大语言模型 10 - 从0开始训练GPT 0.25B参数量 补充知识之模型架构 MoE、ReLU、FFN、MixFFN
写在前面
GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,包括数据收集、预处理、模型设计、训练策略、优化技巧以及后训练阶段(微调、对齐)等环节。
我们将先对 GPT 的训练方案进行一个简述,接着我们将借助 MiniMind 的项目,来完成我们自己的 GPT 的训练。
训练阶段概览
GPT 的训练过程大致分为以下几个阶段:
- 数据准备(Data Preparation)
- 预训练(Pretraining)
- 指令微调(Instruction Tuning)
- 对齐阶段(Alignment via RLHF 或 DPO)
- 推理部署(Inference & Serving)

简单介绍
过去两年,大语言模型(LLM)在实践中几乎清一色采用 Decoder-Only Transformer。与此同时,社区又陆续把 LayerNorm 换成 RMSNorm、把 ReLU/GELU 换成 SwiGLU,甚至在前向网络里引入 MoE / MixFFN 等稀疏或卷积混合结构。理解这些改动背后的设计动机,有助于你在 模型微调、推理加速或重新发明“更小更强”模型 时做出正确的工程权衡。
模型架构
MiniMind-Dense(和Llama3.1一样)使用了Transformer的Decoder-Only结构,跟GPT-3的区别在于:
● 采用了GPT-3的预标准化方法,也就是在每个Transformer子层的输入上进行归一化,而不是在输出上。具体来说,使用的是RMSNorm归一化函数。
● 用SwiGLU激活函数替代了ReLU,这样做是为了提高性能。
● 像GPT-Neo一样,去掉了绝对位置嵌入,改用了旋转位置嵌入(RoPE),这样在处理超出训练长度的推理时效果更好。
MiniMind-MoE模型,它的结构基于Llama3和Deepseek-V2/3中的MixFFN混合专家模块。
● DeepSeek-V2在前馈网络(FFN)方面,采用了更细粒度的专家分割和共享的专家隔离技术,以提高Experts的效果。
MiniMind的整体结构一致,只是在RoPE计算、推理函数和FFN层的代码上做了一些小调整。 其结构如下图(重绘版):
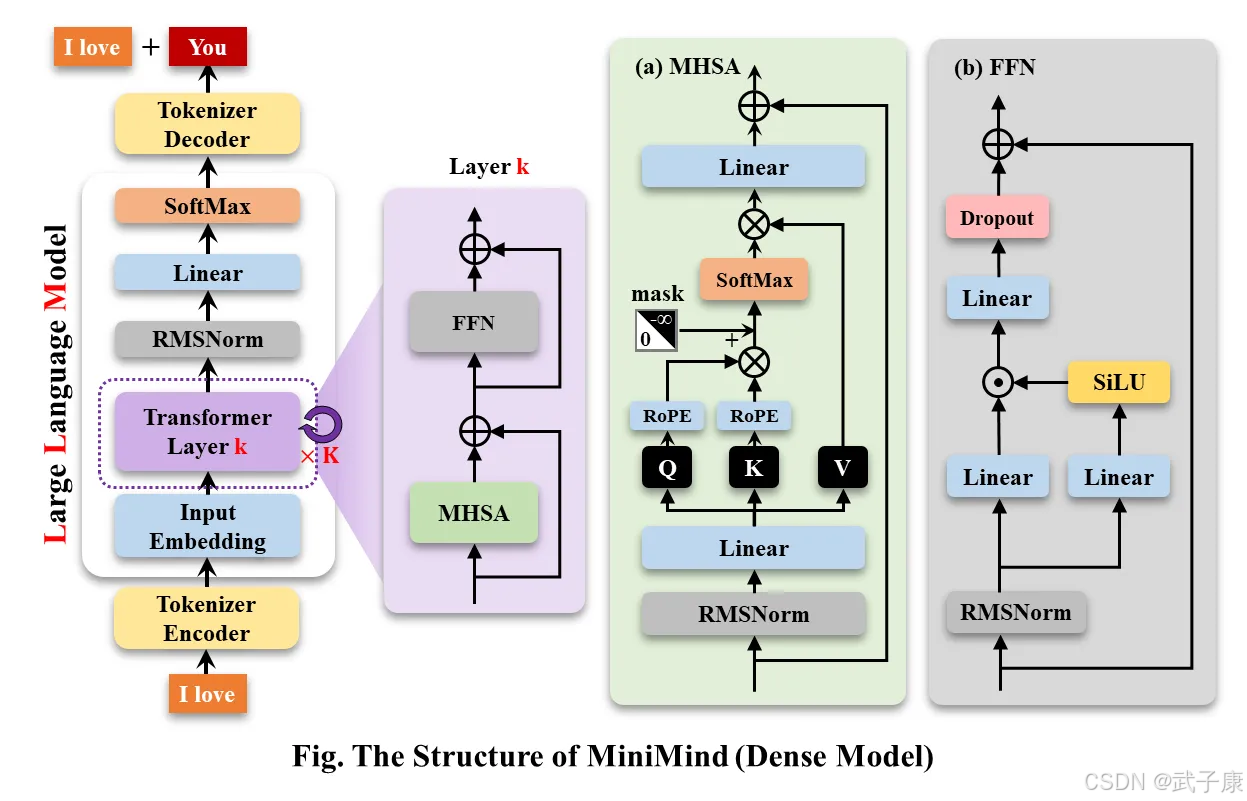
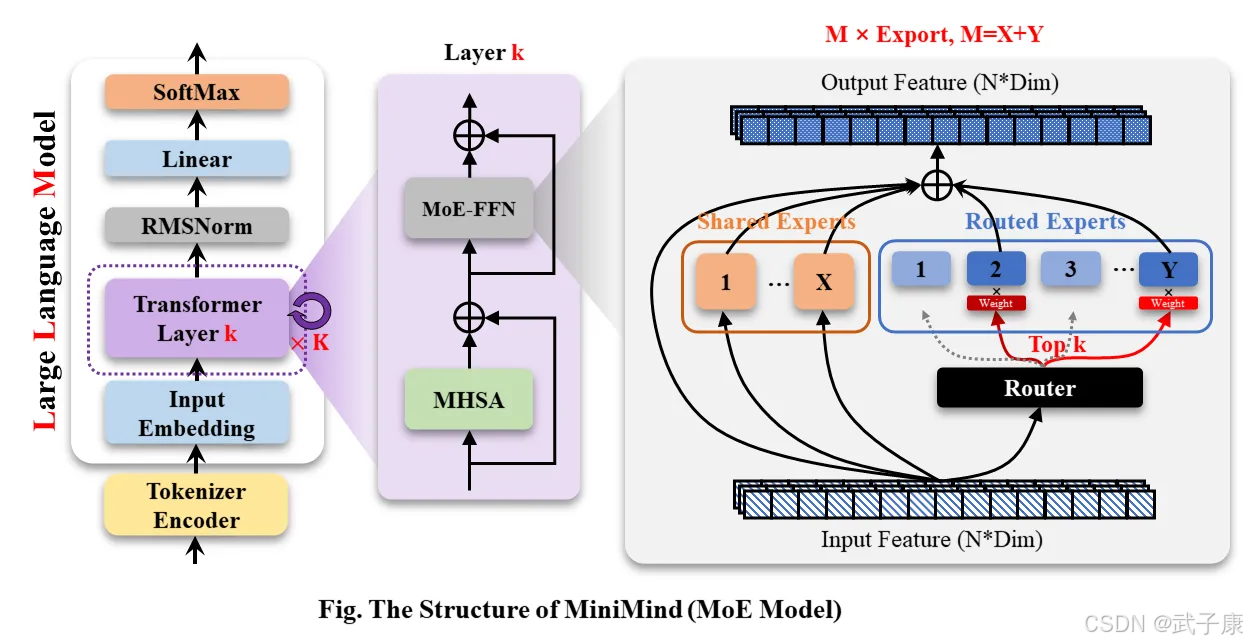
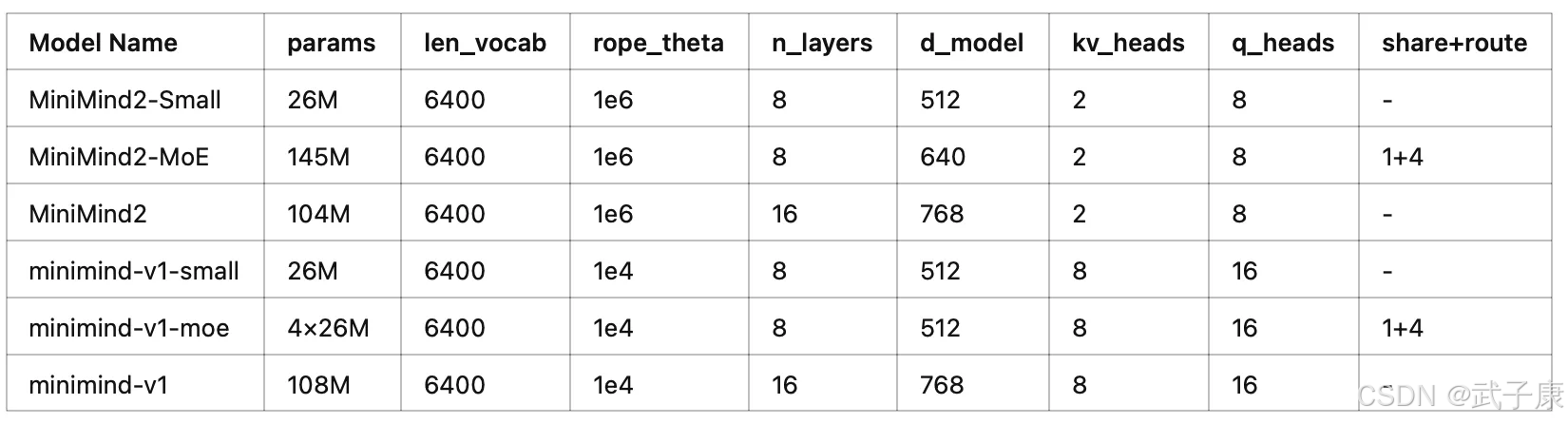
修改模型配置见./model/LMConfig.py。 参考模型参数版本见下表:
Decoder-Only Transformer

Decoder-Only 去掉了原始 Transformer 的 Encoder,改用 因果掩码 + KV-缓存 即可在推理时做到 O(1) 序列延长成本。因此 GPT-3、LLaMA、Gemini 乃至文本-图像多模态模型都选择了它。
decoder-only-transformers-explained-the-engine-behind-llms
FFN
经典 FFN = Linear(d_model → d_ff) + 激活 + Linear(d_ff → d_model),其中
d_ff≈4·d_model,激活函数最早用 ReLU。FFN 占据 >60 % FLOPs & 参数量,因此它也是改进热点。
ReLU vs SwiGLU
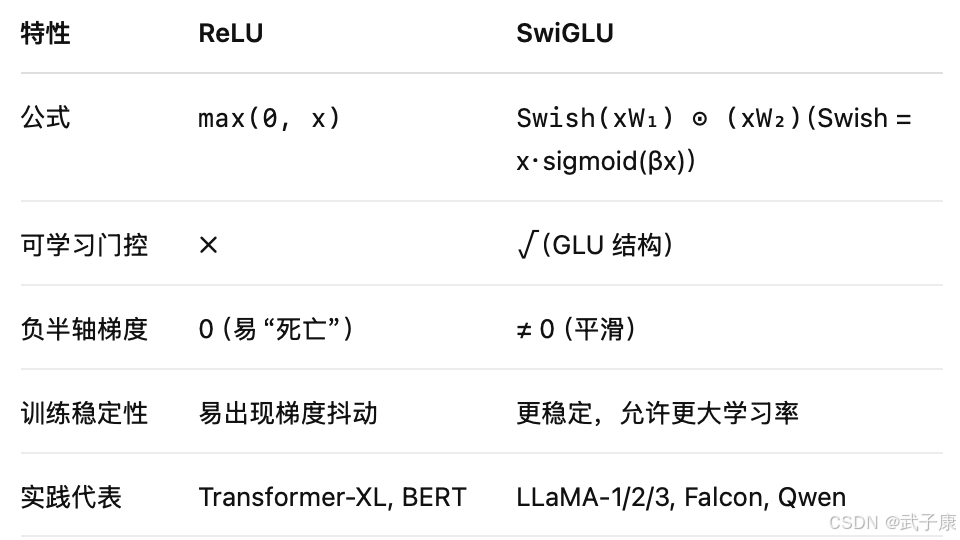
实验证明,等价参数量下 SwiGLU 能带来 0.3 ~ 0.6 token perplexity 改进,且推理成本几乎不变。
RMSNorm
公式:y = x / RMS(x) · γ,其中 RMS(x)=sqrt(mean(x²))
- 省略中心化 → 参数更少,FLOPs 与内存带宽-读写减半
- 训练稳定性 在 Pre-Norm 框架中与 LayerNorm 等价;实测可 缩短 1 ~ 10 % 训练时间
- 兼容大批量 / 低精度 适合 GPU / TPU 混合精度
NeurIPS-23 的对比研究正式证明:Pre-LN 与 Pre-RMSNorm 在数学上可互换,并提出进一步压缩的 CRMSNorm。
MoE & MixFFN
MoE
思路:为每个 token 只激活少数“专家”FFN,计算成本与密集模型相当但可容纳 亿 / 万亿级参数
- 核心模块: ① 稀疏门控(Top-k 或 Router),② 专家簇(通常 k=2,4,8…)
- 代表模型:Switch-Transformer、GLaM、Mixtral-8x7B
优缺点:
- 参数利用率高,训练加速可达 7 × (相同 FLOPs)
- 通讯/负载均衡难度大,推理需要“容量因子”调度
MixFFN
- 在两层 MLP 中插入 3 × 3 Depthwise Conv,融合 局部感受野 与 全局 MLP
- 位置编码可选/可省,分辨率外推更稳
- 语言模型可类比引入 (Conv or) LoRA-Adapter 获得额外局部建模能力
小小总结
- Decoder-Only 让语言生成模型推理线性伸缩;
- RMSNorm 与 SwiGLU 分别在归一化与激活层面消除冗余、提升可训练性;
- MoE / MixFFN 代表 FFN 的两条进化路线:一条追求 参数稀疏 & 超大模型,一条追求 局部感知 & 多模态。