【Agent】MLGym: A New Framework and Benchmark for Advancing AI Research Agents
arxiv: https://arxiv.org/pdf/2502.14499
简介
Meta 推出的 MLGym 框架及配套基准 MLGym-Bench,为评估和开发LLM Agent在 AI 研究任务中的表现提供了全新工具。作为首个基于 Gym 的机器学习任务环境,MLGym 支持强化学习等算法对代理的训练,其模块化设计涵盖Agent、环境、数据集和任务四大核心组件,允许灵活集成新任务、模型、工具和Agent。MLGym-Bench 包含五类机器学习建模任务,共13个跨领域的开放式任务,覆盖数据科学、自然语言处理、计算机视觉、强化学习和博弈论方向。同时,对性能和开销进行了多维度评价。
AI Research Agents研究等级划分
文章中对AI Research Agents进行了六个等级的定义:
● Level 0 可复现: 对现有研究论文工作进行浮现。
● Level 1 改善基线: 在一个Benchmark给出一个基线代码,LLM Agent可以个改善性能。
● Level 2 达到SOTA: 在一个benchmark上金给出任务描述和可获取的公开文献且不为SOTA的方法,根据这些已有资料,实现出SOTA方法。
● Level 3 新的科学贡献: 在多个benchmark上达到SOTA,并且达到在顶级会议(NIPS、ML等)上发表的水平。
● Level 4 突破性科学贡献: LLM Agent可以发现关键研究问题、方向、解决方案并做令人瞩目的贡献,例如:获得best paper等。
● Level 5 长期研究议程: LLM Agent可以进行长期的研究,提出研究问题、方向和解决方案,并在数周、月或年内,不断产生新的科学发现。值得获得诺贝尔奖或者图灵奖的程度。
MLGym架构
该框架由四个核心组件组成:Agents、Environment、Datasets、Tasks
允许人们轻松得利用和扩展库,可以通过为Agent添加工具来扩展环境、在给定任务中添加数据集、在MLGym基准测试中添加更多任务。
Agent: 提供了一个环境和Agent分离的架构,允许用户去使用默认的Agent去测试不同的基座模型或者自己添加新的外部Agent进行测试。agent可以执行bash命令、可以获取工具集等。
Environment: 环境中是本地docker机器中的初始化的shell环境,允许使用需要的工具、安装python的依赖包、拷贝必要的环境、在独立的agent工作空间中编码和提供agent和系统之间的交互管理。
Datasets: 数据集和任务分离,一个数据集可对应多个任务,一个任务可对应多个数据集。数据集支持本地和hf下载。
Tasks: 每个任务可以包含一个或多个数据集、自定义评估脚本、特定任务的conda环境、可选的启动代码、训练超时和内存管理等,可定义不同困难度的各种开放式ml研究任务。可以自定义评估脚本和提交文件说明。
Tool 和 ACI(agent-computer interface):扩展了搜索,导航,文件查看器,文件编辑器和上下文管理与我们的权限管理系统的命令,并引入新的命令,文献检索和内存模块。当agent打开没有权限的文件时,会生成相应的反馈内容。

MLGym-Bench 基准任务
包含五大类,13个开放式AI研究任务。
数据科学
● 房价预测:使用Kaggle数据集,基于rmse和R2评估,基线为简单的Ridge回归。
● 3-SAT问题:优化DPLL算法的变量选择启发式,基于解决100个实例的时间评估。
博弈论
● 迭代囚徒困境:设计策略最大化与随机对手的长期收益,20 轮重复游戏。
● 性别大战:协调策略选择,20 轮重复游戏,对手基于最后一轮随机选择。
● Colonel Blotto 游戏:资源分配策略,对手使用简单随机分配规则。
计算机视觉
● CIFAR-10 图像分类:基线准确率 49.71%,优化模型架构和超参数。
● Fashion MNIST 图像分类:基线为两层 CNN,优化测试集准确率。
● MS-COCO 图像字幕生成:基于图像编码器 - 文本解码器基线,优化 BLEU 分数。
自然语言处理
● MNLI 自然语言推理:基于预训练 BERT 模型,优化微调策略和超参数。
● 语言建模:使用 FineWeb 数据集,基于 NanoGPT 基线,优化验证集困惑度。
强化学习
● MetaMaze 导航:网格世界环境,基于 Gymnax,基线为 PPO 算法。
● Mountain Car Continuous 控制:连续控制环境,优化策略以驱动汽车上山。
● Breakout MinAtar 游戏:Arcade 游戏环境,基于 Gymnax 评估平均分数。
评价指标
● 性能曲线(Performance Profiles)
○ 用于统一不同指标的性能衡量对比。定义方法 m 在任务 t 上的性能比:
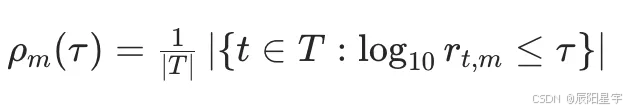
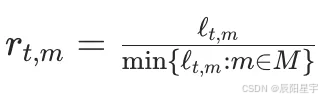
(1)
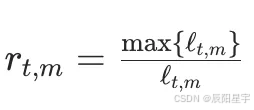
(2)
○ 性能曲线ρm(τ)表示方法 m 在 τ 阈值内的任务比例。其中M是所有方法的集合,P是任务集合, l t , m l_{t,m} lt,m是方法M在任务t上的性能度量, r t , m r_{t,m} rt,m是一个称为性能比率的量。
○ 适应不同指标方向(越高越好或越低越好),处理不可行方法。(1)中指标越小越好,例如:损失、困惑度等(2)中指标越大越好,例如:准确率、召回率等。
● AUP 分数(Area Under the Performance Profile):
○ 计算性能曲线下面积,衡量方法在多任务上的综合表现。定义性能曲线下的面积(Area Under the Performance Profile),量化方法的综合表现。
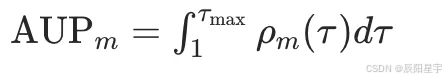
其中 τ m a x \tau_{max} τmax是使所有方法 ρ m ( τ ) = 1 \rho_m(\tau)=1 ρm(τ)=1的最小阈值。
● 两类评估维度:
○ 最佳提交(Best Submission@4):每个模型在 4 次独立运行中验证的最佳中间结果。
○ 最佳尝试(Best Attempt@4):每个模型在 4 次独立运行中最终提交的最佳结果。
● 不可行方法处理:
○ 若有代理未生成有效解或者未超越极限,标记为 infeasible ,设置分数为: ( 1 + ϵ ) × r t , b a s e l i n e ( ϵ = 0.05 ) (1+\epsilon) \times r_{t,baseline} (\epsilon=0.05) (1+ϵ)×rt,baseline(ϵ=0.05)
避免因部分任务失败导致评估是真,保证跨模型比较的公平性。