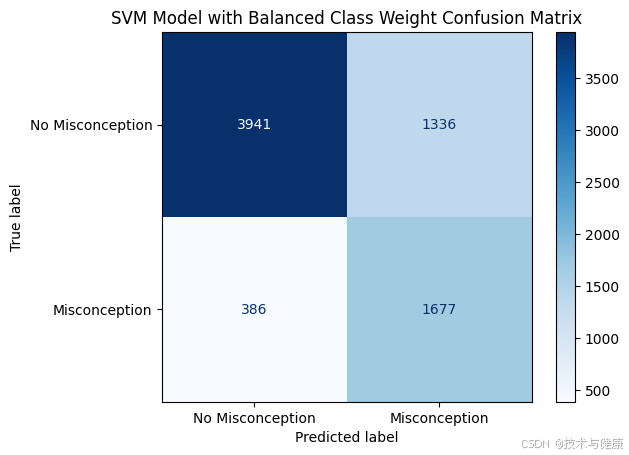
【SVM smote】MAP - Charting Student Math Misunderstandings
针对数据不平衡问题,用调整类别权重的方式来处理数据不平衡问题,同时使用支持向量机(SVM)模型进行训练。
我们通过使用 SMOTE(Synthetic Minority Over-sampling Technique)进行过采样,增加少数类别的样本。。
import pandas as pd
import string
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
from imblearn.over_sampling import SMOTE# Step 1: Load the dataset
file_path = '/content/train.csv' # 修改为实际文件路径
data = pd.read_csv(file_path)# Step 2: Clean the student explanation text (remove punctuation and lower case)
def clean_text(text):text = text.lower() # Convert to lower casetext = ''.join([char for char in text if char not in string.punctuation]) # Remove punctuationreturn text# Apply the cleaning function to the 'StudentExplanation' column
data['cleaned_explanation'] = data['StudentExplanation'].apply(clean_text)# Step 3: Feature extraction using TF-IDF
vectorizer = TfidfVectorizer(stop_words='english', max_features=5000)
X = vectorizer.fit_transform(data['cleaned_explanation'])# Step 4: Prepare labels (Misconception column)
# We will predict if the explanation contains a misconception or not
data['Misconception'] = data['Misconception'].fillna('No_Misconception')# Convert labels to binary: 'No_Misconception' -> 0, any other label -> 1
y = data['Misconception'].apply(lambda x: 0 if x == 'No_Misconception' else 1)# Step 5: Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Step 16: Apply SMOTE for over-sampling the minority class
smote = SMOTE(random_state=42)
X_train_resampled, y_train_resampled = smote.fit_resample(X_train, y_train)# Step 7: Train an SVM model with the resampled data
svm_model = SVC(kernel='linear', class_weight='balanced', random_state=42)
svm_model.fit(X_train_resampled, y_train_resampled)# Step 8: Make predictions
y_pred_svm = svm_model.predict(X_test)# Step 9: Evaluate the model
print(classification_report(y_test, y_pred_svm))# Step 10: Plot confusion matrix
cm_weighted = confusion_matrix(y_test, y_pred_svm)# Use ConfusionMatrixDisplay to display the confusion matrix
disp = ConfusionMatrixDisplay(confusion_matrix=cm_weighted, display_labels=['No Misconception', 'Misconception'])
disp.plot(cmap=plt.cm.Blues)
plt.title('SVM Model with Balanced Class Weight Confusion Matrix')
plt.show()
precision recall f1-score support0 0.91 0.75 0.82 52771 0.56 0.81 0.66 2063accuracy 0.77 7340macro avg 0.73 0.78 0.74 7340
weighted avg 0.81 0.77 0.78 7340