PCIe Base Specification解析(九)


文章目录
- 4.2.2.3.3 Receiver Framing Requirements
- 4.2.2.3.4 Recovery from Framing Errors
- 4.2.2.4 Scrambling
- 4.2.2.5 Precoding
- 4.2.2.6 Loopback with 128b/130b Code
- 4.2.3 Link Equalization Procedure for 8.0 GT/s and Higher Data Rates
- 4.2.3.1 Rules for Transmitter Coefficients
- 4.2.3.2 Encoding of Presets
4.2.2.3.3 Receiver Framing Requirements
以下要求适用于接收到的数据流以及发生在数据流开始和结束处的块类型切换。
-
当处理预期为Framing Token的Symbol时,接收与Framing Token的定义不匹配的符号或者符号序列会被定义为是Framing Error。强烈建议 multi-Lane链路的接收器在该Lane的Lane Error Status寄存器中报告一个错误,该错误会在该符号与STP、IDL、SDP、EDB或EDS Token的Symbol+0不匹配的情况下接收到预期的Framing Token的第一个符号(仅bit[3:0])(请参见Figure4-13)。
-
本节中的所有可选错误检查和错误报告都是可选择实现的(请参阅Section 6.2.3.4)。
-
当收到一个STP Token时:
-
接收器必须计算接收到的TLP length 字段的Frame CRC和 Frame Parity,并将结果与接收到的Frame CRC和 Frame Parity 字段进行比较。Frame CRC或帧Frame Parity 不匹配被定义为 Framing Error。
- 为了向数据链路层报告,具有Framing Error的STP Token不被视为TLP的一部分。
-
如果TLP length字段为1,则这些符号不是STP Token,此时需要对其进行评估以确定它们是否为EDS Token。
-
接收器可选择实现是否检查TLP length字段的值是否为0。如果实现,则接收到TLP length字段为0则表示Framing
Error。 -
允许接收者检查TLP length字段的值是2、3还是4。如果实现,则接收这样的TLP length 字段被视为 Framing Error。
-
接收器可以选择实现是否检查TLP length字段的值是否在1152和1535(含)之间。如果实现,则这个TLP被视为Framing Error。
-
不支持协议多路复用的端口上的接收器可以有选择地实现是否检查TLP length字段的值是否大于1535。如果实现,则接收到这样的TLP被视为是Framing Error。
-
支持协议复用的端口上的接收器应处理TLP length字段大于1535的STP Token,作为AppendixG中定义的PMUX数据包的开始。
-
下一个要处理的Token以紧随TLP的最后一个DW之后的符号开始,这由TLP的Length字段确定。
- 接收者必须评估此符号,并确定它是否是EDB Token的第一个符号,并因此确定TLP是否无效。请参阅EDB Token 要求。
-
接收端可以选择实现是否检查在单个Symbol Time内是否收到了多个STP Token。如果实现这个功能,则在单个Symbol Time内接收多个STP Token被视为是Framing Error。
-
-
当收到一个EDB Token时:
-
如果在TLP之后立即收到EDB Token(指TLP的最后一个符号和EDB Token的第一个符号之间没有其它符号),则接收器必须通知数据链路层已收到EDB Token。在处理了EDB Token的第一个符号之后或在处理了EDB Token的任何或所有其余符号之后,允许接收器通知数据链路层已收到EDB Token。无论何时将接收到的EDB Token 通知数据链路层,接收器都必须检查EDB Token的所有符号。收到与EDB Token的定义不匹配的符号被视为是Framing Error。
-
除了紧跟在TLP之后这种情况外,在任何其他时间接收EDB Token都被视为是Framing Error。
-
EDB Token之后的符号是下一个要处理的Token。
-
-
当在链路在数据块的后四个符号中收到EDS时:
-
接收器必须停止处理数据流。
-
在EDS Token之后的块中接收除SKP,EIOS或EIEOS以外的有序集被视为是Framing Error。
-如果在EDS Token之后的块中接收到SKP有序集,则除非检测到帧错误,否则接收方将使用SKP有序集后的数据块的第一个符号恢复数据流处理(这是数据流中嵌入SKP有序集的场景)。
-
当收到一个SDP Token时:
-
紧跟在DLLP的最后一个符号之后的符号是下一个要处理的Token。
-
接收器可以选择检查在单个Symbol Time内是否收到了多个SDP Token。如果实现该功能,则在单个Symbol Time内接收多个SDP Token将被视为是Framing Error。
-
-
当收到IDL Token时:
-
对于x1链路,下一个要处理的Token是接收到的下一个符号。
-
对于x2链路,下一个要处理的Token是在下一个Symbol Time的Lane 0中接收到的符号。接收器可以选择检查在IDL Token之后在Lane 1中接收到的符号是否也是IDL。如果实现这个功能,则接收IDL以外的符号将被视为是Framing Error。
-
对于x4链路,下一个要处理的Token是在下一个Symbol Time的Lane 0中接收到的符号。接收器可以选择检查IDL Token后在Lane 1-3中接收到的符号是否也是IDL。如果实现这个功能,则接收IDL以外的符号将被视为是Framing Error。
-
对于x8,x12,x16和x32链路,下一个要处理的Token是IDL Token 后的下一个DW对齐Lane中接收到的符号。例如,如果在x16链路的Lane 4中接收到IDL Token,则下一个Token位置是同-Symbol Time的Lane 8。但是,如果在x8链路的Lane 4上接收到IDL Token,则下一个Token位置是下一个Symbol Time的Lane 0。接收器可以选择检查在IDL Token和下一个Token位置之间接收到的符号是否也是IDL。如果实现这个功能,则接收IDL以外的符号将被视为是Framing Error。
-
Note:预期在IDL Token之后的同一Symbol Time 内收到的唯一Token是其他IDL Token 或EDS Token。
-
-
在处理数据流时,在考虑到lane-to-lane skew时,接收器还必须检查每个Lane接收到的块类型,其条件如下:
-
在紧接SDS有序集的任何Lane上收到有序集块应该被视为FramingError。
-
接收到具有未定义块类型的块(同步头为11b或oob)被视为Framing Error。接收器可以选择在Lane Error Status寄存器中报告此错误。
-
在任何Lane上接收到有序集块而在前一个块中未接收到EDS Token的情况被视为Framing Error。例如,接收到前面没有EDS Token的SKP有序集就是Framing Error。另外,在数据流中立即接收到一个SKP有序集,紧接着是另一个有序集块(包括另一个SKP有序集),这也是Framing Error。强烈建议,如果有序集的第一个符号是SKP,如果接收到的Symbol 1到4N与Table 4-22或Table 4-23中的相应符号不匹配,则multi-Lane链路的接收器在Lane Error Status 寄存器中为此Lane报告一个错误。
-
当前一个数据块包含EDS Token时,在任何Lane 上接收数据块都是Framing Error。
-
接收器可以选择在不同Lane上检查不同的有序集。例如,Lane 0接收SKP有序集,Lane1接收EIOS。如果实现该功能,则接收不同的有序集是一个Framing Error。
-
4.2.2.3.4 Recovery from Framing Errors
如果接收器在处理数据流时检测到Framing Error,则它必须:
- 如Section 4.2.4.7所述报告接收器错误。
- 停止处理数据流。如前所述,当接收到下一个SDS有序集时,将启动新数据流的处理。
- ·按照Section4.2.4.7中所述启动错误恢复过程。如果LTSSM状态为LO,则将LTSSM定向到Recovery。如果在检测到Framing Error时 LTSSM 状态为Configuration.Complete 或 Configuration.ldle,则可能会由于超时导致从Configuration.Idle转移到Recovery.RcvrLock,或者直接从LO转移到Recovery。如果在检测到Framing Error时LTSSM状态Recovery.RcvrCfg或Recovery.Idle,则可能会由于超时导致导致从Recovery.Idle转换到Recovery.RcvrLock,或者直接从LO转移到Recovery。如果LTSSM为Recovery.RcvrLock或Configuration.Linkwidth.Start子状态,则错误恢复过程会依赖这些子状态退出时后的转移状态,即不会直接把LTSSM转移到Recovery状态;
- Note:预期Framing Error 恢复机制不会直接导致任何数据链路层启动的恢复操作,例如NAK。
IMPLEMENTATION NOTE
Time Spent in Recovery Due to Detection of a Framing Error
使用128b/130b编码时,所有Framing Error都需要实现链路恢复功能。从所有端口都进入恢复状态开始,从Framing Error 中恢复所需的时间预计少于1us。
4.2.2.4 Scrambling
多Lane链路中发射机的每个Lane可以实现单独的LFSR进行加扰。多Lane链路中接收机的每个Lane也可以实现单独的LFSR用于解扰。当然也可以选择复用LFSR的方式。
8.0GT/s 加扰的多项式为: G(X)=X23+X21+X16+X8+X5+X2+1,它的实现如Flgure 4-18所示。**

Figure 4-18: LFSR with Scrambling Polynomial in 8.0 GT/s and Above Data Rate
加扰规则如下:
-
Sync Header的两个比特不加扰,也不执行LFSR(这两个不一样:不加扰意味着还需要进LFSR处理,这会占用cycle,而不执行LFSR意味着不占cycle)。
-
电气空闲退出有序集(EIEOS)的所有16个符号都要bypass掉加扰。在发送时,发送EIEOS的最后一个符号后,将对加扰的LFSR进行初始化;在接收时,接收到EIEOS的最后一个符号后,将对解扰的LFSR进行初始化。
-
对于TS1和TS2有序集:
-
TS1和TS2有序集的第一个符号要bypass掉加扰。
-
TS1和TS2有序集的1-13个符号需要加扰。
-
如果要实现DC平衡,TS1和TS2有序集第14、15个符号要bypass掉加扰;否则要执行加扰。
-
-
FTS (Fast Training Sequence)有序集的16个符号都要bypass掉加扰。
-
SDS (Start of Data Stream)有序集的16个符号都要bypass掉加扰。
-
EIOS (Electrical Idle Ordered Set)有序集的16个符号都要bypass掉加扰。
-
SKP有序集的所有符号都要bypass掉加扰。
-
除SKP有序集外,发送器会对所有有序集的所有符号都会推进LFSR 对于SKP有序集的任何符号,都不推进LFSR0这里推进的意思是让LFSR产生下一个伪随机码。
-
接收器解析有序集块的Symbol0,以确定是否推进其LFSR0。如果该块的Symbol 0为SKP(请参见Section4.2.7.2),则该块的任何符号都不推进LFSR 否则,将对块的所有符号推进LFSR。
-
数据块的所有16个符号均要加扰,并使加扰器推进。
-
对于需要加扰的符号,最低有效位首先被加扰,最高有效位最后被加扰。
-
LFSR的种子值取决于当链路首次进入Configuration.Idle(即从 LinkUp=0∼b的Detect进入Polling时)时分配给该Lane的Lane number。
-
根据Lane number模8获取的种子值如下:

-
加扰的伪代码在Appendix C的Section C.2给出。
- LinkUp=1时,LFSR的种子值不会更改。只要链路是LinkUp状态,通过LTSSM的Configuration状态进行的链路重新配置不会修改初始的Lane number分配(即使Lane分配在Configuration状态可能会更改)。
- 在使用128b/130b编码的情况下,Configuration.Complete 状态不会禁用加扰功能。
- Loopback Slave 不允许对环回的比特流进行加扰或解扰。
IMPLEMENTATION NOTE
LFSR Implementation with a Shared LFSR
具体实现时可以选择实现一个LFSR,并采用不同的分接点,如Figure 4-19所示,这等效于具有不同种子的单个LFSR每Lane,如Figure 4-18所示。还应注意,四个Lane的抽头方程是两个相邻Lane的抽头方程的XOR。例如,可以通过对Lane1和Lane 7的输出进行XOR运算来获得Lane 0。Lane 2是Lane 1和Lane 3的XOR;Lane 4是Lane 3和Lane 5的XOR;Lane 6是Lane 5和Lane 7的XOR∘ 这可以用来帮助减少门数,但由于两个Lane的XOR结果而可能导致延迟。
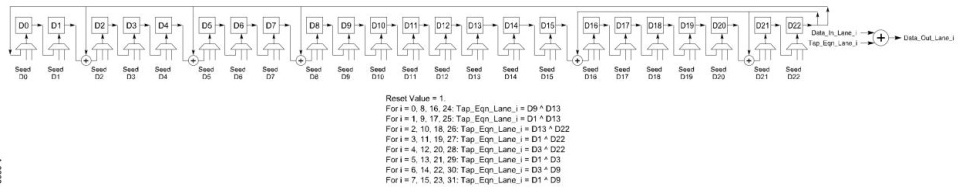
Ao608
Figure 4-19: Alternate Implementation of the LFSR for Descrambling
4.2.2.5 Precoding
预编码(precoding)是2018年全国科学技术名词审定委员会公布的计算机科学技术名词。它是一种利用前后码元相关性,而在很大程度上避免误码扩散的编码技术。
接收器可能会要求其发送器进行预编码,以便以32.0 GT/s或更高的数据速率工作。预编码规则如下:
- Port或Pseudo-Port必须在链路的所有已配置通道上请求预编码。如果通过Port或Pseudo-Port在某些通道上请求预编码,而在其他通道上未请求预编码,则行为是不确定的。
- Port或Pseudo-Port 可以请求独立于其他Port或Pseudo-Port的预编码。例如,在Figure4-35中没有Retimer的情况下,或者仅在两个Retimer中的Tx(A)和Tx(E)的所有通道上,都可能仅在上游端口中打开预编码。示例如Figure 4-35所示。
- 当LTSSM处于Detect状态时,对于数据速率为32.0GT/s以及更高的数据速率,将关闭预编码。
- 在设置32.0GT/s或更高数据速率之前,必须通过设置EQ TS2 Ordered Set或128b/130b EQ TS2Ordered Set 中的相应比特来发出预编码请求。必须通过在EQTS2或128b/130b EQ TS2 Ordered Set中设置 Transmitter Precode Request来发出预编码请求,然后才能在转换到Recovery.Speed,从而达到目标数据速率。对于高于32.0GT/s的每个数据速率,必须独立发出预编码请求。
- 如果链路以32.0 GT/s或更高的数据速率运行,而没有通过(在已修改的)TS1/TS2有序集中协商的No Equalization Needed 机制执行均衡,则必须强制执行来自正在使用的最后均衡结果的预编码请求。因此,如果每个(pseudo)Port通告 No Equalization Needed机制,则必须在每个通道中存储预编码请求以及TxEq值。如果没有对链路进行过任何均衡(在当前链路之前),则预编码将不会打开。
- 如果目标数据速率为32.0GT/s或更高,则如果在从Recovery.RcvrCfg切换到Recovery.Speed过程中接收到的八个连续EQTS2或128b/130b EQ TS2 Ordered Set中的 Transmitter Precode Request 都设置为1b,发送器必须为链路在退出Recovery.Speed时的目标数据速率开启预编码。一旦开启,预编码将对该目标数据速率有效,直到发送器在从Recovery.RcvrCfg切换到Recovery.Speed 期间接收到另一组八个连续EQTS2或128b/130b EQ TS2 Ordered Set,且目标速率与之前相同。
- 对于低于32.0GT/s的任何数据速率,发送器不得开启预编码。
- 对于32.0GT/s或更高的数据速率,如果预编码开启,则发送器必须将处于Recovery状态的TS1 Ordered Set的Transmitter Precoding On 字段设置为1;否则,发送器必须将其设置为0b。
- 启用预编码后,仅对已加扰的比特位进行预编码。
- 用于预编码的“previous bit”在每个块边界上均设置为1b,并通过当前块边界内发送的最后加扰和预编码比特位进行更新。
- 开启预编码后,对于已加扰的符号,接收器必须先对预编码的比特进行解码,然后再将其发送给解扰器。
- 已在Lane 0上以32.0 GT/s数据速率开启预编码的发送器,必须将32.0 GT/s Status寄存器中的Transmitter Precoding On字段设置为1b;否则必须将其设置为0b。已请求或将要求以32.0GT/s数据速率打开预编码的接收器,必须在32.0 GT/s Status 寄存器中将Transmitter Precoding On字段设置为1b;否则必须将其设置为0b。
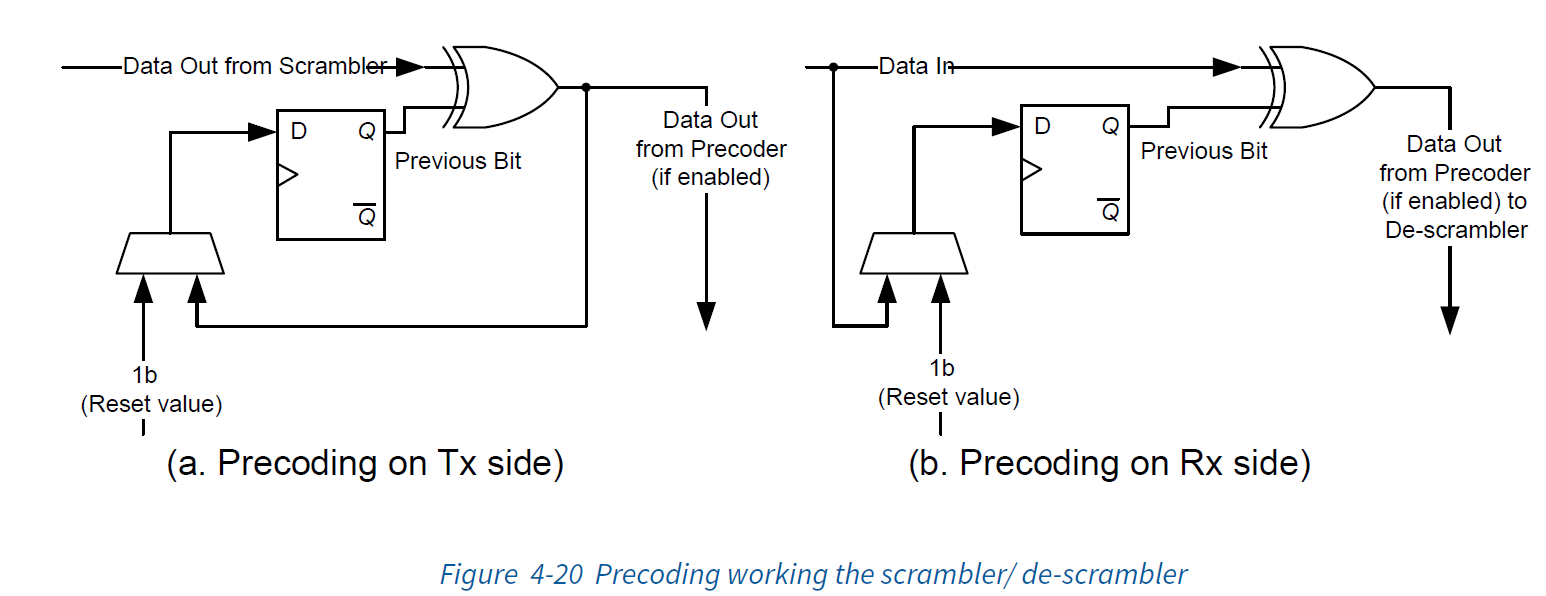
Figure 4-20 Precoding working the scrambler/de-scrambler
IMPLEMENTATION NOTE
Parity in the SKP Ordered Set when Precoding is turned on
根据Section 4.2.4.1和Section 4.2.7.2的规则,当启用预编码时,应在发送侧应用预编码之前计算SKP Ordered Set中的奇偶校验。因此,发送器中的顺序为:
-
scrambling,
-
followed by parity bit calculation,
-
followed by precoding for the scrambled bits。
相应的,接收侧的顺序为:
-
precoding (if turned on by the Transmitter),
-
followed by parity bit calculation,
-
followed by descrambling。
此顺序的基本原理是,在具有一个或两个Retimer的链路中,不同的链路部分可能会启用或禁用预编码。让我们考虑一个在根端口和Endpoint之间有一个Retimer的示例的系统来说明这一点。在上游方向上,由于Retimer Receiver需要在Endpoint上的发送器通道中进行预编码,但是由于根端口不需要在其接收器上进行预编码,因此Retimer到Root Port Link 这一短已关闭了预编码。由于Retimer不会改变奇偶校验位,因此,如果在预编码后由(Endpoint的)发送器进行奇偶校验计算,则根端口将出现奇偶校验错误。
IMPLEMENTATION NOTE
Loopback Master behavior if Precoding is on in any Link Segment
根据本节和Section 4.2.6.4中提到的预编码规则,以32.0 GT/s或更高的数据速率运行的Loopback Master应考虑到预编码在某些链路段上处于打开状态,而在其他链路段上处于关闭状态。当Loopback Slave 从发送TS1 Ordered Set 切换到环回这些比特时,这一点尤其重要。这是Loopback Master 接收器上的预编码可以切换的地方(在预编码打开和关闭之间)。允许Loopback Master 使用特定于实现的机制来处理这种情况。
IMPLEMENTATION NOTE
TS1/TS2 Ordered Sets when Precoding is turned on
根据本节中的规则,当预编码被打开时,用于预编码的“previous bit”对于Symbol 1的第一比特是1b,因为Symbol 0没有被加扰并且“previous bit”在块边界处被设置为1b。
4.2.2.6 Loopback with 128b/130b Code
使用128b/130b编码时,Loopback Masters必须发送具有特定定义的01b和10b同步头的块。但是,从有序集块过渡到数据块时,不需要传输SDS有序集,从数据块过渡到有序集块时,也不需要传输EDS Token。Master必须按照Section 4.2.7中的规定定期发送SKP有序集,并且它们必须能够处理长度变化的环回的SKP有序集。Master 可以发送Section 4.2.2.2.1中定义的电气空闲退出有序集(EIEOS)。允许Master发送它们期望环回的数据块和有序集块中的任何有效负载。但是,应避免与SKP OS,EIEOS或EIOS 的定义相匹配的有序集块,因为它们在环回时已经有明确的用途。
当使用128b/130b编码时,Loopback Slave必须转发所有接收到的未被修改的比特流,除了SKP有序集,可以根据需要对它们进行调整以进行时钟补偿。如果需要时钟补偿,则Slave必须为每个有序集添加或删除4个SKP符号。修改后的SKP有序集必须符合Section 4.2.7.2的定义(即,它必须具有4至20个SKP符号,后跟SKP_END符号,以及Loopback Masters 发送的紧随其后的三个符号)。如果Slave无法获得块对齐或未对齐,则它可能无法执行时钟补偿,因此无法环回所有接收到的比特。在这种情况下,可以根据需要添加或删除符号以继续操作。当检测到从有序集块到数据块的切换时,Slave不得检查接收到的SDS有序集,并且当检测到从数据块到有序集块的切换时,Slave也不得检查接收到的EDS Token。
4.2.3 Link Equalization Procedure for 8.0 GT/s and Higher Data Rates
当以8.0GT/s或更高的数据速率运行时,链路均衡过程使组件能够调整每个Lane的发送器和接收器设置,以改善信号质量并满足Chapter 8中指定的要求。与LTSSM关联的所有Lane必须参与均衡过程。该过程必须在首次将数据速率更改为8.0GT/s或以上的过程中执行。当LinkUp=1b时,组件必须针对将来将要遇到的所有操作条件到达适当的发送器设置。组件不得要求重复均衡过程来确保可靠运行,尽管规定可以重复该过程。组件必须存储均衡过程中协商好的的发射机设置,并将其用于之后的8.0GT/s 或更高的数据速率。甚至在均衡过程完成后,组件仍可以微调其接收器设置,因为这样做不会导致链路不可靠(即不符合Chapter 8中的要求)或进入Recovery状态。
任何数据速率都不需要链路均衡过程,如果链路中的所有组件都已通告其TS1/TS2 Ordered Set 或 modified TS1/TS2 Ordered Set (see Table 4-6, Table 4-7和 Table 4-8)中不需要均衡,则可以完全Bypass链路均衡过程(请参阅Table4-6,Table 4-7和 Table 4-8)。如果组件支持32.0GT/s或更高的数据速率,并且可以使用先前的均衡过程中存储的均衡设置可靠地运行,或者不需要均衡来可靠地操作,那么组件可以选择通告它不需要以高于5.0Gt/s的任何速率进行均衡。
均衡过程可以自主启动,也可以通过软件启动。强烈建议组件使用自主机制来处理其打算在5.0GT/s以上的所有数据速率。但是,对于所有高于5.0GT/s的数据速率,选择不参与自主机制的组件必须具有其相关软件,以确保在以该数据速率运行之前,基于软件的机制应用于未应用自主机制的高于5.0GT/s的数据速率。
通常,仅当以高于5.0GT/s的所有较低数据速率成功完成均衡时,才以较高数据速率执行均衡。例如,链路将以8.0GT/s成功完成均衡,然后才能以16.0GT/s成功完成均衡,然后才能以32.0 GT/s的速率成功完成均衡。但是,如果所有组件都支持32.0 GT/s 或更高的数据速率,则可以使用一种可选的机制(且链路中的所有组件都支持该机制)来跳过均衡,以达到32.0GT/s或更高的公共的数据速率,就如在TS1/TS2 Ordered Set或 modified TS1/TS2 Ordered Set 中通告的那样。启用此可选机制并在组件之间成功协商后,除最高公共数据速率外,不会以任何其他速率执行均衡。对于未执行均衡的所有高于5.0GT/s的数据速率,可以预期的是链路不得以这些数据速率运行。例如,一条链路可以2.5 GT/s的速度训练到LO,进入Recovery并以32.0 GT/s的速度执行均衡,而跳过8.0GT/s和16.0GT/s的均衡。在这种情况下,链路的预期数据传输速率为2.5 GT/s,5.0 GT/s或32.0 GT/s。如果在最高公共数据速率下的均衡过程即使在重新均衡尝试之后也不成功,并且链路需要以较低的数据速率进行均衡,则下游端口必须停止通告 Equalization bypass to highest rate support字段,并确保链路以2.5 GT/s或5.0 GT/s的速率恢复运行。如果不支持跳过均衡到最高公共数据速率的可选机制,则将执行所需的全部均衡过程。如果较低数据速率下的均衡过程由软件驱动,则必须将Equalization bypass to highest rate Disable 设置为1,并将No Equalization Needed Disable 字段设置为1b;设置目标链路速度,使链路以2.5Gt/s或5.0Gt/s的速度运行;然后将目标链路速度设置为以8.0GT/s起的较低速率均衡。如果Equalization bypass to highest rate Disable 设置为1b,则端口不得通告 Equalization bypass to highest rate support 字段。
如果所有组件都支持32.0GT/s或更高的数据速率,并且链路中的所有组件都支持No Equalization Needed机制,则可以使用另一种可选机制跳过整个均衡过程并直接达到32.0GT/s或更高的最高公共数据速率,此速率为TS1/TS2或modified TS1/TS2 Ordered Set中通告的最高速率。如果一个组件能够从之前的均衡中以所有数据速率检索均衡和其他电路设置(该均衡将对该组件起作用),或者在高于5.0GT/s的所有数据速率中根本不需要均衡,则可以执行此操作。如果Equalization bypass to highest rate Disable 设置为1,则组件不得通告此Capability。
如果链路的一个方向在通告No Equalization Needed,而另一方向在TS1/TS2 Ordered Set 中通告 Equalization bypass to highest rate support,则链路将在Equalization bypass to highest rate support 下工作,因为No Equalization Needed字段还指示设备能够绕过均衡以获得最高数据速率。在modified TS1/TS2 Ordered Set中,将 No Equalization Needed 字段设置为1b的设备还必须将Equalization bypass to highest rate support 设置为1b。如果链路的一个方向通告No Equalization Needed,而另一方向仅在modified TS1/TS2Ordered Set 中通告 Equalization bypass to highest rate support,则链路将以 Equalization bypass to highest rate support 工作。如果设备在其发送的modified TS1/TS2 Ordered Set 中将 No Equalization Needed 通告为1b,并且将Equalization bypass to highest rate support设置为0b,则链路操作是不确定的。
如果两个组件在初次链路协商期间(当LinkUp设置为1b时)通告它们至少能够达到8.0GT/s的数据速率(通过TS1和TS2有序集),并且下游端口选择以高于5.0GT/s的预期工作数据速率执行均衡过程,则执行自主机制。虽然不推荐这样做,但下游端口可以选择仅在5.0GT/s以上的预期数据速率的子集上执行自主机制。在这种情况下,必须执行基于软件的机制,以便对5.0GT/s 以上的预期数据速率执行均衡过程,而该机制不在自主机制的范围内。例如,如果两个组件都通告了8.0GT/s、16.0 GT/s和32.0GT/s数据速率,但仅对8.0GT/s和16.0 GT/s数据速率执行了自主均衡,则必须采用基于软件的机制以32.0 GT/s数据速率进行均衡。
在自主机制中,在进入LO之后,无论当前链路速度如何,如果必须执行均衡过程并且直到均衡过程完成,则任何组件都不必发送任何DLLP。一旦每个通道的发送器和接收器设置已针对每个支持的高于5.0GT/s的公共数据速率进行了调整,下游端口打算使用自主机制执行均衡,则认为均衡过程已完成。下游端口需要启动对需要执行均衡的数据速率的速度改变。在任何均衡(自主或软件启动或重新均衡)期间,下游端口不得通告对高于Recovery中需要执行均衡的数据速率的任何数据速率的支持。提供以下示例来说明均衡流程。
Example:考虑一个需要在8.0GT/s和16.0GT/s下自动执行均衡的链路。下游端口通过不通告高于8.0GT/s的任何数据速率而进入Recovery以8.0 GT/s的速率执行均衡。如果Link Status 2寄存器的Equalization 8.0 GT/s Phase 3 Successful 和 Equalization 8.0 GT/s Complete字段均设置为1b,则认为8.0GT/s均衡过程已成功执行。从Recovery切换到L0后,在初始数据速率更改为8.0GT/s 之后,需要下游端口从LO切换到Recovery,通告对16.0 GT/s数据速率支持(但不通告对32.0GT/s的支持,即使它能够支持32.0GT/s),将数据速率更改为16.0GT/s,然后执行16.0GT/s均衡过程。
如果下游端口检测到均衡问题或上游端口发出均衡重做请求(通过将Request Equalization 设置为1b),则下游端口可以在继续以均衡失败的数据速率操作或以更高的数据速率执行均衡之前重做均衡。在给定的数据速率下,背靠背均衡重做的次数是特定于实现的,但必须是有限的。如果在初始或后续均衡过程结束时以及在执行特定数量的均衡重做时,链路不能以执行均衡的数据速率可靠地操作,那么它必须恢复到较低的数据速率操作。
在均衡过程完成之前,使用自主机制的组件不得启用任何自主链路宽度缩小机制。在从下游端口接收到DLLP之前,上游端口不得传输任何DLLP。如果下游端口再次执行均衡,则在完成均衡过程之前,它不得传输任何DLLP。如果下游端口能够满足其系统要求,则可以基于其自身的需要或者基于来自上游端口的请求再次执行均衡。如Section 6.6所述,多次执行均衡可能会干扰软件对链路和设备状态的确定。
IMPLEMENTATION NOTE
DLLP Blocking During Autonomous Equalization
当使用自主机制以8.0GT/s或更高的数据速率进行均衡时,下游端口需要阻止DLLP的传输,直到均衡完成,并且上游端口需要阻止DLLP的传输,直到从下游端口接收到DLLP为止。如果两个组件都通告它们能够以16.0GT/s(或32.0 GT/s)的数据速率传输数据,但下游端口仅使用自主机制以8.0GT/s的速率进行均衡,则下游端口仅需要在8.0GT/s均衡完成之前阻止DLLP传输。类似地,如果两个组件都通告它们能够以32.0GT/s的数据速率传输,但下游端口仅使用自主机制以16.0 GT/s的速率进行均衡,则下游端口仅需要阻塞DLLP传输,直到16.0GT/s均衡完成。如果在DLLP传输被阻止时,下游端口延迟从LO进入Recovery,则LO推断的电气空闲超时(见 Section 4.2.4.4)或DLLP超时(见Section 2.6.1.2)可能在上游或下游端口中过期。如果这两个超时中的任何一个发生,它将导致启动一个进入Recovery来执行链路重新训练。这两个超时都不是可报告的错误情况,并且由此产生的链路重新训练对正确的链路操作没有影响。
当使用基于软件的机制时,软件必须保证不会对正在进行的传输事务产生任何副作用(例如,不能超时)如果有的话,是因为链路正在执行均衡过程。软件可以将1b写入Link Control 3的 Perform Equalization 字段,然后写Link Control 2的Target Link Speed 字段,以使链路以8.0GT/s或更高的速度运行,然后将1b写到下行端口的Link Control的 Retrain Link 字段以执行均衡过程。如果未成功执行以8.0GT/s开始的所有较低数据速率的均衡过程,则在软件启动的均衡过程中,软件不得使链路以8.0GT/s以上的数据速率运行并将均衡bypass到更高的数据速率(即 Equalization bypass to highest rate Supported 为 0b 或 Equalization bypass to highest rate Disable为1b)。对于以下数据速率,均衡过程被视为成功:
8.0 GT/s: Link Status 2 寄存器的 Equalization 8.0 GT/s Phase 3 Successful 和 Equalization 8.0 GT/s Complete字段均设置为1b。
16.0GT/s: 16.0GT/s Status 寄存器的 Equalization 16.0 GT/s Phase 3 Successful 和 Equalization 16.0 GT/s Complete 字段均设置为1b。
软件可能会在两个组件中都设置Link Control 寄存器的 Hardware Autonomous Width Disable 字段,或使用其他机制来确保在设置下行端口中的Perform Equalization字段之前,链路的全部Lane的功能是完善的。启用自主width downsizing 功能的组件负责通过把 Hardware Autonomous Width Disable 设置为1b之后的1ms内让LTSSM切换到Recovery和 Configuration,来将链路配置为对应宽度。如果上游端口最初并未通告8.0GT/s、16.0GT/s或32.0GT/s数据速率并参与自主均衡机制,则其相关软件必须确保对均衡期间执行的任何传输事务没有任何副作用(如果有的话),然后再指示上游端口转换到Recovery状态并通告之前未通告的数据速率并启动一个速度切换。下游端口在转换到Recovery状态时,在初始速度更改为通告的数据速率时,随后将启动均衡过程。
Hardware Autonomous Width Disabl=0,表示在链路某条Lane异常时链路会自主协商,减小Lane的宽度,以规避异常Lane。当切换到8.0GT/s时,可能存在某条Lane 设置的不恰当导致该Lane支持不了8.0 GT/s而其他Lane可以支持8.0GT/s的现象,这时候这个功能就起作用了。Hardware Autonomous Width Disable=1的话这个功能就被禁用了。
需要上游端口在Recovery.RcvrLock状态下检查均衡设置问题(参阅Section 4.2.6.4.1)。但是,允许下游端口和上游端口在任何时候都使用特定于实现的方法来检测均衡问题。对于以下每个数据速率,如果检测到其均衡设置有问题则端口需要执行以下操作:
8.0GT/s:Link Status 2寄存器的Link Equalization Request 8.0 GT/s字段要设置为1b。
16.0GT/s : 16.0 GT/s Status 寄存器的Link Equalization Request 16.0 GT/s字段要设置为1b。
32.0GT/s : 32.0 GT/s Status 寄存器的Link Equalization Request 32.0 GT/s字段要设置为1b。
除了把相应的Link Equalization Request设置为1b,上游端口必须让LTSSM切换到Recovery状态,并使用其在Recovery.RcvrCfg 子状态中发送的TS2有序集中的Request Equalization位来发出均衡请求,并把Equalization Request Data Rate 设置为检测到问题的数据速率。对于每个检测到的问题,它只能发出一次均衡请求。当请求均衡时,也允许但不要求上游端口将Quiesce Guarantee 字段设置为1b,以通知下游端口在1ms内启动的均衡过程不会对其操作造成任何副作用。
当下游端口接收到来自上游端口的均衡请求时(处于Recovery.RcvrCfg状态并接收到8个连续的TS2有序集且Request Equalization 设置为1b时),它必须在完成下一个Recovery到LO转换的1ms内以请求的数据速率(由接收的 Equalization Request Data Rate 字段定义)启动均衡过程,或必须在其Link Status 2寄存器中设置适当的Link Equalization Request 8.0 GT/s值,或在其16.0 GT/s Status寄存器中设置Link Equalization Request 16.0 GT/s,或在其32.0 GT/s Status寄存器中设置 Link Equalization Request32.0GT/so 只有当它能够保证执行均衡过程不会对其操作或上游端口的操作造成任何副作用时,它才应该启动均衡过程。允许但不要求下游端口使用接收到的Quiesce Guarantee位来确定上游端口在没有副作用的情况下执行均衡过程的能力。
如果下游端口要启动均衡过程并可以保证不会对其自身操作产生副作用,但是无法直接确定均衡过程是否会对上游端口的操作产生副作用,则允许请求上游端口发起均衡请求。下游端口通过转换为Recovery并在Recovery.RcvrCfg状态下将其传输的TS2有序集的Request Equalization位设置为1b,将Equalization Request Data Rate 位设置为所需数据速率,并将Quiesce Guarantee 位设置为1b来实现此目的。当上游端口从下游端口接收到这样的均衡请求时(处于Recovery.RcvrCfg状态,并且接收到8个连续的TS2有序集,且Request Equalization 和Quiesce Guarantee 位设置为1b),这是允许的,但不是必需的,以静默其操作并准备以下游端口请求的数据速率执行均衡过程,然后以相同的数据速率(使用前面介绍的报告均衡设置问题的方法)并要求将Quiesce Guarantee位设置为1b。上游端口可以响应的时间没有时间限制,但是应该尝试尽快做出响应。如果下游端口发出请求并从上游端口接收到此类响应,则它仍必须保证在执行完下一次从Recovery到LO的转换后的1毫秒内,以协商的数据速率启动均衡过程。均衡过程不会对其操作产生任何副作用,或者必须在其Link Status 2寄存器中设置适当的Link Equalization Request 8.0 GT/s或在16.0 GT/s Status 寄存器中设置 Link Equalization Request 16.0 GT/s 位或在32.0 GT/s Status 寄存器中设置 Link Equalization Request 32.0 GT/s位。
IMPLEMENTATION NOTE
Using Quiesce Guarantee Mechanism
数据链路层处于DL_Active状态后,由于执行均衡而产生的副作用可能发生在端口,设备或系统级别。例如,执行均衡过程所需的时间可能会导致Completion Timeout 错误发生-这指的是在其他可能的系统组件中。Quiesce Guarantee Mechanism 可以帮助端口决定是否发出一个均衡请求动作。
在报告其均衡问题之后,组件可以通过Recovery.Speed超时或通过将数据速率更改为较低的数据速率来以较低的数据速率运行。执行均衡过程所需的任何数据速率更改均不受Section 6.11节中200ms要求的限制。Table 4-3描述了重做均衡的机制。有时可能需要将速度更改为中间数据速率以重做均衡。例如,如果下游端口要以16.0 GT/s的速度重新进行均衡,且不支持bypass equalization,并且当前数据速率为2.5GT/s或5.0 GT/s,则下游端口必须首先将速度更改为8.0GT/s(除非必要,否则不会执行8.0GT/s均衡过程),然后它将以16.0GT/s的速度启动重做均衡。通过Recovery状态,每一跳最多只能执行一次均衡过程。
从2.5GT/s 或5.0GT/s 到8.0GT/s 均衡此处描述的机制对于所有均衡方式都是相同的:初次、重做、自主或软件启动。
8.0GT/s 均衡
下游端口使用8b/10b 编码将每个通道的发送器的preset 值和接收器的preset hint 发送到上游端口(如果适用)。在协商了将数据速率更改为较高数据速率之前,在切换到较高数据速率以执行均衡之前,使用Recovery.RcvrCfg 中的EQ TS2 有序集(在Section 4.2.4.1 中定义)发送这些值。在EQ TS2 有序集中发送的preset 的推导如下:
- 对于8.0 GT/s 速率下的均衡:Lane Equalization Control Register Entry 的Upstream Port 8.0 GT/s Transmitter Preset 和Upstream Port 8.0 GT/s Receiver Preset Hint 字段的值。
在数据速率更改为需要进行均衡的较高数据速率之后,上游端口将使用其接收到的preset 值发送TS1 有序集。如果发送器使用reduced swing,则preset 值必须在Section 8.3.3.3 中定义的可操作范围内。
在数据速率改变到需要执行均衡的更高数据速率后,下游端口发送具有如下preset 值的TS1 有序集,假设preset 值必须在Section 8.3.3.3 中定义的可操作范围内,前提是发送器将使用reducedswing:
- 对于8.0 GT/s 速率下的均衡:Lane Equalization Control Register Entry的Downstream Port 8.0 GT/s Transmitter Preset 和可选的Downstream Port 8.0 GT/s Receiver Preset Hint 字段的值。
要执行重做均衡,下游端口必须在2.5 GT/s 或5.0 GT/s 通过Recovery.RcvrLock 中的EQ TS1 有序集发起Speed Change 的请求,以通知上游端口它打算以更高的数据速率进行重做均衡。如果上游端口接收到EQ TS1 有序集且Speed Change 位设置为1b,并且打算将来以更高的数据速率运行,则上游端口应在Recovery 中通告更高的数据速率。
Phase 0
这个阶段是在协商(和之前)将要执行均衡的数据速率时执行的。如Table 4-3所述确定用于均衡的preset值。
Phase 1
这两个组件都使链路能够以当前数据速率运行,并可以交换TS1有序集,以完成剩余阶段的发送器/接收器对的微调。预计在组件准备好进入下一阶段之前,链路将以小于 10-4的BER运行。每个发送器使用Table 4-3中所述的preset值。
下游端口通过发送 EC=01∼b 的TS1有序集(表示Phase 1)来启动Phase 1。上游端口在调整其接收器(如有必要)以确保其可以进行均衡处理后,接收这些TS1有序集并转换到Phase 1(在该Phase中,它以 EC=01∼b发送TS1有序集)。当下游端口在进入Phase 2之前从上游端口接收到 EC=01∼b的TS1有序集时,下游端口确保能够可靠地从上游端口接收比特流以继续进行其余Phase。
Phase 2
在此阶段中,上游端口在每个Lane上独立地调整下游端口的发送器设置及其自身的接收器设置,以确保它接收到符合 Chapter 8要求的比特流(比如,所有可用的Lane上的BER小于 10-12)。下游端口通过将 EC=10b的TS1有序集发送到上游端口来启动进入Phase 2。下游端口按照下面的规则通告发送器系数及其所使用的preset值,Phase 1仅发送preset值,Phase 2会发送preset 值和coefficients值。上游端口接收这些有序集,并可能要求使用不同的preset和coefficients,并继续评估每组值,直到达到下游端口Lane的最佳设置为止。上游端口完成此阶段后,它将链路EC=11b的TS1有序集发送到下游端口,从而将链路切换到Phase 3。
Phase 3
在此阶段中,下游端口使用类似于Phase2的握手和评估过程,独立地在每个Lane上调整上游端口的发送器设置及其自身的接收器设置,只不过EC值要设置为11b。下游端口通过发送 EC=00b的TS1有序集来发信号通知Phase 3(以及均衡过程)结束。
组件用来调整其Link partner的发送器的算法以及对该发送器设置及其接收器设置的评估是特定于实现的。组件可以请求更改任意数量的Lane,并且可以为每个Lane请求不同的设置。每个请求的设置可以是preset值或一组符合Section 4.2.3.1中定义要求的系数。每个组件负责确保在微调结束时(上游端口的Phase 2和下游端口的Phase 3),其Link partner在每个Lane中都具有最佳的Transmitter设置,这将使链路满足Chapter 8中的要求。
接收到调整其发送器请求的Link partner 必须评估该请求并对其执行操作。如果请求有效的preset值,并且发送器在full swing 模式下运行,则必须将其反映在发送器设置中,然后反映在Link partner传输的TS1有序集的preset字段和coefficients字段中。如果请求一个预设值,且发送器在reduced swing模式下运行,并且如Section 8.3.3.3中所定义的那样支持所请求的preset,它必须反映在发送器设置中,然后反映在Link partner传输的TS1有序集的preset字段和coefficients字段中。允许工作在reduced swing 模式下的发送器拒绝Section 8.3.3.3中定义的不支持的预设请求。调整系数的请求可以被接受或拒绝。如果为Lane请求的系数集被接受,则必须在发送器设置中反映出来,然后在传输的TS1有序集中反映出来。如果为Lane请求的系数集被拒绝,则不会更改发送器设置,但发送的TS1有序集必须反映所请求的系数以及将Reject Coefficient 字段设置为1b。在响应系数请求的任何一种情况下,传输的TS1有序集的预设字段都不会从传输的最后一个预设值更改。仅当请求的系数集不符合Section 4.2.3.1中定义的规则时,Link partner才可以拒绝调整系数的请求。
在执行crosslink的均衡时,在较早的crosslink 初始化期间以较低数据速率扮演下游端口角色的组件也承担了下游端口进行均衡的责任。
如果某Lane在Polling.Compliance、Loopback、Recovery.Equalization的Phase 0或Phase 1直接使用了保留的或不支持的发送器的preset值,则允许该Lane以特定的实现方式来支持发送器的preset值的设置。保留的或不支持的发送器预设值将在任何后续的Compliance Patterns 或有序集中传输,而不是由Lane选择的特定于实现的预设值。例如,如果上游端口的Lane被定向为使用它在Recovery.RcvrCfg中接收到的EQTS2有序集使用的发送器的保留值1111b,则在更改数据后允许将任何受支持的发发送器预设值用于其发射机设置 速率达到8.0GT/s,但它必须在Recovery.Equalization的Phase 0和Phase 1发送的TS1有序集中发送1111b 作为其发送器预设值。
在环回状态下,Loopback Master 负责通过EQTS1有序集传送其希望从设备使用的发送器和接收器设置,它以2.5 GT/s或5.0 GT/s 的数据速率以及预设或系数进行传输,希望被测设备在TS1有序集下以8.0GT/s数据速率传输的设置。同样,如果通过TS1有序集输入了Polling.Compliance状态,则执行测试的实体必须根据Section 4.2.6.2节中定义的机制发送适当的EQ TS1有序集和系数以供被测设备使用。
IMPLEMENTATION NOTE
Equalization Example
下图是说明两个设备如何完成均衡过程的示例。如果两个端口支持的最大公共数据速率为8.0GT/s,则在8.0GT/s均衡过程结束时,均衡过程就完成了。如果两个端口支持的最大公共数据速率为16.0 GT/s,则在8.0GT/s均衡过程之后执行16.0 GT/s均衡过程。如果在链路处于8.0GT/s数据速率(对于8.0GT/s均衡)或16.0 GT/s(对于16.0GT/s均衡)时,重复执行8.0 GT/s或16.0 GT/s 均衡过程,并且在链路处于执行状态时执行,则可以跳过Phase 0,因为链路不需要回到2.5GT/s或5.0 GT/s(对于8.0GT/s均衡)或8.0GT/s(对于16.0GT/s均衡)以重新发送相同的EQTS2有序集以传送preset值。如果下游端口根据平台中的通道和组件确定不需要对发送器进行微调,则可以选择跳过Phase 2和Phase 3。


IMPLEMENTATION NOTE
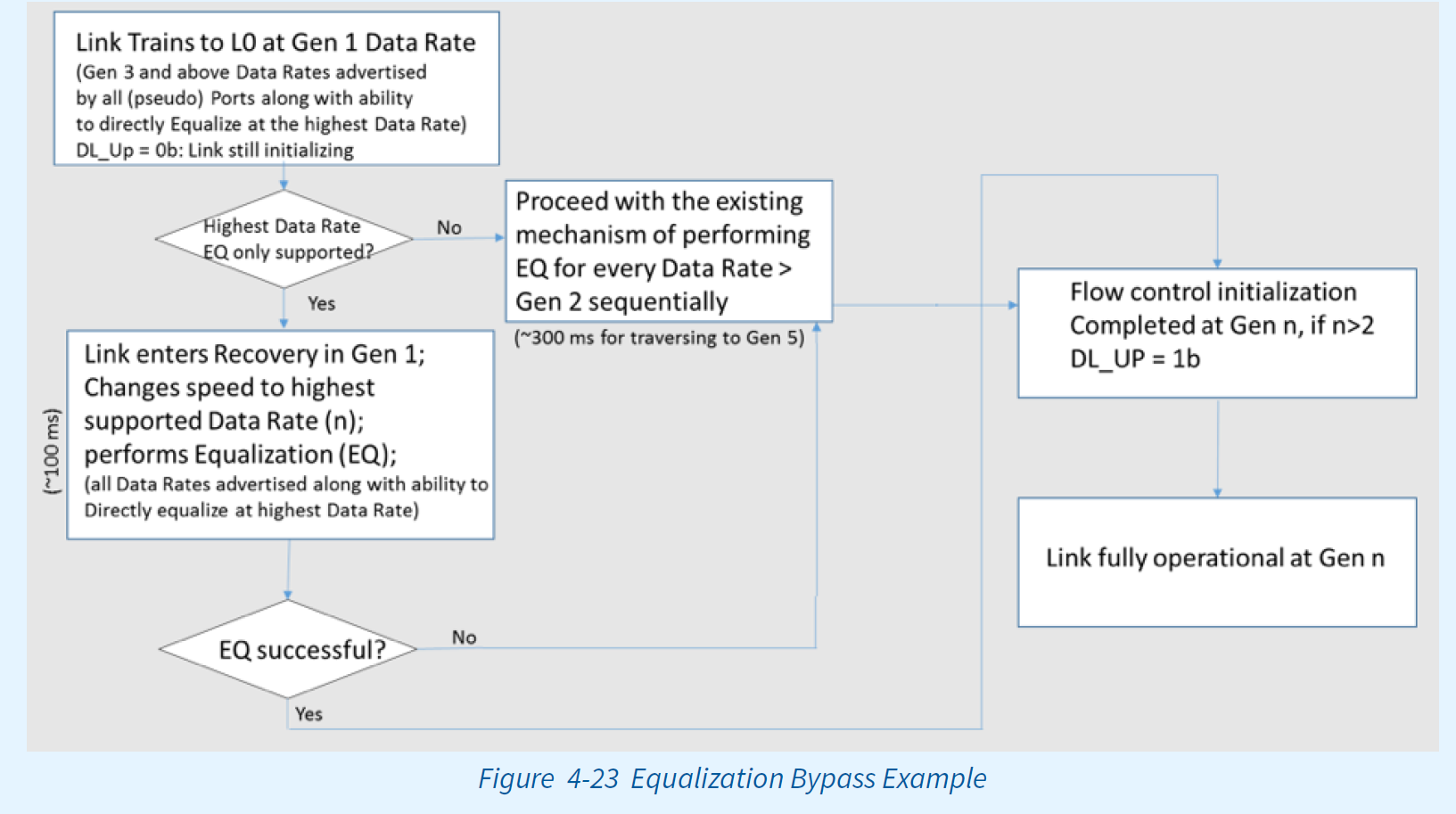
Equalization Bypass Example
下面的流程图提供了一个示例流程,其中链路可以以较低的数据速率bypass均衡,并以最高的支持数据速率进行均衡。例如,当n=5时,链路可以将Gen1数据速率训练为LO,确定所有组件(包括Retimer,如果有的话)都可以bypass的Gen5的均衡,则将数据速率更改为Gen 5。
4.2.3.1 Rules for Transmitter Coefficients
有关系数及其表示的FIR滤波器的说明,请参见Section 8.3.3.1。以下规则适用于通告系数设置和请求系数设置。
-
C-1和 C+1是FIR方程中使用的系数,分别代表前驱和后驱。TS1有序集中传递的pre-cursor和post-cursor值表示其绝对值。C0表示cursor系数设置,并且是一个正数。
-
系数的绝对值之和定义了FS(Full Swing; .FS=|C-1|+C0+|C+1|)。在Phase1中,FS会通知给Link partner。发送器FS范围定义如下:
· 对于Full Swing模式,FS值在24~63之间。
· 对于Reduced Swing模式,FS值在12~63之间。
- 发送器在Phase 1期间通告其LF(Low Frequency)值。这对应于发送器可产生的最小差分电压,该最小差分电压是LF/FS 乘以发送最大差分电压的值。发送器必须确保当下面的公式c)等于LF时,它必须满足Section 8.3.3.9中定义的 VTXEIEOS-FS 和 VTX-EIEOS-RS 的电气要求。
- 在请求Link partner的发送器的一组系数之前,必须满足以下规则。接收到TX系数设置的更新请求后,端口必须验证新请求满足以下条件,如果违反以下任何条件,则拒绝该请求:

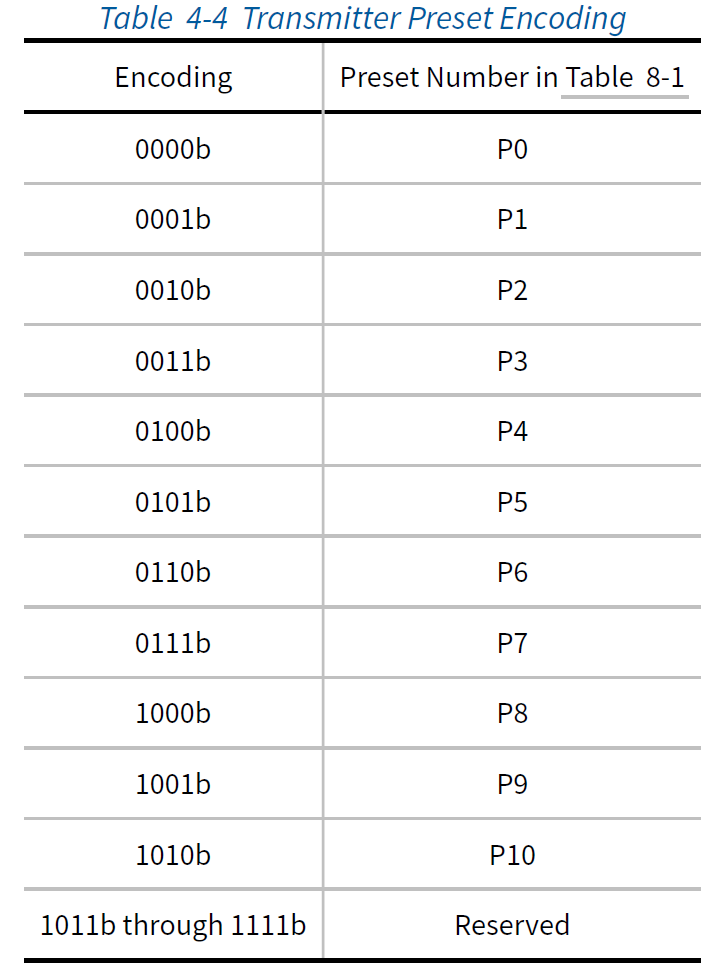
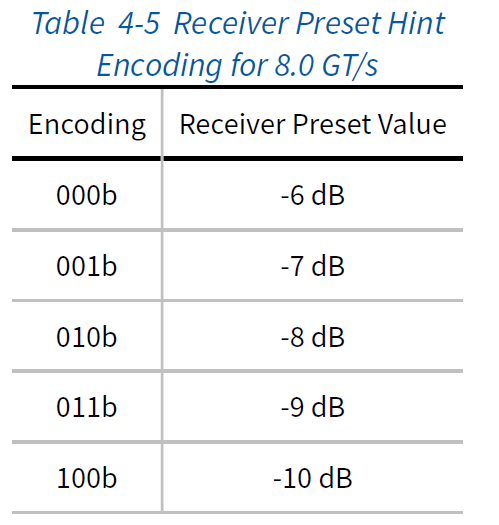
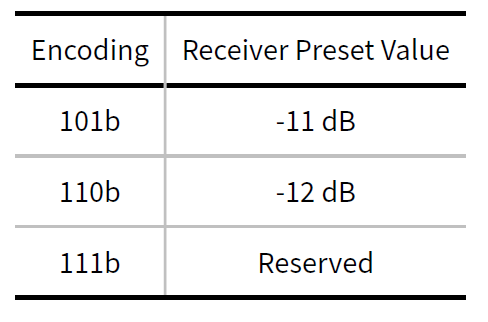
4.2.3.2 Encoding of Presets
发送器和接收器Preset Hint的定义在Chapter 8中描述。Table 4-4和Table 4-5提供了发送器Preset和接收器Preset Hint的编码。接收器Preset Hint是可选的,仅针对8.0GT/s的数据速率进行定义。