【完整源码+数据集+部署教程】无人机自然场景分割系统源码和数据集:改进yolo11-RVB
背景意义
研究背景与意义
随着无人机技术的迅猛发展,基于无人机的自然场景分割系统在环境监测、农业管理、城市规划等领域展现出了广泛的应用潜力。自然场景分割的核心任务是从复杂的图像中准确识别和分离不同的地物类别,如冰、土地、天空和水体等。这一过程不仅对提高无人机的自主导航能力至关重要,也为后续的数据分析和决策提供了重要支持。
近年来,深度学习技术的快速进步为图像分割任务带来了新的机遇。其中,YOLO(You Only Look Once)系列模型因其高效的实时检测能力而受到广泛关注。YOLOv11作为该系列的最新版本,进一步提升了检测精度和速度,适用于动态变化的自然场景。然而,现有的YOLOv11模型在处理复杂自然场景时仍面临一些挑战,例如背景干扰、光照变化以及物体重叠等问题。因此,改进YOLOv11以增强其在自然场景分割中的表现,具有重要的研究价值和实际意义。
本研究旨在基于改进的YOLOv11模型,构建一个高效的无人机自然场景分割系统。我们将利用一个包含4000张随机图像的数据集,该数据集涵盖了冰、土地、天空和水体四个类别。这些图像经过精心标注,能够为模型的训练和评估提供坚实的基础。通过对数据集的深入分析和处理,我们希望能够提升模型在不同自然环境下的分割精度,从而为无人机在复杂场景中的应用提供更为可靠的技术支持。
综上所述,基于改进YOLOv11的无人机自然场景分割系统不仅具有重要的理论研究价值,也将为实际应用提供切实可行的解决方案,推动无人机技术在各个领域的进一步发展。
图片效果
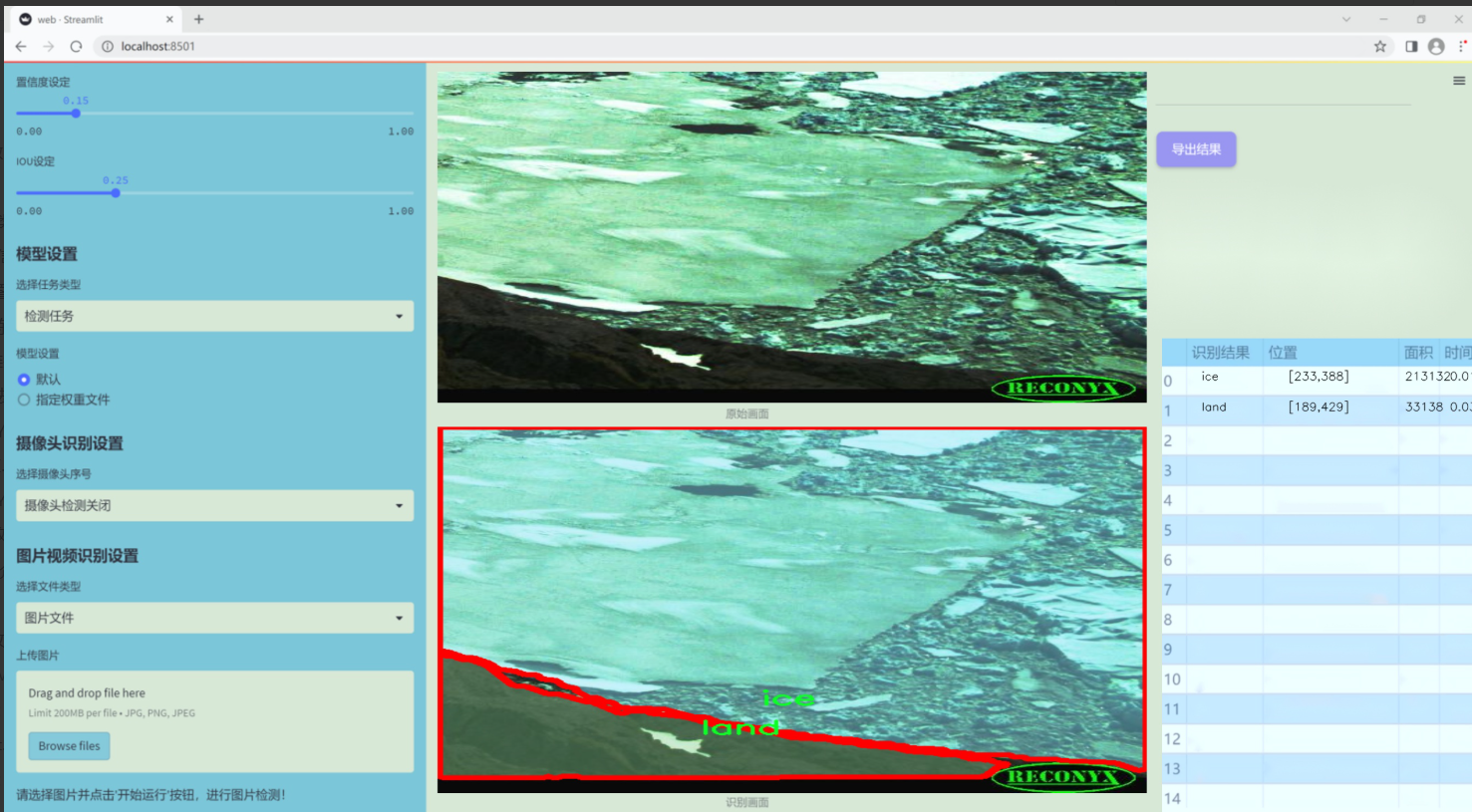
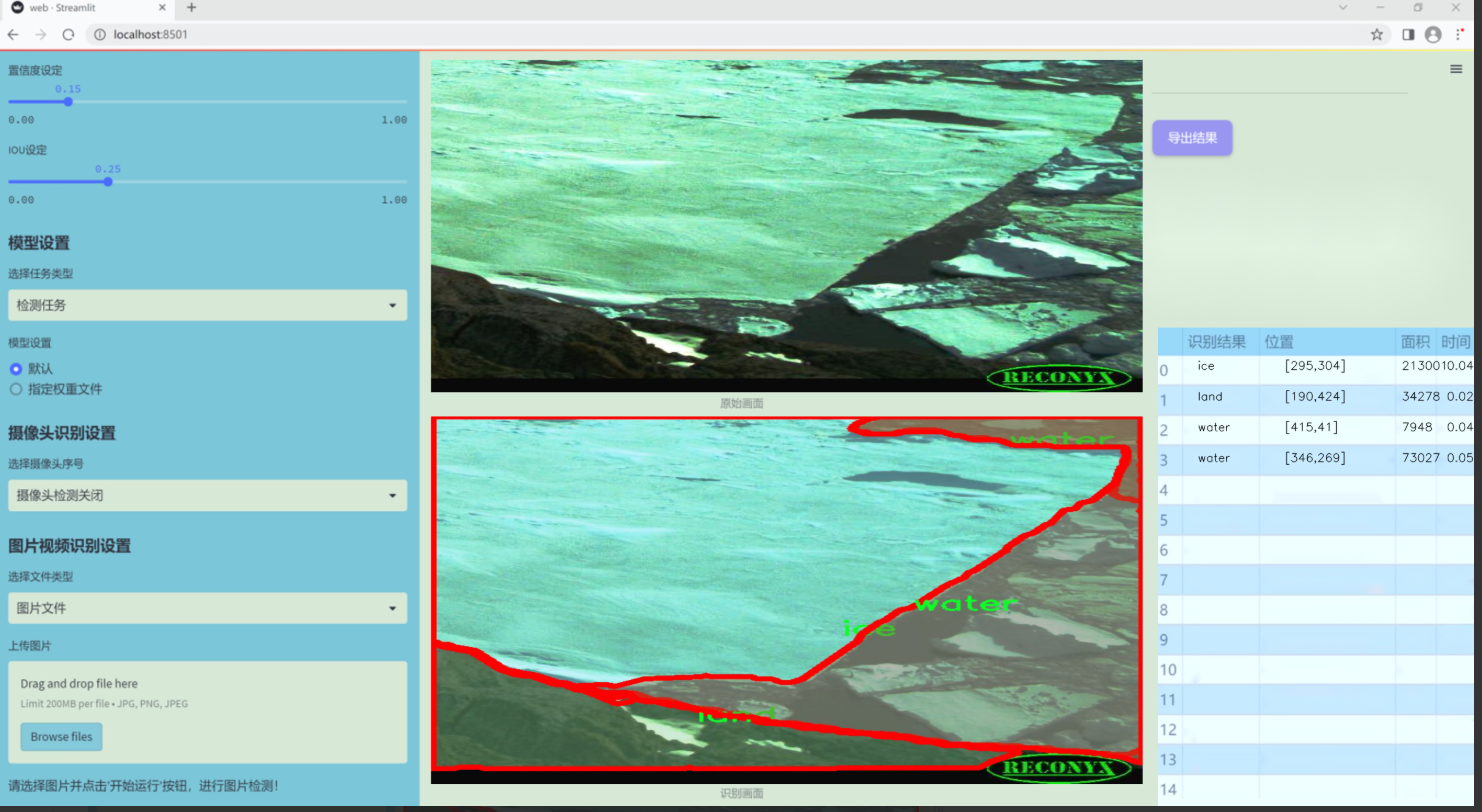
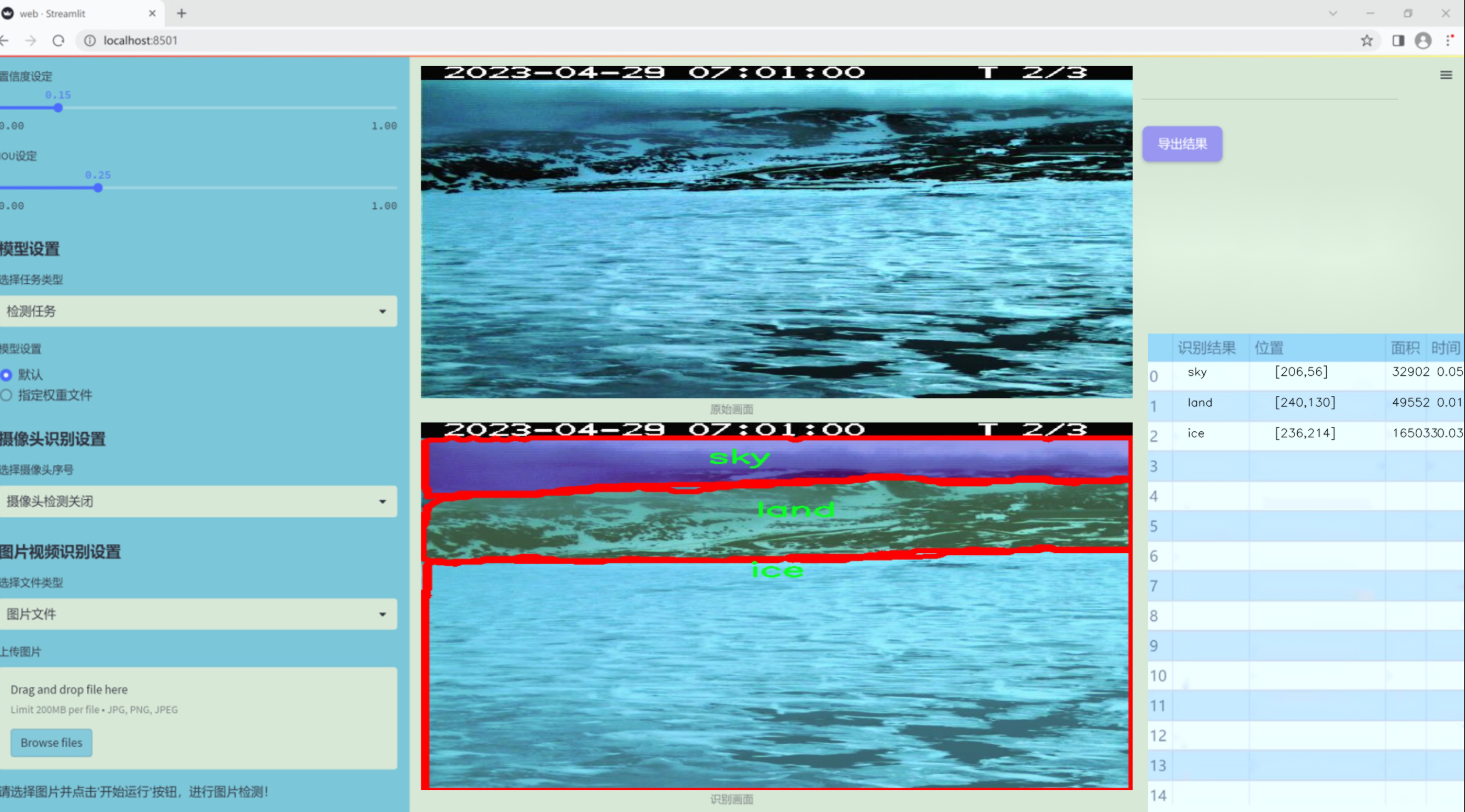
数据集信息
本项目数据集信息介绍
本项目所使用的数据集旨在支持改进YOLOv11的无人机自然场景分割系统,专注于自然环境中不同元素的识别与分割。数据集的主题为“随机图像”,通过收集和整理多样化的自然场景图像,确保模型在实际应用中具备更强的泛化能力和准确性。该数据集包含四个主要类别,分别为冰(ice)、陆地(land)、天空(sky)和水(water),这些类别涵盖了自然环境中常见的元素,为模型提供了丰富的训练素材。
在数据集的构建过程中,我们注重图像的多样性和代表性,确保每个类别的样本数量均衡,且涵盖不同的拍摄角度、光照条件和季节变化。这种多样性不仅增强了模型的鲁棒性,还提高了其在复杂场景下的分割精度。冰类图像可能包括冰川、冰面等,陆地类则涵盖森林、草地和山脉等自然地貌,天空类图像则可能是晴天、阴天及日出日落等不同状态,而水类则包括湖泊、河流和海洋等多种水体。
通过精心挑选和标注的图像,数据集为训练YOLOv11提供了坚实的基础,使其能够有效识别和分割这些自然元素。我们相信,经过充分训练的模型将能够在无人机应用中实现高效的场景理解,为环境监测、资源管理和灾害响应等领域提供有力支持。数据集的设计和实施将为后续的研究和应用奠定良好的基础,推动无人机技术在自然场景分析中的进一步发展。





核心代码
以下是经过简化并注释的核心代码部分,主要包括 ChannelTransformer、Encoder、Block_ViT、Attention_org 和 Channel_Embeddings 类。这些类是实现通道变换器的关键组成部分。
import torch
import torch.nn as nn
import numpy as np
import math
class Channel_Embeddings(nn.Module):
“”“构建通道嵌入,包括补丁嵌入和位置嵌入。”“”
def init(self, patchsize, img_size, in_channels):
super().init()
img_size = (img_size, img_size) # 将图像大小转换为元组
patch_size = (patchsize, patchsize) # 将补丁大小转换为元组
n_patches = (img_size[0] // patch_size[0]) * (img_size[1] // patch_size[1]) # 计算补丁数量
# 定义补丁嵌入层self.patch_embeddings = nn.Sequential(nn.MaxPool2d(kernel_size=5, stride=5), # 最大池化层nn.Conv2d(in_channels=in_channels,out_channels=in_channels,kernel_size=patchsize // 5,stride=patchsize // 5) # 卷积层)# 定义位置嵌入self.position_embeddings = nn.Parameter(torch.zeros(1, n_patches, in_channels))self.dropout = nn.Dropout(0.1) # Dropout层def forward(self, x):"""前向传播,计算嵌入。"""if x is None:return Nonex = self.patch_embeddings(x) # 通过补丁嵌入层x = x.flatten(2) # 展平x = x.transpose(-1, -2) # 转置embeddings = x + self.position_embeddings # 加上位置嵌入embeddings = self.dropout(embeddings) # 应用Dropoutreturn embeddings
class Attention_org(nn.Module):
“”“实现多头注意力机制。”“”
def init(self, vis, channel_num):
super(Attention_org, self).init()
self.vis = vis
self.KV_size = sum(channel_num) # 计算键值对的大小
self.channel_num = channel_num
self.num_attention_heads = 4 # 注意力头的数量
# 定义查询、键、值的线性变换self.query = nn.ModuleList([nn.Linear(c, c, bias=False) for c in channel_num])self.key = nn.Linear(self.KV_size, self.KV_size, bias=False)self.value = nn.Linear(self.KV_size, self.KV_size, bias=False)self.softmax = nn.Softmax(dim=-1) # Softmax层self.attn_dropout = nn.Dropout(0.1) # Dropout层def forward(self, *embeddings):"""前向传播,计算注意力输出。"""multi_head_Q = [query(emb) for query, emb in zip(self.query, embeddings) if emb is not None]multi_head_K = self.key(torch.cat(embeddings, dim=-1)) # 连接所有嵌入multi_head_V = self.value(torch.cat(embeddings, dim=-1))# 计算注意力分数attention_scores = [torch.matmul(Q, multi_head_K) / math.sqrt(self.KV_size) for Q in multi_head_Q]attention_probs = [self.softmax(score) for score in attention_scores]# 应用Dropout并计算上下文层context_layers = [torch.matmul(prob, multi_head_V) for prob in attention_probs]return context_layers
class Block_ViT(nn.Module):
“”“ViT块,包含注意力和前馈网络。”“”
def init(self, vis, channel_num):
super(Block_ViT, self).init()
self.attn_norm = nn.LayerNorm(sum(channel_num), eps=1e-6) # 归一化层
self.channel_attn = Attention_org(vis, channel_num) # 注意力层
self.ffn = nn.ModuleList([nn.Sequential(
nn.Linear(c, c * 4), # 前馈网络
nn.GELU(),
nn.Linear(c * 4, c)
) for c in channel_num])
def forward(self, *embeddings):"""前向传播,计算注意力和前馈网络输出。"""emb_all = torch.cat(embeddings, dim=2) # 连接所有嵌入attn_output = self.channel_attn(*embeddings) # 计算注意力输出# 添加残差连接outputs = [emb + attn for emb, attn in zip(embeddings, attn_output)]# 前馈网络outputs = [ffn(out) for ffn, out in zip(self.ffn, outputs)]return outputs
class Encoder(nn.Module):
“”“编码器,包含多个ViT块。”“”
def init(self, vis, channel_num):
super(Encoder, self).init()
self.layer = nn.ModuleList([Block_ViT(vis, channel_num) for _ in range(1)]) # 只包含一个块
def forward(self, *embeddings):"""前向传播,依次通过每个块。"""for layer_block in self.layer:embeddings = layer_block(*embeddings) # 通过块return embeddings
class ChannelTransformer(nn.Module):
“”“通道变换器,整合各个部分。”“”
def init(self, channel_num=[64, 128, 256, 512], img_size=640, vis=False, patchSize=[40, 20, 10, 5]):
super().init()
self.embeddings = nn.ModuleList([Channel_Embeddings(patchSize[i], img_size // (2 ** (i + 2)), channel_num[i]) for i in range(len(channel_num))])
self.encoder = Encoder(vis, channel_num) # 编码器
def forward(self, en):"""前向传播,计算嵌入和编码。"""embeddings = [emb(en[i]) for i, emb in enumerate(self.embeddings) if en[i] is not None]encoded = self.encoder(*embeddings) # 编码return encoded # 返回编码后的嵌入
代码说明
Channel_Embeddings: 负责将输入图像转换为补丁嵌入和位置嵌入。
Attention_org: 实现多头注意力机制,计算注意力分数并生成上下文层。
Block_ViT: 由注意力层和前馈网络组成的块,包含残差连接。
Encoder: 包含多个 Block_ViT,负责处理输入的嵌入。
ChannelTransformer: 整合所有部分,完成输入图像的嵌入、编码和输出。
这个简化版本保留了核心功能,并添加了详细的中文注释,以帮助理解每个部分的作用。
这个程序文件 CTrans.py 实现了一个基于通道的变换器(Channel Transformer),主要用于图像处理任务。代码中定义了多个类,每个类负责不同的功能,下面是对这些类及其功能的详细说明。
首先,文件导入了一些必要的库,包括 PyTorch 和 NumPy,并定义了一些基础的模块。Channel_Embeddings 类用于构建图像的嵌入表示。它接受图像的尺寸、补丁大小和输入通道数,并通过最大池化和卷积操作生成补丁嵌入。然后,它为每个补丁添加位置嵌入,并应用 dropout 以防止过拟合。
接下来是 Reconstruct 类,它负责将嵌入的特征图重建为更高分辨率的图像。它通过卷积层和上采样操作来实现这一点,并使用批归一化和 ReLU 激活函数来增强模型的非线性表达能力。
Attention_org 类实现了多头自注意力机制。它接收多个嵌入作为输入,计算查询、键和值的线性变换,并通过点积计算注意力分数。然后,它使用 softmax 函数计算注意力权重,并通过 dropout 进行正则化。最终,它将注意力权重应用于值,生成上下文层。
Mlp 类实现了一个简单的多层感知机,包含两个全连接层和一个 GELU 激活函数。它的主要作用是对输入进行非线性变换,并通过 dropout 防止过拟合。
Block_ViT 类是一个变换器块,包含了自注意力机制和前馈网络。它首先对输入的嵌入进行层归一化,然后通过自注意力模块处理嵌入,接着通过前馈网络进一步处理。最后,它将输入和输出相加以实现残差连接。
Encoder 类由多个 Block_ViT 组成,负责将输入的嵌入通过多个变换器块进行编码。它也包含了层归一化的操作,以确保模型的稳定性。
ChannelTransformer 类是整个模型的核心,整合了上述所有组件。它初始化了不同尺度的嵌入、编码器和重建模块,并在前向传播中处理输入图像。它将输入图像划分为多个通道,分别进行嵌入、编码和重建,最后将重建的特征图与原始输入相加。
最后,GetIndexOutput 类用于从模型的输出中提取特定索引的结果,便于后续处理。
总体来说,这个程序实现了一个复杂的图像处理模型,利用了通道注意力机制和多层感知机的组合,旨在提高图像特征的表达能力和重建质量。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式