SQL查询效率以及索引设计
1. SQL 查询效率与数据库缓冲池机制
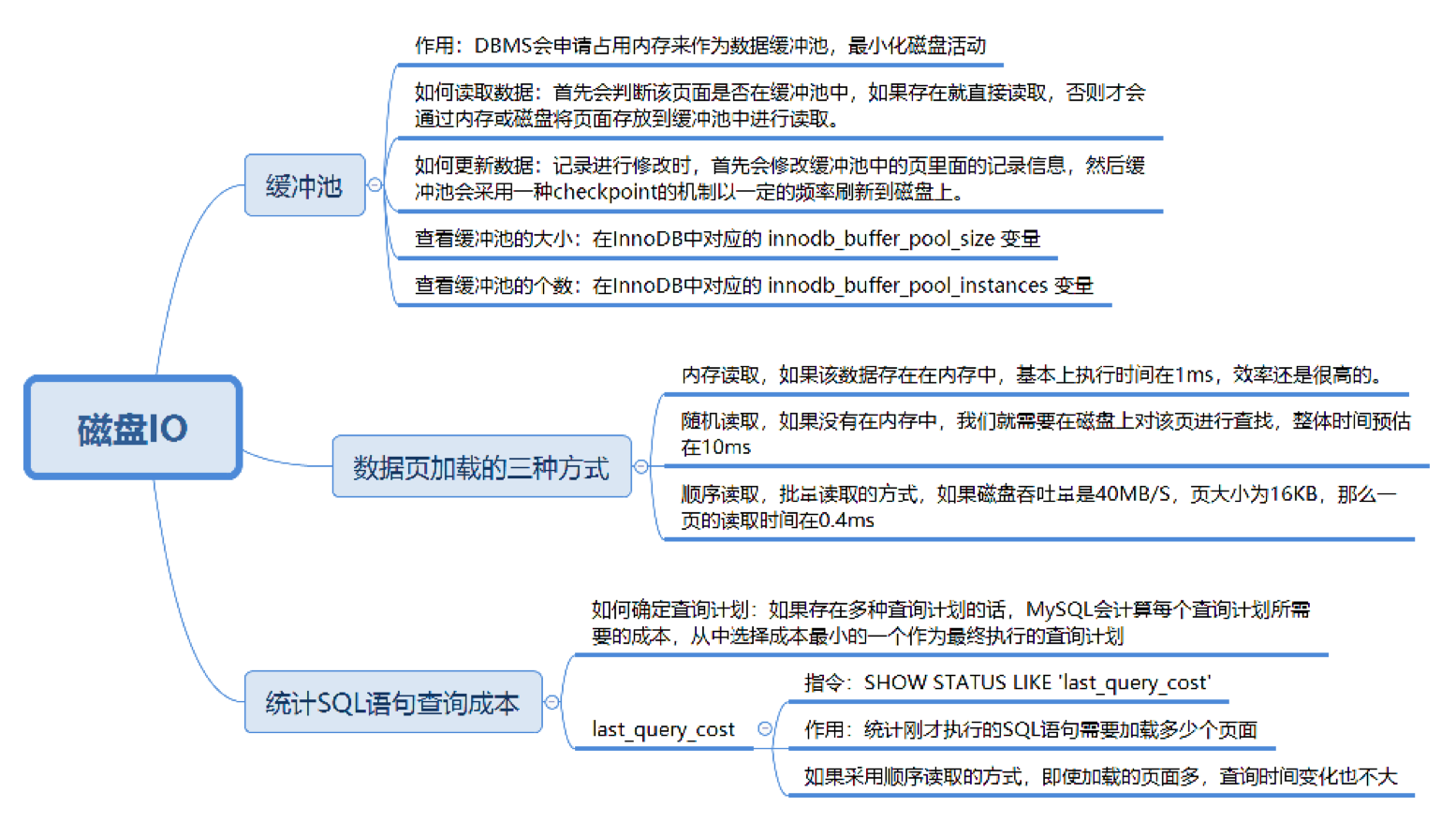
1.1. 数据库缓冲池(Buffer Pool)
磁盘 I/O 需要消耗的时间很多,而在内存中进行操作,效率则会高很多,为了能让数据表或者索引中的数据随时被我们所用,DBMS 会申请占用内存来作为数据缓冲池,这样做的好处是可以让磁盘活动最小化,从而减少与磁盘直接进行 I/O 的时间。
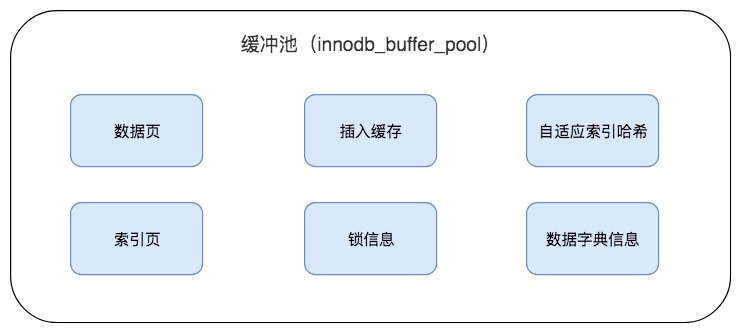
缓冲池的工作原理:
1. 数据库读取页时,先检查缓冲池是否有该页。
- 有 → 直接读取。
- 没有 → 从磁盘读取到缓冲池,再读取。
2. 对数据库中的记录进行修改:
修改数据时,先修改缓冲池中的页,然后延迟刷新到磁盘。
当我们对数据库中的记录进行修改的时候,首先会修改缓冲池中页里面的记录信息,然后数据库会以一定的频率刷新到磁盘上。注意并不是每次发生更新操作,都会立刻进行磁盘回写。缓冲池会采用一种叫做 checkpoint 的机制将数据回写到磁盘上,这样做的好处就是提升了数据库的整体性能。
3. 使用 checkpoint 机制 将“脏页(dirty page)”回写到磁盘:
- 脏页:缓冲池中已修改但尚未同步到磁盘的页。
- 回写时机:缓冲池不够用时、定时、事务提交等。
1.2. 查看缓冲池信息
1. 不同引擎的缓冲机制
- MyISAM 引擎:
只缓存索引,不缓存数据。
参数:key_buffer_size
- InnoDB 引擎:
缓存索引和数据。
参数:innodb_buffer_pool_size
2. 查看/设置缓冲池大小
查看:
SHOW VARIABLES LIKE 'innodb_buffer_pool_size';- 示例:8388608 bytes = 8MB
修改:
SET GLOBAL innodb_buffer_pool_size = 134217728; -- 设置为128MB3. 查看缓冲池实例数量
SHOW VARIABLES LIKE 'innodb_buffer_pool_instances';- 默认值为 8,但当
innodb_buffer_pool_size < 1GB时,实例数量强制为 1。 - 多个实例需要将缓冲池大小设置为 ≥ 1GB。
1.3. 数据页的三种加载方式
1. 内存读取
数据已存在内存中。
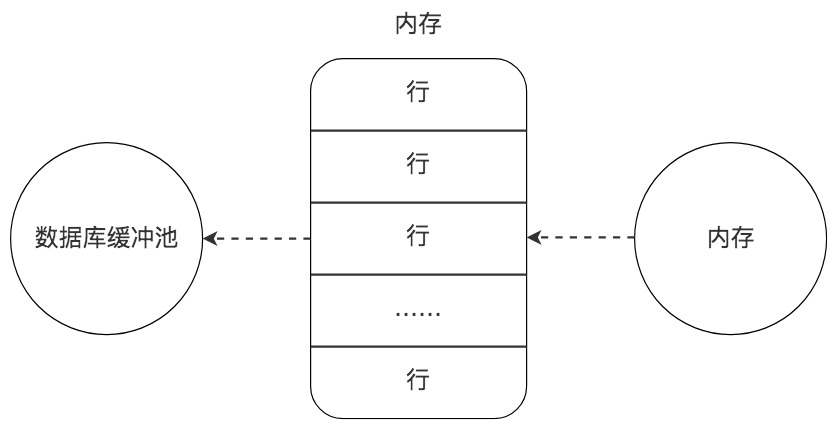
时间:≈1ms,效率最高。
1. 随机读取(磁盘)
数据不在内存中,从磁盘上随机读取页。
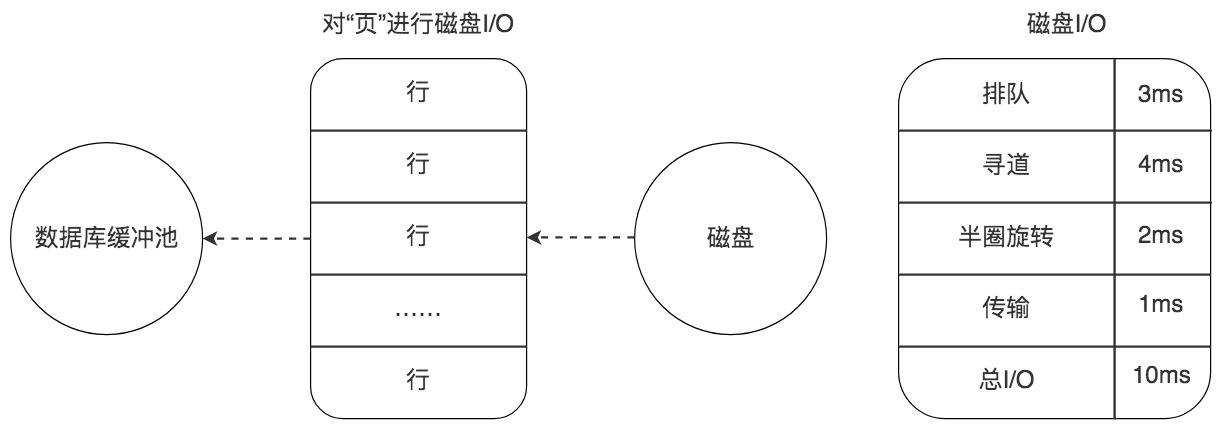
时间:≈10ms(包括寻道、旋转、排队、传输等)
效率较低。
2. 顺序读取(磁盘)
数据页在磁盘上相邻,采用批量加载方式。
时间:≈0.4ms/页(以40MB/s磁盘吞吐量计算)
效率可超过内存中的单页随机读取。
SQL 查询是一个动态的过程,从页加载的角度来看,可以得到以下两点结论:
3. 位置决定效率。
页在内存(缓冲池)中 → 查询效率最高。
页在磁盘中 → 查询需耗时进行 I/O 操作。
4. 批量决定效率。
单页随机读效率低。
顺序读取 + 批量加载 → 平均读页效率更高。
2. 设计索引
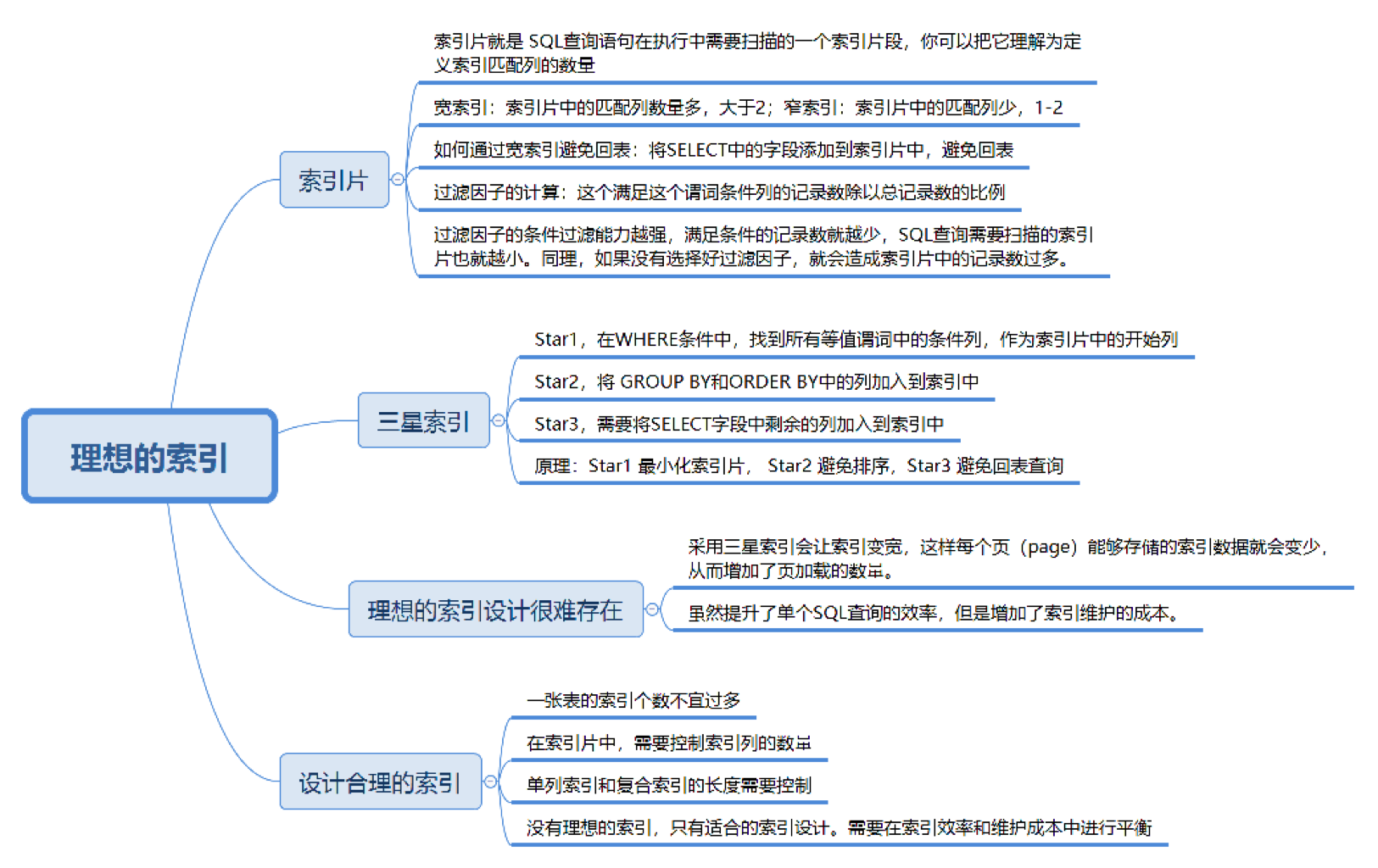
2.1. 索引片和过滤因子
- 索引片:SQL 查询中需要扫描的索引片段,根据包含的匹配列数,索引可以分为窄索引(1~2列)和宽索引(3列及以上)。
窄索引:减少索引访问开销。
宽索引:扫描更多的索引页,但可避免回表操作,提升查询效率。
- 回表:回表是通过索引查找到记录后,还需要使用主键再次查询数据表。宽索引可以避免这种回表操作。
- 过滤因子:描述谓词选择性的指标,衡量索引的筛选能力。过滤因子越高,满足条件的记录数越少,查询时扫描的索引片也就越小。
不好的过滤因子:例如,gender='male'(所有球员都是男性),team_id=1001(数据集中特定比例过高)。
好的过滤因子:例如,height=2.08,通过组合多个字段形成联合过滤因子,能更高效筛选记录。
2.2. 如何设计索引
三星索引:
一种理想的索引设计方法,旨在提高SQL查询效率,遵循以下三条原则:
- 在 WHERE 子句中的等值谓词条件列添加到索引片中。
- 将 GROUP BY 和 ORDER BY 中的列也加入到索引中,以避免
file sort。 - 将 SELECT 字段中的剩余列添加到索引片中,避免回表。
为什么理想的索引设计难以应用
- 索引宽度问题:三星索引会使索引片变宽,增加了页加载的数量,可能增加磁盘I/O操作。如果数据量巨大,索引可能占用大量空间,增加缓冲池的负担。
- 索引维护成本:过多的索引增加了插入、更新、删除操作的成本。每次修改数据时,需要更新所有相关索引,这可能导致性能下降。
-
- 举个例子:假设添加一条记录需要在10个索引中更新,时间消耗可能达到0.1秒。
设计索引的最佳实践
- 索引个数:一张表的索引数量不宜过多,过多的索引会增加插入、更新和删除的成本。需要定期检查索引的使用情况,删除不常用的索引。
- 复合索引:当需要新建索引时,可以考虑在已有的索引基础上增加字段,采用复合索引而不是新建单独索引。
- 索引列数量:尽量将 WHERE 条件中的列加入索引中,SELECT 中的非条件列一般不需要加入索引,除非这些列常常被查询。
- 单列索引与复合索引长度控制:
MySQL InnoDB 默认索引长度最大为 767 字节,超过此限制会采用前缀索引。
字符类型字段的索引:字符类型字段占用较多空间,建议用数值类型代替字符类型做主键,字符字段做前缀索引。
总结
- 理想索引:三星索引是一种理想的索引设计方案,但实际应用中需要考虑索引的宽度、索引维护成本等因素,过多索引会增加系统负担。
- 权衡:在设计索引时,需要在查询效率和索引维护成本之间做出平衡,避免过多的宽索引导致性能瓶颈。
- 复合索引和单列索引:当有多个条件时,使用复合索引来减少扫描的索引片,提升查询效率。