Redis常见线上问题
文章目录
- Redis常见线上问题
-
- 引言
-
- 报告背景与目的
- Redis版本与环境说明
- 性能瓶颈问题
-
- 慢查询分析与优化
- 高CPU与网络延迟
- 内存管理问题
-
- 内存碎片成因与优化
- BigKey与内存溢出
- 数据一致性与高可用问题
-
- 主从同步延迟
- 脑裂问题与解决方案
- 持久化机制问题
-
- RDB与AOF对比
-
- 核心特性对比
- 适用场景分析
- 混合持久化方案
- 混合持久化实践
-
- 电商场景下的恢复效率提升案例
- 不同数据量下的性能对比
- 配置与优化建议
- 安全问题
-
- 未授权访问与ACL控制
- 密码策略与漏洞修复
- 运维管理问题
-
- 监控与告警
- 版本选择与升级
- 解决方案总结与最佳实践
-
- 核心问题解决方案对比
-
- 一、持久化策略选择决策树
- 二、分布式协调方案对比:分布式锁 vs Lua原子操作
- 三、内存淘汰策略选择
- 四、行业最佳实践总结
- 生产环境配置示例
-
- redis.conf优化模板
- 结论与展望
-
- 报告总结
- 未来趋势
Redis常见线上问题
引言
报告背景与目的
随着Redis在现代应用中的广泛应用,其功能与性能持续演进。截至2025年,Redis已迭代至7.0版本,引入多AOF(Append-Only File)、Listpack等重要特性,并从传统缓存工具逐步向多模型数据库转型,以应对全球每天数亿次缓存请求的高并发场景[1]。在此过程中,Redis的核心问题逐渐呈现多样化特征,主要涵盖性能瓶颈、内存管理、数据一致性、持久化机制(如RDB与AOF)、安全及运维等关键领域[1][2]。
本报告旨在通过系统梳理Redis的版本特性演进与核心问题分类,为线上环境提供全面的问题诊断方法与优化方案,助力提升Redis部署的稳定性、可靠性与性能表现。
Redis版本与环境说明
性能瓶颈问题
慢查询分析与优化
Redis慢查询是指执行时间超过预设阈值的命令,其分析与优化需从配置、检测、原因定位及策略实施等环节系统推进。在配置层面,通过调整slowlog-log-slower-than和slowlog-max-len参数可启用慢查询日志记录。例如,将slowlog-log-slower-than设为1000微秒(默认10000微秒),可捕获执行耗时超过1毫秒的命令;slowlog-max-len建议设置为512(默认128)以保留更多日志数据,便于分析历史趋势[3][4]。通过SLOWLOG GET命令可直接获取慢查询日志详情,包括命令标识ID、执行时间戳、耗时及具体命令参数,为问题定位提供原始数据[3]。
慢查询的产生源于外部环境与内部操作两方面因素。外部因素包括网络延迟、CPU资源竞争及内存不足;内部因素则主要涉及高复杂度命令(如KEYS、SORT、SUNION)和BigKey操作(如对包含10万条数据的列表执行DEL或SET)[3][5]。例如,KEYS *命令需遍历全库键值对,复杂度为O(N),在数据量较大时易导致阻塞;SORT命令对包含N个元素的集合排序时复杂度为O(N+M*log(M))(M为返回结果数量),数据规模增长会显著延长执行时间[5]。
针对慢查询问题,可采用多种优化策略,不同策略的性能提升效果存在显著差异:
批量操作与Pipeline优化:通过MGET、MSET等批量命令可减少网络往返次数。例如,在Lua脚本中使用MGET处理10个键仅需20微秒,而循环调用GET需51微秒,性能提升约2.5倍[6]。Pipeline技术通过一次性发送多个命令并批量接收结果,可将QPS提升2-3倍。测试显示,在批量设置10万用户标签场景中,Pipeline结合Lua脚本的原子性操作效率显著优于逐条执行命令[1]。与MGET相比,Pipeline在处理大量键时更具灵活性,但需注意命令打包数量(建议单次不超过100条)以避免额外延迟[7]。
Lua脚本优化:Lua脚本可在Redis服务端原子执行多步逻辑,减少网络交互开销。在限流场景中,Java客户端逐条执行命令的QPS为1.2万,而Lua脚本实现的QPS可达2.8万,性能提升133%[8]。电商秒杀场景下,普通多命令操作因2次网络往返平均耗时15ms,QPS约2000;Lua脚本通过单次网络往返将耗时降至3ms,QPS提升至8000+[9]。此外,脚本缓存(如EVALSHA命令)可进一步降低重复执行开销,其性能与INCR、GET等原生命令相当(约22000次/秒)[10]。
命令与数据结构优化:替换高复杂度命令是降低慢查询风险的关键。例如,用SCAN替代KEYS进行键遍历(SCAN通过游标分批返回结果,复杂度O(1)),用SSCAN替代SMEMBERS迭代集合元素,避免一次性返回大量数据[3][5]。数据结构层面,Redis 7.0采用Listpack替代Ziplist存储字符串列表,在包含10万条用户标签的场景中,内存占用减少23%(从82MB降至63MB),范围查询性能提升35%,间接降低了因内存操作耗时过长导致的慢查询风险[1]。
慢查询的持续监控可通过第三方工具实现。例如,DBbrain支持实例与Proxy双维度慢日志分析,可查看CPU使用率、慢查询数及分段耗时统计;阿里云DAS可展示慢日志趋势、事件分布及节点级详情,并支持最近一个月数据的导出与告警[11][12]。结合Prometheus与Redis Exporter,通过increase(redis_slowlog_count[1h])等指标可量化慢查询频率,配合Grafana可视化实现实时监控与预警[13]。
综上,慢查询优化需结合业务场景选择适配策略:批量操作与Pipeline适用于高频小命令场景,Lua脚本优势在原子性多步操作,而命令替换与数据结构优化是长期性能保障的基础。通过配置调优、工具监控与策略组合,可显著降低慢查询发生率,提升Redis服务稳定性。
高CPU与网络延迟
高CPU使用率和网络延迟是Redis在高并发场景下的常见性能瓶颈,可能导致吞吐量下降和响应延迟增加。以下结合具体案例与测试数据,从多线程I/O优化、CPU负载管理及网络配置影响三方面展开分析。
在性能优化手段中,多线程I/O是提升Redis高并发处理能力的关键技术。Redis 6.0及以上版本引入多线程I/O机制,通过配置io-threads参数可有效提升网络密集型应用的性能[14]。实际测试显示,在单机环境下,面对100,000个并发请求时,Redis 5(单线程I/O)的QPS约为2,571,而Redis 6启用多线程I/O后QPS提升至约4,349,性能提升40%;在单线程redis-benchmark测试中,Redis 6默认吞吐与Redis 5相近(约6,400 req/s),但启用多线程I/O后吞吐飙升至12,051 req/s,增幅达88%[15]。对于Redis 7,多线程I/O的优化效果呈现场景差异性:部分报告显示Redis 7.8.2在高并发场景下相较Redis 6.x降低延迟10–15%,也有测试指出其平均性能比Redis 6慢3–26%,但托管服务ElastiCache for Redis 7.1在AWS环境中相较6.0版本吞吐量提升达72%,进一步验证了多线程I/O在高并发场景下的优化潜力[15]。
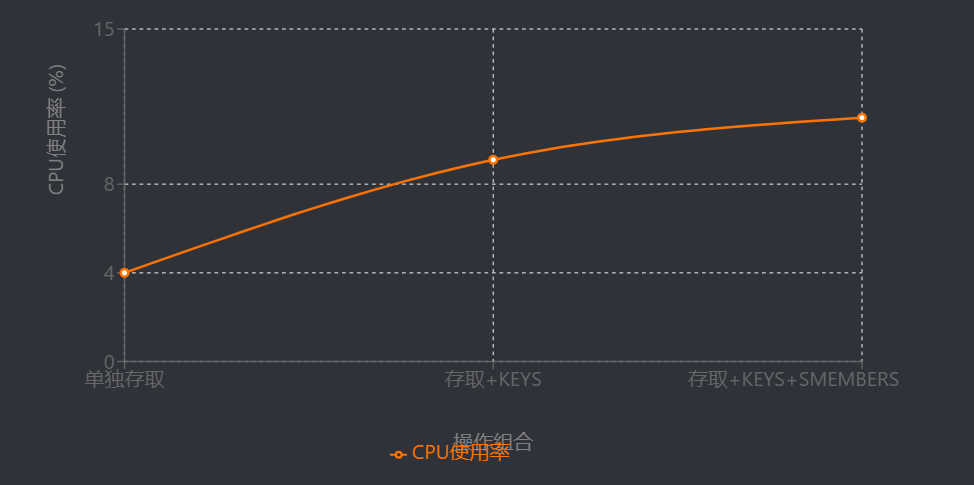
高CPU负载是导致性能下降的重要因素。某生产环境中,Redis集群主节点CPU使用率接近100%时,节点间通信出现明显延迟波动[16]。此外,阻塞操作(如KEYS、SMEMBERS)会显著增加CPU消耗。测试数据显示,当同时执行存取操作、KEYS查询及SMEMBERS集合操作时,CPU使用率从单独存取时的4.0%升至11.0%[17]。因此,减少阻塞命令、合理配置多线程I/O以平衡CPU资源分配,是缓解CPU瓶颈的核心策略。
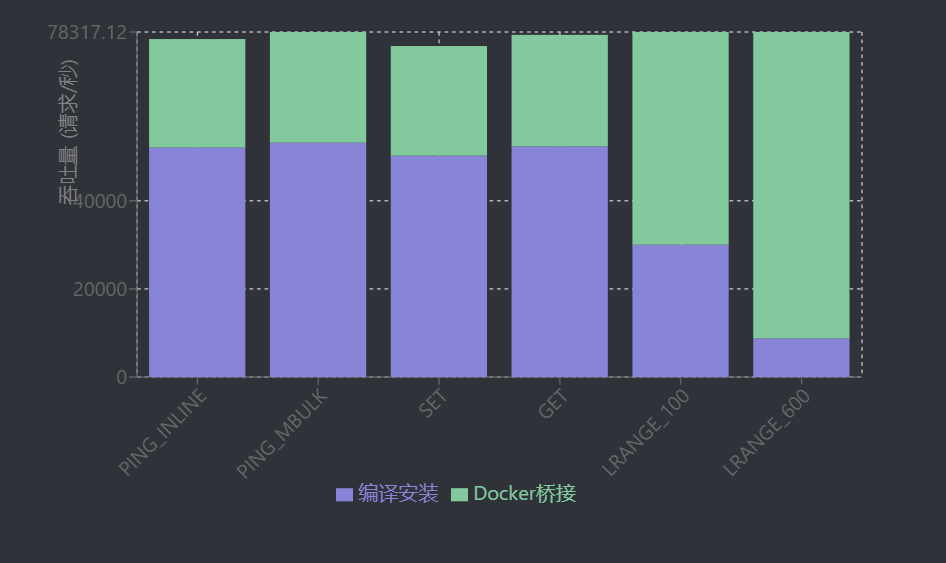
网络配置对Redis性能的影响同样显著。不同网络模式下的性能差异可通过对比测试体现:在同一机器上,Docker桥接网络模式下Redis的各项操作吞吐量均显著低于编译安装方式。例如,SET操作吞吐量从编译安装的50,251.26 requests/s降至24,875.62 requests/s,P50延迟从0.671 ms增至1.199 ms,LRANGE等批量操作性能下降更为明显[18]。这表明优化网络路径(如客户端与服务端同局域网部署、减少网络转发层级)对降低延迟、提升吞吐量具有实际意义。
综上,多线程I/O通过并行处理网络请求显著提升高并发场景下的吞吐量,是优化Redis性能的重要手段;同时,需关注CPU负载均衡与网络路径优化,避免高CPU使用率和网络延迟成为性能瓶颈。
内存管理问题
内存碎片成因与优化
BigKey与内存溢出
BigKey指存储大量数据的键,通常表现为String类型超过10KB、List/Hash/Set/ZSet元素数量超过1万,或包含数万字段的哈希、数百万元素的列表等结构[19][20]。此类键对Redis的持久化和复制过程存在显著影响:在持久化阶段,BigKey会导致RDB文件过大,增加IO写入耗时和存储开销,AOF重写时也可能因单次处理大量数据引发主线程阻塞;在复制过程中,主节点向从节点同步BigKey会占用大量网络带宽,延长数据同步周期,甚至引发复制中断或主从数据不一致[3]。此外,对BigKey的操作(如DEL、SET)可能直接阻塞Redis服务,例如对包含100万条数据的列表执行DEL命令会导致服务长时间无响应[3]。
针对BigKey问题,实践中常采用拆分策略将其分解为多个小键。以用户数据存储为例,可按用户ID哈希分片存储,将原本集中在单个键的大量用户信息分散到多个子键中。例如,通过哈希函数对用户ID进行分片,将用户数据分散至不同的子键空间,示例代码如下:
数据一致性与高可用问题
主从同步延迟
Redis主从同步延迟是影响数据一致性的关键问题,尤其在高并发场景下可能导致严重的数据不一致风险。Redis 7.0引入的无盘复制(diskless replication)机制通过直接将RDB文件从主节点通过网络传输至从节点,避免了磁盘I/O开销,在一定程度上优化了同步效率。其核心配置包括启用无盘复制(repl-diskless-sync yes)及设置传输延迟(repl-diskless-sync-delay),但该机制仍可能受网络带宽、主节点CPU负载等因素影响,导致RDB文件生成或传输延迟,进而引发同步滞后。
同步