elasticsearch查询操作(DSL语句方式)
说明:本文介绍在kibana,es的可视化界面上对文档的查询操作;
添加数据
先使用API,创建索引库,并且把数据从MySQL中查出来,传到ES上,参考(http://t.csdn.cn/NaTHg)
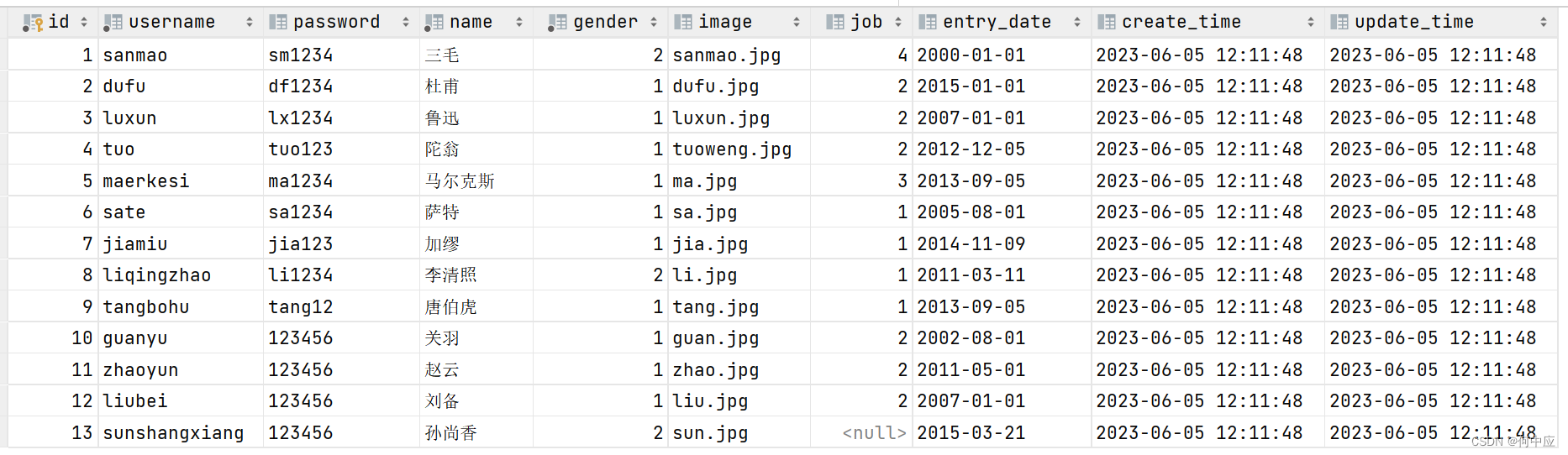
索引库(student)结构;
1、模糊查询
模糊查询,是指字段类型是“text”,参与分词的字段,如name、all字段;
(1)全部查询;
格式:
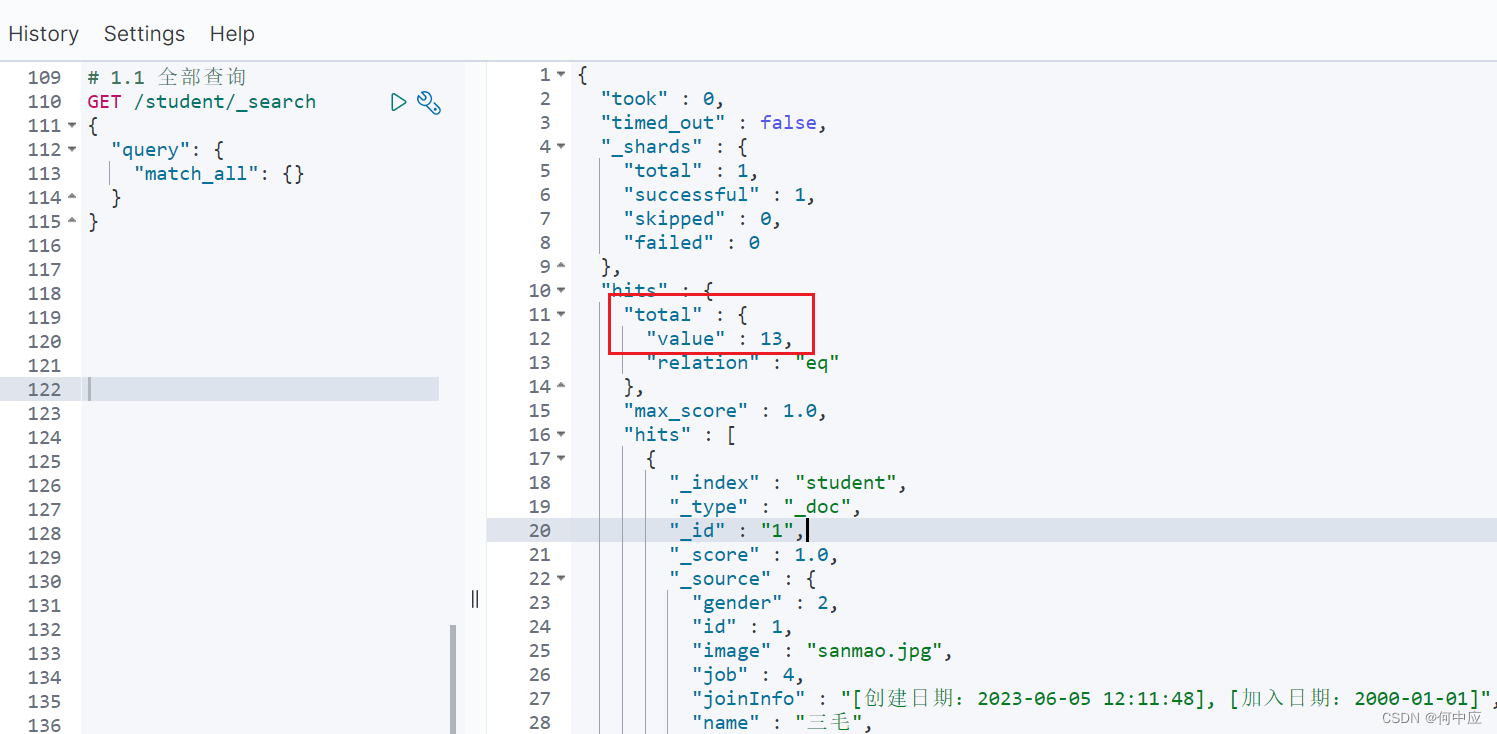
# 1.1 全部查询
GET /索引库名/_search
{"query": {"match_all": {}}
}
可以看到,13条文档都查询出来了;
(2)单字段查询;
格式:
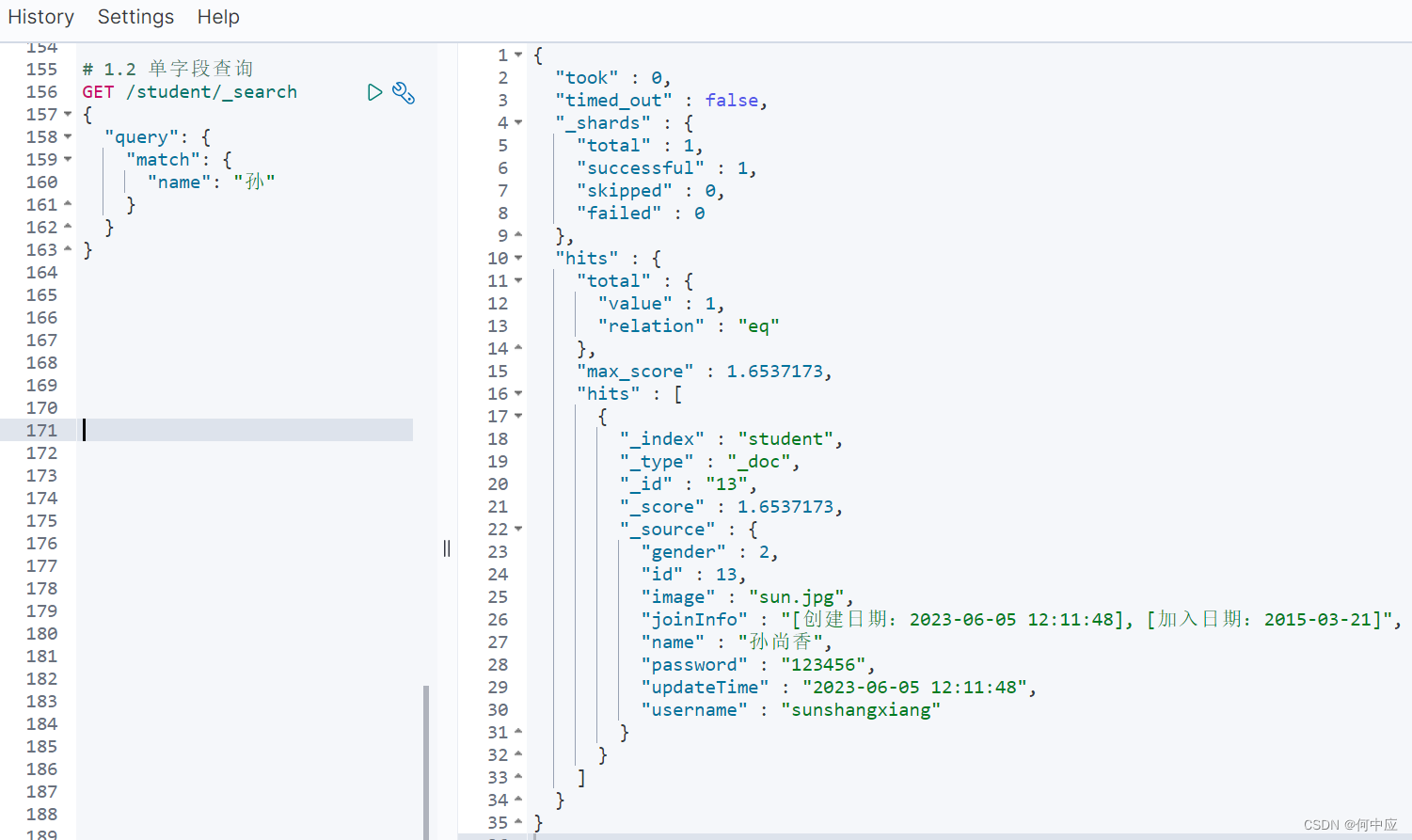
# 1.2 单字段查询
GET /索引库名/_search
{"query": {"match": {"字段名": "字段值"}}
}
查询结果:
(3)多字段查询;
格式:
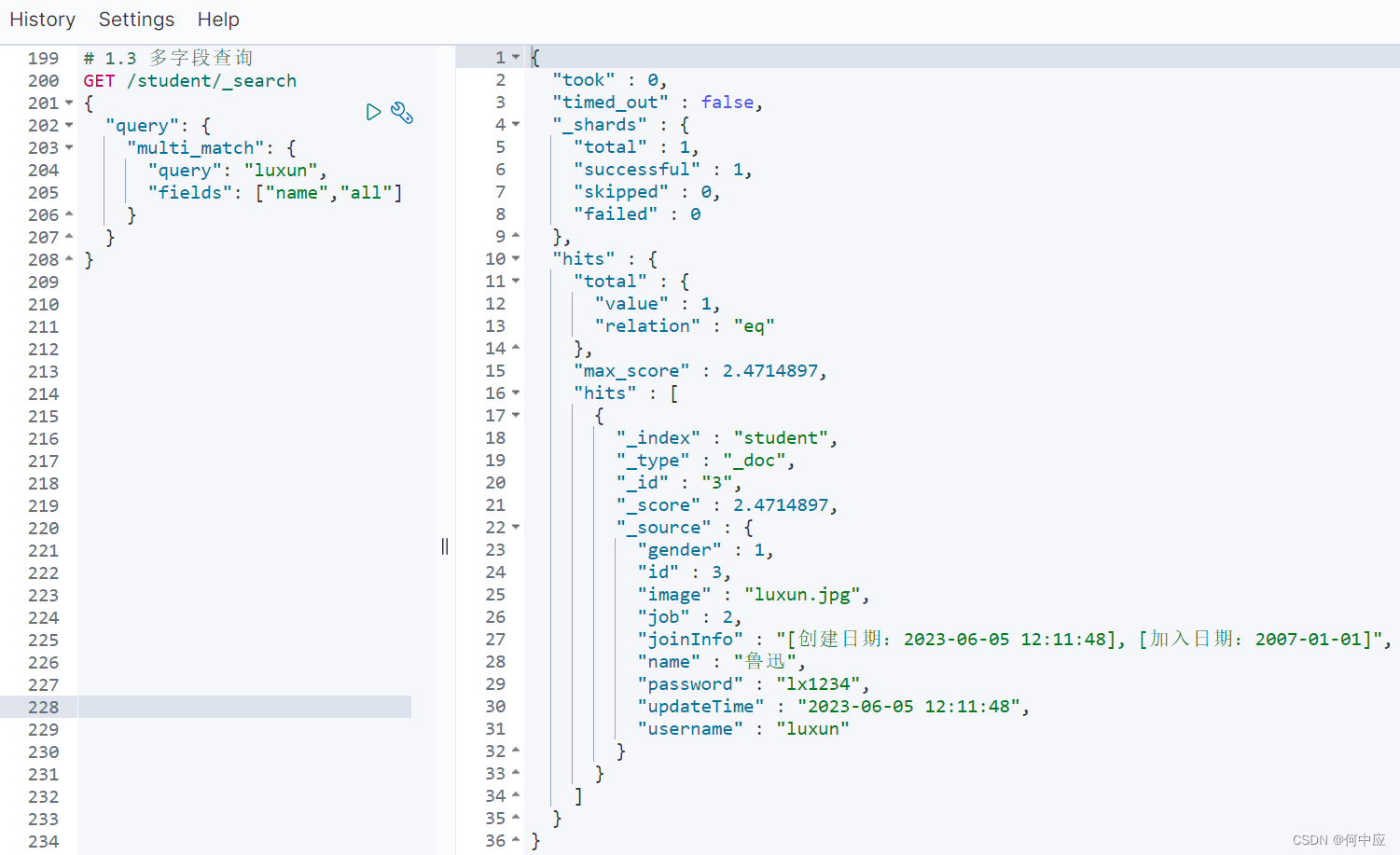
# 1.3 多字段查询
GET /索引库名/_search
{"query": {"multi_match": {"query": "字段值","fields": ["字段名1","字段名2"]}}
}
查询结果:
2、精确查询
精确查询,用于等值判断的文档,即查询的值等于文档中对应字段的值,有两种,分别是term、range;
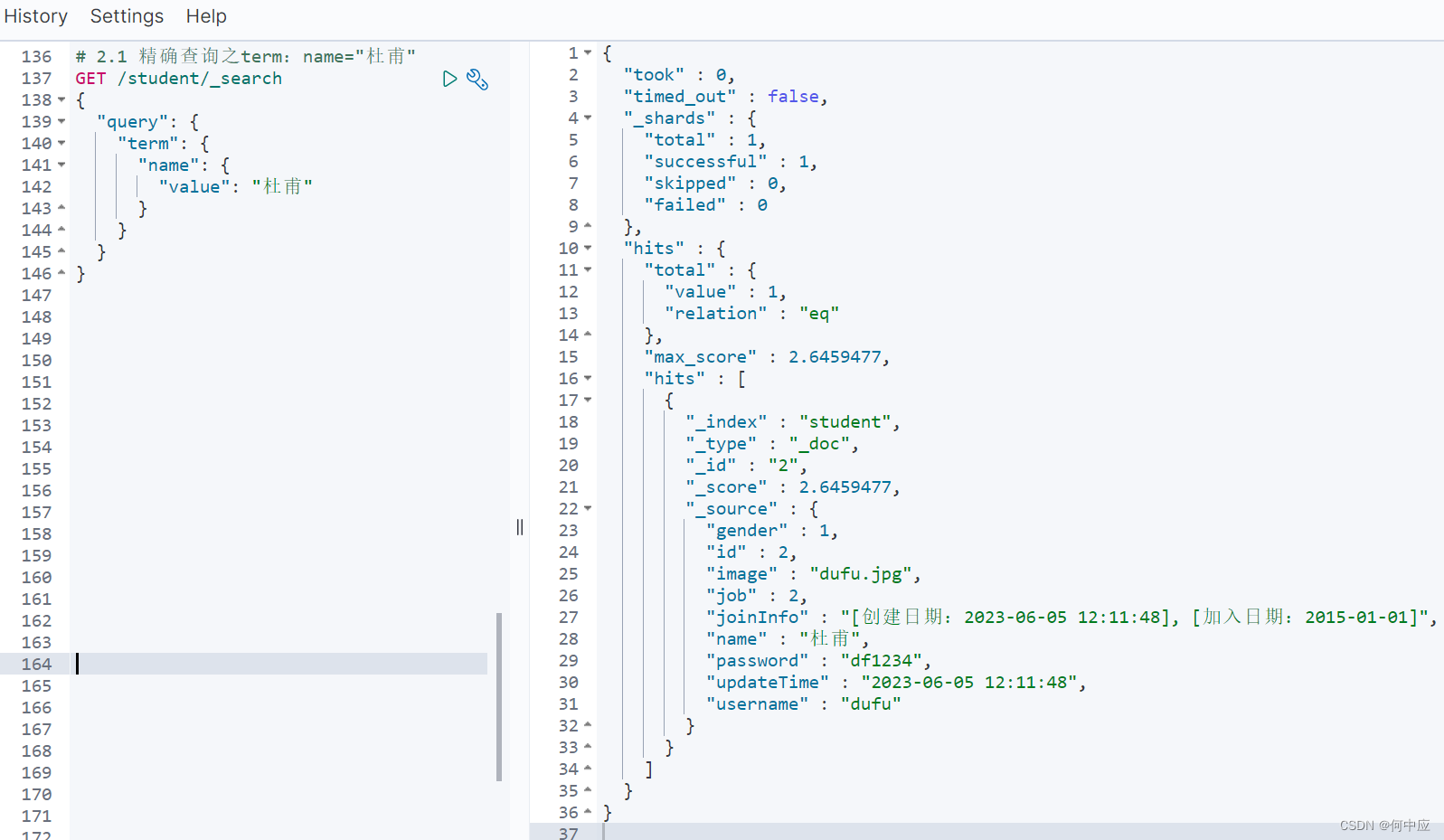
(1)term查询;
格式:
GET /索引库/_search
{"query": {"term": {"字段名": {"value": "字段值"}}}
}
查询结果:
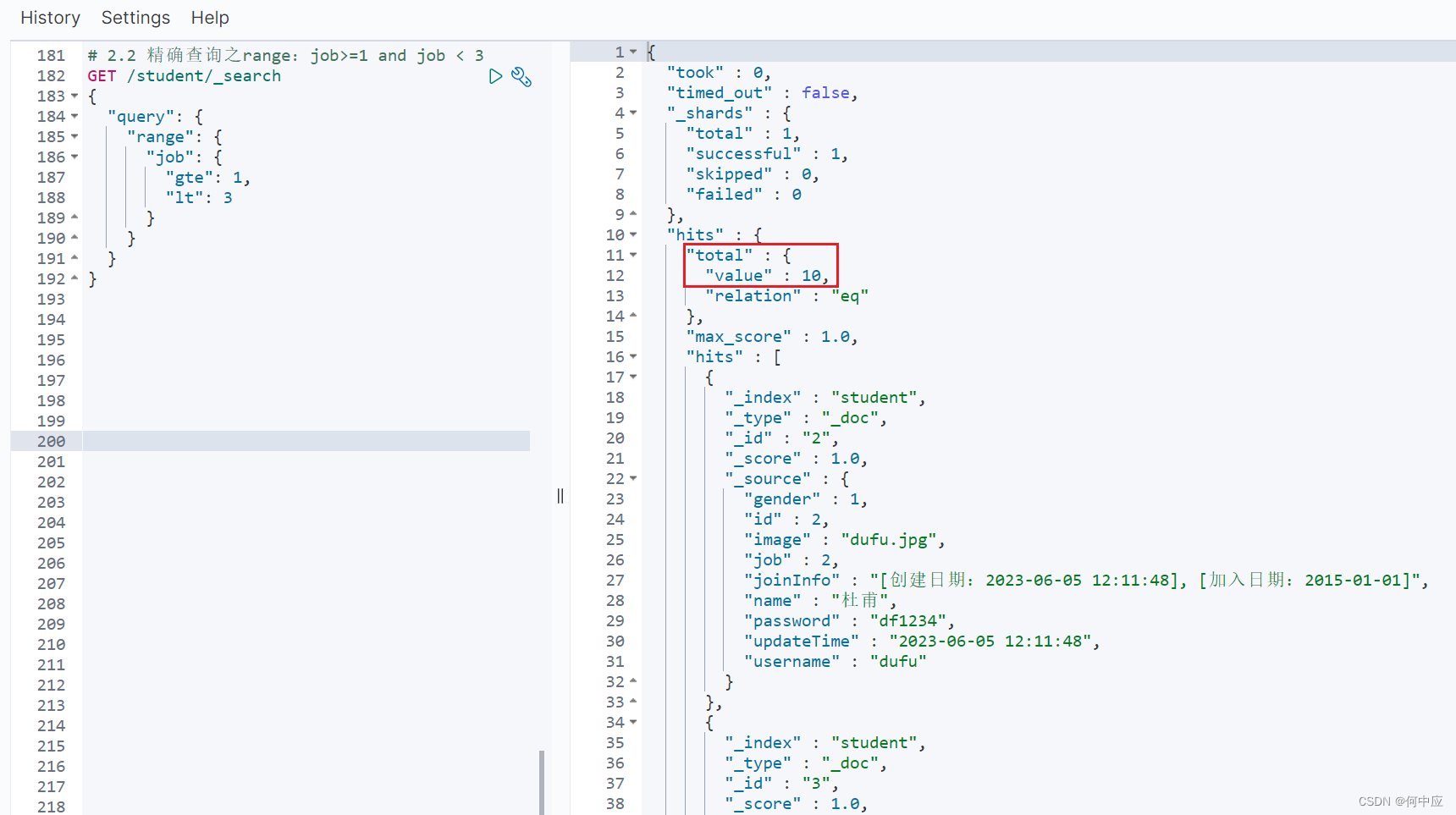
(2)range查询;
格式:
# 2.2 精确查询之range:job>=1 and job < 3
GET /索引库名/_search
{"query": {"range": {"字段名": {"gte": 字段值≥,"lt": 字段值<}}}
}
查询结果:
3、地理坐标查询
es提供了地理坐标数据类型(如geo_point),如果文档中有由经纬度组成的位置数据,可以针对文档中的经纬度坐标查询,有两种方式:
(1)矩形范围;
根据提供的两个位置,画出一个矩形,查询位置在这个矩形内的文档;
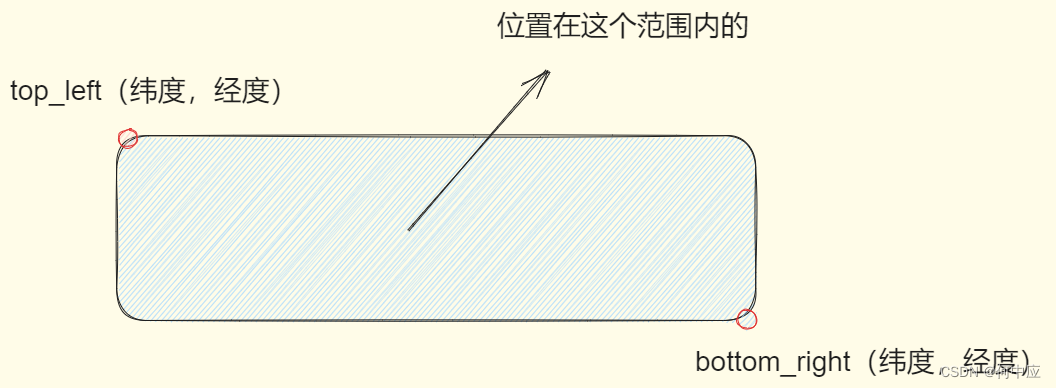
格式:
GET /索引库名/_search
{"query": {"geo_bounding_box":{"location":{"top_left":{"lat":左上角位置纬度,"lon":左上角位置经度},"bottom_right":{"lat":右下角位置纬度,"lon":右下角位置经度}}}}
}
(2)方圆范围;
根据提供的一个位置,一个距离,以位置为圆心,距离为半径,查询该位置方圆范围的文档;
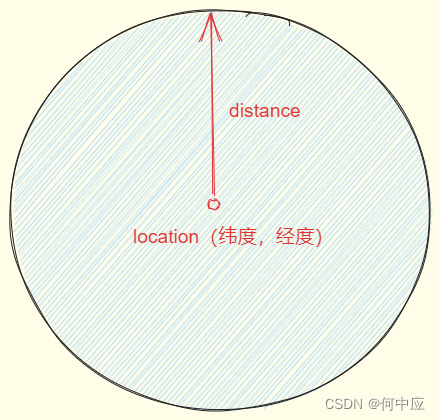
格式:
# 3.2 地理查询值geo_distance
GET /索引库名/_search
{"query": {"geo_distance":{"distance":"距离","location":"纬度,经度"}}
}
距离可以可以写任意长度单位,如15km,15000m;
4、复合查询
(1)算分查询;
查询的每条文档都会有一个分值,这个分值是ES根据BM25公式计算得出的,查询结果会按照分值从高到低排序,我们可以根据文档中的条件,来手动调整该分值,使分值高的文档排在最前面;
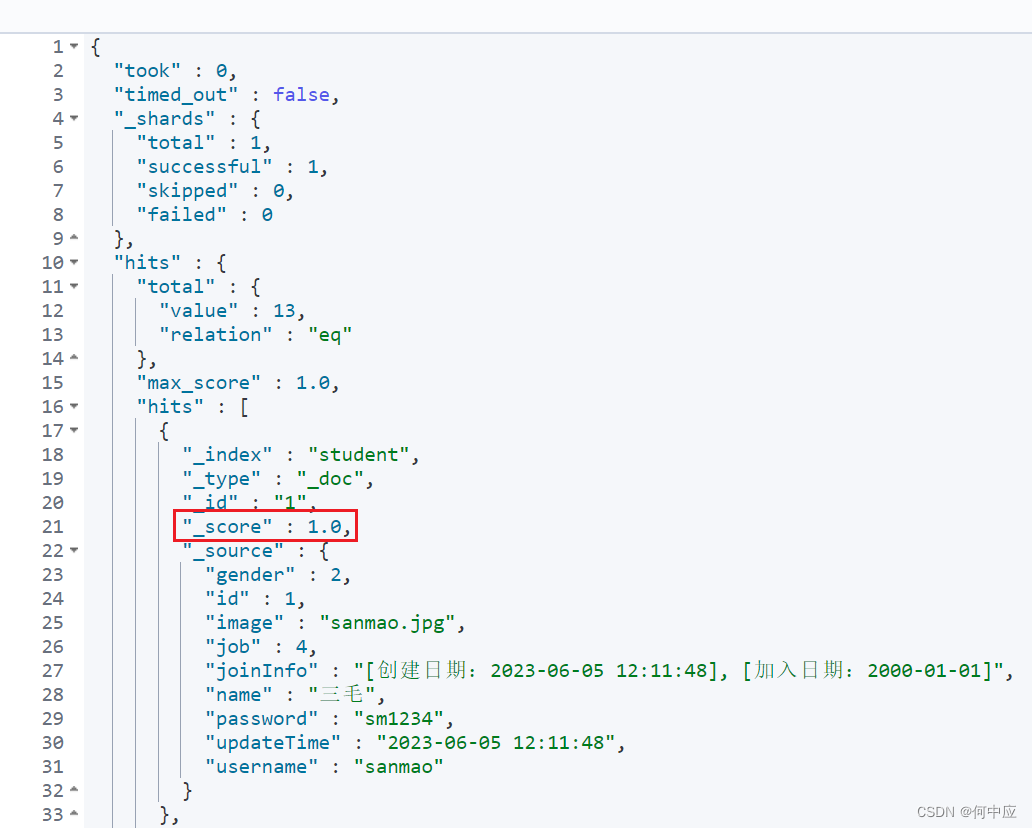
比如,我们把ID为13的文档,手动修改分值,使其排在最前面;
格式:
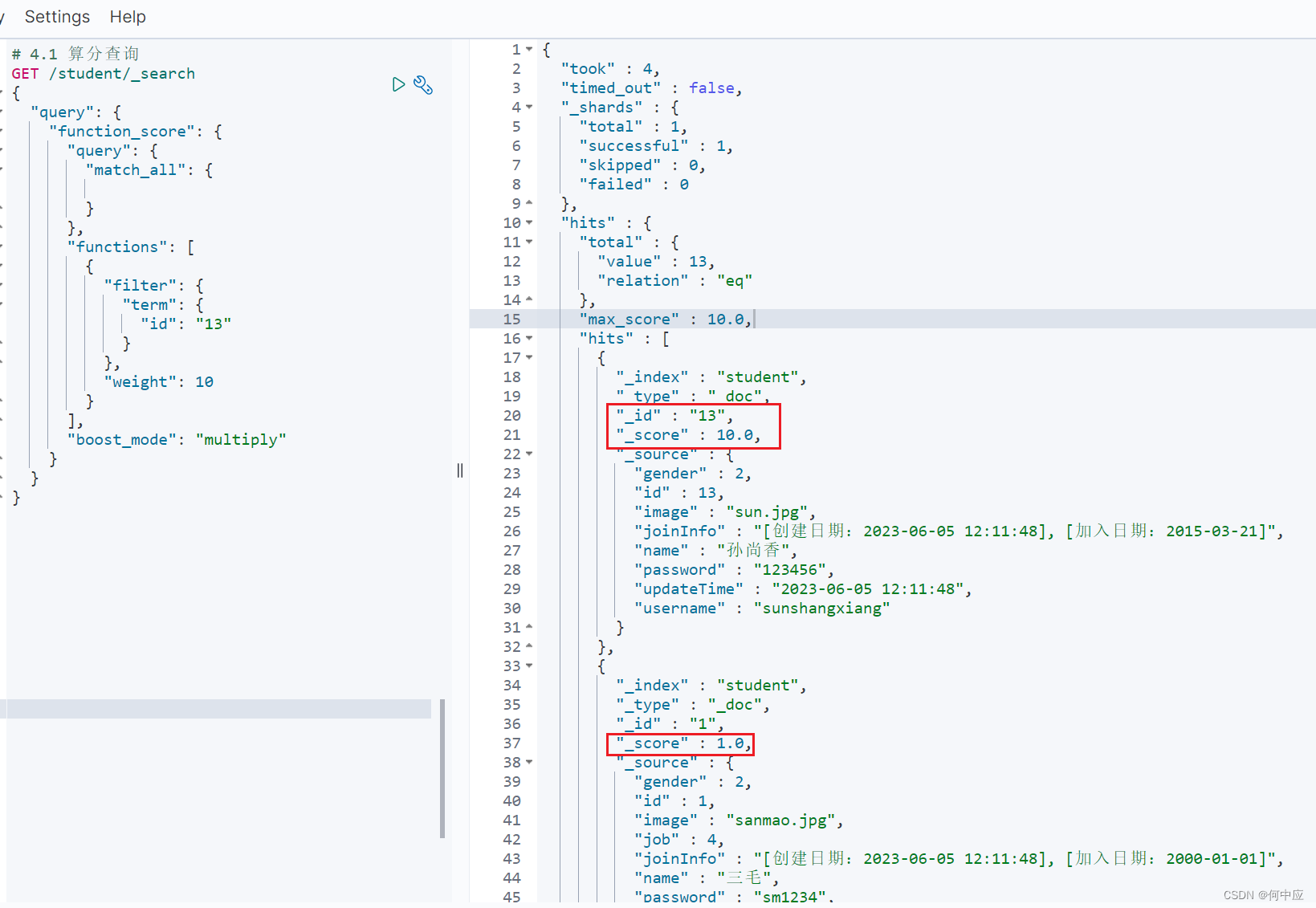
# 4.1 算分查询
GET /student/_search
{"query": {"function_score": {"query": {# 查询"match_all": {}},"functions": [{"filter": {# 过滤"term": {"id": "13"}},# 设置权重"weight": 10}],# 加权模式,即最终分值 = 查询分值 ? 权重的运算符,multiply为乘"boost_mode": "multiply"}}
}
boost_mode常见的有multiply(乘),sum(加),replace(替换,即使用权重替换掉查询分值);
(2)布尔查询;
布尔查询也叫复合查询,指多条件的查询,该查询下有以下四个子查询,可根据实际需要添加:
-
must:必须匹配的子查询,类似“与”;
-
should:选择性匹配子查询,类似“或”;
-
must_not:必须不匹配,不参与算分,类似“非”;
-
filter:必须匹配,不参与算分;
如查询性别为“1”,job不在(2,4]区间内,id为11的文档,all字段可以为123456,DSL语句如下:
# 4.2 布尔查询
GET /student/_search
{"query": {"bool": {# 必须匹配的子查询"must": [{"match": {"gender": "1"}}],# 必须不能匹配的子查询"must_not": [{"range": {"job": {"gt": 2,"lte": 4}}}],# 可以匹配的子查询"should": [{"match": {"all": "123456"}}],# 必须匹配的子查询"filter": [{"term": {"id": "11"}}]}}
}
must、should参与算分,即分值高低决定排序前后顺序;
must_not、filter不参与算分,分值高低无所谓;
5、排序
(1)按位置排序
如果文档字段中有位置/坐标相关的字段,可将查询结果按照位置排序,距离越近排序越靠前;
表示按照提供的位置,距离该位置越近,排序越靠前,当然这取决于order是不是升序(asc);
# 5.1 按照坐标排序
GET /索引库名/_search
{"query": {"match_all": {}}, "sort": [{"_geo_distance": {# 文档中位置相关的字段名、字段值"字段名": {"lat": 纬度,"lon": 经度},# 升序"order": "asc",# 距离单位"unit": "km"}}]
}
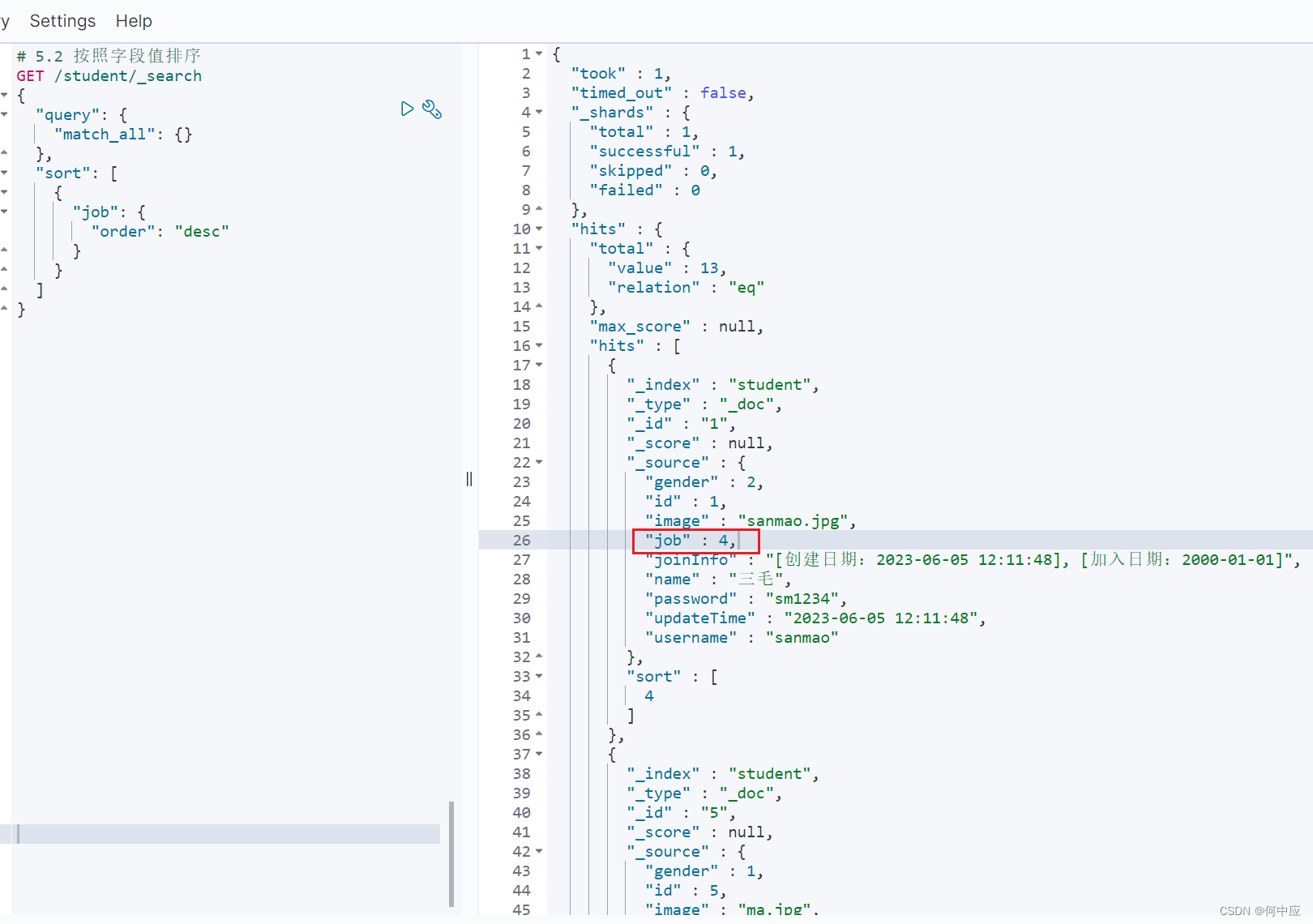
(2)按字段值排序
如按照job的值降序,越高排序越靠前;
格式:
# 5.2 按照字段值排序
GET /索引库名/_search
{"query": {"match_all": {}},"sort": [{"字段名": {"order": "desc"}}]
}
查询结果,job越高排序越靠前;
(3)按多个字段值排序
如果有多个值参与排序,可在sort里面按照顺序写多个值;
如按照job降序,job相同再按照gender升序;
格式:
# 5.3 按照多个字段值排序
GET /索引库名/_search
{"query": {"match_all": {}},"sort": [{"字段值1": {"order": "desc"},"字段值2": {"order": "asc"}}]
}
也可以写在外面的大括号里面,效果一样,如下:
# 5.3 按照多个字段值排序
GET /索引库名/_search
{"query": {"match_all": {}},"sort": [{"字段值1": {"order": "desc"}},{"字段值2": {"order": "asc"}}]
}
6、分页
es默认查询只显示前10条,可以使用分页输出,输出更多内容;目前es常用的分页有两种方式:
-
方式一:指定起始(from)、条数分页(size);
-
方式二:基于上一次查询(search_after)的结果,取值作为参数,设置条数,分页查询;
(1)方式一:
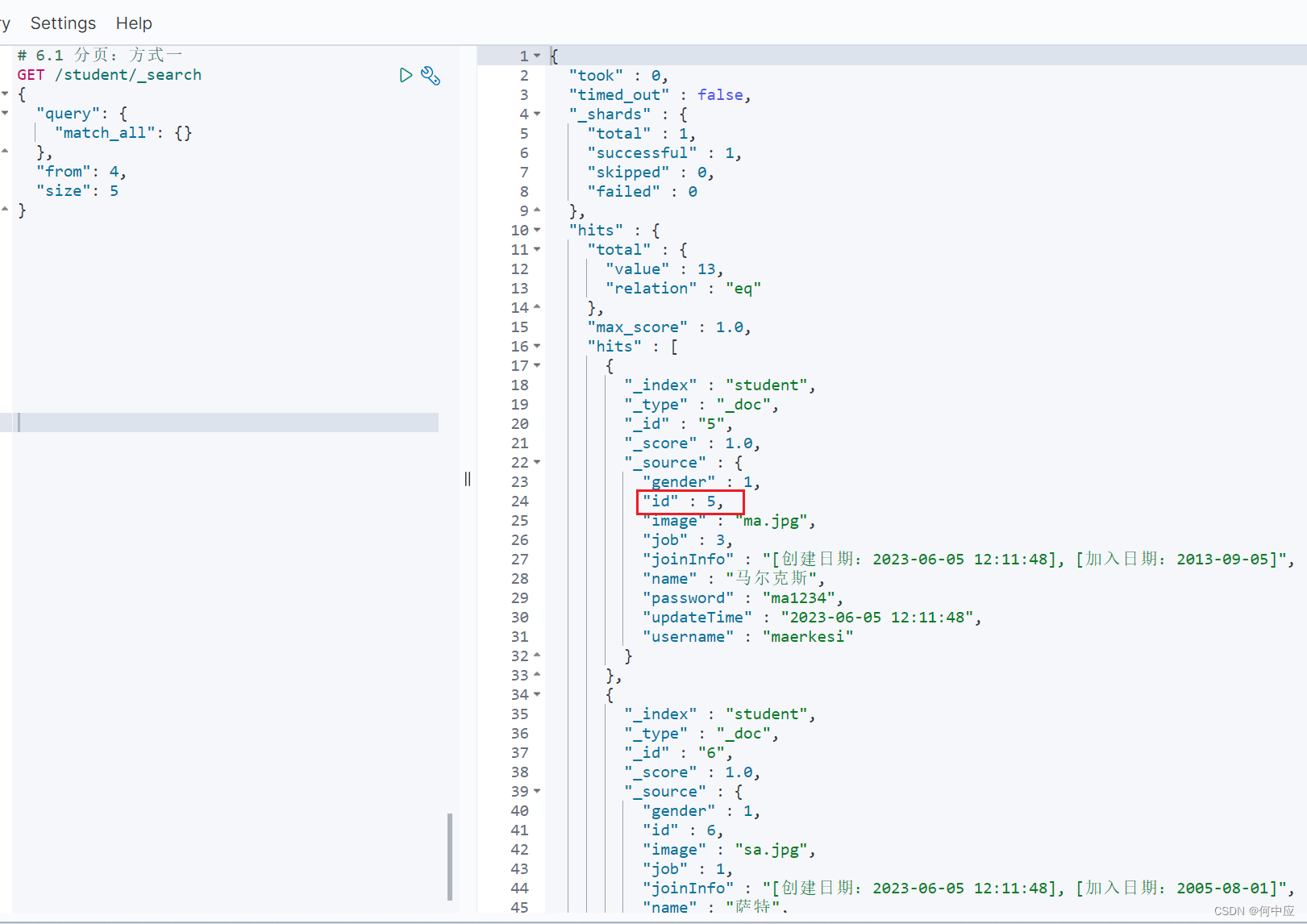
如查询起始ID为5,条数为5的文档内容;
# 6.1 分页:方式一
GET /student/_search
{"query": {"match_all": {}},"from": 起始位置,"size": 条数
}
注意from的值是从0开始计算的,所以需要 - 1;
(2)方式二
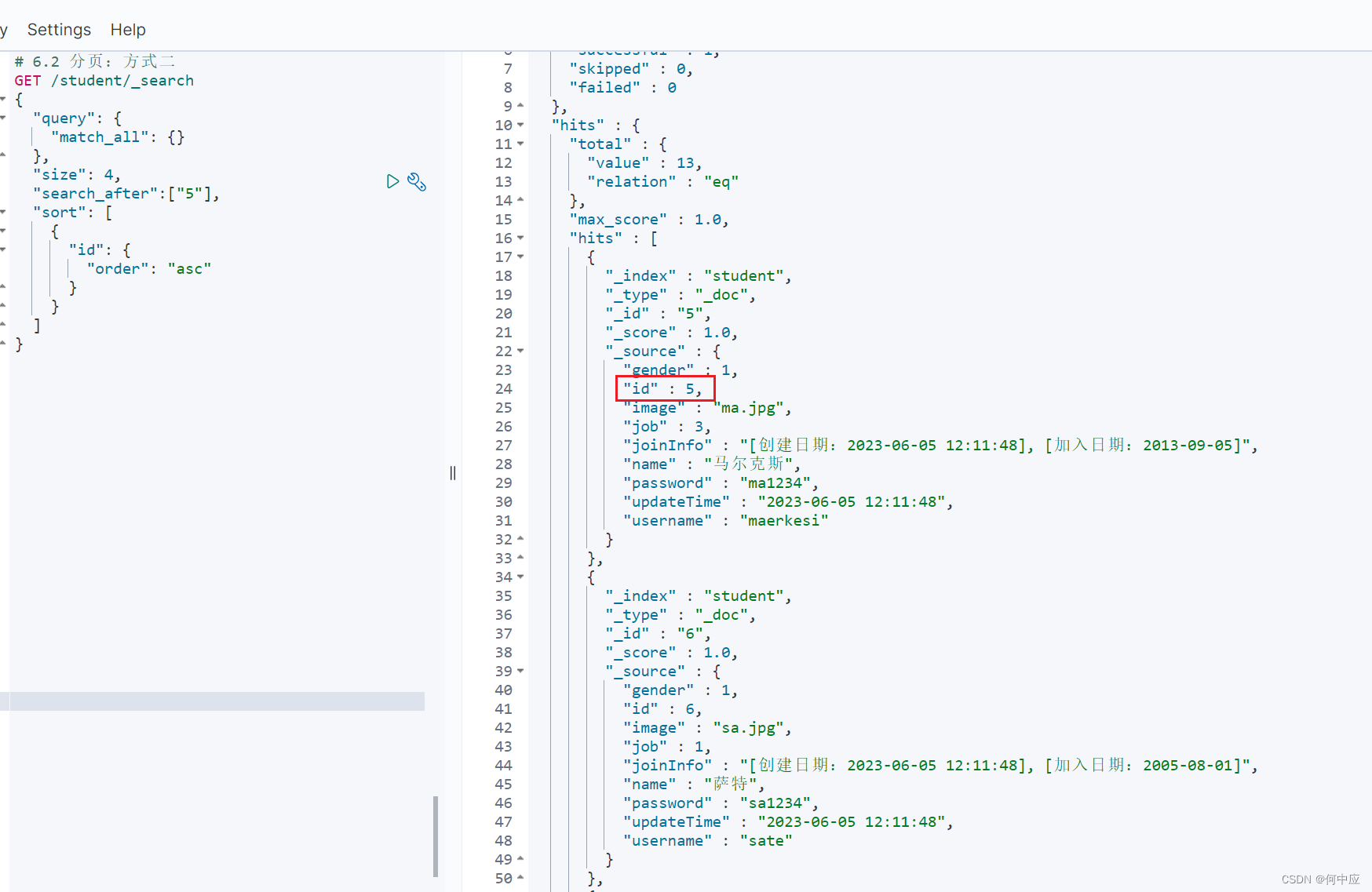
如方式一中,可以取出查询结果中的ID值,作为search_after的参数,往后查询4条
# 6.2 分页:方式二
GET /student/_search
{"query": {"match_all": {}},"size": 4,"search_after":["5"],"sort": [{"id": {"order": "asc"}}]
}
查询结果:
小结
- 方式一查询,需要注意 from + size不能超过10000 ,不然会报错;
(4 + 9996 = 10000 不会报错)
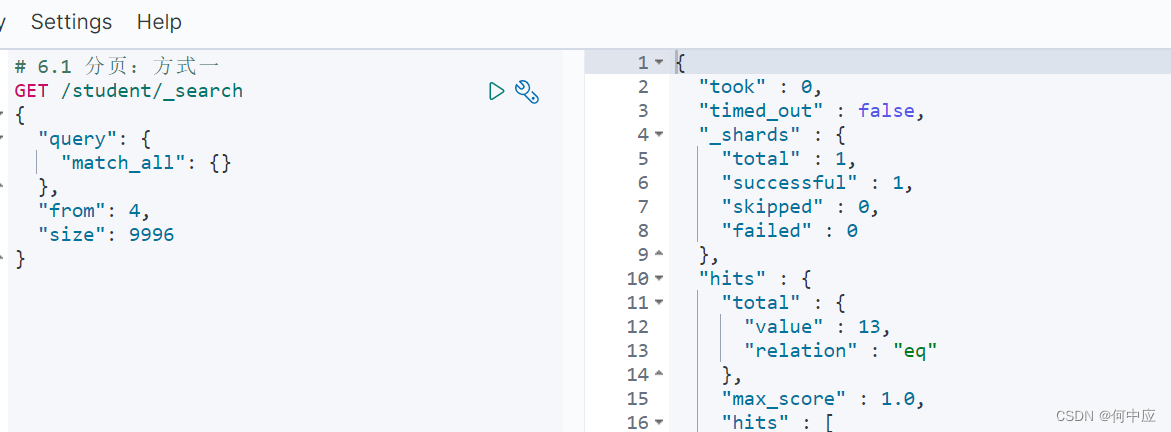
(4 + 9997 = 10001 超过10000报错)

方式二(search_after)分页查询,需要注意,字段尽量使用主键字段或者唯一字段,不然在设置上次查询的值时,该值如果在上次查询的结果中有多条,会选择最后一条文档作为search_after的位置,这样可能会跳过一些文档。
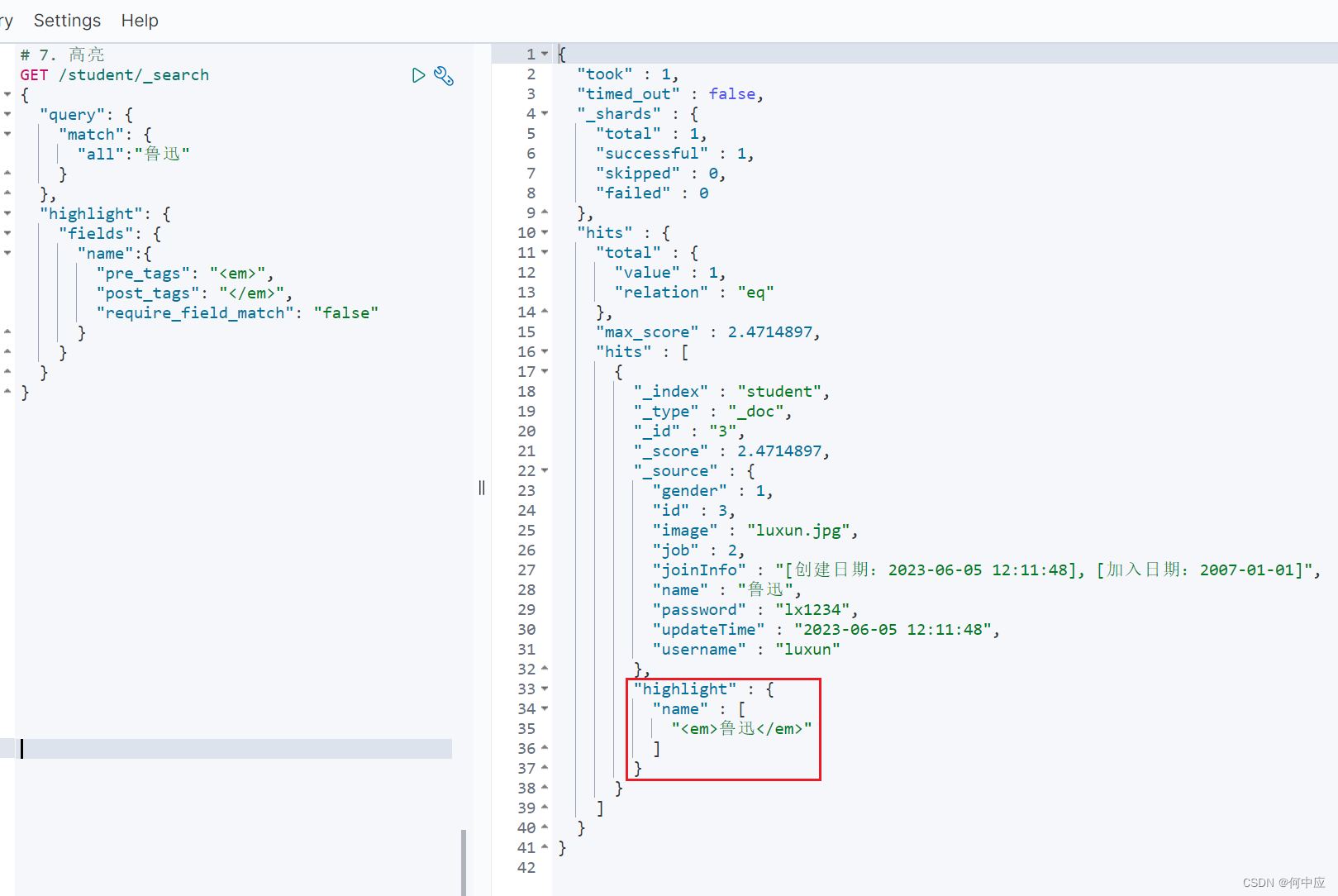
7、高亮
高亮是指对查询的结果,可选择字段特殊显示。如百度中查询的结果,关键字会呈红色字体显示,具体实现就是把关键词前后加一个css样式;
例如我这里把查询的结果,name字段斜体显示,如下:
# 7. 高亮
GET /student/_search
{"query": {"match": {"all":"鲁迅"}},"highlight": {"fields": {"name":{# 关键词前"pre_tags": "<em>",# 关键词后"post_tags": "</em>",# 此字段是否为match匹配的字段,选择false,因为我上面没有按照name进行匹配查找"require_field_match": "false"}}}
}
查询结果可以看到,鲁迅前后被em标签包裹
总结
以上DSL语句不可直接复制使用