CNN vs ViT:图像世界的范式演进
一、图像建模,是不是也可以“大一统”
在前文中我们提到,多模态大模型打破“只能处理文字”的限制。
在 NLP 世界里,Transformer 已经证明自己是理解语言的王者。那么在图像世界,我们是否也能有一种“通用架构”,让模型像“理解语言”一样理解图像呢?
这篇文章,我们同样从开发者熟悉的角度,讲清楚 CNN 和 ViT 的核心原理与区别,以及为什么 ViT 被称为“视觉的 BERT”,开启了图像建模的新时代。
二、图像是怎么被“看懂”的?——介绍 CNN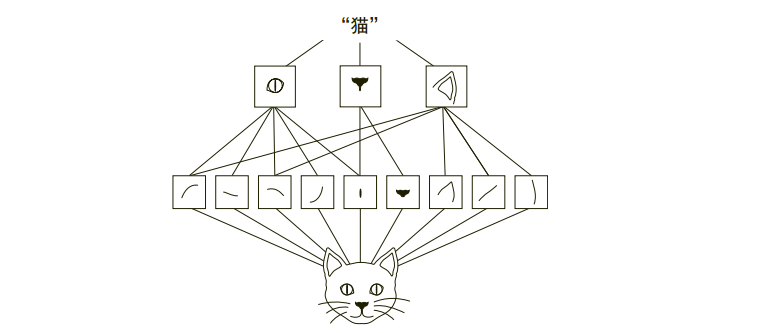
想象你正在处理一张图片,比如一张猫的照片。你不是用人眼看,而是交给一个“滤镜系统”处理。
这时候,卷积核就像是一组特定用途的图像滤镜,比如:
-
有些滤镜专门“强调边缘”;
-
有些滤镜“只在看到竖线时有反应”;
-
有些滤镜“喜欢曲线”或“角落状的区域”;
当你用这些滤镜一层层地扫描整张猫图时(如上图):
-
第一层滤镜可能捕捉到了猫耳朵的轮廓、胡须的线条、眼睛的对比边缘;
-
第二层把这些低级特征组合起来,形成“猫眼睛”或“猫耳朵区域”的高级特征;
-
更深的层能捕捉出“这可能是一只猫”的抽象概念。
这个过程可以理解成是Conv2D和MaxPooling2D的堆叠。
从优缺点上来看,CNN非常高效,部署成熟,以及“平移不变性”和“局部性”的特性,所以数据量不大也能训练出不错的模型。
但它也有明显局限:
-
缺乏全局建模能力,无法直接理解图像中远距离的元素之间的关系(比如“天空”和“地面”的相对位置)
-
架构复杂且难统一,不同任务需要设计不同网络结构(ResNet、EfficientNet 等)
三、ViT 的崛起:把图像变成 Token,统一进 Transformer
那有没有一种架构,既能保留 CNN 的特征提取能力,又能拥有更强的全局建模能力?
2020 年,Google 提出了 Vision Transformer(ViT),提出了一个惊人的想法:
图像也可以像句子一样,切分为 Token,然后直接输入 Transformer。
如上图,Transformer中一个重要特性是注意力机制(self-attention),当前token跟其他每个token计算重要程度。远距离也可以很好捕捉。
Bert、ChatGPT等现在主流的模型都是用到Transformer架构,那架构上也实现了统一。
四、ViT如何实现分词
之前文章中,我们讲到文本首先要“分词”,更专业称呼为Tokenization。
那ViT是如何实现tokenizer的呢?——切成一个个patch
如下面九宫格,将原始图片分成的一个一个patch。而每个patch,等同于自然语言中的token。

原始图片

九宫格

铺平
针对这个“九宫格”进行铺平,就变成了自然语言中长度为9的概念。
五、ViT 的意义:视觉也能加入“大模型俱乐部”
ViT 的真正意义在于:它让图像建模也走向 Transformer 范式,从而进入大模型时代。
有了 ViT,我们可以:
-
把图像和文本一起作为 token 输入 Transformer,实现图文统一理解
-
用文本 prompt 控制视觉模型,发展多模态交互(LLaVA)
-
将视觉编码结果作为语言模型的提示,让模型“看图说话”(Qwen-VL)
这些技术的基础,都是 ViT 将图像表示 token 化,并送入 Transformer 架构的能力。
六、总结
本篇粗略介绍了CNN和ViT这种更通用的“图像语言处理器”,即图像也能像语言一样,被统一处理。
后面,我们从更多案例出发,打下更多的认知基础。