从0到1搭建一个Rag引擎(ollama+Qwen3)
介绍
背景概念
大型语言模型(LLM)在生成语言时,可能会产生幻觉或不准确的结果。这些问题包括
- 信息误导:模型生成的内容可能基于不准确或过时的信息。
- 知识更新滞后:模型无法访问最新的信息,尤其是在专业领域。
- 推理能力不足:LLM 在面对复杂推理任务时,难以提供高效且准确的结果
为了解决这些问题,检索增强生成(Retrieval-Augmented Generation, RAG)应运而生。RAG 通过先从数据库中检索与问题相关的信息,再基于检索到的内容进行回答生成,极大地提升了模型输出的准确性和相关性。RAG 不仅提高了知识更新的效率,还显著增强了生成内容的可追溯性,使其在实际应用中更具实用性和可信度。
- RAG技术也被称作知识检索增强技术,旨在为大模型灵活的提供外部知识库支持,以拓展大模型知识边界
- 对于大模型来说,知识直接代表其功能水平,合理的挂载外部知识库,不仅能进行更大范围选题的问答,同时也有助于大模型构建Agent能力增强.
RAG技术诞生的原因:大模型最大对话上下文限制
- 尽管大模型的训练数据看似可以无限增加,但在执行每一次对话任务的时候,受到算法原理限制,大模型可以处理的文本长度是有限的
- 此外,由于单次训练的成本高昂、训练文本具有时效性以及少量信息文本无法被模型学习,这就导致大模型本身对于专业性知识和实效性较强的知识响应能力很弱。
- 因此希望能有一种方法,每次大模型回复之前,都可以把问题相关的文本内容输入给大模型,这样一来既节省了成本、同时具备极强的可拓展性;又能提高模型响应速度
- 问题在于,如何把问题相关的文档片段“检索出来”
RAG技术核心步骤与通用优化方法
文档切分
- 根据关键字符切分或根据字符串长度切分、以及滑动窗口切分等;
- 围绕不同类型文本,可选不同切分策略;
- 文本数据清洗占绝大多数时间,也是本环节提效的关键
文档匹配与输入
- 根据Embedding进行文本词向量化处理,并根据余弦相似度判断和问题相关的文档;
- 选择更好的Embedding模型、以及匹配后文本增强、重拍等,是优化的关键;
模型问答
- 灵活判断文档段落内容是否可用、并根据文档进行回答;
- 真实性检验、后处理、用户意图判断是本环节优化的关键;
一个RAG系统的核心组件说明
为了实现 RAG 模型,需要以下几个核心模块:
- 向量化模块:用于将文档片段转换为向量表示,以便后续检索。
- 文档加载与切分模块:负责加载文档并将其切分为若干易于处理的文档片段。
- 数据库模块:用于存储文档片段及其对应的向量表示。
- 检索模块:根据用户输入的查询,检索与其相关的文档片段。
- 生成模块:调用语言模型生成基于检索信息的回答。
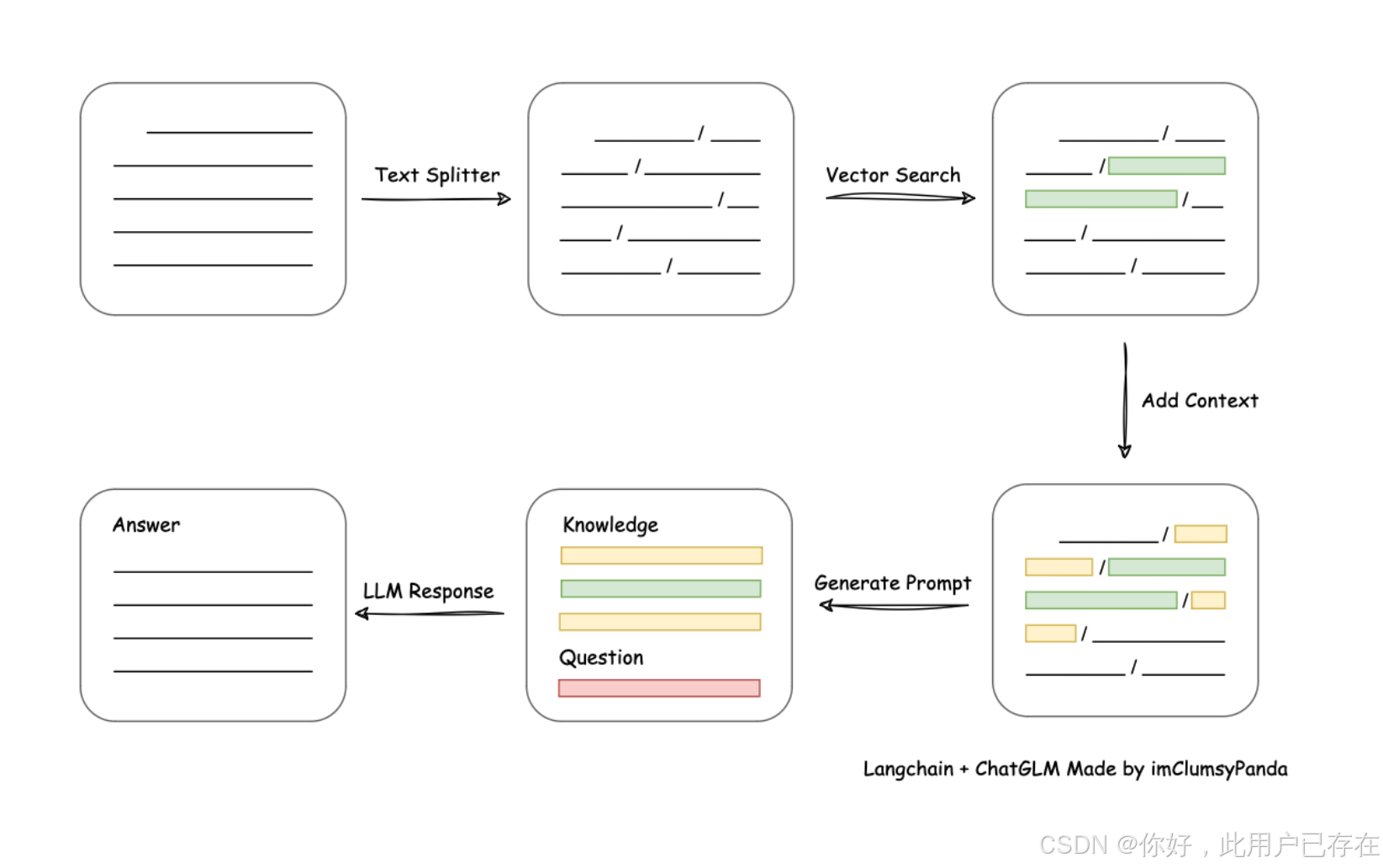
基本构成如下图所示:
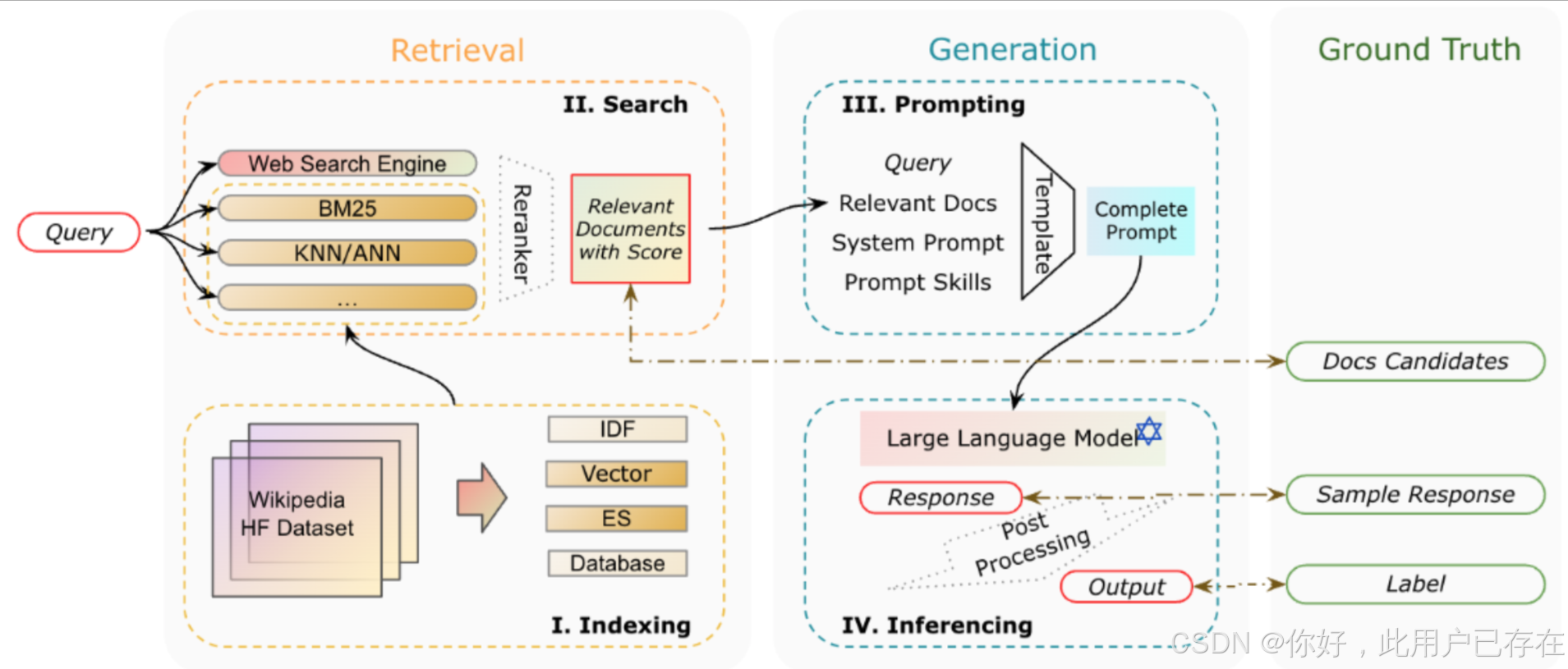
而这些组件,也是我们接下来手动构建一个RAG系统的基础。
据此我们也可以看出一个RAG系统的基本流程:
- 索引:将文档库分割成较短的 Chunk,并通过编码器构建向量索引。
- 检索:根据问题和 chunks 的相似度检索相关文档片段。
- 生成:以检索到的上下文为条件,生成问题的回答。
这些模块共同构成了一个简易 RAG 的核心架构。每个模块在模型的不同阶段发挥作用,确保查询的处理从检索到生成都有条不紊地进行。
系统构建
文本向量化模块创建
在自然语言处理和机器学习领域中,Embedding 是将文本转化为数值向量的常用方法。通过这种方式,模型可以衡量不同文本之间的相似性,进而应用于如搜索、分类、推荐等多个领域。
如今来说,各家厂商的Embedding 效果都大差不差,本文采用的Embedding 模型是Qwen3-Embedding
Qwen3-Embedding下载
进入魔塔社区官网,搜索Qwen3-Embedding,如下所示,会显示出目前Qwen3支持的embedding模型,可根据自己的电脑情况选择合适的模型
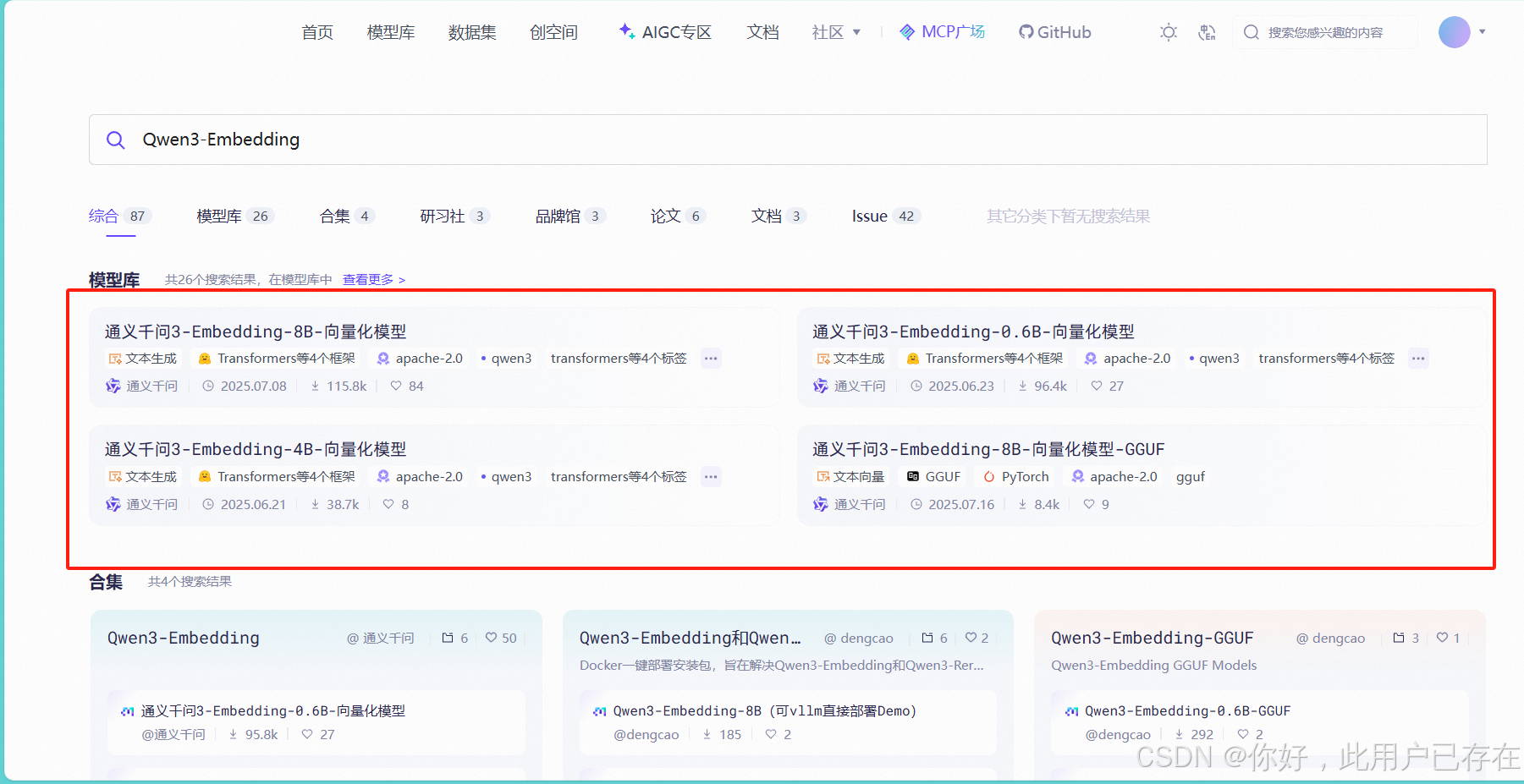
以Qwen3-Embedding-4B为例,直接点击下方模型链接
进入模型详情页面后,点击下载模型,官方会给出各种下载方式
本文采取modelscope方式下载,按照官方给出的代码,需要首先安装modelscope
pip install modelscope然后下载完整模型库
modelscope download --model Qwen/Qwen3-Embedding-4B使用示例
按照官方给出的使用示例,把刚才下载的模型路径进行替换
from sentence_transformers import SentenceTransformer# Load the model
model = SentenceTransformer("model/modelscope/hub/models/Qwen/Qwen3-Embedding-4B")# We recommend enabling flash_attention_2 for better acceleration and memory saving,
# together with setting `padding_side` to "left":
# model = SentenceTransformer(
# "Qwen/Qwen3-Embedding-4B",
# model_kwargs={"attn_implementation": "flash_attention_2", "device_map": "auto"},
# tokenizer_kwargs={"padding_side": "left"},
# )# The queries and documents to embed
queries = ["What is the capital of China?","Explain gravity",
]
documents = ["The capital of China is Beijing.","Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun.",
]# Encode the queries and documents. Note that queries benefit from using a prompt
# Here we use the prompt called "query" stored under `model.prompts`, but you can
# also pass your own prompt via the `prompt` argument
query_embeddings = model.encode(queries, prompt_name="query")
document_embeddings = model.encode(documents)# Compute the (cosine) similarity between the query and document embeddings
similarity = model.similarity(query_embeddings, document_embeddings)
print(similarity)我们也可以自己写相似的文本,观察embedding后的向量是什么样子,同时两两计算相似度
text1 = '我喜欢吃苹果'
text2 = "苹果是我最喜欢吃的水果"
text3 = "我喜欢用苹果手机"vector1 = model.encode(text1)
vector2 = model.encode(text2)
vector3 = model.encode(text3)print(vector1)
print(vector2)
print(vector3)# Compute the (cosine) similarity between the vectors
similarity1 = model.similarity(vector1, vector2)
similarity2 = model.similarity(vector1, vector3)
similarity3 = model.similarity(vector3, vector2)print(similarity1)
print(similarity2)
print(similarity3)观察发现,text1和text2的相似度是最高的,这符合我们的直觉
tensor([[0.8355]])
tensor([[0.7432]])
tensor([[0.7494]])
创建环境变量
为了方便,我们将模型路径及后续使用到的模型api_key等写入一个环境变量文件中,方便维护代码
.env
BASE_URL=http://localhost:11434/v1/
MODEL=qwen3:1.7b
OPENAI_API_KEY=ollama
LOCAL_MODEL_PATH=model/modelscope/hub/models/Qwen/Qwen3-Embedding-4BEMBEDDING_URL=http://localhost:11434/v1/embeddings/
EMBEDDING_API_KEY=ollama
EMBEDDING_MODEL=text-embedding-3-large模块构建
体验完Qwen3-embedding模型之后,我们接下来将借助其实现我们的RAG系统的向量化模块。向量化是 RAG 的基础,它的作用是将文档片段转化为向量表示,便于后续的检索操作。在这个过程中,我们将实现一个向量化类,用来将文本片段映射成向量。
为了便于扩展和未来可能使用不同的模型,我们首先编写一个 Embedding 基类。该基类定义了获取文本向量表示的方法,同时包含一个计算两个向量之间余弦相似度的功能。这样,如果我们未来使用不同的向量化模型,只需继承该基类并重写向量获取的逻辑,而不需要重复编写相似度计算部分。
embedding.py
import os
from typing import List
import numpy as np
from sentence_transformers import SentenceTransformer
from dotenv import load_dotenvclass BaseEmbeddings:"""向量化的基类,用于将文本转换为向量表示。不同的子类可以实现不同的向量获取方法。"""def __init__(self,is_api: bool) -> None:"""初始化基类。参数:path (str) - 如果是本地模型,path 表示模型路径;如果是API模式,path可以为空is_api (bool) - 表示是否使用API调用,如果为True表示通过API获取Embedding"""self.is_api = is_apidef get_embedding(self, text: str, model: str) -> List[float]:"""抽象方法,用于获取文本的向量表示,具体实现需要在子类中定义。参数:text (str) - 需要转换为向量的文本model (str) - 所使用的模型名称返回:list[float] - 文本的向量表示"""raise NotImplementedErrordef cosine_similarity(vector1: List[float], vector2: List[float]) -> float:"""计算两个向量之间的余弦相似度,用于衡量它们的相似程度。参数:vector1 (list[float]) - 第一个向量vector2 (list[float]) - 第二个向量返回:float - 余弦相似度值,范围从 -1 到 1,越接近 1 表示向量越相似"""dot_product = np.dot(vector1, vector2) # 向量点积magnitude = np.linalg.norm(vector1) * np.linalg.norm(vector2) # 向量的模if not magnitude:return 0return dot_product / magnitude # 计算余弦相似度我们在这个基类基础上,可以通过继承它来实现具体的模型。如完成我们自己通过Qwen3模型构造的Embedding类,只需重写 `get_embedding` 方法即可。
class SentenceTransformerEmbedding(BaseEmbeddings):def __init__(self, is_api: bool = True) -> None:"""初始化类,设置 OpenAI API 客户端,如果使用的是 API 调用。参数:path (str) - 本地模型的路径,使用API时可以为空is_api (bool) - 是否通过 API 获取 Embedding,默认为 True"""load_dotenv()super().__init__(is_api)if self.is_api:from openai import OpenAIself.client = OpenAI()self.client.api_key = os.getenv("EMBEDDING_API_KEY") self.client.base_url = os.getenv("EMBEDDING_URL") self.model = os.getenv("EMBEDDING_MODEL") if self.is_api==False:self.path = os.getenv("LOCAL_MODEL_PATH") self.model=SentenceTransformer(self.path)def get_embedding(self, text: str) -> List[float]:if self.is_api==False:return self.model.encode(text)else:text = text.replace("\n", " ")# 调用 OpenAI API 获取文本的向量表示return self.client.embeddings.create(input=[text], model=self.model).data[0].embeddingdef cosine_similarity(self, vector1: List[float], vector2: List[float]) -> float:return self.model.similarity(vector1, vector2)这样设计的结构让我们可以轻松替换或扩展向量化模型,而不需要改变整体框架。以下是使用示例
#以下是测试代码
if __name__ == '__main__':text1 = '我喜欢吃苹果'text2 = "苹果是我最喜欢吃的水果"text3 = "我喜欢用苹果手机"embeding=SentenceTransformerEmbedding(is_api=False)vector1=embeding.get_embedding(text1)vector2=embeding.get_embedding(text2)vector3=embeding.get_embedding(text3)sim=embeding.cosine_similarity(vector1,vector2)print(sim)文档加载与切分模块创建
在实现了向量化之后,我们接下来需要编写一个文档加载与切分模块,用于处理不同格式的文档并将其切分为小片段。为什么要进行切分呢?这是为了确保每个文档片段都尽量保持简短且信息集中,以便于后续的向量化和检索。
文档格式处理函数
我们的目标是支持多种格式的文档,例如 PDF、Markdown、TXT 等。每种文件格式都有不同的读取方式,下面我们展示一个支持多种格式的简单实现:
def read_file_content(cls, file_path: str):# 根据文件扩展名选择读取方法if file_path.endswith('.pdf'):return cls.read_pdf(file_path)elif file_path.endswith('.md'):return cls.read_markdown(file_path)elif file_path.endswith('.txt'):return cls.read_text(file_path)else:raise ValueError("Unsupported file type")文档切分函数
这里我们考虑将文档按Token长度进行切分,设置一个最大的 Token 长度,然后按这个长度进行切分。在这个过程中,我们也会确保每个片段之间有一定的重叠,避免重要信息被切掉。
def get_chunk(cls, text: str, max_token_len: int = 600, cover_content: int = 150):chunk_text = []curr_len = 0curr_chunk = ''lines = text.split('\n') # 以换行符为单位切分文本for line in lines:line = line.replace(' ', '')line_len = len(enc.encode(line)) # 计算当前行的 Token 长度if line_len > max_token_len:print('warning line_len = ', line_len)if curr_len + line_len <= max_token_len:curr_chunk += line + '\n'curr_len += line_len + 1else:chunk_text.append(curr_chunk)curr_chunk = curr_chunk[-cover_content:] + linecurr_len = line_len + cover_contentif curr_chunk:chunk_text.append(curr_chunk)return chunk_text完整类编写如下:
chunk_file.py
import os
from openai import OpenAI
import matplotlib.pyplot as plt
import numpy as npimport PyPDF2
import markdown
import json
import tiktoken
import re
from bs4 import BeautifulSoupenc = tiktoken.get_encoding("cl100k_base")
class ReadFiles:"""读取文件的类,用于从指定路径读取支持的文件类型(如 .txt、.md、.pdf)并进行内容分割。"""def __init__(self, path: str) -> None:"""初始化函数,设定要读取的文件路径,并获取该路径下所有符合要求的文件。:param path: 文件夹路径"""self._path = pathself.file_list = self.get_files() # 获取文件列表def get_files(self):"""遍历指定文件夹,获取支持的文件类型列表(txt, md, pdf)。:return: 文件路径列表"""file_list = []for filepath, dirnames, filenames in os.walk(self._path):# os.walk 函数将递归遍历指定文件夹for filename in filenames:# 根据文件后缀筛选支持的文件类型if filename.endswith(".md"):file_list.append(os.path.join(filepath, filename))elif filename.endswith(".txt"):file_list.append(os.path.join(filepath, filename))elif filename.endswith(".pdf"):file_list.append(os.path.join(filepath, filename))return file_listdef get_content(self, max_token_len: int = 600, cover_content: int = 150):"""读取文件内容并进行分割,将长文本切分为多个块。:param max_token_len: 每个文档片段的最大 Token 长度:param cover_content: 在每个片段之间重叠的 Token 长度:return: 切分后的文档片段列表"""docs = []for file in self.file_list:content = self.read_file_content(file) # 读取文件内容# 分割文档为多个小块chunk_content = self.get_chunk(content, max_token_len=max_token_len, cover_content=cover_content)docs.extend(chunk_content)return docs@classmethoddef get_chunk(cls, text: str, max_token_len: int = 600, cover_content: int = 150):"""将文档内容按最大 Token 长度进行切分。:param text: 文档内容:param max_token_len: 每个片段的最大 Token 长度:param cover_content: 重叠的内容长度:return: 切分后的文档片段列表"""chunk_text = []curr_len = 0curr_chunk = ''token_len = max_token_len - cover_contentlines = text.splitlines() # 以换行符分割文本为行for line in lines:line = line.replace(' ', '') # 去除空格line_len = len(enc.encode(line)) # 计算当前行的 Token 长度if line_len > max_token_len:# 如果单行长度超过限制,将其分割为多个片段num_chunks = (line_len + token_len - 1) // token_lenfor i in range(num_chunks):start = i * token_lenend = start + token_len# 防止跨单词分割while not line[start:end].rstrip().isspace():start += 1end += 1if start >= line_len:breakcurr_chunk = curr_chunk[-cover_content:] + line[start:end]chunk_text.append(curr_chunk)start = (num_chunks - 1) * token_lencurr_chunk = curr_chunk[-cover_content:] + line[start:end]chunk_text.append(curr_chunk)elif curr_len + line_len <= token_len:# 当前片段长度未超过限制时,继续累加curr_chunk += line + '\n'curr_len += line_len + 1else:chunk_text.append(curr_chunk) # 保存当前片段curr_chunk = curr_chunk[-cover_content:] + linecurr_len = line_len + cover_contentif curr_chunk:chunk_text.append(curr_chunk)return chunk_text@classmethoddef read_file_content(cls, file_path: str):"""读取文件内容,根据文件类型选择不同的读取方式。:param file_path: 文件路径:return: 文件内容"""if file_path.endswith('.pdf'):return cls.read_pdf(file_path)elif file_path.endswith('.md'):return cls.read_markdown(file_path)elif file_path.endswith('.txt'):return cls.read_text(file_path)else:raise ValueError("Unsupported file type")@classmethoddef read_pdf(cls, file_path: str):"""读取 PDF 文件内容。:param file_path: PDF 文件路径:return: PDF 文件中的文本内容"""with open(file_path, 'rb') as file:reader = PyPDF2.PdfReader(file)text = ""for page_num in range(len(reader.pages)):text += reader.pages[page_num].extract_text()return text@classmethoddef read_markdown(cls, file_path: str):"""读取 Markdown 文件内容,并将其转换为纯文本。:param file_path: Markdown 文件路径:return: 纯文本内容"""with open(file_path, 'r', encoding='utf-8') as file:md_text = file.read()html_text = markdown.markdown(md_text)# 使用 BeautifulSoup 从 HTML 中提取纯文本soup = BeautifulSoup(html_text, 'html.parser')plain_text = soup.get_text()# 使用正则表达式移除网址链接text = re.sub(r'http\S+', '', plain_text) return text@classmethoddef read_text(cls, file_path: str):"""读取普通文本文件内容。:param file_path: 文本文件路径:return: 文件内容"""with open(file_path, 'r', encoding='utf-8') as file:return file.read()class Documents:"""文档类,用于读取已分好类的 JSON 格式文档。"""def __init__(self, path: str = '') -> None:self.path = pathdef get_content(self):"""读取 JSON 格式的文档内容。:return: JSON 文档的内容"""with open(self.path, mode='r', encoding='utf-8') as f:content = json.load(f)return content
以下是基本使用示例
if __name__ == '__main__':# 初始化 ReadFiles 类,指定文件目录路径file_reader = ReadFiles(path="./data")# 获取目录下所有支持的文件类型file_list = file_reader.get_files()print("支持的文件列表:", file_list)# 将文件内容读取并分块document_chunks = file_reader.get_content(max_token_len=600, cover_content=150)print("分块后的文档内容:", document_chunks)print("文档总数:", len(document_chunks))print("文档示例:", document_chunks[0])词向量数据库与向量检索模块
接下来我们将继续构建向量数据库以及检索模块,这是 RAG 模型中的核心功能之一。向量数据库用于存储文档片段及其对应的向量表示,而检索模块则根据用户提出的问题(Query)在数据库中检索相关的文档片段。通过这些功能,我们创建的简易 RAG 能够根据输入的查询快速找到最相关的文档片段。
为了构建这个向量数据库,我们需要以下几个关键功能:
- 持久化存储(persist): 将数据库存储到本地,便于下次加载使用。
- 加载数据库(load_vector): 从本地文件加载已经存储的向量和文档。
- 获取向量表示(get_vector): 将文档转化为向量表示并存储。
- 检索(query): 根据用户的 Query,检索数据库中的相关文档片段。
我们将基于这些功能来实现一个简单的 VectorStore 类。
首先,我们创建一个基础的 VectorStore 类,提供上述功能的框架。通过这个类,我们能够将文档片段转化为向量存储,加载本地数据库,进行检索。
vector.py
import os
import matplotlib.pyplot as plt
import numpy as np
from typing import List
from embedding import BaseEmbeddings
from embedding import SentenceTransformerEmbedding class VectorStore:def __init__(self, document: List[str] = None) -> None:"""初始化向量存储类,存储文档和对应的向量表示。:param document: 文档列表,默认为空。"""if document is None:document = []self.document = document # 存储文档内容self.vectors = [] # 存储文档的向量表示# 使用传入的 `EmbeddingModel` 对所有文档进行向量化,并将这些向量存储在 `self.vectors` 中def get_vector(self, EmbeddingModel: BaseEmbeddings) -> List[List[float]]:"""使用传入的 Embedding 模型将文档向量化。:param EmbeddingModel: 传入的用于生成向量的模型(需继承 BaseEmbeddings 类)。:return: 返回文档对应的向量列表。"""# 遍历所有文档,获取每个文档的向量表示self.vectors = [EmbeddingModel.get_embedding(doc) for doc in self.document]return self.vectors# 将文档片段及其向量表示保存到本地文件系统,便于持久化存储。def persist(self, path: str = 'storage'):"""将文档和对应的向量表示持久化到本地目录中,以便后续加载使用。:param path: 存储路径,默认为 'storage'。"""if not os.path.exists(path):os.makedirs(path) # 如果路径不存在,创建路径# 保存向量为 numpy 文件np.save(os.path.join(path, 'vectors.npy'), self.vectors)# 将文档内容存储到文本文件中with open(os.path.join(path, 'documents.txt'), 'w') as f:for doc in self.document:f.write(f"{doc}\n")# 从本地文件系统加载已保存的文档片段和向量,供后续检索使用def load_vector(self, path: str = 'storage'):"""从本地加载之前保存的文档和向量数据。:param path: 存储路径,默认为 'storage'。"""# 加载保存的向量数据self.vectors = np.load(os.path.join(path, 'vectors.npy')).tolist()# 加载文档内容with open(os.path.join(path, 'documents.txt'), 'r') as f:self.document = [line.strip() for line in f.readlines()]# 接收用户输入的查询,通过向量化后在数据库中检索最相关的文档片段,并返回最匹配的文档def query(self, query: str, EmbeddingModel: BaseEmbeddings, k: int = 1) -> List[str]:# 将查询文本向量化query_vector = EmbeddingModel.get_embedding(query)# 计算相似度并提取标量值similarities = [float(EmbeddingModel.cosine_similarity(query_vector, vector).item()) for vector in self.vectors]print("查询向量与每个文档向量的相似度:", similarities)# 获取相似度最高的 k 个文档索引top_k_indices = np.argsort(similarities)[-k:][::-1].tolist()print("相似度最高的 k 个文档索引:", top_k_indices)# 返回对应的文档内容return [self.document[idx] for idx in top_k_indices]上述代码解释如下:
- get_vector 方法: 这个方法使用传入的
EmbeddingModel对所有文档进行向量化,并将这些向量存储在self.vectors中。 - persist 方法: 该方法将文档片段及其向量表示保存到本地文件系统,便于持久化存储。
- load_vector 方法: 从本地文件系统加载已保存的文档片段和向量,供后续检索使用。
- get_similarity 方法: 计算两个向量之间的余弦相似度,用于比较查询和文档向量的相似度。
- query 方法: 接收用户输入的查询,通过向量化后在数据库中检索最相关的文档片段,并返回最匹配的文档。
同样,假设我们已经有一组文档片段存储在 `documents` 中,并且使用 Qwen3的 Embedding API 进行向量化处理,以下是一个简化的运行示例:
if __name__ == '__main__':# 初始化文档列表documents = ["机器学习是人工智能的一个分支。","深度学习是一种特殊的机器学习方法。","监督学习是一种训练模型的方式。","强化学习通过奖励和惩罚进行学习。","无监督学习不依赖标签数据。",]# 创建向量数据库vector_store = VectorStore(document=documents)# 使用 SentenceTransformer Embedding 模型对文档进行向量化path="/data1/sx/jl/pro/model/modelscope/hub/models/Qwen/Qwen3-Embedding-4B"embedding_model = SentenceTransformerEmbedding(path=path, is_api=False)# 获取文档向量并存储vector_store.get_vector(embedding_model)# 打印文档向量print(vector_store.vectors)# 持久化存储到本地vector_store.persist('storage')# 模拟用户查询query = "什么是深度学习?"result = vector_store.query(query, embedding_model) print("检索结果:", result)在上面这段代码中,npy 文件是 NumPy 库用于存储数组数据的文件格式。npy 文件能够高效地保存和加载 NumPy 数组,并保留数组的形状、数据类型等信息。它是一种二进制文件格式,用于序列化 NumPy 数组,使得存储和读取过程更加快速和便捷。
大模型问答模块编写
我们借助ollma搭建自己的本地模型,这里我使用的模型是Qwen3的问答模型,具体搭建部署过程可参考
零基础本地部署Qwen3模型(ollama+Open-WebUI)_ollama部署qwen3-CSDN博客
为了方便维护和复用提示语,可以使用一个字典来保存不同模型的提示模板。
PROMPT_TEMPLATE = dict(GPT4o_PROMPT_TEMPLATE="""下面有一个或许与这个问题相关的参考段落,若你觉得参考段落能和问题相关,则先总结参考段落的内容。若你觉得参考段落和问题无关,则使用你自己的原始知识来回答用户的问题,并且总是使用中文来进行回答。问题: {question}可参考的上下文:···{context}···有用的回答:"""
)以下是模型问答模块
chat_model.py
import os
from contextlib import AsyncExitStack
from openai import OpenAI
from typing import List
from dotenv import load_dotenvPROMPT_TEMPLATE = dict(PROMPT_TEMPLATE="""下面有一个或许与这个问题相关的参考段落,若你觉得参考段落能和问题相关,则先总结参考段落的内容。若你觉得参考段落和问题无关,则使用你自己的原始知识来回答用户的问题,并且总是使用中文来进行回答。问题: {question}可参考的上下文:···{context}···有用的回答:"""
)class ChatModel:def __init__(self):load_dotenv()self.exit_stack = AsyncExitStack()self.openai_api_key = os.getenv("OPENAI_API_KEY") # 读取 OpenAI API Keyself.base_url = os.getenv("BASE_URL") # 读取 BASE URLself.model = os.getenv("MODEL") # 读取 modelprint("🤖 正在初始化聊天模型...",self.model)if not self.openai_api_key:raise ValueError("❌ 未找到 OpenAI API Key,请在 .env 文件中设置 OPENAI_API_KEY")self.client = OpenAI(api_key=self.openai_api_key, base_url=self.base_url)def chat(self, prompt: str, history: List = [], content: str = '') -> str:""":param prompt: 用户的提问:param history: 之前的对话历史(可选):param content: 可参考的上下文信息(可选):return: 生成的回答"""print("🤖 问题:", prompt)print("🤖 上下文:", content)# 构建包含问题和上下文的完整提示full_prompt = PROMPT_TEMPLATE['PROMPT_TEMPLATE'].format(question=prompt, context=content)messages=[{"role": "user", "content": full_prompt}]response = self.client.chat.completions.create(model=self.model,messages=messages,)# 返回模型生成的第一个回答return response.choices[0].message.content
同样以下是测试代码
if __name__ == '__main__':chat_model = ChatModel()prompt = "你好,我想问一下,你们家的冰箱里面有什么东西可以用来做冰淇淋?"print(chat_model.chat(prompt))chat_model.chat(prompt)
注意后台需要打开ollama服务,否则代码将连接不到模型
ollama startRAG Demo完整流程演示
接下来,我们展示一个完整的 RAG Demo,结合我们前面实现的向量检索和大模型模块,展示如何在实际应用中使用 RAG 模型来回答问题。
main.py
from chunk_file import ReadFiles
from vector import VectorStore
from embedding import SentenceTransformerEmbedding
from chat_model import ChatModel
from IPython.display import display, Code, Markdown
from bs4 import BeautifulSoupdef run_mini_rag(question: str, knowledge_base_path: str, k: int = 1) -> str:"""运行一个简化版的RAG项目。:param question: 用户提出的问题:param knowledge_base_path: 知识库的路径,包含文档的文件夹路径:param api_key: OpenAI API密钥,用于调用GPT-4o模型:param k: 返回与问题最相关的k个文档片段,默认为1:return: 返回GPT-4o模型生成的回答"""# 加载并切分文档docs = ReadFiles(knowledge_base_path).get_content(max_token_len=600, cover_content=150)vector = VectorStore(docs)# 使用 SentenceTransformer Embedding 模型对文档进行向量化embedding=SentenceTransformerEmbedding(is_api=False)# 获取文档向量并存储vector.get_vector(embedding)# 打印文档向量print(vector.vectors)# 持久化存储到本地vector.persist('storage')# 在数据库中检索最相关的文档片段content = vector.query(question, EmbeddingModel=embedding, k=1)[0]# 使用 Qwen3 模型生成答案chat = ChatModel() answer=chat.chat(question, [], content)soup =BeautifulSoup(answer, 'html.parser')# print("模型回答:", answer)think_content = soup.find('think').text.strip() if soup.find('think') else Noneprint ("🤖 \n思考结果:\n", think_content)print("🤖 \n正在生成回答...\n")non_think_content = []for element in soup.children:if element.name != 'think' and str(element).strip():non_think_content.append(str(element).strip())print('\n'.join(non_think_content))return non_think_contentif __name__ == '__main__':# 用户提出问题question = 'OpenAI的分词技术经历了哪些迭代'knowledge_base_path = './data'run_mini_rag(question, knowledge_base_path)完整代码可见
JL-sky/MiniRag: 借助Qwen3搭建一个简易rag引擎