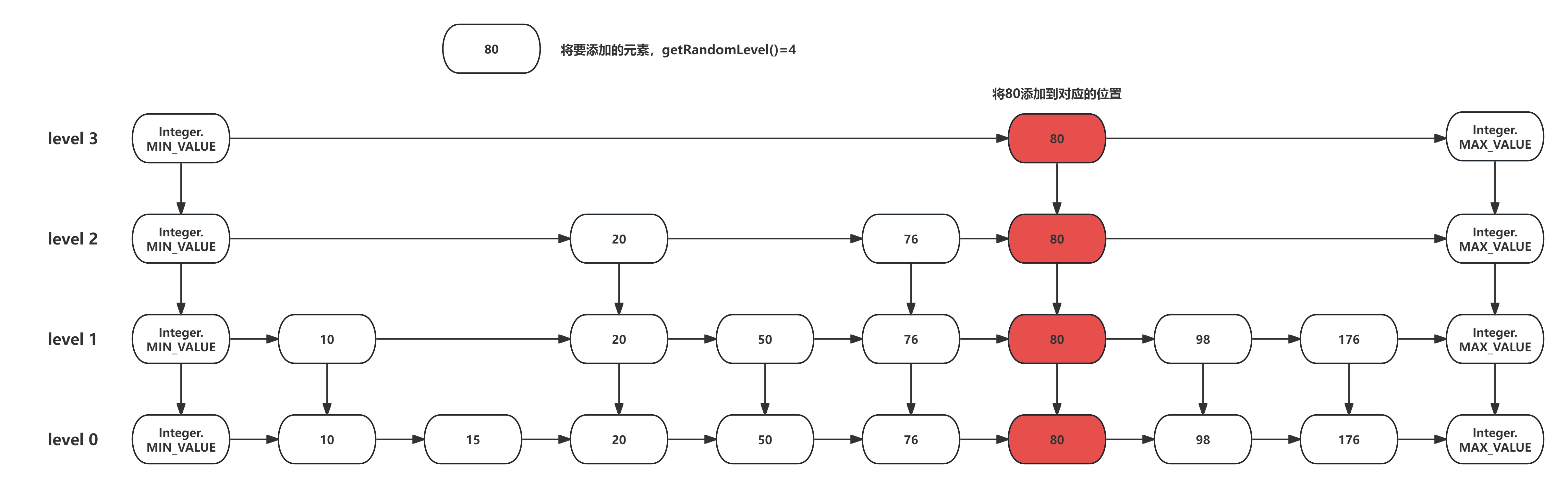
跳表的添加方法的相关代码如下所示:
public void add(int num) {int level = getRandomLevel();//获取本次添加的值的层数//如果本次添加的值的层数大于当前跳表的层数,则需要在添加当前值前先将跳表层数扩充if (level > curLevel) {expanLevel(level - curLevel);}//curNode表示num值在当前层对应的节点SkiplistNode curNode = new SkiplistNode(num, level);//preNode表示curNode在当前层的前一个节点SkiplistNode preNode = headNodes.get(curLevel - level);for (int i = 0; i <= level; i++) {//从当前层的head节点开始向后遍历,直到找到一个preNode//使得preNode.data < num <= preNode.next.datawhile (preNode.next.data < num) {preNode = preNode.next;}//将curNode插入到preNode和preNode.next中间curNode.next = preNode.next;preNode.next = curNode;//如果当前并不是0层,则继续向下层添加节点if (curNode.level > 0) {SkiplistNode downNode = new SkiplistNode(num, curNode.level - 1);curNode.down = downNode;//curNode指向下一层的节点curNode = downNode;//curNode向下移动一层}//preNode向下移动一层preNode = preNode.down;}
}private void expanLevel(int expanCount) {SkiplistNode head = headNodes.getFirst();//取出头节点中level最高的SkiplistNode tail = tailNodes.getFirst();//取出尾节点中level最高的//循环扩充level,直到与新加入节点的level相等for (int i = 0; i < expanCount; i++) {SkiplistNode headNew = new SkiplistNode(Integer.MIN_VALUE, head.level + 1);SkiplistNode tailNew = new SkiplistNode(Integer.MAX_VALUE, tail.level + 1);headNew.down = head;tailNew.down = tail;head = headNew;tail = tailNew;headNodes.addFirst(head);tailNodes.addFirst(tail);}
}
SkipList的搜索方法
在跳表中搜索一个元素时,需要从顶层开始,逐层向下搜索。当目标值大于当前节点的后一个节点值时,需要在本层链表上继续向后搜索;当目标值大于当前节点值,小于当前节点的后一个节点值时,向下移动一层,并从下层链表的同节点位置向后搜索;当目标值等于当前节点值时,搜索结束并返回。具体流程如下图所示:
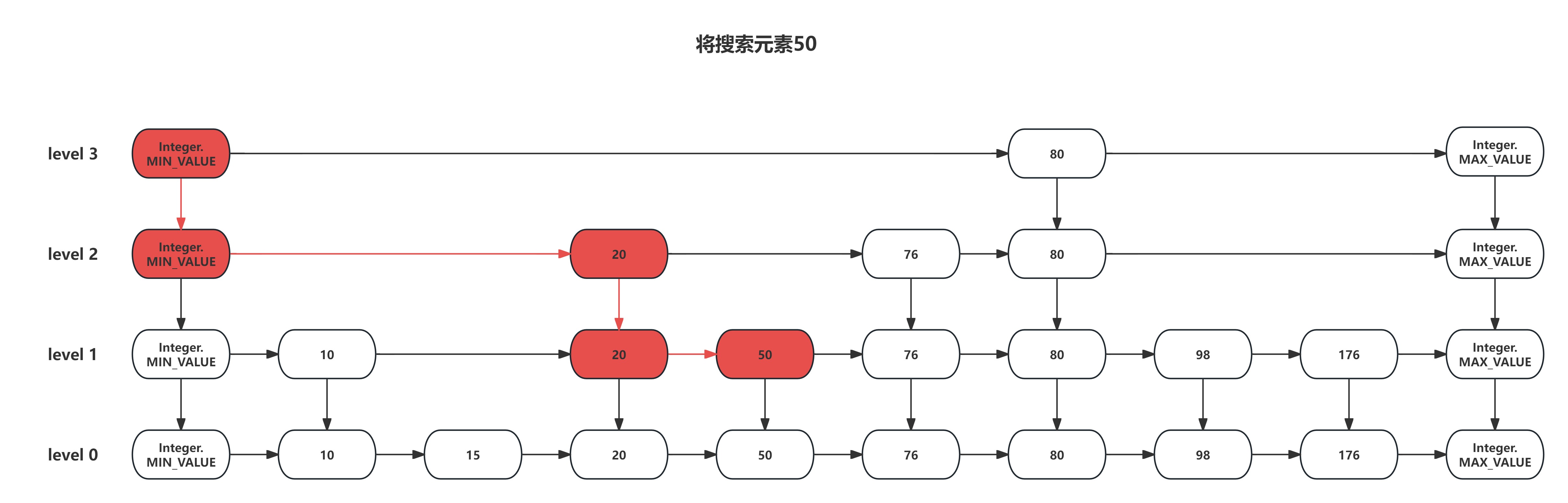
跳表的搜索代码如下所示:
public boolean search(int target) {SkiplistNode curNode = headNodes.getFirst();//从顶层开始寻找,curNode表示当前遍历到的节点while (curNode != null) {if (curNode.next.data == target) {return true;//从顶层开始寻找,curNode表示当前遍历到的节点} else if (curNode.next.data > target) {//curNode的后一节点值大于target,说明目标节点在curNode和curNode.next之间//此时需要向下层寻找curNode = curNode.down;} else {//curNode的后一节点值小于target,说明目标节点在curNode的后一节点的后面//此时在本层继续向后寻找curNode = curNode.next;}}return false;
}
SkipList的删除方法
当在跳表中需要删除一个元素时,则需要将这个元素在所有层的节点全部删除。首先按照跳表的搜索方式找到要删除的节点,如果可以找到,此时搜索到的节点对应要删除节点的最高层;从待删除节点的最高层往下,将每一层的待删除节点都删除掉,删除方式就是让待删除节点的前一节点直接指向待删除节点的后一节点。具体流程如下图所示:
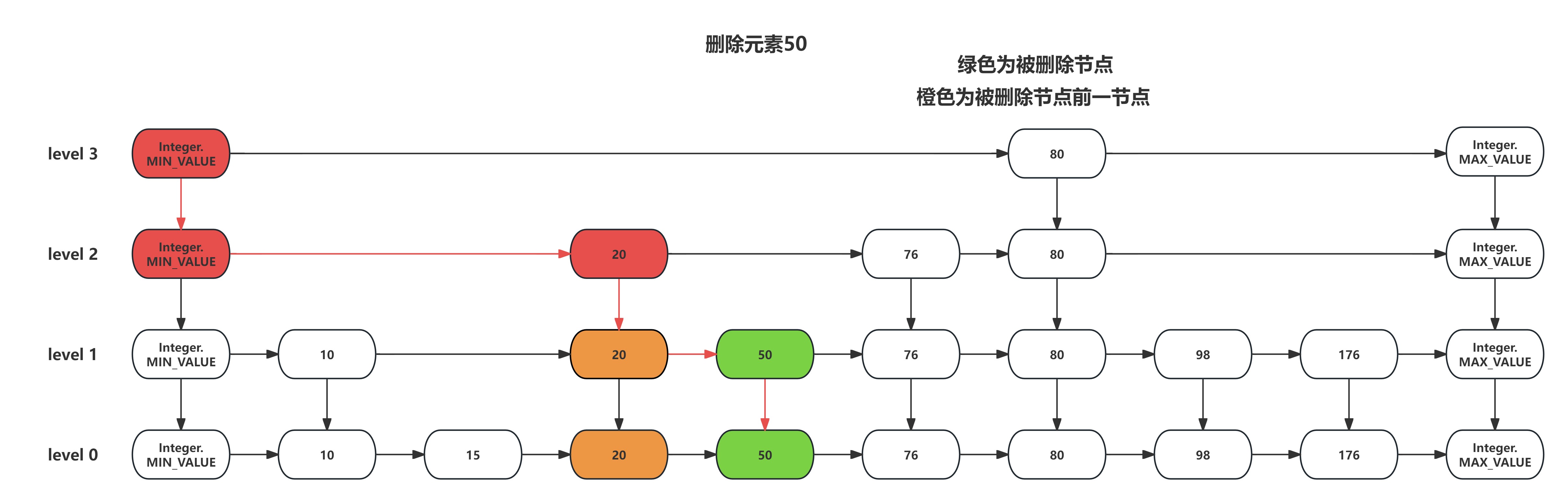
跳表的删除的相关代码如下所示:
public boolean erase(int num) {SkiplistNode curNode = headNodes.getFirst();//拿到level最高的头结点开始查询while (curNode != null) {if (curNode.next.data == num) {SkiplistNode preDeleteNode = curNode;//preDeleteNode表示待删除节点的前一节点while (true) {//删除当前层的待删除节点,就是让待删除节点的前一节点指向待删除节点的后一节点preDeleteNode.next = curNode.next.next;//当前层删除完后,需要继续删除下一层的待删除节点//这里让preDeleteNode向下移动一层//向下移动一层后,preDeleteNode就不一定是待删除节点的前一节点了preDeleteNode = preDeleteNode.down;//如果preDeleteNode为null,说明已经将底层的待删除节点删除了//此时就结束删除流程,并返回trueif (preDeleteNode == null) {return true;}//preDeleteNode向下移动一层后,需要继续从当前位置向后遍历//直到找到一个preDeleteNode,使得preDeleteNode.next的值等于目标值//此时preDeleteNode就又变成了待删除节点的前一节点while (preDeleteNode.next.data != num) {preDeleteNode = preDeleteNode.next;}}} else if (curNode.next.data > num) {curNode = curNode.down;} else {curNode = curNode.next;}}return false;
}关于跳表的增删查就讲到这里,大家有什么问题或者勘误可以在评论区留言,笔者看到都会回复的。