Streamlit 官翻 3 - 开发教程 Develop Tutorials
文章目录
- 教程
- 添加用户认证功能
- 聊天应用与大型语言模型
- 配置与主题定制
- 连接数据源
- 使用 Streamlit 核心组件
- 使用核心特性探索 Streamlit 的执行模型
- 创建多页面应用
- 用户认证与个性化应用
- Google 认证平台
- Microsoft Entra
- 使用 Google 身份验证平台进行用户认证
- 前提条件
- 概述
- 在 Google Cloud Console 中创建 Web 应用
- 配置您的同意屏幕
- 配置您的受众群体
- 配置您的客户端
- 收集您的应用程序详细信息
- 构建示例
- 配置你的密钥
- 重要提示
- 初始化你的应用
- 用户登录与登出
- 注意:
- 在社区云上部署您的应用
- 使用 Microsoft Entra 进行用户身份验证
- 前提条件
- 概述
- 在 Microsoft Entra ID 中创建 Web 应用程序
- 注册新应用程序
- 收集应用程序的详细信息
- 构建示例
- 配置你的密钥
- 重要提示
- 初始化你的应用
- 用户登录与登出
- 注意:
- 在社区云上部署您的应用
- 构建LLM应用
- 构建基础聊天应用
- 使用LangChain构建LLM应用
- 获取聊天反馈
- 验证并编辑聊天响应
- 构建基础LLM聊天应用
- 简介
- 聊天组件
- st.chat_message
- st.chat_input
- 构建一个镜像输入内容的聊天机器人
- 构建一个支持流式传输的简易聊天机器人界面
- 构建类ChatGPT应用
- 安装依赖项
- 将OpenAI API密钥添加到Streamlit secrets
- 编写应用
- 使用LangChain构建LLM应用
- 18行代码实现OpenAI、LangChain与Streamlit整合
- 目标
- 前提条件
- 设置编码环境
- 构建应用
- 应用部署
- 总结
- 收集用户对LLM回复的反馈
- 应用概念
- 前提条件
- 概述
- 构建示例
- 初始化你的应用
- 构建模拟聊天响应流的函数
- 初始化并渲染聊天历史记录
- 添加聊天输入
- 可选:修改反馈行为
- 验证和编辑聊天回复
- 应用概念
- 前提条件
- 概述
- 构建示例
- 初始化你的应用
- 构建模拟聊天响应流的函数
- 创建验证函数
- 创建辅助函数高亮文本
- 初始化并显示聊天历史记录
- 定义 `"user"` 阶段
- 定义 `"validate"` 阶段
- 定义 `"correct"` 阶段
- 定义 `"rewrite"` 阶段
- 改进示例
- 自定义主题并配置应用
- 使用静态字体文件自定义字体
- 使用可变字体文件自定义字体
- 使用静态字体文件自定义字体
- 前提条件
- 概述
- 下载并保存字体文件
- 创建应用配置
- 提示
- 构建示例
- 初始化你的应用
- 在应用中显示文本
- 使用可变字体文件自定义字体
- 前提条件
- 概述
- 下载并保存字体文件
- 创建应用配置
- 提示
- 构建示例
- 初始化你的应用
- 在应用中显示文本
- 将Streamlit连接到数据源
- 将Streamlit连接到AWS S3
- 简介
- 创建S3存储桶并添加文件
- 注意:
- 创建访问密钥
- 提示
- 本地设置 AWS 凭据
- 重要提示
- 将应用密钥复制到云端
- 将 FilesConnection 和 s3fs 添加到你的依赖文件
- 编写你的 Streamlit 应用
- 将 Streamlit 连接到 Google BigQuery
- 简介
- 创建 BigQuery 数据库
- 注意:
- 启用 BigQuery API
- 创建服务账号及密钥文件
- 注意:
- 将密钥文件添加到本地应用配置中
- 重要提示
- 将应用密钥同步至云端
- 将 google-cloud-bigquery 添加到你的依赖文件
- 编写你的 Streamlit 应用
- 将Streamlit连接到Google云存储
- 简介
- 创建Google Cloud Storage存储桶并添加文件
- 注意:
- 启用 Google Cloud Storage API
- 创建服务账号及密钥文件
- 注意:
- 将密钥添加到本地应用机密配置中
- 重要提示
- 将应用密钥同步至云端
- 将 FilesConnection 和 gcsfs 添加到你的 requirements 文件
- 编写你的 Streamlit 应用
- 将Streamlit连接到Microsoft SQL Server
- 简介
- 创建 SQL Server 数据库
- 注意:
- 本地连接
- 提示
- 创建 SQL Server 数据库
- Add username and password to your local app secrets
- Important
- Copy your app secrets to Streamlit Community Cloud
- Add pyodbc to your requirements file
- Note :
- Write your Streamlit app
- 初始化连接
- 使用 st.cache_resource 确保只运行一次
- 执行查询
- 使用 st.cache_data 仅在查询变更或10分钟后重新运行
- 打印结果
- 连接 Streamlit 到 MongoDB
- 简介
- 创建 MongoDB 数据库
- 注意:
- 将用户名和密码添加到本地应用密钥中
- 重要提示
- 将应用密钥复制到云端
- 将 PyMongo 添加到依赖文件
- 编写你的 Streamlit 应用
- 连接 Streamlit 到 MySQL
- 简介
- 创建 MySQL 数据库
- 注意:
- 为本地应用添加用户名和密码到机密配置
- 重要提示
- 将应用密钥同步至云端
- 将依赖项添加到 requirements 文件
- 编写你的 Streamlit 应用
- 将 Streamlit 连接到 Neon
- 简介
- 前提条件
- 注意:
- 创建 Neon 项目
- 将 Neon 连接字符串添加到本地应用密钥中
- 重要提示
- 编写你的 Streamlit 应用
- 从Community Cloud连接Neon数据库
- 将Streamlit连接到PostgreSQL
- 简介
- 创建 PostgreSQL 数据库
- 注意:
- 为本地应用添加用户名和密码配置
- 重要提示
- 将应用密钥复制到云端
- 将依赖项添加到你的 requirements 文件
- 编写你的 Streamlit 应用
- 将Streamlit连接到私有Google表格
- 简介
- 前提条件
- 创建 Google 表格
- 启用 Sheets API
- 创建服务账号及密钥文件
- 注意:
- 与服务账号共享Google表格
- 将密钥文件添加到本地应用配置中
- 重要提示
- 编写你的 Streamlit 应用
- 从Community Cloud连接Google Sheets
教程
https://docs.streamlit.io/develop/tutorials
我们的教程包含使用Streamlit构建各类应用的逐步示例。
添加用户认证功能
利用 Streamlit 内置的 OpenID Connect 支持实现用户认证。
官方认证教程
聊天应用与大型语言模型
利用大型语言模型开发聊天应用。
https://docs.streamlit.io/develop/tutorials/chat-and-llm-apps
配置与主题定制
自定义应用的外观样式。
https://docs.streamlit.io/develop/tutorials/configuration-and-theming
连接数据源
连接到主流数据源。
https://docs.streamlit.io/develop/tutorials/databases
使用 Streamlit 核心组件
掌握数据框和图表等核心组件的使用方法。
https://docs.streamlit.io/develop/tutorials/elements
使用核心特性探索 Streamlit 的执行模型
通过构建简单应用并跟随示例,了解 Streamlit 的核心特性及其执行模型。
https://docs.streamlit.io/develop/tutorials/execution-flow
创建多页面应用
创建多页面应用、导航和流程。
https://docs.streamlit.io/develop/tutorials/multipage
完成应用开发后,请参阅我们的部署教程!
上一页:API参考
下一页:认证与个性化
用户认证与个性化应用
https://docs.streamlit.io/develop/tutorials/authentication
Streamlit 支持通过 OpenID Connect (OIDC) 协议实现用户认证。
您可以使用任何 OIDC 提供商。
无论是创建社交登录还是管理企业用户,Streamlit 都能让用户认证变得简单。
Google 认证平台
Google 是最受欢迎的社交登录身份提供商之一。
您可以使用任何 Google 账户(包括个人账户和组织账户)通过 Google 认证平台进行登录。
https://docs.streamlit.io/develop/tutorials/authentication/google
Microsoft Entra
微软因其社交和商务登录功能而广受欢迎。
您可以在集成中纳入个人、学校或工作账户。
https://docs.streamlit.io/develop/tutorials/authentication/microsoft
上一篇:教程
下一篇:Google 认证平台
使用 Google 身份验证平台进行用户认证
https://docs.streamlit.io/develop/tutorials/authentication/google
Google 是最受欢迎的社交登录身份提供商之一。
您可以将 Google 身份验证平台与个人及企业 Google 账户结合使用。
本教程将为所有拥有 Google 账户的用户配置身份验证。
如需了解更多信息,请参阅 Google 关于 Google Auth Platform 和 OpenID Connect 的概述文档。
前提条件
- 本教程需要以下 Python 库:
streamlit>=1.42.0
Authlib>=1.3.2
- 你需要一个名为
your-repository的干净工作目录。
- 你必须拥有 Google 账号并接受 Google Cloud 的服务条款才能使用其身份验证服务。
- 你必须在 Google Cloud 中拥有一个项目,以便在其中创建应用程序。
有关在 Google Cloud 中管理项目的更多信息,请参阅 Google 文档中的创建和管理项目。
概述
在本教程中,您将构建一个允许用户通过Google账户登录的应用。
登录后,用户会看到包含其姓名的个性化问候语,并可以选择退出登录。
以下是您将实现的功能预览:
完整代码
.streamlit/secrets.toml
[auth]
redirect_uri = "http://localhost:8501/oauth2callback"
cookie_secret = "xxx"
client_id = "xxx"
client_secret = "xxx"
server_metadata_url = "https://accounts.google.com/.well-known/openid-configuration"
app.py
import streamlit as stdef login_screen():st.header("This app is private.")st.subheader("Please log in.")st.button("Log in with Google", on_click=st.login)if not st.user.is_logged_in:login_screen()
else:st.header(f"Welcome, {st.user.name}!")st.button("Log out", on_click=st.logout)
在 Google Cloud Console 中创建 Web 应用
本节将指导您完成三个步骤,在 Google Cloud Console 项目中创建您的 Web 应用:
- 配置同意屏幕
- 配置受众群体
- 配置客户端
同意屏幕是用户在认证流程中看到的 Google 界面。
受众群体设置管理着您应用的状态(测试中 或 已发布)。
为 Web 应用创建客户端会生成配置 Streamlit 应用所需的 ID 和密钥。
要了解更多关于同意屏幕、受众群体和客户端的信息,请参阅 Google 的 Google 认证平台 概述。
配置您的同意屏幕
1、前往 Google Auth Platform,并登录 Google 账号。
2、在左上角选择您的项目。
3、在左侧导航菜单中,选择“品牌信息”。
4、填写应用程序同意屏幕所需的各项信息。
这些信息将控制用户在 Google 认证流程中看到的内容。
您设置的“应用名称”会显示在 Google 的提示中。
Google 会要求用户同意将他们的账户信息发送给您的应用。
如果您在本地开发或部署在 Streamlit Community Cloud 上,请在“授权域名”中使用 example.com。
有关各字段的详细信息,请参阅设置 OAuth 同意屏幕。
5、在品牌信息页面底部,选择“保存”。
配置您的受众群体
1、在左侧导航菜单中,选择"受众群体"。
2、在"OAuth用户上限"→"测试用户"下方,选择"添加用户"。
3、输入个人Google账号的电子邮件地址,然后选择"保存"。
当您在Google认证平台创建新应用时,其状态为测试中。
在测试中状态下,只有特定用户才能对您的应用进行认证;用户无法自行注册。
因此,请添加您希望在开发过程中用于测试应用的所有电子邮件地址。
当您准备发布应用时,需要返回此部分并将状态更改为已发布。
应用发布后,您的应用将接受新用户。
配置您的客户端
1、在左侧导航菜单中,选择"Clients"。
2、在客户端列表顶部,选择"CREATE CLIENT"。
3、在应用类型中,选择"Web application"。
4、为您的应用输入一个唯一名称。
客户端名称仅用于内部识别,不会向用户显示。
5、跳过"Authorized JavaScript origins"部分。
6、在"Authorized redirect URIs"下方,选择"ADD URI"。
7、输入包含路径名oauth2callback的应用URL。
例如,如果您在本地开发,请输入http://localhost:8501/oauth2callback。
如果使用其他端口,请将8501改为您的实际端口号。
8、可选:添加其他授权重定向URI。
如果您的应用将通过多个URL访问,或已知将来会使用的URL,可以现在添加。
请确保每个URL都包含oauth2callback路径名。
9、在页面底部选择"CREATE"。
现在您已在Google Cloud中创建了一个可用于用户认证的客户端。
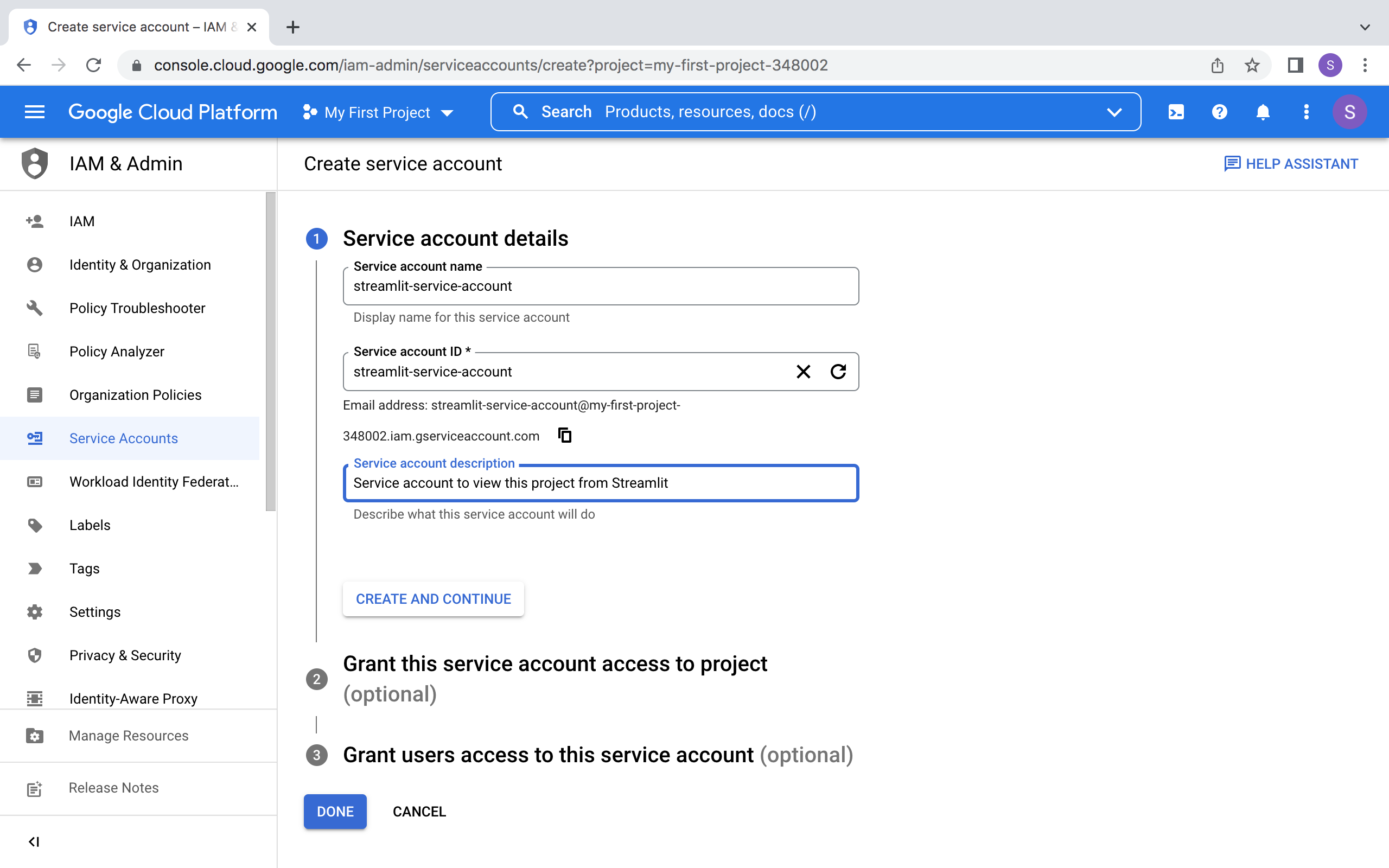
收集您的应用程序详细信息
1、在客户端页面中,选择您的新客户端。
2、为了保存应用程序信息供后续步骤使用,请打开文本编辑器,或者(更推荐)在密码管理器中创建新条目。
请始终安全处理您的应用密钥。
粘贴时记得标注每个值的用途,以免混淆。
3、在右侧,将您的"Client ID"和"Client secret"复制到文本编辑器中。
对于Google认证平台,服务器元数据URL是所有应用共享的,不会单独列在您的客户端中。
Google认证平台的服务器元数据URL是https://accounts.google.com/.well-known/openid-configuration。
有关服务器元数据URL的更多信息,请参阅Google文档中的发现文档。
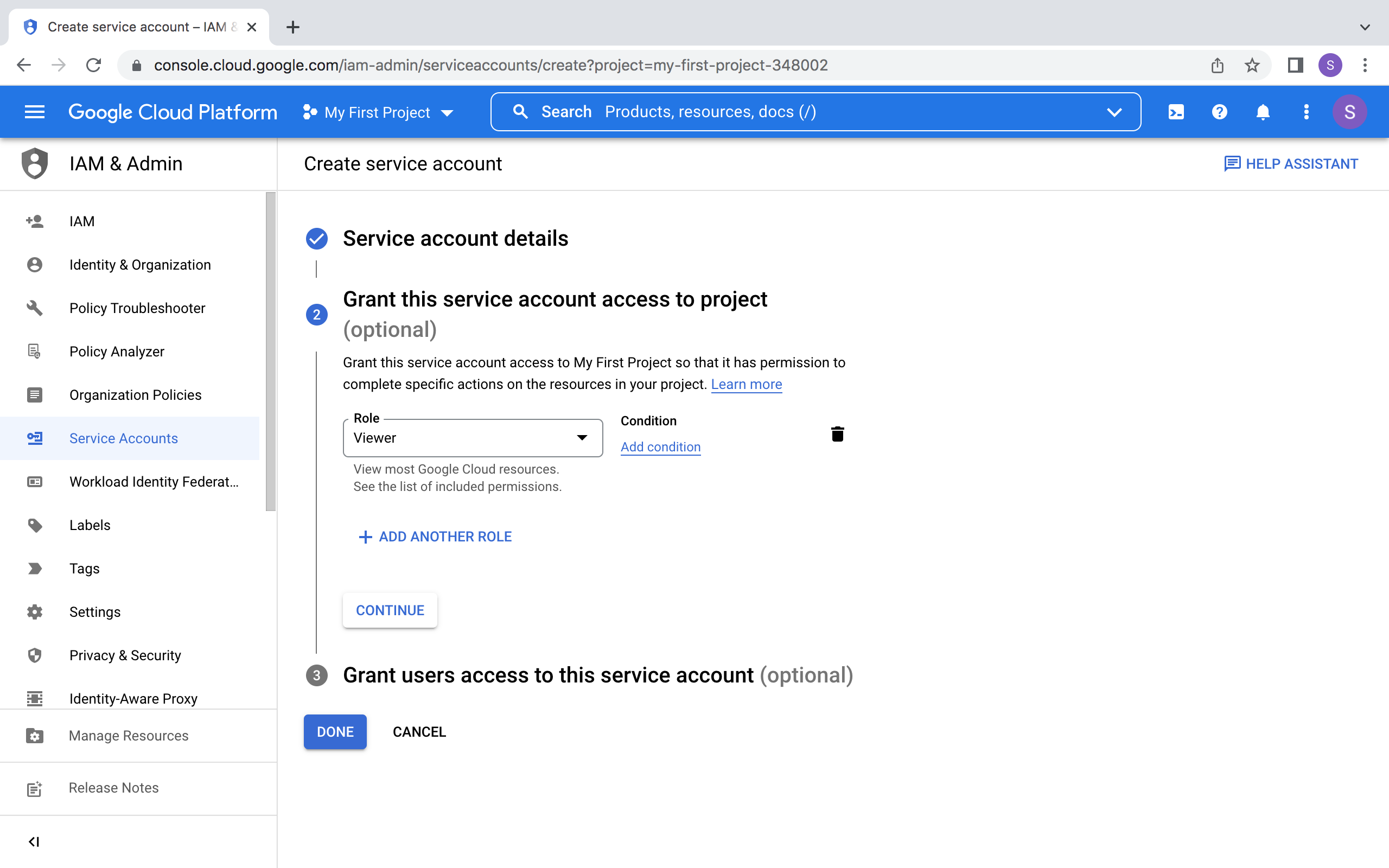
构建示例
要创建一个带用户认证功能的应用,你需要配置密钥并提示用户登录。
通过密钥管理来存储来自客户端的信息,然后构建一个简单的应用,在用户登录后通过姓名欢迎他们。
配置你的密钥
1、在 your_repository 中,创建一个 .streamlit/secrets.toml 文件。
2、将 secrets.toml 添加到你的 .gitignore 文件中。
重要提示
切勿将密钥提交到代码仓库。
有关.gitignore的更多信息,请参阅忽略文件。
- 生成一个高强度随机密钥作为cookie密钥。
该cookie密钥用于对每个用户的身份cookie进行签名,当用户登录时Streamlit会存储这些cookie。
- 在
.streamlit/secrets.toml文件中添加您的连接配置:
[auth]
redirect_uri = "http://localhost:8501/oauth2callback"
cookie_secret = "xxx"
client_id = "xxx"
client_secret = "xxx"
server_metadata_url = "https://accounts.google.com/.well-known/openid-configuration"
将 client_id 和 client_secret 的值替换为您之前复制到文本编辑器中的内容。
将 cookie_secret 的值替换为在上一步生成的随机密钥。
- 保存您的
secrets.toml文件。
初始化你的应用
1、在 your_repository 目录中,创建一个名为 app.py 的文件。
2、在终端中,切换到 your_repository 目录,然后启动你的应用:
streamlit run app.py
你的应用会显示空白,因为你还需要添加代码。
3、在 app.py 文件中,编写以下内容:
import streamlit as st
4、保存你的 app.py 文件,并查看正在运行的应用程序。
5、在你的应用中,选择"总是重新运行"选项,或按下"A"键。
预览界面会显示空白,但当你保存对 app.py 的修改时,它会自动更新。
6、返回你的代码。
用户登录与登出
- 定义一个提示用户登录的函数:
def login_screen():st.header("This app is private.")st.subheader("Please log in.")st.button("Log in with Google", on_click=st.login)
该函数显示一条简短消息和一个按钮。
Streamlit 的登录命令被指定为该按钮的回调函数。
注意:
如果不希望使用回调函数,可以用等效的 if 语句替换最后一行代码:
- st.button("Log in with Google", on_click=st.login)
+ if st.button("Log in with Google"):
+ st.login()
- 根据用户是否登录的条件,调用您的函数来提示用户或显示其信息:
if not st.user.is_logged_in:login_screen()
else:st.user
因为 st.user 是一个独立显示的类字典对象,Streamlit 的魔法功能会将其展示在你的应用中。
3、保存你的 app.py 文件,并测试正在运行的应用。
在实时预览中,当你登录应用时,登录按钮会被身份令牌的内容替代。
注意观察 Google 提供的不同值,你可以利用这些值为用户个性化定制应用。
4、返回你的代码。
5、将 st.user 替换为个性化的问候语:
else:
- st.user
+ st.header(f"Welcome, {st.user.name}!")
6、添加登出按钮:
st.button("Log out", on_click=st.logout)
7、保存你的 app.py 文件并测试正在运行的应用程序。
在实时预览中,如果你退出应用程序,它将返回到登录提示界面。
在社区云上部署您的应用
当您准备好部署应用时,需要更新Google Cloud上的应用程序和密钥配置。
以下步骤说明如何在社区云上部署应用。
1、在代码仓库中添加包含以下内容的requirements.txt文件:
streamlit>=1.42.0
Authlib>=1.3.2
这确保为你的部署应用安装了正确的 Python 依赖项。
2、保存你的 requirements.txt 文件。
3、部署你的应用,并将应用 URL 复制到文本编辑器中。
后续步骤中,你将使用该 URL 更新密钥和客户端配置。
关于在 Community Cloud 上部署应用的更多信息,请参阅 部署应用。
4、在 Community Cloud 的 应用设置 中,选择 “Secrets”。
5、复制本地 secrets.toml 文件内容,粘贴到应用设置中。
6、修改 redirect_uri 以匹配你之前在本教程中复制的部署应用 URL。
例如,如果你的应用是 my_streamlit_app.streamlit.io,重定向 URI 应为 https://my_streamlit_app.streamlit.io/oauth2callback。
7、保存并关闭设置。
8、返回 Google 认证平台的客户端页面,选择你的客户端。
9、在 “Authorized redirect URIs” 下,添加或更新 URI 以匹配新的 redirect_uri。
10、在页面底部选择 “SAVE”。
11、打开已部署的应用进行测试。
此时你的 Google Cloud 应用状态仍为 测试中。
你应能使用在 “Audience” 页面输入的 Google 个人账户登录和退出应用。
12、当准备让其他人使用你的应用时,返回 Google 认证平台的 “Audience” 页面,将应用状态设为 已发布。
上一页:认证与个性化
下一页:Microsoft Entra
使用 Microsoft Entra 进行用户身份验证
https://docs.streamlit.io/develop/tutorials/authentication/microsoft
Microsoft Identity Platform 是 Microsoft Entra 中的一项服务,可帮助您构建应用程序来实现用户身份验证。
您的应用程序可以使用由 Microsoft 管理的个人账户、工作账户和学校账户。
前提条件
- 本教程需要以下 Python 库:
streamlit>=1.42.0
Authlib>=1.3.2
- 你应该有一个名为
your-repository的干净工作目录。
- 你必须拥有一个包含 Microsoft Entra ID 的 Microsoft Azure 账户。
概述
在本教程中,您将构建一个应用程序,用户可以使用其个人Microsoft账户登录。
登录后,他们将看到包含其姓名的个性化问候语,并可以选择注销。
以下是您将要构建的内容预览:
完整代码
.streamlit/secrets.toml
[auth]
redirect_uri = "http://localhost:8501/oauth2callback"
cookie_secret = "xxx"
client_id = "xxx"
client_secret = "xxx"
server_metadata_url = "https://login.microsoftonline.com/consumers/v2.0/.well-known/openid-configuration"
app.py
import streamlit as stdef login_screen():st.header("This app is private.")st.subheader("Please log in.")st.button("Log in with Microsoft", on_click=st.login)if not st.user.is_logged_in:login_screen()
else:st.header(f"Welcome, {st.user.name}!")st.button("Log out", on_click=st.logout)
在 Microsoft Entra ID 中创建 Web 应用程序
在 Azure 的 Microsoft Entra ID 中,你需要注册一个新应用程序并生成配置应用所需的密钥。
本示例中,你的应用程序将仅接受个人 Microsoft 账户,但你也可以选择接受工作或学校账户,或将应用程序限制在你的个人租户内。
Microsoft Entra 还允许你连接其他外部身份提供商。
注册新应用程序
1、访问 Microsoft Azure,并登录 Microsoft 账户。
2、在页面顶部的服务列表中,选择 “Microsoft Entra ID”。
3、在左侧导航栏中,选择 “管理” → “应用注册”。
4、在屏幕顶部,选择 “新注册”。
5、填写您的应用程序名称。
该名称将在 Microsoft 提供的身份验证流程中显示给用户。
6、在 “支持的账户类型” 下,选择 “仅限个人 Microsoft 账户”。
7、在 “重定向 URI” 部分,选择 “Web” 平台,并输入带有路径 oauth2callback 的应用 URL。
例如,如果您在本地开发,请输入 http://localhost:8501/oauth2callback。
如果使用其他端口,请将 8501 更改为您的实际端口号。
8、在屏幕底部,选择 “注册”。
Microsoft 将跳转至您的新应用程序页面,这是 Azure 中的一项资源。
收集应用程序的详细信息
1、为了保存应用程序信息供后续步骤使用,请打开文本编辑器,或者(更推荐)在密码管理工具中新建条目。
务必安全处理应用程序密钥。
粘贴时记得标注每个值的用途,避免混淆。
2、在"基本信息"部分,将"应用程序(客户端)ID"复制到文本编辑器。
这就是你的client_id。
3、在页面顶部选择"终结点"。
4、将"OpenID Connect元数据文档"复制到文本编辑器。
这就是你的server_metadata_url。
5、在左侧导航栏选择"管理"→"证书和密码"。
6、在顶部附近选择"新建客户端密码"。
7、输入描述并选择过期时间。
描述仅用于内部标识。
生成的密码将用于配置Streamlit应用,因此建议选择能帮助你记忆密码用途的描述。
8、在对话框底部选择"添加"。
Azure生成密码可能需要几秒钟时间。
9、将"值"复制到文本编辑器。
这就是你的client_secret。
离开Azure后微软会隐藏该值,请立即将其安全存储。
如果丢失密码,需从配置中删除并重新生成。
你的客户端现已准备好接收用户。
构建示例
要创建一个带用户认证功能的应用,你需要配置密钥并提示用户登录。
通过密钥管理来存储客户端信息,然后开发一个简单的应用,在用户登录后显示欢迎消息并称呼其用户名。
配置你的密钥
1、在 your_repository 中创建 .streamlit/secrets.toml 文件。
2、将 secrets.toml 添加到你的 .gitignore 文件中。
重要提示
切勿将机密信息提交到代码仓库。
有关.gitignore的更多信息,请参阅忽略文件。
- 生成一个高强度随机密钥作为Cookie密钥。
该密钥用于对每位用户的身份验证Cookie进行签名,Streamlit会在用户登录时存储此Cookie。
- 在
.streamlit/secrets.toml文件中添加您的连接配置:
[auth]redirect_uri = "http://localhost:8501/oauth2callback"cookie_secret = "xxx"client_id = "xxx"client_secret = "xxx"server_metadata_url = "https://login.microsoftonline.com/consumers/v2.0/.well-known/openid-configuration"
将 client_id、client_secret 和 server_metadata_url 的值替换为您之前复制到文本编辑器中的内容。
将 cookie_secret 的值替换为前一步骤生成的随机密钥。
- 保存您的
secrets.toml文件。
初始化你的应用
1、在 your_repository 目录下,创建一个名为 app.py 的文件。
2、在终端中,切换到 your_repository 目录,并启动你的应用:
streamlit run app.py
你的应用目前会是空白的,因为你还需要添加代码。
3、在 app.py 中编写以下内容:
import streamlit as st
4、保存你的 app.py 文件,并查看正在运行的应用程序。
5、在你的应用中,选择"始终重新运行",或按下"A"键。
预览界面将显示为空白,但当你保存对 app.py 的更改时,它会自动更新。
6、返回你的代码。
用户登录与登出
- 定义一个提示用户登录的函数:
def login_screen():st.header("This app is private.")st.subheader("Please log in.")st.button("Log in with Microsoft", on_click=st.login)
该函数显示一条简短消息和一个按钮。
Streamlit 的登录命令被指定为该按钮的回调函数。
注意:
如果不希望使用回调函数,可以用等效的 if 语句替换最后一行代码:
- st.button("Log in with Microsoft", on_click=st.login)
+ if st.button("Log in with Microsoft"):
+ st.login()
- 根据用户是否登录的条件,调用相应函数来提示用户或显示其信息:
if not st.user.is_logged_in:login_screen()
else:st.user
因为 st.user 是一个独立显示的类字典对象,Streamlit 的魔法功能会将其展示在你的应用中。
3、保存你的 app.py 文件,并测试正在运行的应用。
在实时预览中,当你登录应用时,登录按钮会被身份令牌的内容替代。
注意观察 Microsoft 提供的不同数值,你可以利用这些值为用户个性化定制应用。
4、返回你的代码。
5、将 st.user 替换为个性化的问候语:
else:
- st.user
+ st.header(f"Welcome, {st.user.name}!")
6、添加登出按钮:
st.button("Log out", on_click=st.logout)
7、保存你的 app.py 文件并测试正在运行的应用程序。
在实时预览中,如果你退出应用程序,它将返回到登录提示界面。
在社区云上部署您的应用
当您准备好部署应用时,必须更新 Microsoft Azure 中的应用程序和相关密钥。
以下步骤说明如何在社区云上部署应用。
1、在代码仓库中添加包含以下内容的 requirements.txt 文件:
streamlit>=1.42.0
Authlib>=1.3.2
这将确保为您的部署应用安装正确的 Python 依赖项。
2、保存您的 requirements.txt 文件。
3、部署您的应用,并将应用 URL 复制到文本编辑器中。
您将使用应用 URL 在后续步骤中更新密钥和应用配置。
有关在 Community Cloud 上部署应用的更多信息,请参阅部署您的应用。
4、在 Community Cloud 的应用设置中,选择“Secrets”。
5、复制本地 secrets.toml 文件的内容,并将其粘贴到应用设置中。
6、修改 redirect_uri 以反映您部署的应用 URL。
例如,如果您的应用是 my_streamlit_app.streamlit.io,则重定向 URI 应为 https://my_streamlit_app.streamlit.io/oauth2callback。
7、保存并关闭设置。
8、返回 Microsoft Azure 中的应用程序。
如果您已关闭 Microsoft Azure 并需要重新导航到应用程序,请转到 Azure 门户 → Microsoft Entra ID → 应用注册,然后从列表中选择它。
9、在左侧导航栏中,选择“Authentication”。
10、在“Platform configurations” → “Web”下,添加或更新 URI 以匹配新的 redirect_uri。
11、在页面底部,选择“Save”。
12、打开您部署的应用并进行测试。
上一页:Google Auth Platform
下一页:Chat and LLM apps
构建LLM应用
https://docs.streamlit.io/develop/tutorials/chat-and-llm-apps
构建基础聊天应用
通过构建一个简单的OpenAI聊天应用,快速上手Streamlit的聊天组件。
https://docs.streamlit.io/develop/tutorials/llms/build-conversational-apps
使用LangChain构建LLM应用
通过LangChain框架结合OpenAI构建聊天应用。
https://docs.streamlit.io/develop/tutorials/llms/llm-quickstart
获取聊天反馈
构建一个聊天应用并让用户对回复进行评分。
(点赞 点踩)
验证并编辑聊天响应
构建一个带响应验证功能的聊天应用。
允许用户修正或编辑响应内容。
https://docs.streamlit.io/develop/tutorials/chat-and-llm-apps/validate-and-edit-chat-responses
上一节:身份验证与个性化
下一节:构建基础LLM聊天应用
构建基础LLM聊天应用
https://docs.streamlit.io/develop/tutorials/chat-and-llm-apps/build-conversational-apps
简介
像GPT这样的大型语言模型的出现,彻底改变了开发基于聊天的应用程序的便捷性。
Streamlit提供了多种聊天元素,使您能够为对话代理或聊天机器人构建图形用户界面(GUI)。
结合会话状态使用这些元素,您可以仅用Python代码构建从基础聊天机器人到更高级的、类似ChatGPT体验的任何应用。
在本教程中,我们将首先介绍Streamlit的聊天元素st.chat_message和st.chat_input。
然后我们将构建三个不同的应用程序,每个都展示了逐步增加的复杂性和功能:
-
首先,我们将构建一个镜像输入的机器人,以熟悉聊天元素及其工作原理。
我们还将介绍会话状态以及如何用它存储聊天历史。
这部分将作为教程其余部分的基础。 -
接下来,您将学习如何构建一个支持流式传输的简单聊天机器人GUI。
-
最后,我们将构建一个类似ChatGPT的应用,利用会话状态记住对话上下文,全部代码不超过50行。
以下是本教程中将构建的支持LLM的流式传输聊天机器人GUI预览:
全屏查看 open_in_new
您可以先体验上面的演示,感受我们将构建的内容。
需要注意几点:
- 屏幕底部始终可见一个聊天输入框,内含占位文本。
您可以输入消息并按Enter或点击运行按钮发送。 - 当您输入消息时,它会作为聊天消息显示在上方容器中。
容器可滚动,因此您可以向上查看历史消息。
消息左侧会显示默认头像。 - 助手的响应会流式传输到前端,并显示不同的默认头像。
在开始构建之前,让我们先详细了解将使用的聊天元素。
聊天组件
Streamlit 提供了多个命令来帮助您构建对话式应用。
这些聊天组件设计为相互配合使用,但也可以单独使用。
st.chat_message 允许您在应用中插入聊天消息容器,用于显示用户或应用发送的消息。
聊天容器可以包含其他 Streamlit 组件,包括图表、表格、文本等。
st.chat_input 则用于显示聊天输入控件,让用户可以输入消息。
要了解该 API 的概览,请观看 Streamlit 高级开发者倡导者 Chanin Nantasenamat(@dataprofessor)提供的视频教程。
st.chat_message
st.chat_message 允许你在应用中插入一个多元素的聊天消息容器。
返回的容器可以包含任何 Streamlit 元素,包括图表、表格、文本等。
要向返回的容器添加元素,你可以使用 with 语法。
st.chat_message 的第一个参数是消息作者的 name,可以是 "user" 或 "assistant" 以启用预设样式和头像(如上方的演示所示)。
你也可以传入自定义字符串作为作者名称。
目前,该名称不会在用户界面中显示,仅作为无障碍标签设置。
出于无障碍考虑,不应使用空字符串。
以下是一个使用 st.chat_message 显示欢迎消息的极简示例:
import streamlit as stwith st.chat_message("user"):st.write("Hello 👋")

注意,由于我们传入"user"作为作者名称,消息会以默认头像和样式显示。
你也可以传入"assistant"作为作者名称来使用另一套默认头像和样式,或者传入自定义名称和头像。
更多详情请参阅API参考文档。
import streamlit as st
import numpy as npwith st.chat_message("assistant"):st.write("Hello human")st.bar_chart(np.random.randn(30, 3))
全屏 open_in_new
虽然我们在上述示例中使用了推荐的with语法,但你也可以直接在返回的对象上调用方法。
以下示例与上面的示例等效:
import streamlit as st
import numpy as npmessage = st.chat_message("assistant")
message.write("Hello human")
message.bar_chart(np.random.randn(30, 3))
到目前为止,我们展示的都是预定义的消息。
但如果想根据用户输入来显示消息,该怎么做呢?
st.chat_input
st.chat_input 允许你显示一个聊天输入组件,用户可以在其中输入消息。
返回值是用户的输入内容,如果用户尚未发送消息,则返回值为 None。
你还可以传入一个默认提示文本,显示在输入组件中。
以下是一个使用 st.chat_input 显示聊天输入组件并展示用户输入内容的示例:
import streamlit as stprompt = st.chat_input("Say something")
if prompt:st.write(f"User has sent the following prompt: {prompt}")
全屏模式 open_in_new
非常简单明了,对吧?现在让我们结合 st.chat_message 和 st.chat_input 来构建一个能镜像或回显你输入的聊天机器人。
构建一个镜像输入内容的聊天机器人
在本节中,我们将创建一个能镜像(或称回显)用户输入的聊天机器人。
具体来说,这个机器人会用相同的消息内容来回复用户的输入。
我们将使用 st.chat_message 来显示用户输入,用 st.chat_input 来接收用户输入。
同时还会利用 会话状态 存储聊天记录,以便在消息容器中展示历史对话。
首先,我们需要规划构建这个机器人所需的组件:
- 两个聊天消息容器,分别用于显示用户和机器人的消息
- 一个聊天输入控件,供用户输入消息
- 存储聊天记录的机制,用于在消息容器中展示历史对话。
我们可以用列表存储消息,每当用户或机器人发送消息时就追加到列表中。
列表中的每个条目都是一个字典,包含以下键:role(消息作者)和content(消息内容)
import streamlit as stst.title("Echo Bot")# Initialize chat history
if "messages" not in st.session_state:st.session_state.messages = []# Display chat messages from history on app rerun
for message in st.session_state.messages:with st.chat_message(message["role"]):st.markdown(message["content"])
在上述代码片段中,我们为应用添加了标题,并通过for循环遍历聊天历史记录,在聊天消息容器中显示每条消息(包含作者角色和消息内容)。
同时添加了检查逻辑,确认st.session_state中是否存在messages键。
若不存在,则将其初始化为空列表。
这是因为后续我们会向该列表添加消息,避免每次应用重新运行时覆盖原有列表。
现在让我们通过st.chat_input接收用户输入,将用户消息显示在聊天消息容器中,并将其添加到聊天历史记录。
# React to user input
if prompt := st.chat_input("What is up?"):# Display user message in chat message containerwith st.chat_message("user"):st.markdown(prompt)# Add user message to chat historyst.session_state.messages.append({"role": "user", "content": prompt})我们使用 := 运算符将用户输入赋值给 prompt 变量,并在同一行检查其值是否为 None。
如果用户发送了消息,我们会在聊天消息容器中显示该消息,并将其追加到聊天历史记录中。
剩下的工作就是在 if 代码块内添加聊天机器人的响应。
我们将采用与之前相同的逻辑,在聊天消息容器中显示机器人的响应(这里直接返回用户输入内容),并将其添加到历史记录中。
response = f"Echo: {prompt}"
# Display assistant response in chat message container
with st.chat_message("assistant"):st.markdown(response)
# Add assistant response to chat history
st.session_state.messages.append({"role": "assistant", "content": response})将所有内容整合起来,以下是我们简单聊天机器人GUI的完整代码及运行效果:
import streamlit as stst.title("Echo Bot")# Initialize chat history
if "messages" not in st.session_state:st.session_state.messages = []# Display chat messages from history on app rerun
for message in st.session_state.messages:with st.chat_message(message["role"]):st.markdown(message["content"])# React to user input
if prompt := st.chat_input("What is up?"):# Display user message in chat message containerst.chat_message("user").markdown(prompt)# Add user message to chat historyst.session_state.messages.append({"role": "user", "content": prompt})response = f"Echo: {prompt}"# Display assistant response in chat message containerwith st.chat_message("assistant"):st.markdown(response)# Add assistant response to chat historyst.session_state.messages.append({"role": "assistant", "content": response})
全屏打开 open_in_new
虽然上面的示例非常简单,但它是构建更复杂对话应用的绝佳起点。
请注意聊天机器人如何立即响应您的输入。
在下一节中,我们将添加延迟来模拟机器人在回复前的"思考"过程。
构建一个支持流式传输的简易聊天机器人界面
在本节中,我们将构建一个简易的聊天机器人图形界面,它会从预设的回复列表中随机选择一条消息来响应用户输入。
在下一节中,我们将使用OpenAI把这个简单的示例改造成类似ChatGPT的体验。
与之前一样,构建聊天机器人仍需要相同的组件:两个聊天消息容器分别用于显示用户和机器人的消息,一个聊天输入控件让用户可以输入消息,以及存储聊天历史记录的方式以便在消息容器中展示。
我们只需复制上一节的代码并稍作修改即可。
import streamlit as st
import random
import timest.title("Simple chat")# Initialize chat history
if "messages" not in st.session_state:st.session_state.messages = []# Display chat messages from history on app rerun
for message in st.session_state.messages:with st.chat_message(message["role"]):st.markdown(message["content"])# Accept user input
if prompt := st.chat_input("What is up?"):# Display user message in chat message containerwith st.chat_message("user"):st.markdown(prompt)# Add user message to chat historyst.session_state.messages.append({"role": "user", "content": prompt})
目前唯一的区别是我们更改了应用的标题,并添加了对 random 和 time 的导入。
我们将使用 random 从一系列回复中随机选择响应,并用 time 添加延迟来模拟聊天机器人"思考"后再回复的效果。
剩下的工作就是在 if 代码块内添加聊天机器人的回复。
我们将使用一个回复列表并随机选择一条显示。
同时会添加延迟来模拟聊天机器人回复前的"思考"过程(或流式传输其响应)。
为此我们将创建一个辅助函数,并将其放在应用代码的顶部。
# Streamed response emulator
def response_generator():response = random.choice(["Hello there! How can I assist you today?","Hi, human! Is there anything I can help you with?","Do you need help?",])for word in response.split():yield word + " "time.sleep(0.05)
回到在聊天界面中编写响应,我们将使用st.write_stream以打字机效果输出流式响应。
# Display assistant response in chat message container
with st.chat_message("assistant"):response = st.write_stream(response_generator())
# Add assistant response to chat history
st.session_state.messages.append({"role": "assistant", "content": response})
在上面,我们添加了一个占位符来显示聊天机器人的回复。
我们还添加了一个for循环来遍历响应内容,逐个单词显示。
每个单词之间设置了0.05秒的延迟,以模拟聊天机器人"思考"后再回复的效果。
最后,我们将聊天机器人的回复追加到聊天历史记录中。
你可能已经猜到,这是一个简单的流式传输实现方式。
我们将在next section中学习如何使用OpenAI实现流式传输。
将所有部分整合起来,以下是我们简单聊天机器人GUI的完整代码及运行效果:
查看完整代码
import streamlit as st
import random
import time# Streamed response emulator
def response_generator():response = random.choice(["Hello there! How can I assist you today?","Hi, human! Is there anything I can help you with?","Do you need help?",])for word in response.split():yield word + " "time.sleep(0.05)st.title("Simple chat")# Initialize chat history
if "messages" not in st.session_state:st.session_state.messages = []# Display chat messages from history on app rerun
for message in st.session_state.messages:with st.chat_message(message["role"]):st.markdown(message["content"])# Accept user input
if prompt := st.chat_input("What is up?"):# Add user message to chat historyst.session_state.messages.append({"role": "user", "content": prompt})# Display user message in chat message containerwith st.chat_message("user"):st.markdown(prompt)# Display assistant response in chat message containerwith st.chat_message("assistant"):response = st.write_stream(response_generator())# Add assistant response to chat historyst.session_state.messages.append({"role": "assistant", "content": response})
全屏 open_in_new
试试上面的演示,感受一下我们构建的内容。
这是一个非常简单的聊天机器人界面,但它包含了更复杂聊天机器人的所有组件。
在下一节中,我们将了解如何使用OpenAI构建类似ChatGPT的应用程序。
构建类ChatGPT应用
现在您已经掌握了Streamlit聊天组件的基础知识,接下来我们将进行一些调整,构建自己的类ChatGPT应用。
您需要安装OpenAI Python库并获取API密钥才能继续操作。
安装依赖项
首先我们需要安装本节所需的依赖项:
pip install openai streamlit
将OpenAI API密钥添加到Streamlit secrets
接下来,我们需要将OpenAI API密钥添加到Streamlit secrets。
具体操作是在项目目录中创建.streamlit/secrets.toml文件,并添加以下内容:
# .streamlit/secrets.toml
OPENAI_API_KEY = "YOUR_API_KEY"
编写应用
现在我们来编写这个应用。
我们将使用之前的相同代码,但会将响应列表替换为调用OpenAI API。
我们还会添加一些调整,让应用更像ChatGPT。
import streamlit as st
from openai import OpenAIst.title("ChatGPT-like clone")# Set OpenAI API key from Streamlit secrets
client = OpenAI(api_key=st.secrets["OPENAI_API_KEY"])# Set a default model
if "openai_model" not in st.session_state:st.session_state["openai_model"] = "gpt-3.5-turbo"# Initialize chat history
if "messages" not in st.session_state:st.session_state.messages = []# Display chat messages from history on app rerun
for message in st.session_state.messages:with st.chat_message(message["role"]):st.markdown(message["content"])# Accept user input
if prompt := st.chat_input("What is up?"):# Add user message to chat historyst.session_state.messages.append({"role": "user", "content": prompt})# Display user message in chat message containerwith st.chat_message("user"):st.markdown(prompt)
唯一的变化是我们向st.session_state添加了一个默认模型,并通过Streamlit的secrets设置了OpenAI API密钥。
接下来才是精彩之处——我们可以用OpenAI模型的实际响应来替换原先模拟的数据流:
# Display assistant response in chat message containerwith st.chat_message("assistant"):stream = client.chat.completions.create(model=st.session_state["openai_model"],messages=[{"role": m["role"], "content": m["content"]}for m in st.session_state.messages],stream=True,)response = st.write_stream(stream)st.session_state.messages.append({"role": "assistant", "content": response})
在上面,我们将响应列表替换为调用 OpenAI().chat.completions.create。
我们设置 stream=True 来将响应流式传输到前端。
在 API 调用中,我们传递了在会话状态中硬编码的模型名称,并将聊天历史记录作为消息列表传递。
我们还传递了聊天历史中每条消息的 role 和 content。
最后,OpenAI 返回一个响应流(拆分为令牌块),我们遍历并显示每个块。
将所有内容整合在一起,以下是我们类似 ChatGPT 应用的完整代码和结果:
from openai import OpenAI
import streamlit as stst.title("ChatGPT-like clone")client = OpenAI(api_key=st.secrets["OPENAI_API_KEY"])if "openai_model" not in st.session_state:st.session_state["openai_model"] = "gpt-3.5-turbo"if "messages" not in st.session_state:st.session_state.messages = []for message in st.session_state.messages:with st.chat_message(message["role"]):st.markdown(message["content"])if prompt := st.chat_input("What is up?"):st.session_state.messages.append({"role": "user", "content": prompt})with st.chat_message("user"):st.markdown(prompt)with st.chat_message("assistant"):stream = client.chat.completions.create(model=st.session_state["openai_model"],messages=[{"role": m["role"], "content": m["content"]}for m in st.session_state.messages],stream=True,)response = st.write_stream(stream)st.session_state.messages.append({"role": "assistant", "content": response})
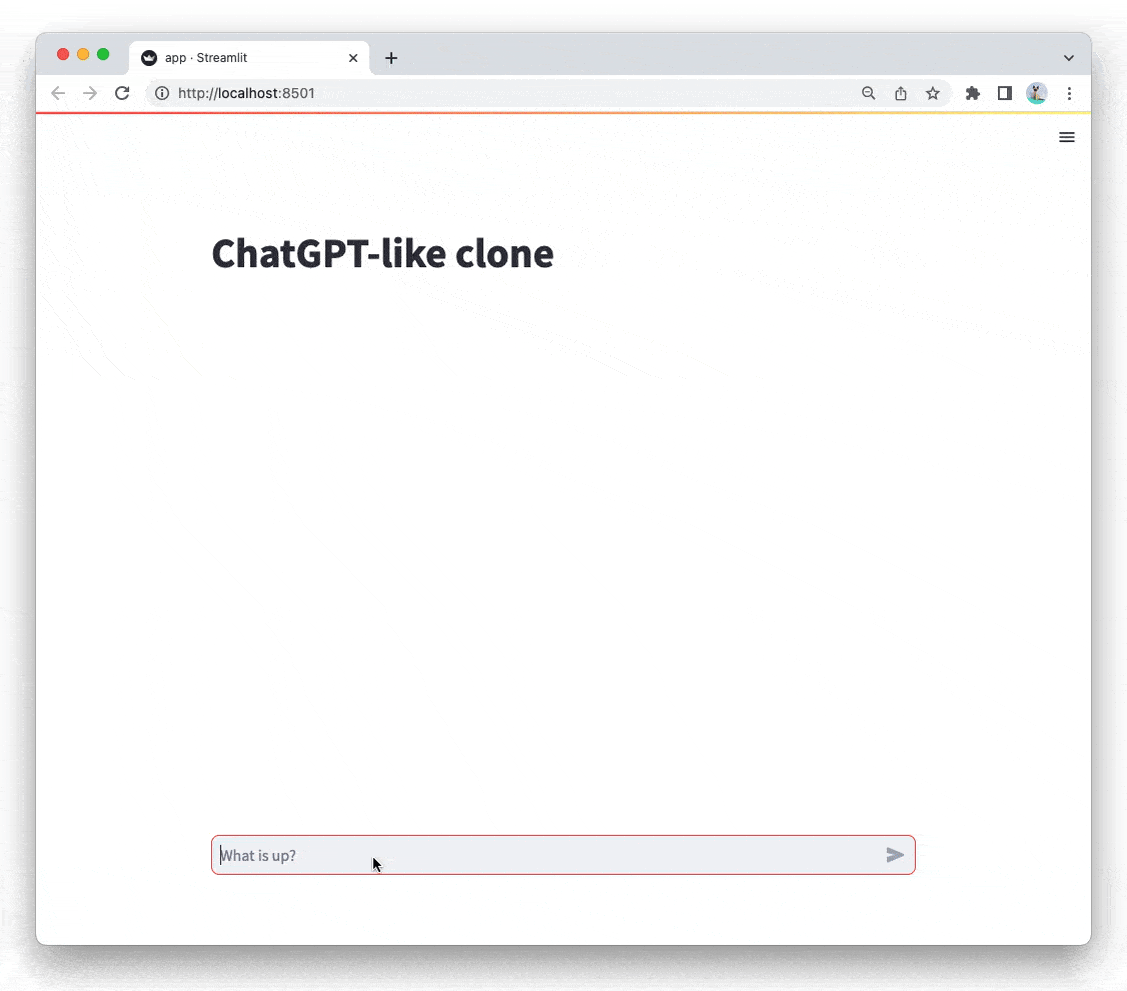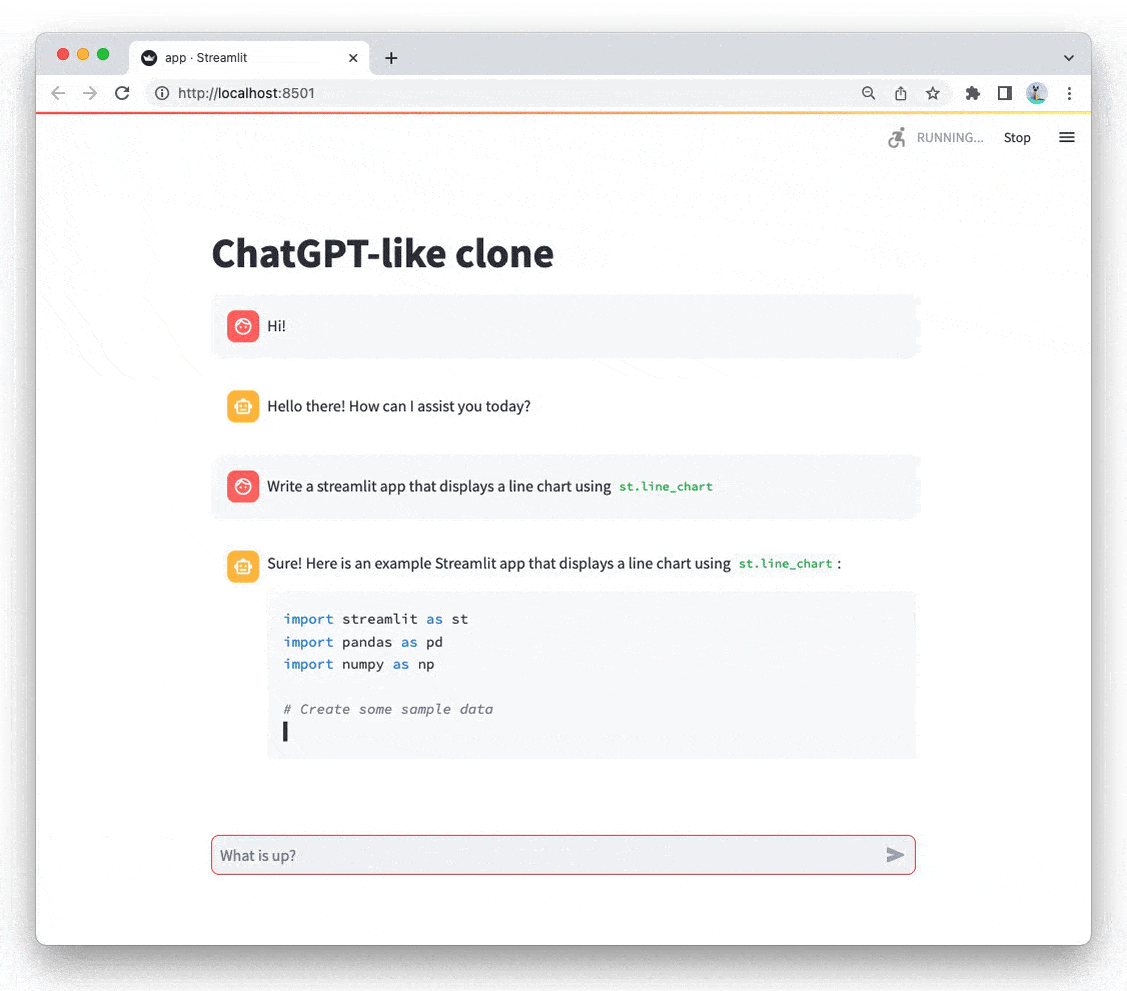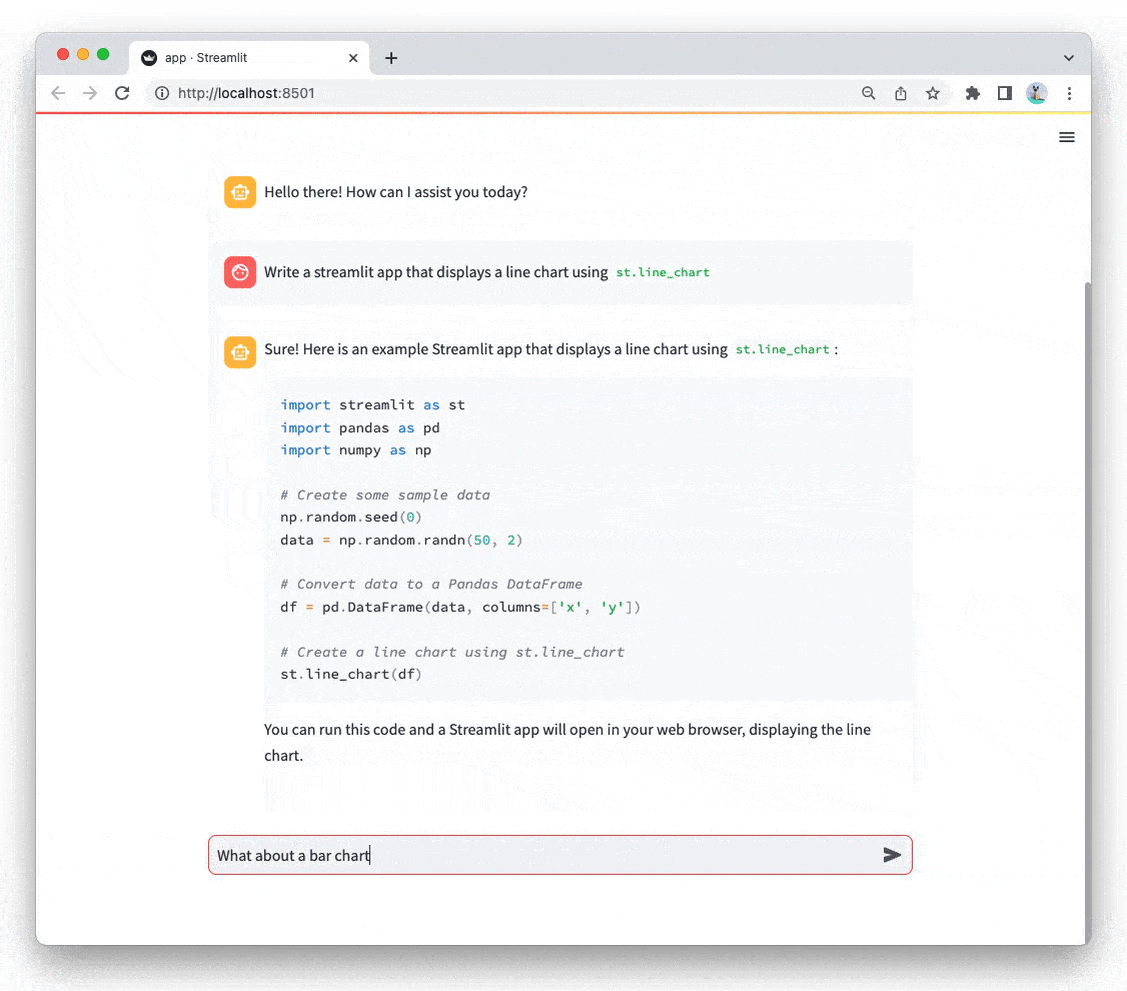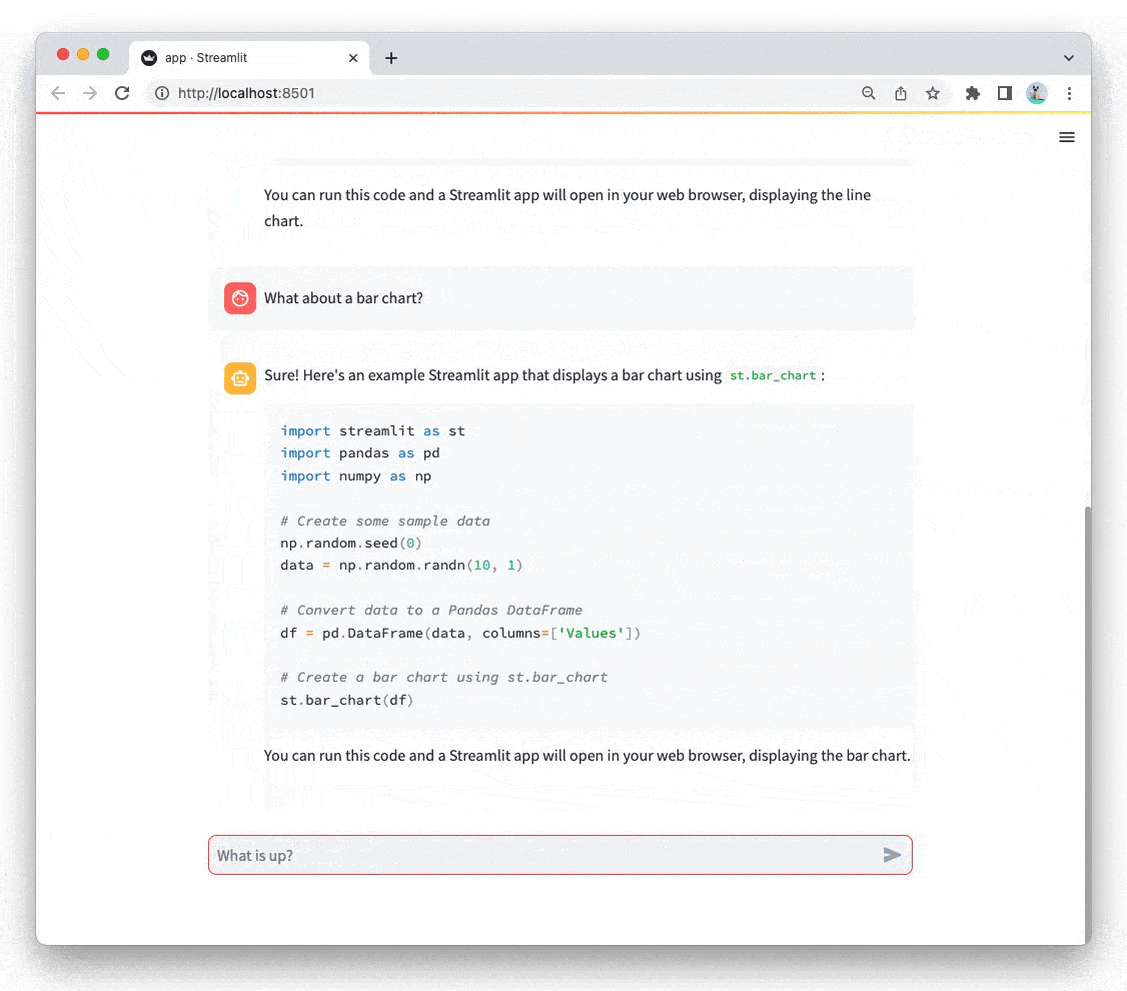
全屏查看 open_in_new
恭喜!您用不到50行代码就构建了自己的类ChatGPT应用。
我们非常期待看到您将如何运用Streamlit的聊天组件进行创作。
尝试不同的模型并调整代码,打造属于您的对话式应用。
如果您开发了有趣的作品,欢迎在论坛分享,或参考其他生成式AI应用获取灵感。
🎈
上一篇:聊天与LLM应用
下一篇:使用LangChain构建LLM应用
使用LangChain构建LLM应用
https://docs.streamlit.io/develop/tutorials/chat-and-llm-apps/llm-quickstart
18行代码实现OpenAI、LangChain与Streamlit整合
本教程将指导你构建一个基于Streamlit的LLM应用,能够根据用户输入的提示词生成文本。
这个Python应用会使用LangChain框架和Streamlit组件。
完成后,你还可以选择将应用部署到Streamlit Community Cloud。
*本教程改编自Chanin Nantesanamat的博客文章:LangChain教程#1:用18行代码构建LLM驱动应用。
*
全屏查看 open_in_new
目标
1、从终端用户处获取OpenAI密钥。
2、验证用户的OpenAI密钥有效性。
3、获取用户输入的文本提示。
4、使用用户密钥完成OpenAI认证。
5、将用户提示发送至OpenAI API。
6、接收响应并展示结果。
附加任务:将应用部署到Streamlit Community Cloud!
前提条件
- Python 3.9 或更高版本
- Streamlit
- LangChain
- OpenAI API密钥
设置编码环境
在您的IDE(集成开发环境)中,打开终端并安装以下两个Python库:
pip install streamlit langchain-openai
在工作目录的根目录下创建一个 requirements.txt 文件并保存这些依赖项。
这是后续将应用部署到 Streamlit Community Cloud 所必需的。
streamlit
openai
langchain
构建应用
该应用仅需18行代码:
import streamlit as st
from langchain_openai.chat_models import ChatOpenAIst.title("🦜🔗 Quickstart App")openai_api_key = st.sidebar.text_input("OpenAI API Key", type="password")def generate_response(input_text):model = ChatOpenAI(temperature=0.7, api_key=openai_api_key)st.info(model.invoke(input_text))with st.form("my_form"):text = st.text_area("Enter text:","What are the three key pieces of advice for learning how to code?",)submitted = st.form_submit_button("Submit")if not openai_api_key.startswith("sk-"):st.warning("Please enter your OpenAI API key!", icon="⚠")if submitted and openai_api_key.startswith("sk-"):generate_response(text)首先,创建一个新的 Python 文件,并将其保存为工作目录根目录下的 streamlit_app.py。
- 导入必要的 Python 库。
import streamlit as st
from langchain_openai.chat_models import ChatOpenAI
2、使用 st.title 创建应用的标题。
st.title("🦜🔗 Quickstart App")
3、添加一个文本输入框,供用户输入他们的OpenAI API密钥。
openai_api_key = st.sidebar.text_input("OpenAI API Key", type="password")
4、定义一个函数,用于通过用户密钥认证 OpenAI API,发送提示词并获取 AI 生成的响应。
该函数接收用户提示词作为参数,并使用 st.info 将 AI 生成的响应显示在蓝色框中。
def generate_response(input_text):model = ChatOpenAI(temperature=0.7, api_key=openai_api_key)st.info(model.invoke(input_text))
5、最后,使用 st.form() 创建一个文本框(st.text_area())用于用户输入。
当用户点击 Submit 时,系统会调用 generate-response() 函数,并将用户输入作为参数传递。
with st.form("my_form"):text = st.text_area("Enter text:","What are the three key pieces of advice for learning how to code?",)submitted = st.form_submit_button("Submit")if not openai_api_key.startswith("sk-"):st.warning("Please enter your OpenAI API key!", icon="⚠")if submitted and openai_api_key.startswith("sk-"):generate_response(text)
6、记得保存文件!
7、返回电脑终端运行应用程序。
streamlit run streamlit_app.py
应用部署
要将应用部署到 Streamlit Cloud,请按照以下步骤操作:
1、为应用创建一个 GitHub 仓库。
您的仓库应包含两个文件:
your-repository/
├── streamlit_app.py
└── requirements.txt
2、前往 Streamlit Community Cloud,点击工作区中的 New app 按钮,然后指定代码仓库、分支和主文件路径。
你还可以选择自定义子域名来个性化应用的 URL。
3、点击 Deploy! 按钮。
你的应用将立即部署到 Streamlit Community Cloud,全球用户都可以访问!🌎
总结
恭喜你用18行代码构建了一个基于LLM的Streamlit应用!🥳 你可以通过输入提示词,用这个应用生成任意文本内容。
虽然应用功能受限于OpenAI LLM的能力,但它依然能创作出富有创意且有趣的文本。
希望本教程对你有所帮助!查看更多示例,感受Streamlit与LLM的强大组合。
💖
祝Streamlit开发愉快!🎈
上一篇:构建基础LLM聊天应用
下一篇:获取聊天反馈
收集用户对LLM回复的反馈
https://docs.streamlit.io/develop/tutorials/chat-and-llm-apps/chat-response-feedback
在聊天应用中,一个常见任务是收集用户对LLM回复的反馈。
Streamlit提供了st.feedback功能,通过显示一组可选的情绪图标来便捷地收集用户情感反馈。
本教程将使用Streamlit的聊天命令和st.feedback功能,构建一个简单的聊天应用,用于收集用户对每条回复的反馈。
应用概念
- 使用
st.chat_input和st.chat_message创建聊天界面
- 使用
st.feedback收集用户对聊天回复的满意度反馈
前提条件
- 本教程需要以下版本的 Streamlit:
streamlit>=1.42.0
- 你应该有一个名为
your-repository的干净工作目录。
- 你应该对 Session State 有基本了解。
概述
在本示例中,您将构建一个聊天界面。
为了避免调用API,该聊天应用会以固定回复回应用户的提示信息。
每条聊天回复后都会附带一个反馈组件,用户可点击"点赞"或"点踩"。
下方代码中,用户提交反馈后无法修改。
如需允许用户更改评分,请参阅本教程末尾的选读说明。
以下是您将实现的效果预览:
import streamlit as st
import timedef chat_stream(prompt):response = f'You said, "{prompt}" ...interesting.'for char in response:yield chartime.sleep(0.02)def save_feedback(index):st.session_state.history[index]["feedback"] = st.session_state[f"feedback_{index}"]if "history" not in st.session_state:st.session_state.history = []for i, message in enumerate(st.session_state.history):with st.chat_message(message["role"]):st.write(message["content"])if message["role"] == "assistant":feedback = message.get("feedback", None)st.session_state[f"feedback_{i}"] = feedbackst.feedback("thumbs",key=f"feedback_{i}",disabled=feedback is not None,on_change=save_feedback,args=[i],)if prompt := st.chat_input("Say something"):with st.chat_message("user"):st.write(prompt)st.session_state.history.append({"role": "user", "content": prompt})with st.chat_message("assistant"):response = st.write_stream(chat_stream(prompt))st.feedback("thumbs",key=f"feedback_{len(st.session_state.history)}",on_change=save_feedback,args=[len(st.session_state.history)],)st.session_state.history.append({"role": "assistant", "content": response})
全屏 open_in_new
构建示例
初始化你的应用
1、在 your_repository 目录中,创建一个名为 app.py 的文件。
2、在终端中,切换到 your_repository 目录,并启动你的应用:
streamlit run app.py
您的应用界面将显示为空白,因为您尚未添加代码。
3、在 app.py 文件中编写以下内容:
import streamlit as st
import time
你将使用 time 来构建一个模拟的聊天响应流。
4、保存你的 app.py 文件,并查看正在运行的应用程序。
5、在你的应用中,选择“始终重新运行”,或按下“A”键。
预览界面会是空白的,但当你保存对 app.py 的更改时,它会自动更新。
6、返回到你的代码。
构建模拟聊天响应流的函数
首先,你需要定义一个函数来流式传输固定的聊天响应。
如果只想直接复制函数,可以跳过本节。
完整的模拟聊天流函数
def chat_stream(prompt):response = f'You said, "{prompt}" ...interesting.'for char in response:yield chartime.sleep(0.02)
定义一个函数,该函数接收提示词并生成响应:
def chat_stream(prompt):response = f'You said, "{prompt}" ...interesting.'`2、Loop through the characters and yield each one at 0.02-second intervals:`for char in response:yield chartime.sleep(.02)
你现在拥有一个完整的生成器函数来模拟聊天流对象。
初始化并渲染聊天历史记录
为了让你的聊天应用具备状态保持能力,你需要将对话历史以消息列表的形式保存到会话状态(Session State)中。
每条消息都是一个包含消息属性的字典,其键名包括以下内容:
"role": 表示消息来源(取值为"user"或"assistant")
"content": 消息正文内容(字符串格式)"feedback": 表示用户反馈的整数值。
该字段仅在消息角色为"assistant"时存在,因为用户不会对自己的提问留下反馈
1、在会话状态中初始化聊天历史记录:
if "history" not in st.session_state:st.session_state.history = []
- 遍历聊天历史中的消息,并在聊天消息容器中渲染其内容:
for i, message in enumerate(st.session_state.history):with st.chat_message(message["role"]):st.write(message["content"])
在后续步骤中,您需要为每条助手消息生成唯一键。
可以利用消息在聊天历史中的索引位置来创建唯一键。
因此,请使用enumerate()函数同时获取每条消息字典及其对应的索引。
3、针对每条助手消息,检查是否已保存反馈:
if message["role"] == "assistant":feedback = message.get("feedback", None)
如果当前消息未保存任何反馈,.get()方法将返回指定的默认值None。
4、将该反馈值以该消息的唯一键存入会话状态中:
st.session_state[f"feedback_{i}"] = feedback
由于有序聊天历史中的消息索引是唯一的,您可以使用该索引作为键值。
为了提升可读性,可以在索引前添加前缀"feedback_"。
在下一步中,为了让反馈组件显示该值,您需要为组件分配相同的键值。
5、在聊天消息容器中添加反馈组件:
st.feedback("thumbs",key=f"feedback_{i}",disabled=feedback is not None,)
目前编写的代码会显示聊天记录。
如果用户已对聊天记录中的某条消息进行过评分,反馈组件将显示该评分并处于禁用状态,用户无法更改评分。
所有未评分的消息都包含一个可用的反馈组件。
但当用户与这些组件交互时,当前代码尚未实现将评分信息保存到聊天记录的功能。
要解决这个问题,请按以下步骤使用回调函数:
6、在应用顶部,定义完 chat_stream() 之后、初始化聊天记录之前,定义一个用作回调的函数:
def save_feedback(index):st.session_state.history[index]["feedback"] = st.session_state[f"feedback_{index}"]
save_feedback() 函数接收一个索引参数,并使用该索引从 Session State 中获取关联的组件值,随后将该值保存至聊天历史记录中。
7、为你的 st.feedback 组件添加回调函数和索引参数:
st.feedback("thumbs",key=f"feedback_{i}",disabled=feedback is not None,
+ on_change=save_feedback,
+ args=[i],)
当用户与反馈组件交互时,回调函数会在应用重新运行前更新聊天记录。
添加聊天输入
1、通过 st.chat_input 组件接收用户输入的提示语,将其显示在聊天消息容器中,并保存至聊天历史记录:
if prompt := st.chat_input("Say something"):with st.chat_message("user"):st.write(prompt)st.session_state.history.append({"role": "user", "content": prompt})
st.chat_input 小组件的行为类似于一个按钮。
当用户输入提示并点击发送图标时,它会触发重新运行。
在重新运行期间,先前的代码会显示聊天历史记录。
当执行此条件块时,用户的新提示会显示出来,然后被添加到历史记录中。
在下一次重新运行时,该提示将作为历史记录的一部分显示。
:= 符号是一种在表达式中赋值变量的简写形式。
以下代码与本步骤中的先前代码等效:
prompt = st.chat_input("Say something")
if prompt:with st.chat_message("user"):st.write(prompt)st.session_state.history.append({"role": "user", "content": prompt})
2、在另一个聊天消息容器中,处理提示信息,显示回复内容,添加反馈组件,并将回复追加到聊天历史记录中:
with st.chat_message("assistant"):response = st.write_stream(chat_stream(prompt))st.feedback("thumbs",key=f"feedback_{len(st.session_state.history)}",on_change=save_feedback,args=[len(st.session_state.history)],)st.session_state.history.append({"role": "assistant", "content": response})
这与用户提示使用的模式相同。
在条件语句块内部,响应会先显示出来,然后被添加到历史记录中。
在下一次重新运行时,该响应将作为聊天历史的一部分显示。
当 Streamlit 执行 st.feedback 命令时,响应尚未被添加到聊天历史中。
此时应使用等于聊天历史长度的索引值,因为该索引正是下一行代码将响应添加到聊天历史时所处的位置。
3、保存文件后,在浏览器中测试你的新应用。
可选:修改反馈行为
当前应用中,用户可以对任何回答进行一次评分。
他们可以随时提交评分,但无法修改。
如果希望用户仅对最近一次回答进行评分,可以从聊天历史记录中移除评分组件:
for i, message in enumerate(st.session_state.history):with st.chat_message(message["role"]):st.write(message["content"])
- if message["role"] == "assistant":
- feedback = message.get("feedback", None)
- st.session_state[f"feedback_{i}"] = feedback
- st.feedback(
- "thumbs",
- key=f"feedback_{i}",
- disabled=feedback is not None,
- on_change=save_feedback,
- args=[i],
- )
或者,如果您希望允许用户修改他们的回答,只需移除 disabled 参数即可:
for i, message in enumerate(st.session_state.history):with st.chat_message(message["role"]):st.write(message["content"])if message["role"] == "assistant":feedback = message.get("feedback", None)st.session_state[f"feedback_{i}"] = feedbackst.feedback("thumbs",key=f"feedback_{i}",
- disabled=feedback is not None,on_change=save_feedback,args=[i],)
上一页:使用LangChain构建LLM应用
下一页:验证并编辑聊天响应
验证和编辑聊天回复
https://docs.streamlit.io/develop/tutorials/chat-and-llm-apps/validate-and-edit-chat-responses
在训练LLM模型时,您可能希望用户能够修正或改进聊天回复。
通过Streamlit,您可以构建一个允许用户改进聊天回复的聊天应用。
本教程使用Streamlit的聊天命令来构建一个简单的聊天应用,让用户通过修改聊天回复来提升其质量。
应用概念
- 使用
st.chat_input和st.chat_message创建聊天界面
- 利用 Session State 管理流程的不同阶段
前提条件
- 本教程需要以下版本的 Streamlit:
streamlit>=1.24.0
- 你需要一个名为
your-repository的干净工作目录。
- 你应该对 Session State 有基本了解。
概述
本示例将构建一个聊天界面。
为避免调用API,该应用内置了一个生成器函数来模拟聊天流对象。
当模拟的聊天助手生成响应时,系统会通过验证函数检查响应内容,并高亮标注可能的"错误"供用户审阅。
用户必须接受、修正或重写响应内容后才能继续操作。
以下是您将实现的效果:
import streamlit as st
import lorem
from random import randint
import timeif "stage" not in st.session_state:st.session_state.stage = "user"st.session_state.history = []st.session_state.pending = Nonest.session_state.validation = {}def chat_stream():for i in range(randint(3, 9)):yield lorem.sentence() + " "time.sleep(0.2)def validate(response):response_sentences = response.split(". ")response_sentences = [sentence.strip(". ") + "."for sentence in response_sentencesif sentence.strip(". ") != ""]validation_list = [True if sentence.count(" ") > 4 else False for sentence in response_sentences]return response_sentences, validation_listdef add_highlights(response_sentences, validation_list, bg="red", text="red"):return [f":{text}[:{bg}-background[" + sentence + "]]" if not is_valid else sentencefor sentence, is_valid in zip(response_sentences, validation_list)]for message in st.session_state.history:with st.chat_message(message["role"]):st.write(message["content"])if st.session_state.stage == "user":if user_input := st.chat_input("Enter a prompt"):st.session_state.history.append({"role": "user", "content": user_input})with st.chat_message("user"):st.write(user_input)with st.chat_message("assistant"):response = st.write_stream(chat_stream())st.session_state.pending = responsest.session_state.stage = "validate"st.rerun()elif st.session_state.stage == "validate":st.chat_input("Accept, correct, or rewrite the answer above.", disabled=True)response_sentences, validation_list = validate(st.session_state.pending)highlighted_sentences = add_highlights(response_sentences, validation_list)with st.chat_message("assistant"):st.markdown(" ".join(highlighted_sentences))st.divider()cols = st.columns(3)if cols[0].button("Correct errors", type="primary", disabled=all(validation_list)):st.session_state.validation = {"sentences": response_sentences,"valid": validation_list,}st.session_state.stage = "correct"st.rerun()if cols[1].button("Accept"):st.session_state.history.append({"role": "assistant", "content": st.session_state.pending})st.session_state.pending = Nonest.session_state.validation = {}st.session_state.stage = "user"st.rerun()if cols[2].button("Rewrite answer", type="tertiary"):st.session_state.stage = "rewrite"st.rerun()elif st.session_state.stage == "correct":st.chat_input("Accept, correct, or rewrite the answer above.", disabled=True)response_sentences = st.session_state.validation["sentences"]validation_list = st.session_state.validation["valid"]highlighted_sentences = add_highlights(response_sentences, validation_list, "gray", "gray")if not all(validation_list):focus = validation_list.index(False)highlighted_sentences[focus] = ":red[:red" + highlighted_sentences[focus][11:]else:focus = Nonewith st.chat_message("assistant"):st.markdown(" ".join(highlighted_sentences))st.divider()if focus is not None:new_sentence = st.text_input("Replacement text:", value=response_sentences[focus])cols = st.columns(2)if cols[0].button("Update", type="primary", disabled=len(new_sentence.strip()) < 1):st.session_state.validation["sentences"][focus] = (new_sentence.strip(". ") + ".")st.session_state.validation["valid"][focus] = Truest.session_state.pending = " ".join(st.session_state.validation["sentences"])st.rerun()if cols[1].button("Remove"):st.session_state.validation["sentences"].pop(focus)st.session_state.validation["valid"].pop(focus)st.session_state.pending = " ".join(st.session_state.validation["sentences"])st.rerun()else:cols = st.columns(2)if cols[0].button("Accept", type="primary"):st.session_state.history.append({"role": "assistant", "content": st.session_state.pending})st.session_state.pending = Nonest.session_state.validation = {}st.session_state.stage = "user"st.rerun()if cols[1].button("Re-validate"):st.session_state.validation = {}st.session_state.stage = "validate"st.rerun()elif st.session_state.stage == "rewrite":st.chat_input("Accept, correct, or rewrite the answer above.", disabled=True)with st.chat_message("assistant"):new = st.text_area("Rewrite the answer", value=st.session_state.pending)if st.button("Update", type="primary", disabled=new is None or new.strip(". ") == ""):st.session_state.history.append({"role": "assistant", "content": new})st.session_state.pending = Nonest.session_state.validation = {}st.session_state.stage = "user"st.rerun()
全屏 open_in_new
构建示例
初始化你的应用
1、在 your_repository 目录下,创建一个名为 app.py 的文件。
2、在终端中,切换到 your_repository 目录,然后启动你的应用:
streamlit run app.py
你的应用将显示空白,因为你仍需添加代码。
3、在 app.py 中编写以下内容:
import streamlit as st
import lorem
from random import randint
import time
你将使用 lorem、random 和 time 来构建一个模拟的聊天响应流。
4、保存你的 app.py 文件,并查看正在运行的应用程序。
5、在你的应用中,选择 “Always rerun”(总是重新运行),或按下 “A” 键。
预览界面会是空白的,但当你保存对 app.py 的更改时,它会自动更新。
6、返回你的代码。
构建模拟聊天响应流的函数
首先,你需要定义一个函数来流式传输随机聊天响应。
这个模拟的聊天流将使用 lorem 生成 3 到 9 个随机句子。
如果只想复制该函数,可以跳过本节。
完整的模拟聊天流函数
def chat_stream():for i in range(randint(3, 9)):yield lorem.sentence() + " "time.sleep(0.2)
1、为你的模拟聊天流定义一个函数:
def chat_stream():
在这个示例中,聊天流没有任何参数。
流式响应将是随机且独立于用户提示的。
2、创建一个循环,执行三到九次:
for i in range(randint(3, 9)):
3、在循环内部,从lorem中随机生成一个句子并在末尾添加空格:
yield lorem.sentence() + " "
4、要创建流式效果,在每次 yield 之间使用 time.sleep(0.2) 添加短暂延迟:
time.sleep(0.2)
你现在拥有一个完整的生成器函数来模拟聊天流对象。
创建验证函数
该应用将验证流式响应,帮助用户识别可能的错误。
要验证响应,首先需要将其拆分为句子列表。
任何少于六个单词的句子都会被标记为潜在错误。
这里采用这个标准仅用于示例说明。
完成验证响应的函数
def validate(response):response_sentences = response.split(". ")response_sentences = [sentence.strip(". ") + "."for sentence in response_sentencesif sentence.strip(". ") != ""]validation_list = [True if sentence.count(" ") > 4 else False for sentence in response_sentences]return response_sentences, validation_list
- 定义一个函数,接收字符串响应并将其拆分为句子:
def validate(response):response_sentences = response.split(". ")
2、使用列表推导式清理句子列表。
针对每个句子,去除首尾的空格和句点,然后在末尾恢复一个句点:
response_sentences = [sentence.strip(". ") + "."for sentence in response_sentencesif sentence.strip(". ") != ""]
由于用户会修改响应内容,空格和标点符号可能存在差异。
代码sentence.strip(". ") + "."会移除首尾的空格和句点,并确保每个句子以单个句点结尾。
此外,代码if sentence.strip(". ") != ""会丢弃所有空句子。
这个简单示例未处理其他可能作为句子结尾的标点符号。
3、创建一个句子验证的布尔值列表,使用True表示通过验证的句子,False表示未通过的句子:
validation_list = [True if sentence.count(" ") > 4 else False for sentence in response_sentences]
如前所述,"好"句子至少包含六个单词(即至少五个空格)。
这段代码使用列表推导式来计算每个句子中的空格数,并保存一个布尔值。
4、将句子和验证列表作为元组返回:
return response_sentences, validation_list
创建辅助函数高亮文本
为了向用户展示验证结果,你可以将标记为错误的句子高亮显示。
创建一个辅助函数,为检测到的错误添加文本和背景颜色。
完成高亮错误的功能函数
def add_highlights(response_sentences, validation_list, bg="red", text="red"):return [f":{text}[:{bg}-background[" + sentence + "]]" if not is_valid else sentencefor sentence, is_valid in zip(response_sentences, validation_list)]
- 定义一个函数,接收句子列表及其验证结果作为参数。
该函数需包含高亮显示的文本颜色和背景颜色参数:
def add_highlights(response_sentences, validation_list, bg="red", text="red"):
为方便起见,默认使用 "red" 作为高亮颜色。
在总结验证结果时,您将使用此函数将所有错误标记为红色。
如果用户选择逐个查看错误,则将所有错误标记为灰色(当前聚焦的错误除外)。
2、使用列表推导式返回修改后的句子列表,其中包含检测到错误的 Markdown 高亮标记:
return [f":{text}[:{bg}-background[" + sentence + "]]" if not is_valid else sentencefor sentence, is_valid in zip(response_sentences, validation_list)]
初始化并显示聊天历史记录
您的应用将使用会话状态(Session State)来跟踪验证和修正流程的各个阶段。
- 初始化会话状态:
if "stage" not in st.session_state:st.session_state.stage = "user"st.session_state.history = []st.session_state.pending = Nonest.session_state.validation = {}
st.session_state.stage用于跟踪用户在多阶段流程中的位置。
"user"表示应用正在等待用户输入新的提示。
其他值包括"validate"、"correct"和"rewrite",这些将在后文中定义。st.session_state.history以消息列表的形式存储对话历史。
每条消息都是一个包含消息属性("role"和"content")的字典。st.session_state.pending存储待批准的下一响应内容。st.session_state.validation存储待响应内容的验证信息。
这是一个包含"sentences"和"valid"键的字典,分别用于存储句子列表及其验证结果。
2、遍历聊天历史中的消息,并在聊天消息容器中显示其内容:
for message in st.session_state.history:with st.chat_message(message["role"]):st.write(message["content"])
定义 "user" 阶段
当 st.session_state.stage 的值为 "user" 时,应用正在等待新的提示输入。
- 为
"user"阶段开始一个条件代码块:
if st.session_state.stage == "user":
2、显示聊天输入组件,并根据其输出启动一个嵌套条件块:
if user_input := st.chat_input("Enter a prompt"):
这段嵌套代码块在用户提交提示前不会执行。
当应用首次加载(或在完成响应后返回到"user"阶段时),这里实际上就是脚本的终点。
:=符号是表达式中声明变量的简写形式。
3、将用户提示添加到聊天历史记录中,并在聊天消息容器中显示:
st.session_state.history.append({"role": "user", "content": user_input})with st.chat_message("user"):st.write(user_input)
- 在用户聊天消息容器之后,在另一个聊天消息容器中显示聊天响应。
将完整的流式响应作为待处理消息保存到会话状态中。
with st.chat_message("assistant"):response = st.write_stream(chat_stream())st.session_state.pending = response
5、将阶段更新为 "validate",然后重新运行应用:
st.session_state.stage = "validate"st.rerun()
当用户提交新提示时,应用会重新运行并执行此条件块。
在该块结束时,应用将再次重新运行并继续进入 "validate" 阶段。
定义 "validate" 阶段
当 st.session_state.stage 处于 "validate" 状态时,应用会验证待处理的响应,并向用户展示结果。
随后用户可选择后续操作(接受、修正或重写响应)。
1、为 "validate" 阶段启动条件代码块:
elif st.session_state.stage == "validate":
您可以在每个阶段使用 if 或 elif 条件判断。
每当您在会话状态(Session State)中更新阶段时,应用会立即重新运行。
因此,在同一脚本执行过程中永远不会运行两个不同的阶段。
2、为了视觉一致性,请显示一个禁用的聊天输入框:
st.chat_input("Accept, correct, or rewrite the answer above.", disabled=True)
为了用户清晰理解,使用占位文本来引导他们查看待处理的响应。
3、解析响应并使用辅助函数高亮显示所有错误:
response_sentences, validation_list = validate(st.session_state.pending)
highlighted_sentences = add_highlights(response_sentences, validation_list)
4、将高亮句子合并为单个字符串,并在聊天消息容器中显示。
为了分隔响应和后续按钮,添加一个分隔线:
with st.chat_message("assistant"):st.markdown(" ".join(highlighted_sentences))st.divider()
- 要在一行中显示按钮,请创建三列:
cols = st.columns(3)
在第一列中,启动一个条件块,并显示一个标记为"修正错误"的主类型按钮。
如果未检测到错误,则禁用该按钮。
if cols[0].button("Correct errors", type="primary", disabled=all(validation_list)):
- 在条件语句块中,将验证信息保存到 Session State,更新阶段,然后重新运行应用:
st.session_state.validation = {"sentences": response_sentences,"valid": validation_list,}
st.session_state.stage = "correct"
st.rerun()
如果用户点击"修正错误"按钮,应用程序将重新运行并执行此代码块。
在此代码块结束时,应用程序会再次重新运行并进入"correct"阶段。
8、在第二列中,开始一个条件块,并显示一个标签为"Accept:"的按钮
if cols[1].button("Accept"):
在条件语句块内,将待处理消息保存至聊天记录,并从会话状态中清除待处理及验证信息:
st.session_state.history.append({"role": "assistant", "content": st.session_state.pending})st.session_state.pending = Nonest.session_state.validation = {}
10、将阶段更新为 "user",然后重新运行应用:
st.session_state.stage = "user"st.rerun()
如果用户点击"接受"按钮,应用将重新运行并执行此代码块。
在此代码块结束时,应用会再次重新运行并返回到"user"阶段。
11、在第三列中,启动一个条件块,并显示一个标记为"重写答案:"的三级类型按钮
if cols[2].button("Rewrite answer", type="tertiary"):
12、在条件语句块中,将阶段更新为"rewrite"并重新运行应用:
st.session_state.stage = "rewrite"st.rerun()
如果用户点击"重写答案"按钮,应用程序将重新运行并执行此条件块。
在该块结束时,应用程序会再次重新运行并进入"rewrite"阶段。
您无需将任何信息保存到st.session_state.validation中,因为"rewrite"阶段不会使用这些信息。
定义 "correct" 阶段
当 st.session_state.stage 为 "correct" 时,用户可以修正或接受 st.session_state.validation 中识别的错误。
每次脚本运行时,应用会将用户焦点定位到列表中的第一个错误。
当用户处理完一个错误后,该错误会从列表中移除,并在下一次脚本运行时高亮显示下一个错误。
这一过程持续进行,直到所有错误都被清除。
之后,用户可以选择接受结果、返回 "validate" 阶段,或进入 "rewrite" 阶段。
1、为 "correct" 阶段开启条件代码块:
elif st.session_state.stage == "correct":
2、为了视觉一致性,显示一个禁用的聊天输入框:
st.chat_input("Accept, correct, or rewrite the answer above.", disabled=True)
3、为便于编码,从会话状态中提取验证信息并存入变量:
response_sentences = st.session_state.validation["sentences"]validation_list = st.session_state.validation["valid"]
4、使用辅助函数高亮显示含有错误的句子。
高亮颜色设为灰色。
highlighted_sentences = add_highlights(response_sentences, validation_list, "gray", "gray")
在接下来的步骤中,为了让用户专注于一个错误,您将更改一个句子的高亮颜色。
5、检查 validation_list 中是否存在错误。
如果存在错误,获取第一个错误的索引,并替换对应句子的 Markdown 高亮标记:
if not all(validation_list):focus = validation_list.index(False)highlighted_sentences[focus] = ":red[:red" + highlighted_sentences[focus][11:]
highlighted_sentences[focus] 以 ":gray[:gray-background[" 开头。
因此,highlighted_sentences[focus][11:] 会移除前11个字符,以便你可以前置添加 ":red[:red" 替代。
6、为 focus 设置一个无错误时的默认值:
else:focus = None
7、在聊天消息容器中,显示高亮回复。
为将回复与后续按钮分隔开,需添加一个分隔线:
with st.chat_message("assistant"):st.markdown(" ".join(highlighted_sentences))st.divider()
8、启动条件块:如果存在错误,则显示一个预填充了首个错误的文本输入框。
这就是你用红色高亮显示的错误:
if focus is not None:new_sentence = st.text_input("Replacement text:", value=response_sentences[focus])
value=response_sentences[focus] 会在文本输入框中预填充与 focus 相关联的句子。
用户可以编辑该文本或完全替换它。
你还需要添加一个按钮,以便用户可以选择删除该文本。
9、要在一行中显示按钮,需要创建两列:
cols = st.columns(2)
在第一列中,启动一个条件块,并显示一个标记为"Update"的主类型按钮。
如果文本输入为空,则禁用该按钮。
if cols[0].button("Update", type="primary", disabled=len(new_sentence.strip()) < 1):
11、在条件语句块内,更新句子及其验证逻辑:
st.session_state.validation["sentences"][focus] = (new_sentence.strip(". ") + ".")st.session_state.validation["valid"][focus] = True
12、使用新的结果响应更新 st.session_state.pending 中的完整响应,并重新运行应用:
st.session_state.pending = " ".join(st.session_state.validation["sentences"])st.rerun()
如果用户点击"更新"按钮,应用程序将重新运行并执行此条件块。
在该块结束时,应用会再次重新运行,并继续处于"correct"阶段,同时高亮显示下一个错误。
13、在第二列中,启动一个条件块,并显示一个标记为"移除"的按钮。
在该条件块内,从Session State中的列表中弹出句子及其验证信息。
if cols[1].button("Remove"):st.session_state.validation["sentences"].pop(focus)st.session_state.validation["valid"].pop(focus)
- 使用新的结果响应更新
st.session_state.pending中的完整响应,并重新运行应用:
st.session_state.pending = " ".join(st.session_state.validation["sentences"])st.rerun()
如果用户点击"移除"按钮,应用程序将重新运行并执行这个条件块。
在该块结束时,应用程序会再次重新运行,并继续处于"correct"阶段,同时高亮显示下一个错误。
15、当没有错误时,启动一个else块。
要在一行中显示按钮,请创建两列:
else:cols = st.columns(2)
当用户解决所有错误后,需要确认最终结果。
此时不再显示"Update"和"Remove"按钮,而是显示"Accept"和"Re-validate"按钮。
16、在第一列中,启动一个条件块,并显示一个标记为"Accept"的主类型按钮。
在该条件块内,将待处理消息保存至聊天历史记录,并从会话状态中清除待处理和验证信息:
if cols[0].button("Accept", type="primary"):st.session_state.history.append({"role": "assistant", "content": st.session_state.pending})st.session_state.pending = Nonest.session_state.validation = {}
17、将阶段更新为 "user",然后重新运行应用:
st.session_state.stage = "user"st.rerun()
如果用户点击"Accept"按钮,应用程序将重新运行并执行此代码块。
在此代码块结束时,应用程序会再次重新运行并返回到"user"阶段。
18、在第二列中,启动一个条件块,并显示一个标记为"Re-validate:"的按钮
if cols[1].button("Re-validate"):
19、在条件语句块中,清除 Session State 中的验证信息,将阶段更新为 "validate",并重新运行应用:
st.session_state.validation = {}st.session_state.stage = "validate"st.rerun()
如果用户点击"重新验证"按钮,应用程序将重新运行并执行此条件块。
在该块结束时,应用程序会再次重新运行并进入"validate"阶段。
定义 "rewrite" 阶段
当 st.session_state.stage 处于 "rewrite" 状态时,用户可以在文本区域自由编辑响应内容。
1、 为 "rewrite" 阶段开启条件判断块:
elif st.session_state.stage == "rewrite":
2、为了视觉一致性,显示一个禁用的聊天输入框:
st.chat_input("Accept, correct, or rewrite the answer above.", disabled=True)
3、为了让用户编辑待发送的回复内容,在聊天消息容器中显示一个文本输入区域:
with st.chat_message("assistant"):new = st.text_area("Rewrite the answer", value=st.session_state.pending)
value=st.session_state.pending 会使用待处理的响应预填充文本输入区域。
用户可以编辑该内容或完全替换文本。
4、开始一个条件块,并显示一个标记为"更新"的主类型按钮。
如果文本输入区域为空,则禁用该按钮。
if st.button("Update", type="primary", disabled=new is None or new.strip(". ") == ""):
- 在条件语句块内,将新响应添加到聊天历史记录中,并清除会话状态中的待处理和验证信息:
st.session_state.history.append({"role": "assistant", "content": new})st.session_state.pending = Nonest.session_state.validation = {}
6、将阶段更新为"user",然后重新运行应用:
st.session_state.stage = "user"st.rerun()
如果用户点击"更新"按钮,应用程序将重新运行并执行此代码块。
在此代码块执行结束时,应用程序会再次重新运行并返回到"user"阶段。
7、保存文件并在浏览器中测试您的新应用。
改进示例
现在你有了一个可运行的应用程序,可以逐步优化它。
由于各阶段之间存在一些通用元素,你可能需要引入额外的函数来减少重复代码。
可以为按钮添加回调函数,避免应用连续两次重新运行。
此外,还可以处理更多边界情况。
当前示例已包含防止保存空响应的基础保护,但还不够全面。
如果响应中的每个句子都被标记为错误,用户可能在"correct"阶段删除所有句子并接受空结果。
当"correct"阶段的响应为空时,建议禁用"Accept"按钮或将其改为"Rewrite"。
要观察另一个边界案例,可在运行示例中尝试以下操作:
1、提交提示词
2、选择"Rewrite answer"
3、在文本区域全选内容并按Delete键(不要点击或跳转到文本区域外)
4、立即点击"Update"按钮
当你在其他部件存在未提交值的情况下点击按钮时,Streamlit会先更新该部件的值,再更新按钮的值,最后触发重新运行。
由于在更新文本区域和更新按钮之间没有重新运行,"Update"按钮不会按预期被禁用。
要修正这个问题,可以在"rewrite"阶段额外检查文本区域是否为空:
- if st.button(
- "Update", type="primary", disabled=new is None or new.strip(". ") == ""
- ):
+ is_empty = new is None or new.strip(". ") == ""
+ if st.button("Update", type="primary", disabled=is_empty) and not is_empty:st.session_state.history.append({"role": "assistant", "content": new})st.session_state.pending = Nonest.session_state.validation = {}st.session_state.stage = "user"st.rerun()
现在,如果您重复上述步骤,当应用程序重新运行时,即使按钮触发了重新运行,条件代码块也不会执行。
按钮将被禁用,用户可以继续操作,就像他们刚刚点击或离开文本区域一样。
上一节:获取聊天反馈
下一节:配置与主题
自定义主题并配置应用
https://docs.streamlit.io/develop/tutorials/configuration-and-theming
使用静态字体文件自定义字体
为您的应用添加新字体。
本教程通过静态字体文件来定义替代字体。
https://docs.streamlit.io/develop/tutorials/configuration-and-theming/static-fonts
使用可变字体文件自定义字体
为您的应用添加新字体。
本教程将使用可变字体文件来定义替代字体。
https://docs.streamlit.io/develop/tutorials/configuration-and-theming/variable-fonts
上一页:聊天和LLM应用
下一页:使用静态字体文件
使用静态字体文件自定义字体
https://docs.streamlit.io/develop/tutorials/configuration-and-theming/static-fonts
Streamlit 默认使用 Source Sans 字体,但你可以配置应用使用其他字体。
本教程使用静态字体文件,是自定义 Streamlit 应用中的字体中示例 2 的详细步骤说明。
如需使用可变字体文件的示例,请参阅使用可变字体文件自定义字体。
前提条件
- 本教程需要以下版本的 Streamlit:
streamlit>=1.45.0
- 您需要有一个名为
your-repository的干净工作目录。
- 您需要对静态文件服务有基本了解。
- 您需要具备网页开发中使用字体文件的基础知识。
如果不熟悉,建议先阅读自定义 Streamlit 应用中的字体至示例 2 部分。
概述
以下示例使用 Tuffy 字体。
该字体包含四个静态字体文件,分别对应以下四种字重-样式组合:
- 常规体(normal normal)
- 粗体(normal bold)
- 斜体(italic normal)
- 粗斜体(italic bold)
这是你将构建的内容预览:
完整的 config.toml 文件目录结构:
your_repository/
├── .streamlit/
│ └── config.toml
├── static/
│ ├── Tuffy-Bold.ttf
│ ├── Tuffy-BoldItalic.ttf
│ ├── Tuffy-Italic.ttf
│ └── Tuffy-Regular.ttf
└── streamlit_app.py
.streamlit/config.toml:
[server]
enableStaticServing = true[[theme.fontFaces]]
family="tuffy"
url="app/static/Tuffy-Regular.ttf"
style="normal"
weight=400
[[theme.fontFaces]]
family="tuffy"
url="app/static/Tuffy-Bold.ttf"
style="normal"
weight=700
[[theme.fontFaces]]
family="tuffy"
url="app/static/Tuffy-Italic.ttf"
style="italic"
weight=400
[[theme.fontFaces]]
family="tuffy"
url="app/static/Tuffy-BoldItalic.ttf"
style="italic"
weight=700[theme]
font="tuffy"
streamlit_app.py:
import streamlit as stst.write("Normal ABCabc123")
st.write("_Italic ABCabc123_")
st.write("*Bold ABCabc123*")
st.write("Bold-italic ABCabc123")
st.write("`Code ABCabc123`")
下载并保存字体文件
1、访问 Google fonts。
2、搜索或直接打开 Tuffy 字体页面,点击"获取字体"。
3、下载字体文件:在页面右上角点击购物袋图标(shopping_bag),然后选择"下载 全部下载"。
4、在下载目录中解压下载的压缩包。
5、从解压后的文件中,将TTF字体文件复制保存到 your_repository/ 下的 static/ 目录中。
需要复制的文件:
Tuffy/
├── Tuffy-Bold.ttf
├── Tuffy-BoldItalic.ttf
├── Tuffy-Italic.ttf
└── Tuffy-Regular.ttf
将这些文件保存到您的代码仓库中:
your_repository/
└── static/├── Tuffy-Bold.ttf├── Tuffy-BoldItalic.ttf├── Tuffy-Italic.ttf└── Tuffy-Regular.ttf
创建应用配置
1、在 your_repository/ 目录下,创建一个 .streamlit/config.toml 文件:
your_repository/
├── .streamlit/
│ └── config.toml
└── static/├── Tuffy-Bold.ttf├── Tuffy-BoldItalic.ttf├── Tuffy-Italic.ttf└── Tuffy-Regular.ttf
2、要启用静态文件服务,请在 .streamlit/config.toml 中添加以下文本:
[server]
enableStaticServing = true
这样,static/目录中的文件就可以通过应用的URL以相对路径app/static/{filename}公开访问。
- 要定义替代字体,请在
.streamlit/config.toml中添加以下文本:
[[theme.fontFaces]]family="tuffy"url="app/static/Tuffy-Regular.ttf"style="normal"weight=400[[theme.fontFaces]]family="tuffy"url="app/static/Tuffy-Bold.ttf"style="normal"weight=700[[theme.fontFaces]]family="tuffy"url="app/static/Tuffy-Italic.ttf"style="italic"weight=400[[theme.fontFaces]]family="tuffy"url="app/static/Tuffy-BoldItalic.ttf"style="italic"weight=700
[[theme.fontFaces]] 表格可以重复使用,以便通过多个文件定义单一字体或定义多种字体。
在此示例中,这些定义使 "tuffy" 可供其他字体配置选项使用。
提示
为了方便起见,请避免在字体家族名称中使用空格。
当您声明默认字体时,也可以声明备用字体。
如果字体家族名称中不包含空格,就无需使用内部引号。
4、要将备用字体设置为应用的默认字体,请在 .streamlit/config.toml 中添加以下文本:
[theme]
font="tuffy"
这将把 Tuffy 设置为应用中除行内代码和代码块外所有文本的默认字体。
构建示例
为了验证字体是否正确加载,请创建一个简单的应用。
初始化你的应用
1、在你的代码仓库中,创建一个名为 streamlit_app.py 的文件。
2、在终端中,切换到你的代码仓库目录,并启动应用:
streamlit run app.py
您的应用将显示空白页面,因为您尚未添加代码。
3、在 streamlit_app.py 文件中编写以下内容:
import streamlit as st
4、保存你的 streamlit_app.py 文件,然后查看正在运行的应用程序。
5、在应用中选择"总是重新运行",或按下"A"键。
预览界面会是空白的,但当你保存对 streamlit_app.py 的修改时,它会自动更新。
6、返回你的代码。
在应用中显示文本
1、在工作目录下创建一个 streamlit_app.py 文件
2、在 streamlit_app.py 文件中添加以下文本:
import streamlit as stst.write("Normal ABCabc123")
st.write("_Italic ABCabc123_")
st.write("*Bold ABCabc123*")
st.write("Bold-italic ABCabc123")
st.write("Code ABCabc123")
3、保存你的 streamlit_app.py 文件,并查看正在运行的应用程序。
上一页:配置与主题
下一页:使用可变字体文件
使用可变字体文件自定义字体
https://docs.streamlit.io/develop/tutorials/configuration-and-theming/variable-fonts
Streamlit 默认使用 Source Sans 字体,但你可以配置应用使用其他字体。
本教程使用可变字体文件,是自定义 Streamlit 应用中的字体中示例 1 的详细步骤说明。
如需使用静态字体文件的示例,请参阅使用静态字体文件自定义字体。
前提条件
- 本教程需要以下版本的 Streamlit:
streamlit>=1.45.0
- 您需要准备一个名为
your-repository的干净工作目录。
- 您需要对静态文件服务有基本了解。
- 您需要具备网页开发中字体文件处理的基础知识。
若不了解,请先阅读自定义 Streamlit 应用字体至示例1部分。
概述
以下示例通过静态文件托管服务来部署 Google 的 Noto Sans 和 Noto Sans Mono 字体,并配置应用程序使用这些字体。
这两种字体均采用可变字体文件定义,其中包含参数化的字重。
但由于字体样式未被参数化,Noto Sans 需要两个独立文件分别定义常规体和斜体样式。
而 Noto Sans Mono 并未提供单独的斜体样式文件。
根据 CSS 规则,由于未显式提供斜体样式,浏览器将通过倾斜常规体字体来模拟斜体效果。
以下是您将构建的内容预览:
完整的 config.toml 文件
目录结构:
your_repository/
├── .streamlit/
│ └── config.toml
├── static/
│ ├── NotoSans-Italic-VariableFont_wdth,wght.ttf
│ ├── NotoSans-VariableFont_wdth,wght.ttf
│ └── NotoSansMono-VariableFont_wdth,wght.ttf
└── streamlit_app.py
.streamlit/config.toml:
[server]
enableStaticServing = true[[theme.fontFaces]]
family="noto-sans"
url="app/static/NotoSans-Italic-VariableFont_wdth,wght.ttf"
style="italic"
[[theme.fontFaces]]
family="noto-sans"
url="app/static/NotoSans-VariableFont_wdth,wght.ttf"
style="normal"
[[theme.fontFaces]]
family="noto-mono"
url="app/static/NotoSansMono-VariableFont_wdth,wght.ttf"[theme]
font="noto-sans"
codeFont="noto-mono"
streamlit_app.py:
import streamlit as stst.write("Normal efg")
st.write("_Italic efg_")
st.write("*Bold efg*")
st.write("Bold-italic efg")
st.write("`Code efg`")
下载并保存字体文件
1、访问 Google fonts。
2、搜索或点击链接进入 Noto Sans,然后选择"获取字体"。
3、搜索或点击链接进入 Noto Sans Mono,然后选择"获取字体"。
4、要下载字体文件,在右上角选择购物袋图标 (shopping_bag),然后选择"下载 全部下载"。
5、在下载目录中解压下载的文件。
6、从解压后的文件中,复制并保存 TTF 字体文件到 your_repository/ 下的 static/ 目录中。
复制以下文件:
Noto_Sans,Noto_Sans_Mono/
├── Noto_Sans_Mono/
│ └── NotoSansMono-VariableFont_wdth,wght.ttf
└── Noto_Sans/├── NotoSans-Italic-VariableFont_wdth,wght.ttf└── NotoSans-VariableFont_wdth,wght.ttf
将这些文件保存到你的代码仓库中:
your_repository/
└── static/├── NotoSans-Italic-VariableFont_wdth,wght.ttf├── NotoSans-VariableFont_wdth,wght.ttf└── NotoSansMono-VariableFont_wdth,wght.ttf
在这个示例中,字体文件分别是 NotoSans-Italic-VariableFont_wdth,wght.ttf 和 NotoSansMono-VariableFont_wdth,wght.ttf,分别对应 Noto Sans 斜体和常规字体。NotoSansMono-VariableFont_wdth,wght.ttf 是 Noto Sans Mono 的字体文件。
创建应用配置
1、在 your_repository/ 目录下,创建一个 .streamlit/config.toml 文件:
your_repository/
├── .streamlit/
│ └── config.toml
└── static/├── NotoSans-Italic-VariableFont_wdth,wght.ttf├── NotoSans-VariableFont_wdth,wght.ttf└── NotoSansMono-VariableFont_wdth,wght.ttf
2、要启用静态文件服务,在 .streamlit/config.toml 文件中添加以下内容:
[server]
enableStaticServing = true
这样,static/目录中的文件就能通过应用的URL以相对路径app/static/{filename}公开访问。
3、要定义替代字体,请在.streamlit/config.toml中添加以下文本:
[[theme.fontFaces]]
family="noto-sans"
url="app/static/NotoSans-Italic-VariableFont_wdth,wght.ttf"
style="italic"
[[theme.fontFaces]]
family="noto-sans"
url="app/static/NotoSans-VariableFont_wdth,wght.ttf"
style="normal"
[[theme.fontFaces]]
family="noto-mono"
url="app/static/NotoSansMono-VariableFont_wdth,wght.ttf"
[[theme.fontFaces]] 表格可以重复使用,通过多个文件来定义单一字体或定义多种字体。在此示例中,这些定义使得 "noto-sans" 和 "noto-mono" 可供其他字体配置选项使用。
提示
为了方便起见,建议字体家族名称中不要使用空格。在声明默认字体时,可以同时声明备用字体。如果字体家族名称不含空格,就无需使用内引号。
4、要将备用字体设置为应用的默认字体,请在 .streamlit/config.toml 文件中添加以下内容:
[theme]
font="noto-sans"
codeFont="noto-mono"
这将把 Noto Sans 设置为应用中所有文本的默认字体,但行内代码和代码块除外,它们将使用 Noto Sans Mono 字体。
构建示例
为了验证字体是否正确加载,请创建一个简单的应用。
初始化你的应用
1、在你的代码仓库中,创建一个名为 streamlit_app.py 的文件。
2、在终端中,切换到你的代码仓库目录,并启动应用:
streamlit run app.py
你的应用目前会是空白的,因为你还需要添加代码。
3、在 streamlit_app.py 文件中,编写以下内容:
import streamlit as st
4、保存你的 streamlit_app.py 文件,并查看正在运行的应用程序。
5、在应用程序中,选择"总是重新运行",或按下"A"键。
预览界面将显示为空白,但当你保存对 streamlit_app.py 的更改时,它会自动更新。
6、返回你的代码。
在应用中显示文本
1、在工作目录下创建一个 streamlit_app.py 文件。
2、在 streamlit_app.py 文件中添加以下文本:
import streamlit as stst.write("Normal efg")
st.write("_Italic efg_")
st.write("*Bold efg*")
st.write("Bold-italic efg")
st.write("`Code efg`")
该示例在每行中都包含"efg",以便在运行应用时更清晰地展示排版差异。斜体的"f"会下沉至基线以下,而常规的"f"则不会。斜体的"e"前端呈圆弧状,而常规的"e"则带有尖锐转角。
3、保存您的streamlit_app.py文件,并查看正在运行的应用。
上一页:使用静态字体文件
下一页:连接数据源
将Streamlit连接到数据源
https://docs.streamlit.io/develop/tutorials/databases
这些分步指南展示了如何将Streamlit应用程序连接到各种数据库和API。
它们使用Streamlit的Secrets管理和缓存功能,以提供安全且快速的数据访问。
- AWS S3
- BigQuery
- Firestore (博客)
- Google Cloud Storage
- Microsoft SQL Server
- MongoDB
- MySQL
- Neon
- PostgreSQL
- 私有Google表格
- 公开Google表格
- Snowflake
- Supabase
- Tableau
- TiDB
- TigerGraph
将Streamlit连接到AWS S3
https://docs.streamlit.io/develop/tutorials/databases/aws-s3
简介
本指南介绍如何从 Streamlit Community Cloud 安全访问 AWS S3 上的文件。
方案采用 Streamlit FilesConnection 和 s3fs 库,并可选结合 Streamlit 的 Secrets 密钥管理功能实现。
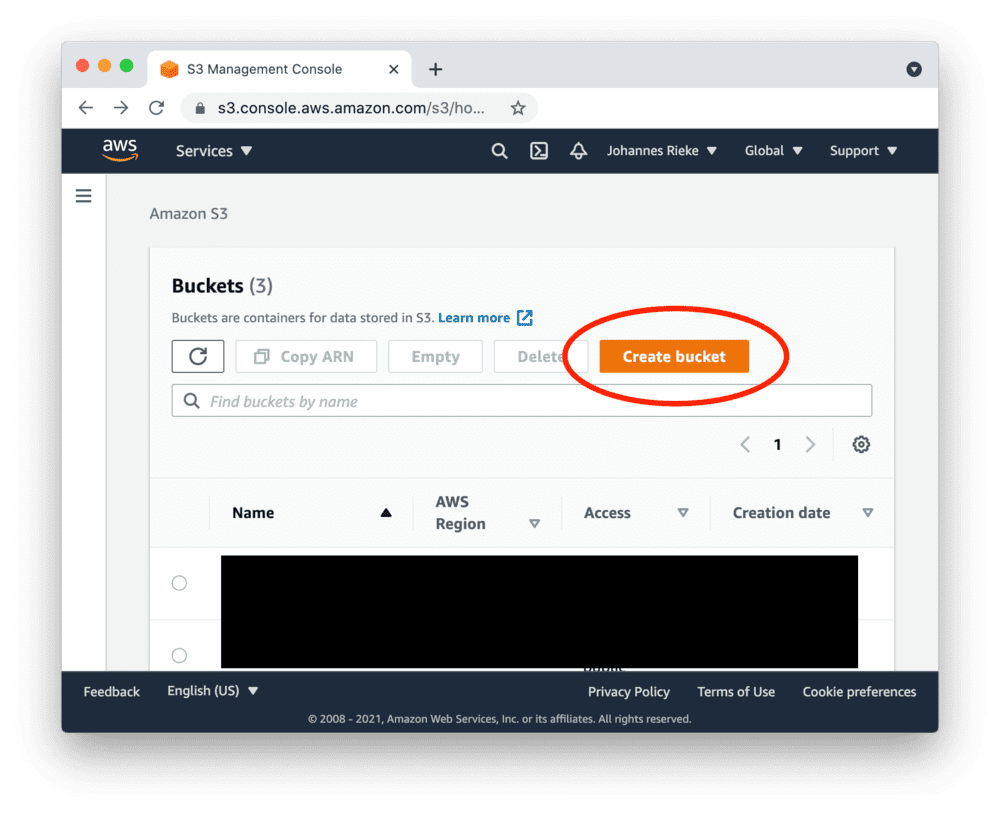
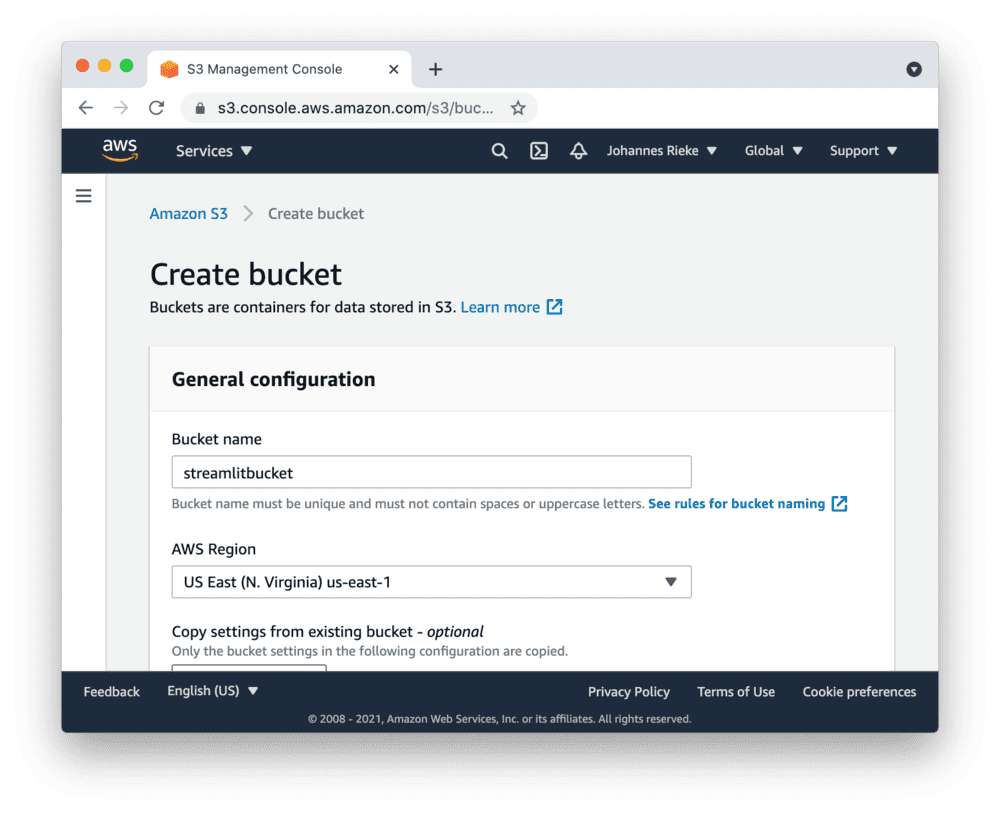
创建S3存储桶并添加文件
注意:
如果您已有想要使用的存储桶,可以直接跳转到下一步。
首先,请注册AWS账户或登录。
进入S3控制台并创建新存储桶:
导航至新存储桶的上传区域:
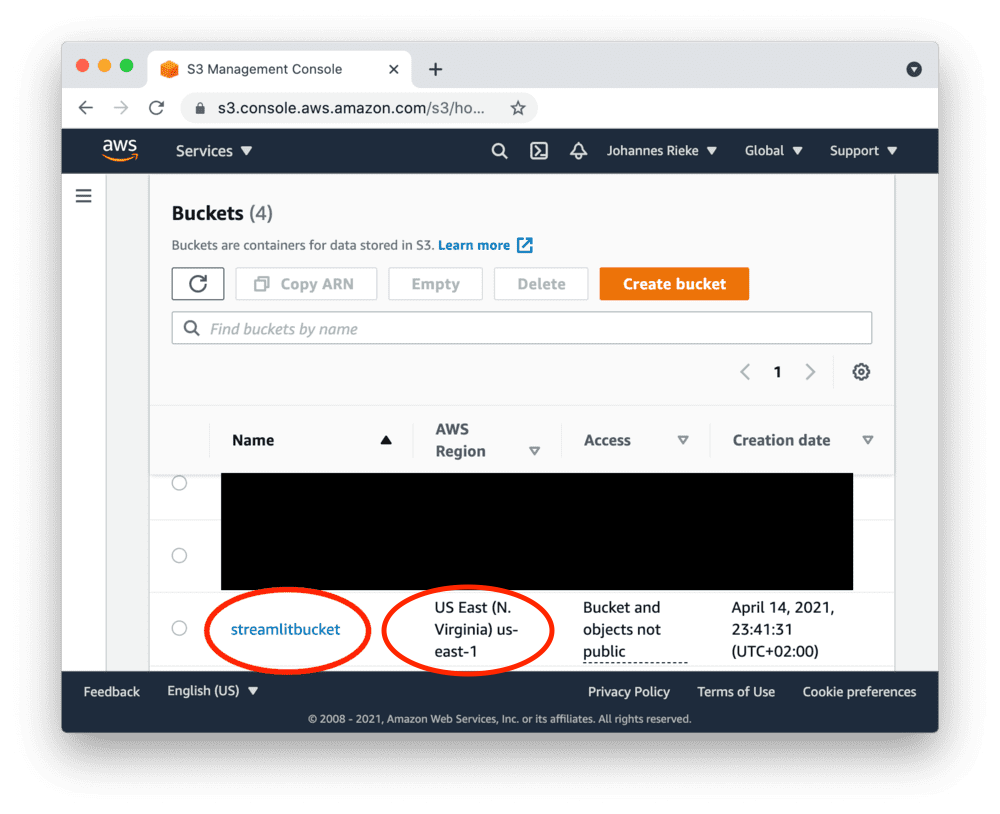
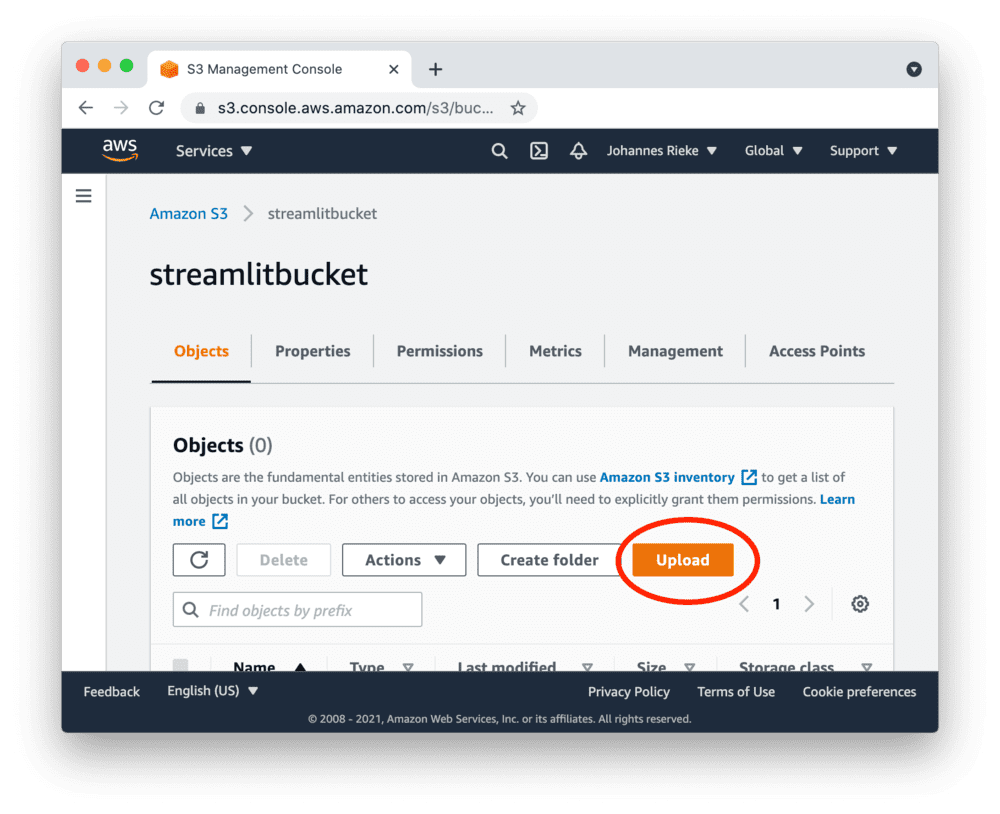
请记录下"AWS区域"供后续使用。
本例中为us-east-1,但您的区域可能不同。
接下来上传包含示例数据的CSV文件:myfile.csv
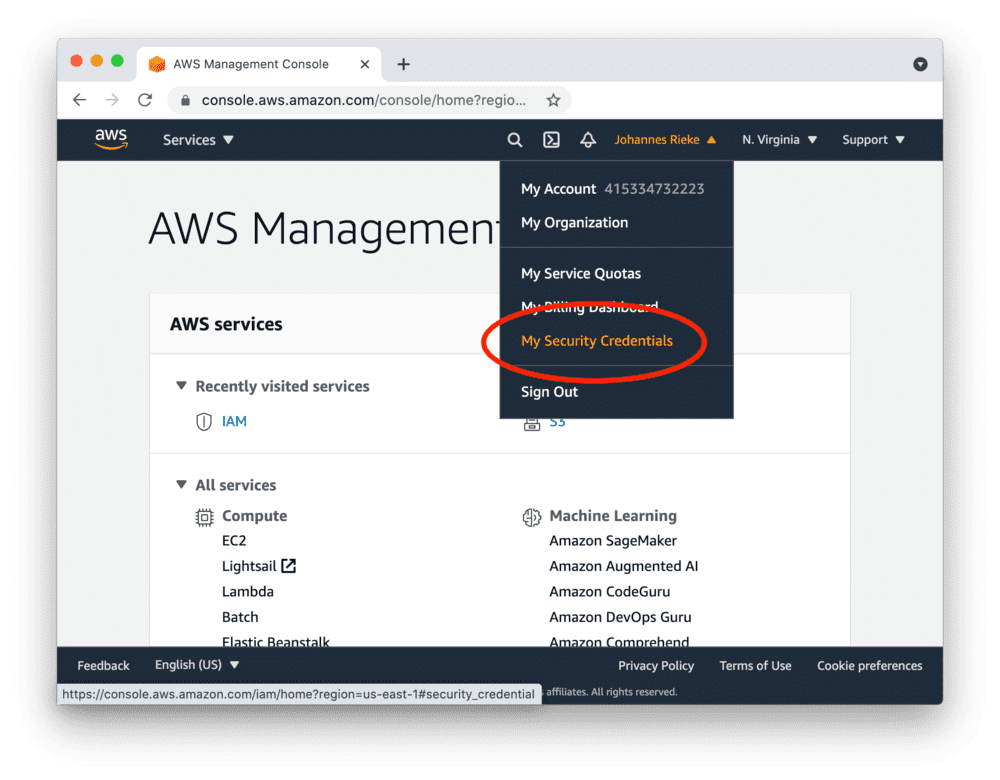
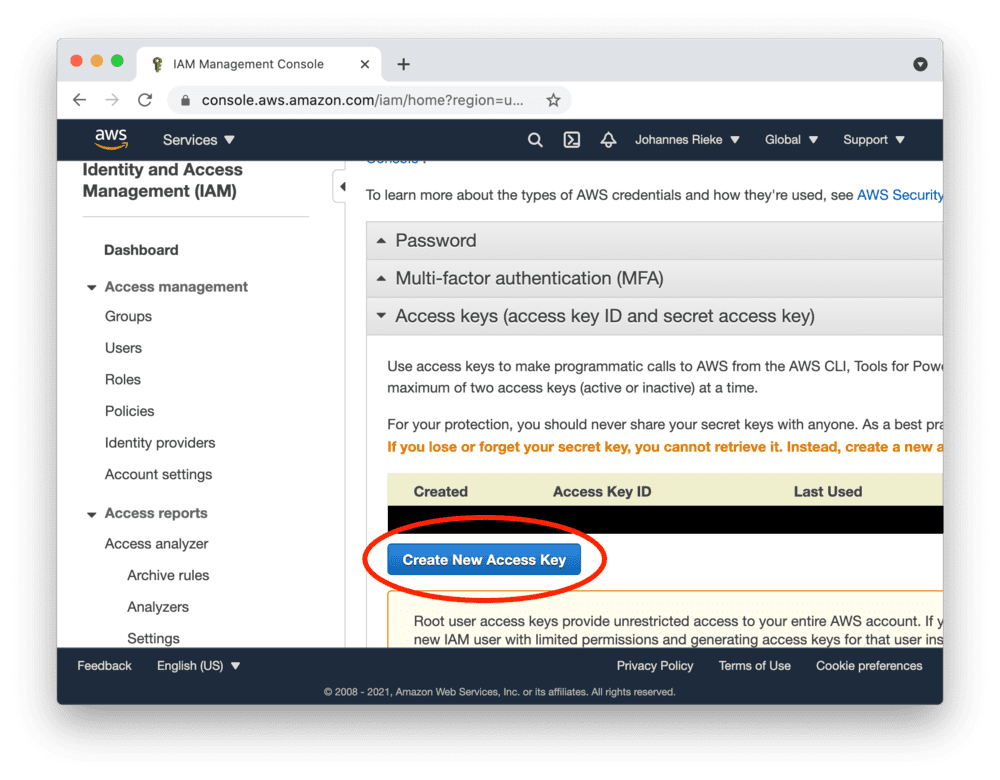
创建访问密钥
前往 AWS 控制台,按以下步骤创建访问密钥并复制"Access Key ID"和"Secret Access Key":
提示
以根用户身份创建的访问密钥拥有广泛权限。
为了提高AWS账户的安全性,建议创建一个权限受限的IAM账户并使用其访问密钥。
更多信息请参阅此处。
本地设置 AWS 凭据
Streamlit FilesConnection 和 s3fs 会自动读取并使用您现有的 AWS 凭据和配置(如果已配置)——例如来自 ~/.aws/credentials 文件或环境变量。
如果尚未设置凭据,或计划将应用托管在 Streamlit Community Cloud 上,您需要通过 .streamlit/secrets.toml 文件指定凭据。
该文件应位于应用根目录或您的主目录下。
若文件不存在,请创建并添加之前记录的访问密钥 ID、访问密钥密钥以及 AWS 默认区域,如下所示:
# .streamlit/secrets.toml
AWS_ACCESS_KEY_ID = "xxx"
AWS_SECRET_ACCESS_KEY = "xxx"
AWS_DEFAULT_REGION = "xxx"
重要提示
请确保将上述 xxx 替换为你之前记录的值,并将此文件添加到 .gitignore 中,以免将其提交到你的 GitHub 仓库!
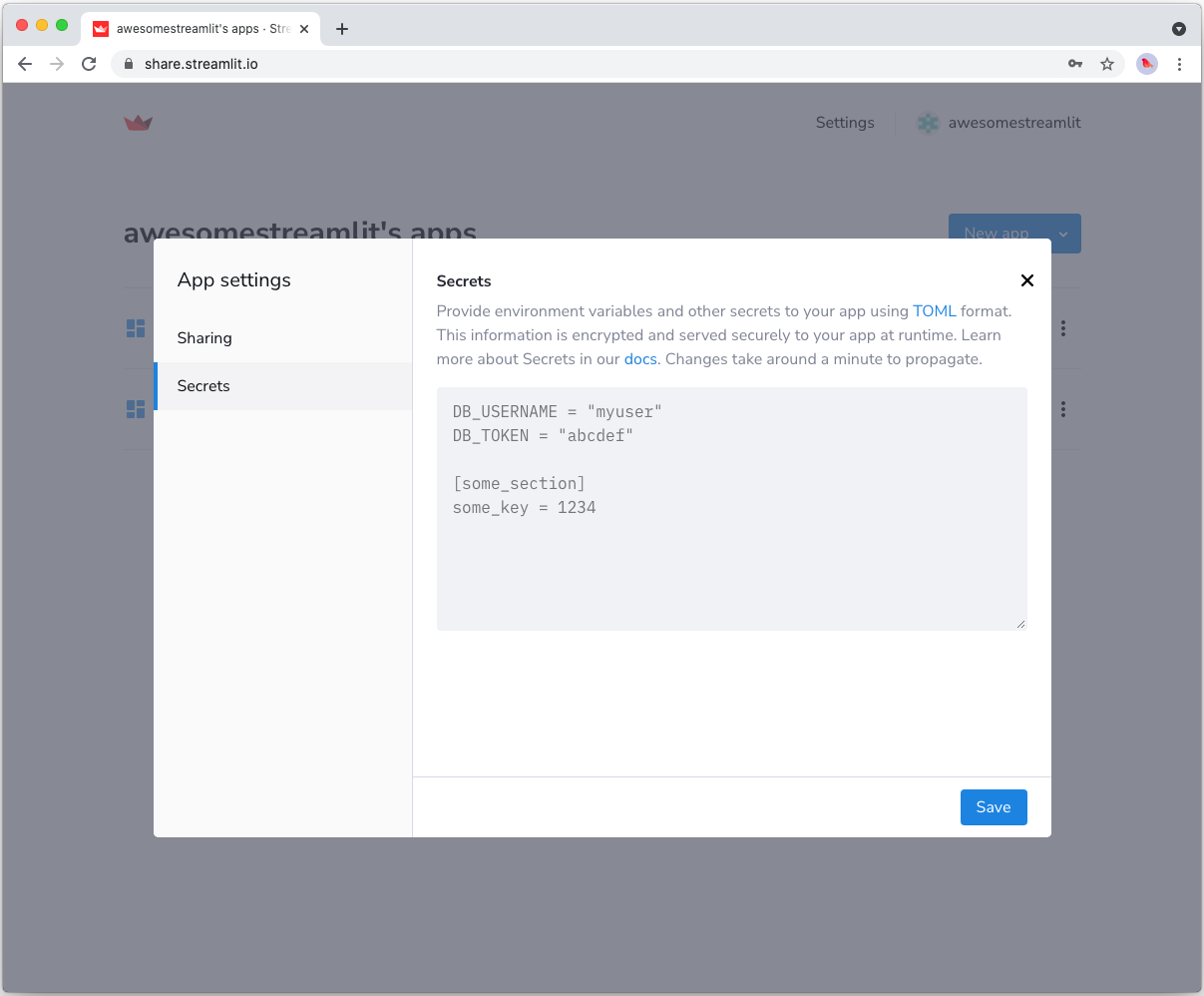
将应用密钥复制到云端
若要在 Streamlit Community Cloud 上托管您的应用,您需要通过密钥将凭据传递给已部署的应用。
请前往应用仪表板,在应用的下拉菜单中点击 Edit Secrets。
将上方 secrets.toml 文件的内容复制到文本区域。
更多信息请参阅密钥管理。
将 FilesConnection 和 s3fs 添加到你的依赖文件
请将 FilesConnection 和 s3fs 包添加到你的 requirements.txt 文件中,建议固定版本号(将 x.x.x 替换为你想要安装的版本):
# requirements.txt
s3fs==x.x.x
st-files-connection
编写你的 Streamlit 应用
将以下代码复制到你的 Streamlit 应用中并运行。
请确保根据实际情况调整存储桶名称和文件名。
需要注意的是,Streamlit 会自动将密钥文件中的访问密钥转换为环境变量,而 s3fs 默认会从这些环境变量中读取配置。
# streamlit_app.pyimport streamlit as st
from st_files_connection import FilesConnection# Create connection object and retrieve file contents.
# Specify input format is a csv and to cache the result for 600 seconds.
conn = st.connection('s3', type=FilesConnection)
df = conn.read("testbucket-jrieke/myfile.csv", input_format="csv", ttl=600)# Print results.
for row in df.itertuples():st.write(f"{row.Owner} has a :{row.Pet}:")
看到上面的 st.connection 了吗?它负责处理密钥获取、初始化设置、结果缓存和重试机制。
默认情况下,read() 的结果会被永久缓存。
在这个例子中,我们设置了 ttl=600 来确保文件内容缓存不超过 10 分钟。
你也可以设置 ttl=0 来禁用缓存。
更多细节请参阅缓存机制。
如果一切顺利(并且你使用了上面提供的示例文件),你的应用应该会显示如下界面:

上一页:连接数据源
下一页:BigQuery
将 Streamlit 连接到 Google BigQuery
https://docs.streamlit.io/develop/tutorials/databases/bigquery
简介
本指南介绍如何从 Streamlit Community Cloud 安全访问 BigQuery 数据库。
我们将使用 google-cloud-bigquery 库和 Streamlit 的 Secrets 管理功能来实现这一目标。
创建 BigQuery 数据库
注意:
如果您已有现成的数据库可供使用,可以直接跳转到下一步。
本示例将使用BigQuery中的示例数据集(即shakespeare表)。
如需新建数据集,请遵循Google的快速入门指南。
启用 BigQuery API
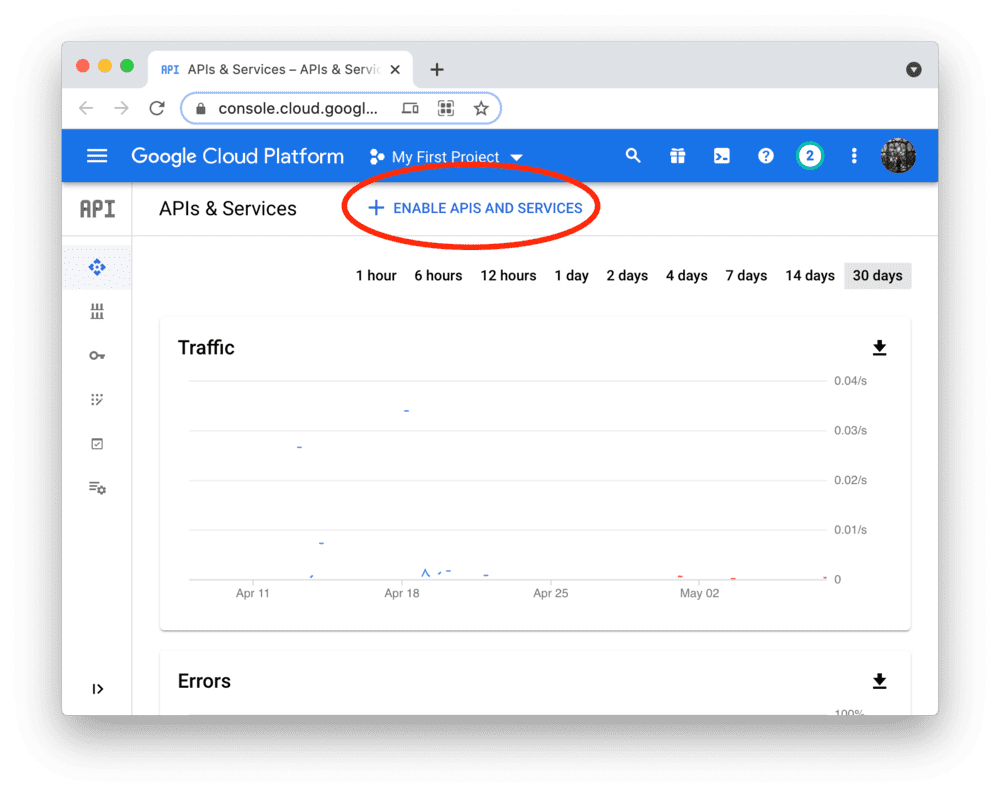
通过 Google Cloud Platform 可以控制对 BigQuery 的编程访问。
创建账户或登录后,前往 APIs & Services 仪表盘(如有提示,请选择或创建一个项目)。
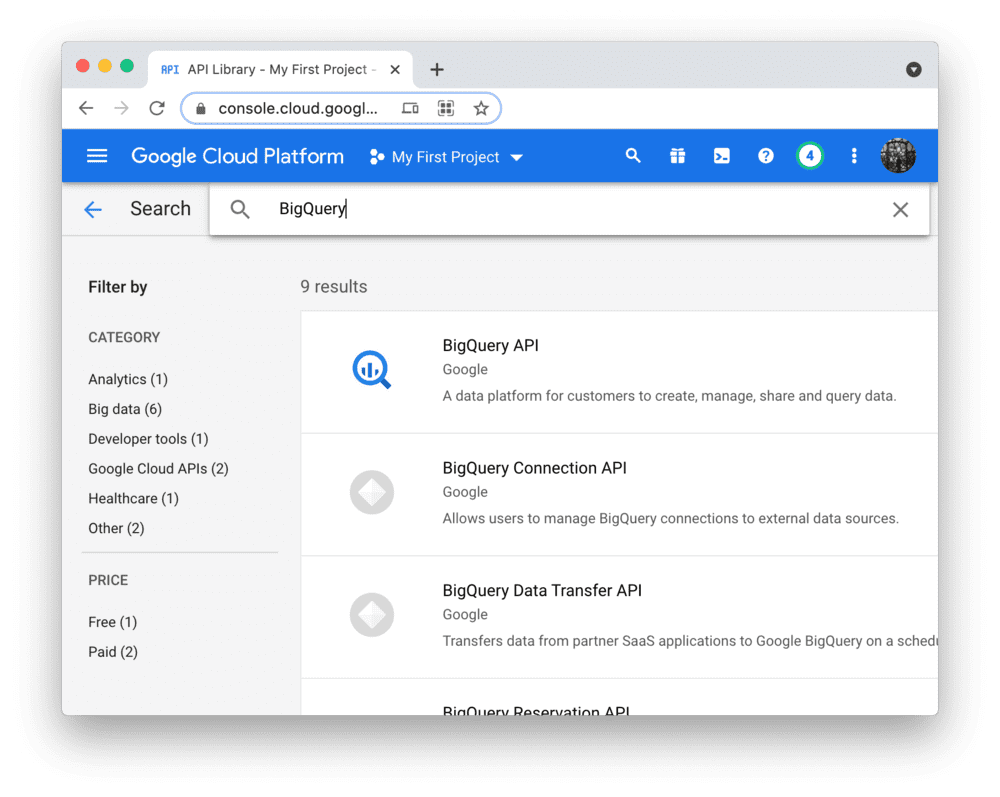
如下图所示,搜索 BigQuery API 并启用它:

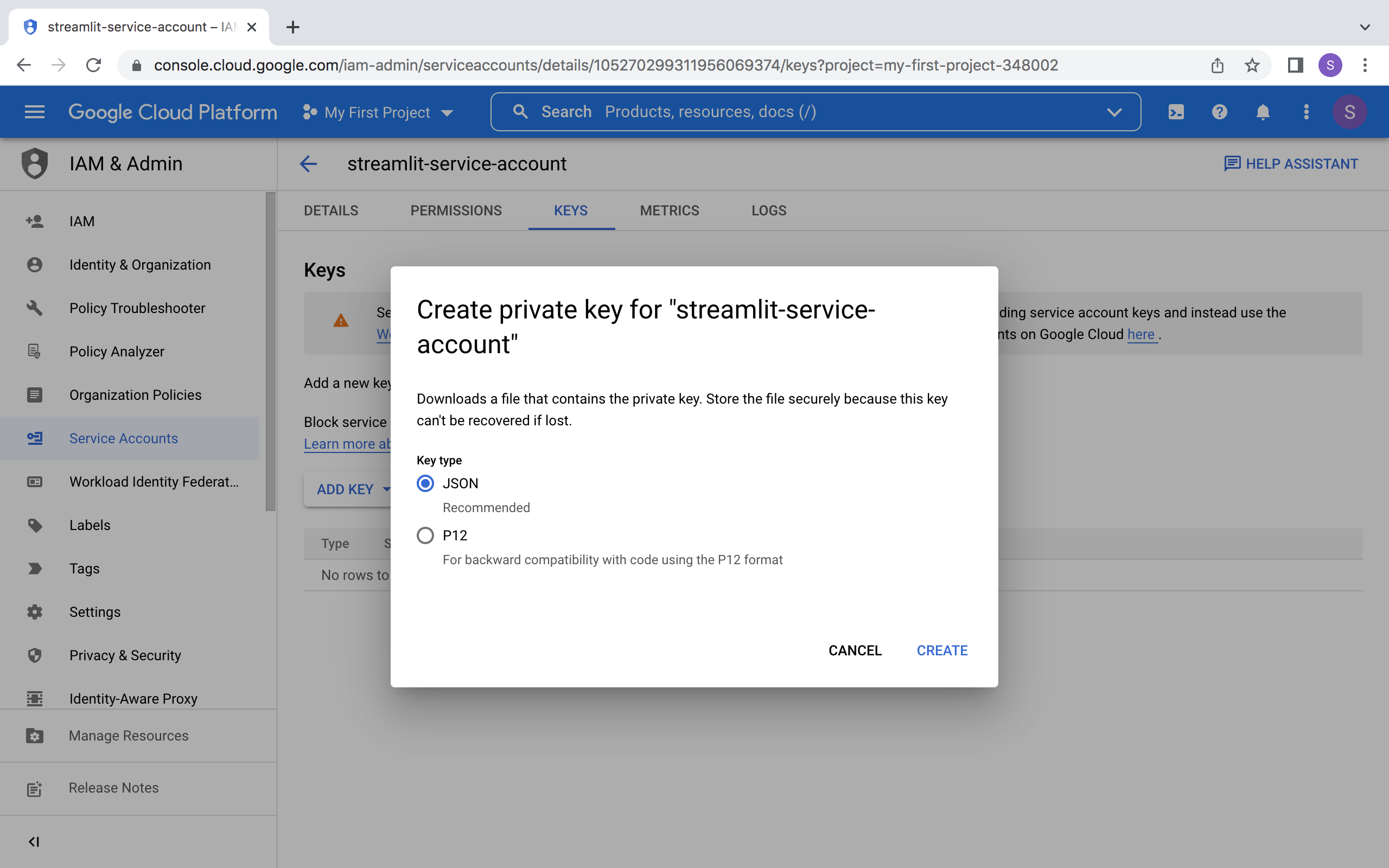
创建服务账号及密钥文件
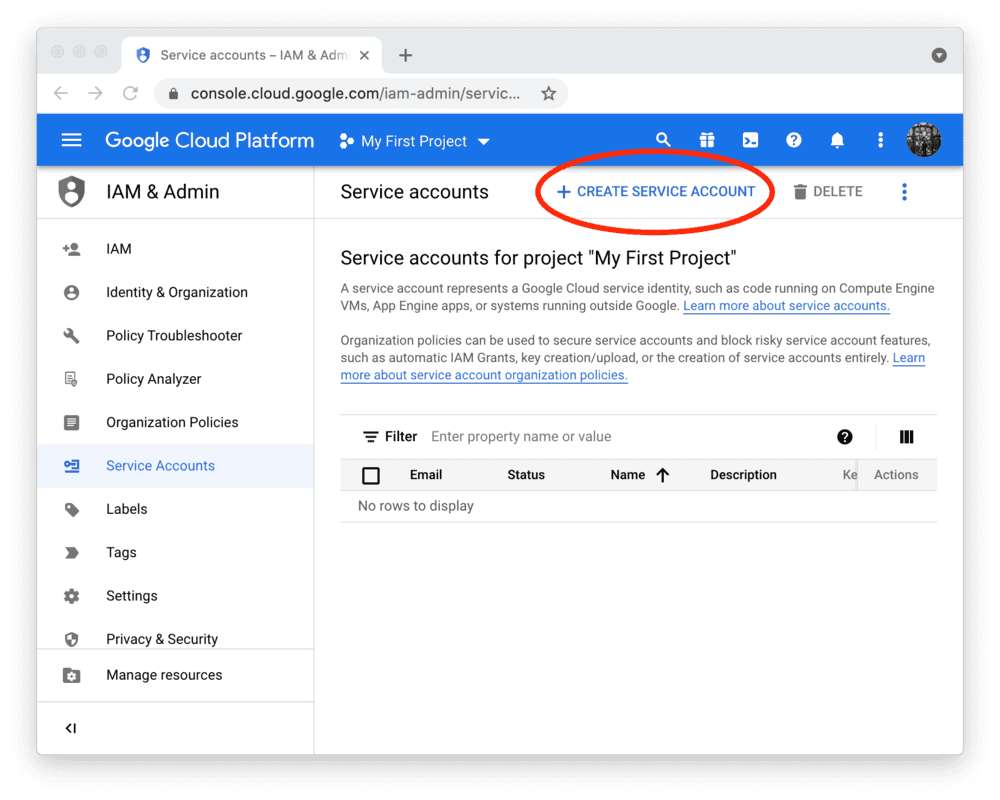
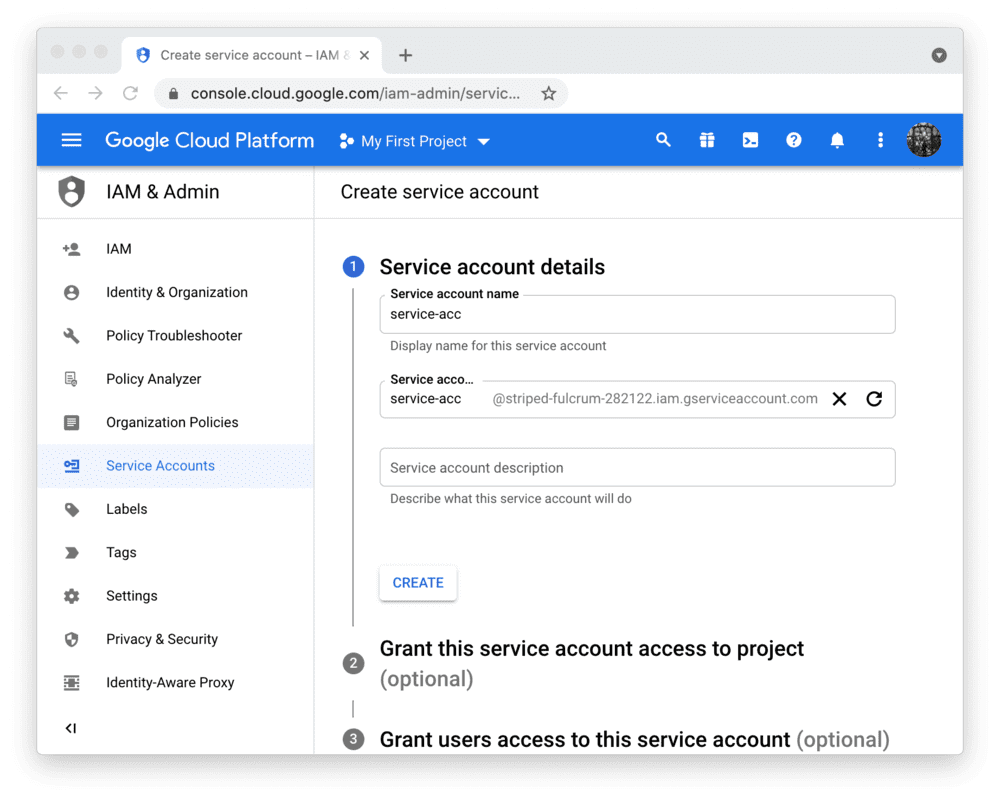
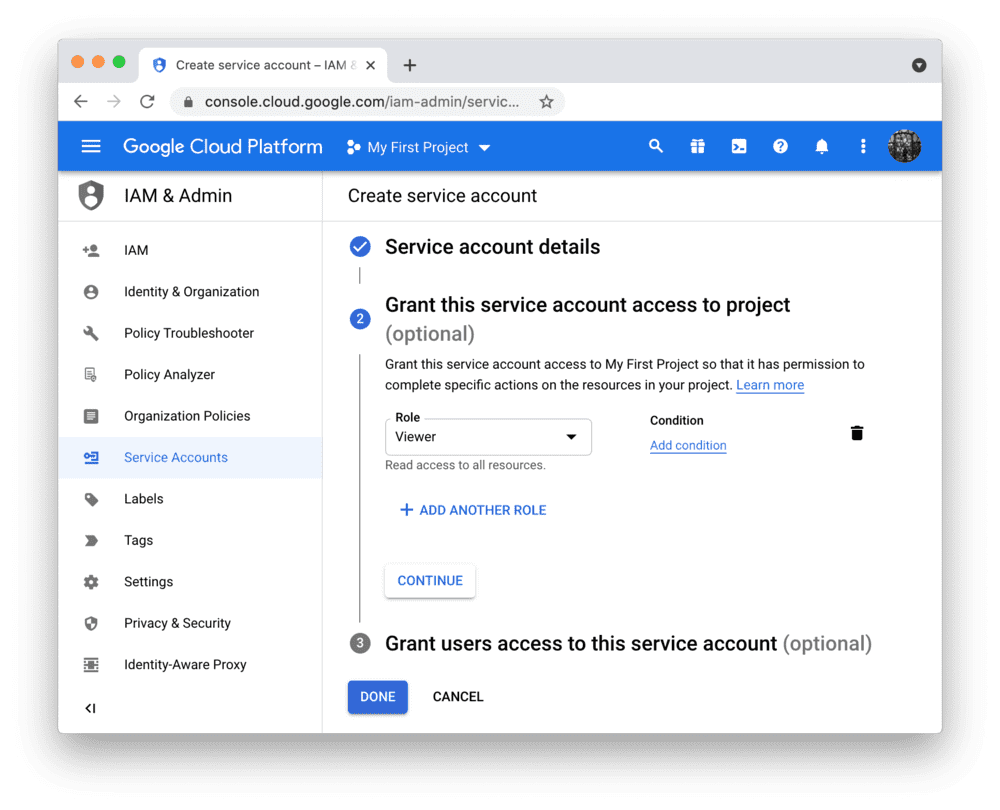
要在 Streamlit Community Cloud 中使用 BigQuery API,您需要一个 Google Cloud Platform 服务账号(一种专用于程序化数据访问的特殊账号类型)。
前往 服务账号 页面,创建一个具有 查看者 权限的账号(该权限允许账号访问数据但不可修改):
注意:
如果 CREATE SERVICE ACCOUNT 按钮显示为灰色,说明您没有正确的权限。
请向您的 Google Cloud 项目管理员寻求帮助。
点击 DONE 后,您将返回服务账户概览页面。
请为新账户创建 JSON 密钥文件并下载:
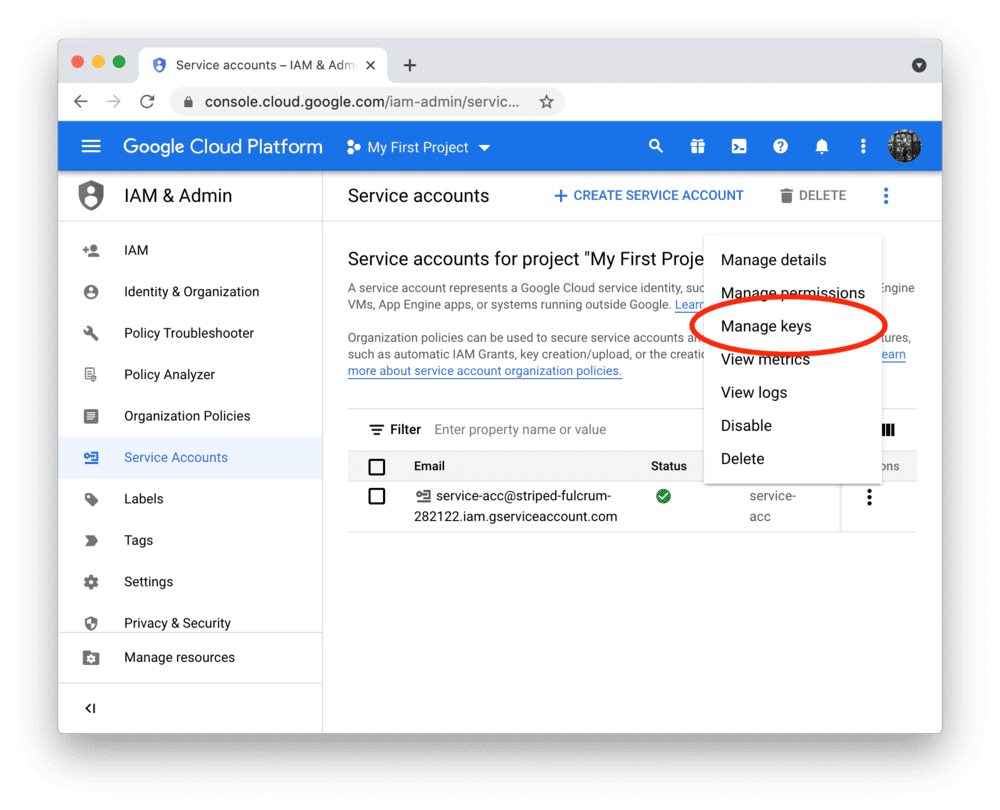
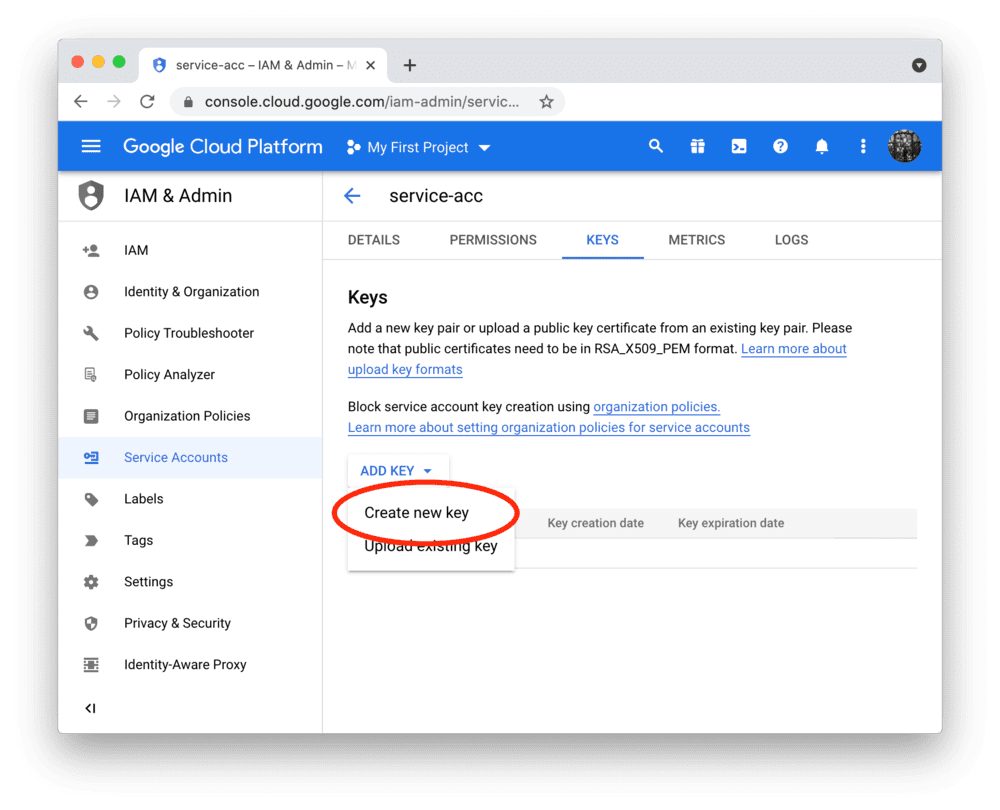
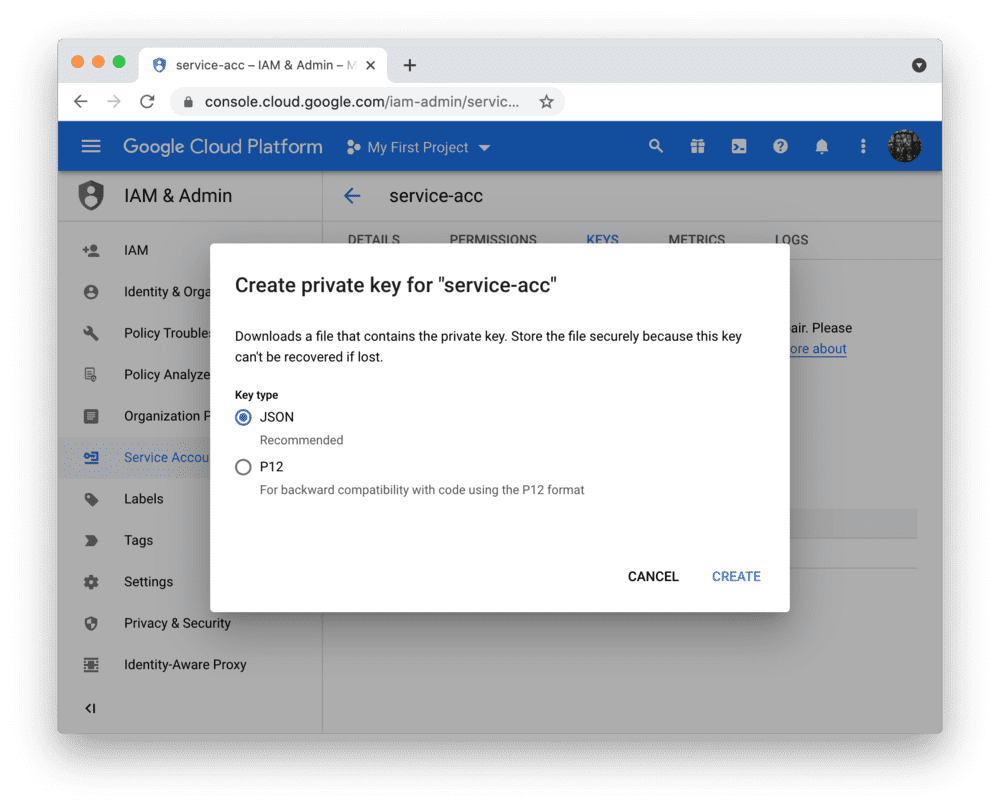
将密钥文件添加到本地应用配置中
你的本地 Streamlit 应用会从项目根目录下的 .streamlit/secrets.toml 文件中读取配置信息。
如果该文件不存在,请先创建它,然后将刚才下载的密钥文件内容按照以下方式添加进去:
# .streamlit/secrets.toml[gcp_service_account]
type = "service_account"
project_id = "xxx"
private_key_id = "xxx"
private_key = "xxx"
client_email = "xxx"
client_id = "xxx"
auth_uri = "https://accounts.google.com/o/oauth2/auth"
token_uri = "https://oauth2.googleapis.com/token"
auth_provider_x509_cert_url = "https://www.googleapis.com/oauth2/v1/certs"
client_x509_cert_url = "xxx"
重要提示
将此文件添加到 .gitignore 中,不要将其提交到你的 GitHub 仓库!
将应用密钥同步至云端
由于上述 secrets.toml 文件未提交至 GitHub,您需要单独将其内容传递至已部署的应用(在 Streamlit Community Cloud 上)。
请前往应用仪表板,在应用下拉菜单中点击 Edit Secrets,将 secrets.toml 的内容复制到文本区域。
更多信息请参阅密钥管理。
将 google-cloud-bigquery 添加到你的依赖文件
将 google-cloud-bigquery 包添加到你的 requirements.txt 文件中,建议固定其版本(将 x.x.x 替换为你想要安装的版本):
# requirements.txt
google-cloud-bigquery==x.x.x
编写你的 Streamlit 应用
将以下代码复制到你的 Streamlit 应用中并运行。
如果未使用示例表,请确保调整查询语句。
# streamlit_app.pyimport streamlit as st
from google.oauth2 import service_account
from google.cloud import bigquery# Create API client.
credentials = service_account.Credentials.from_service_account_info(st.secrets["gcp_service_account"]
)
client = bigquery.Client(credentials=credentials)# Perform query.
# Uses st.cache_data to only rerun when the query changes or after 10 min.
@st.cache_data(ttl=600)
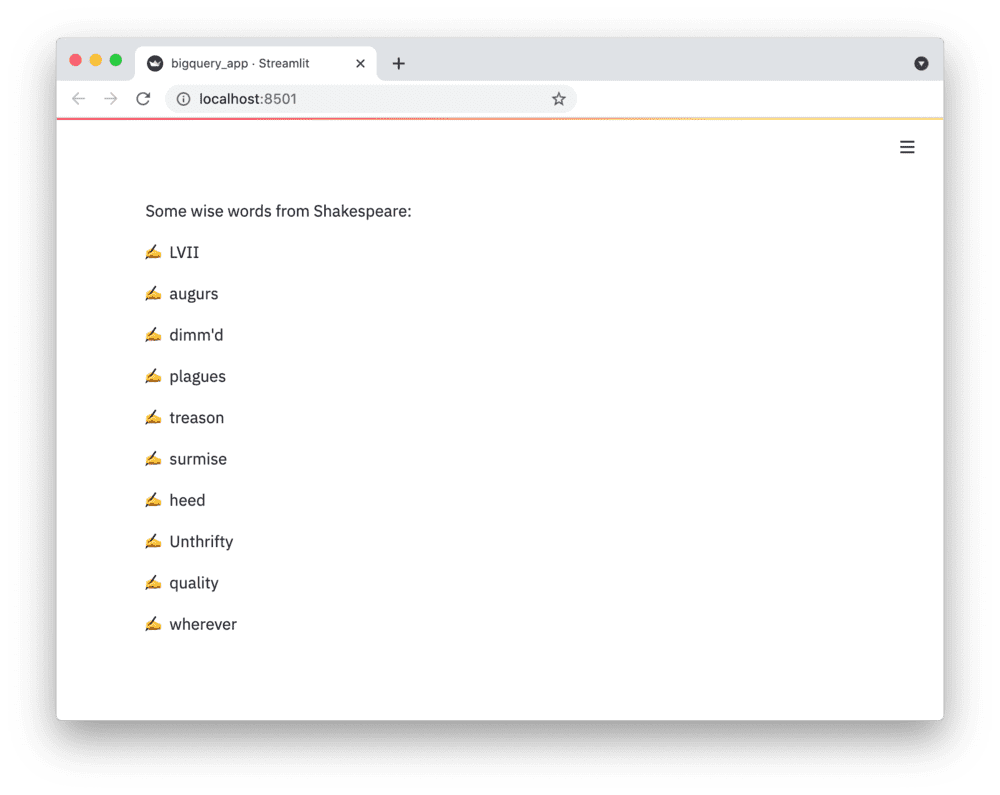
def run_query(query):query_job = client.query(query)rows_raw = query_job.result()# Convert to list of dicts. Required for st.cache_data to hash the return value.rows = [dict(row) for row in rows_raw]return rowsrows = run_query("SELECT word FROM `bigquery-public-data.samples.shakespeare` LIMIT 10")# Print results.
st.write("Some wise words from Shakespeare:")
for row in rows:st.write("✍️ " + row['word'])
看到上面的st.cache_data了吗?没有它的话,每当应用重新运行时(比如组件交互时),Streamlit都会重新执行查询。
而使用st.cache_data后,查询只会在内容变更或10分钟后才会重新执行(这就是ttl参数的作用)。
注意:如果数据库更新更频繁,你应该调整ttl或禁用缓存,确保用户始终看到最新数据。
了解更多请参阅缓存机制。
另一种方式是直接用pandas从BigQuery读取数据到DataFrame!按照上述所有步骤,安装pandas-gbq库(别忘了加入requirements.txt!),然后调用pandas.read_gbq(query, credentials=credentials)。
更多细节见pandas文档。
如果一切正常(且使用了示例表),你的应用应该会显示如下效果:
上一章:AWS S3
下一章:Firestore
将Streamlit连接到Google云存储
https://docs.streamlit.io/develop/tutorials/databases/gcs
简介
本指南介绍如何从 Streamlit Community Cloud 安全访问 Google Cloud Storage 中的文件。
它使用了 Streamlit FilesConnection、gcsfs 库以及 Streamlit 的 Secrets 管理功能。
创建Google Cloud Storage存储桶并添加文件
注意:
如果您已有想要使用的存储桶,可以直接跳至下一步。
首先,请注册Google Cloud Platform或登录。
前往Google Cloud Storage控制台并创建一个新存储桶。
进入新存储桶的上传区域:
上传以下包含示例数据的CSV文件:myfile.csv
启用 Google Cloud Storage API
通过 Google Cloud 控制台或 CLI 创建项目时,Google Cloud Storage API 默认已启用。
你可以直接跳转到下一步。
如果确实需要为项目中的程序化访问启用该 API,请前往 APIs 和服务仪表盘(根据提示选择或创建项目)。
搜索 Cloud Storage API 并启用它。
下面的截图显示了一个蓝色的"管理"按钮,并标注"API 已启用",这意味着无需进一步操作。
由于 API 默认启用,你的界面很可能也是如此。
但如果你看到的是"启用"按钮,则需要手动启用该 API:
创建服务账号及密钥文件
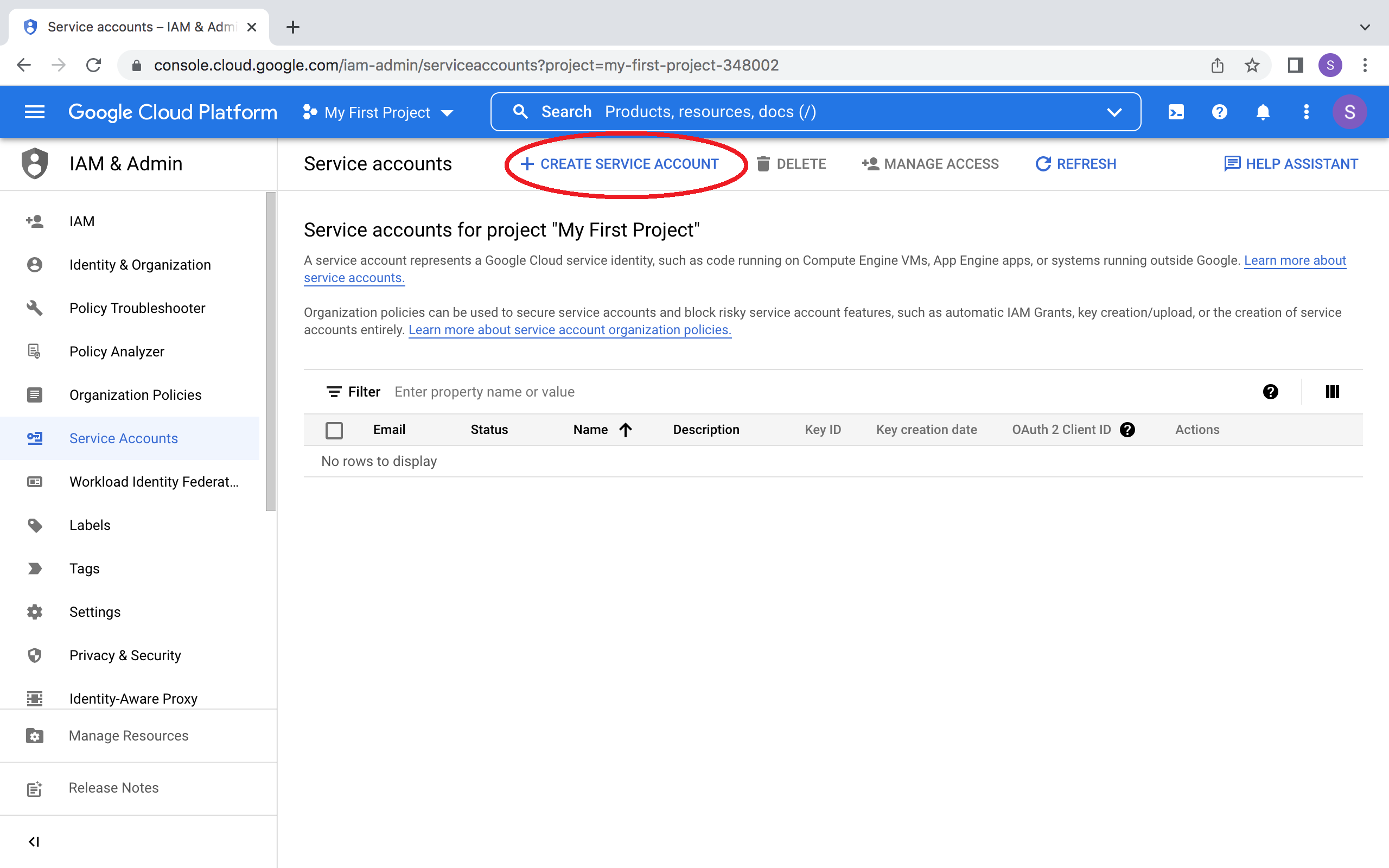
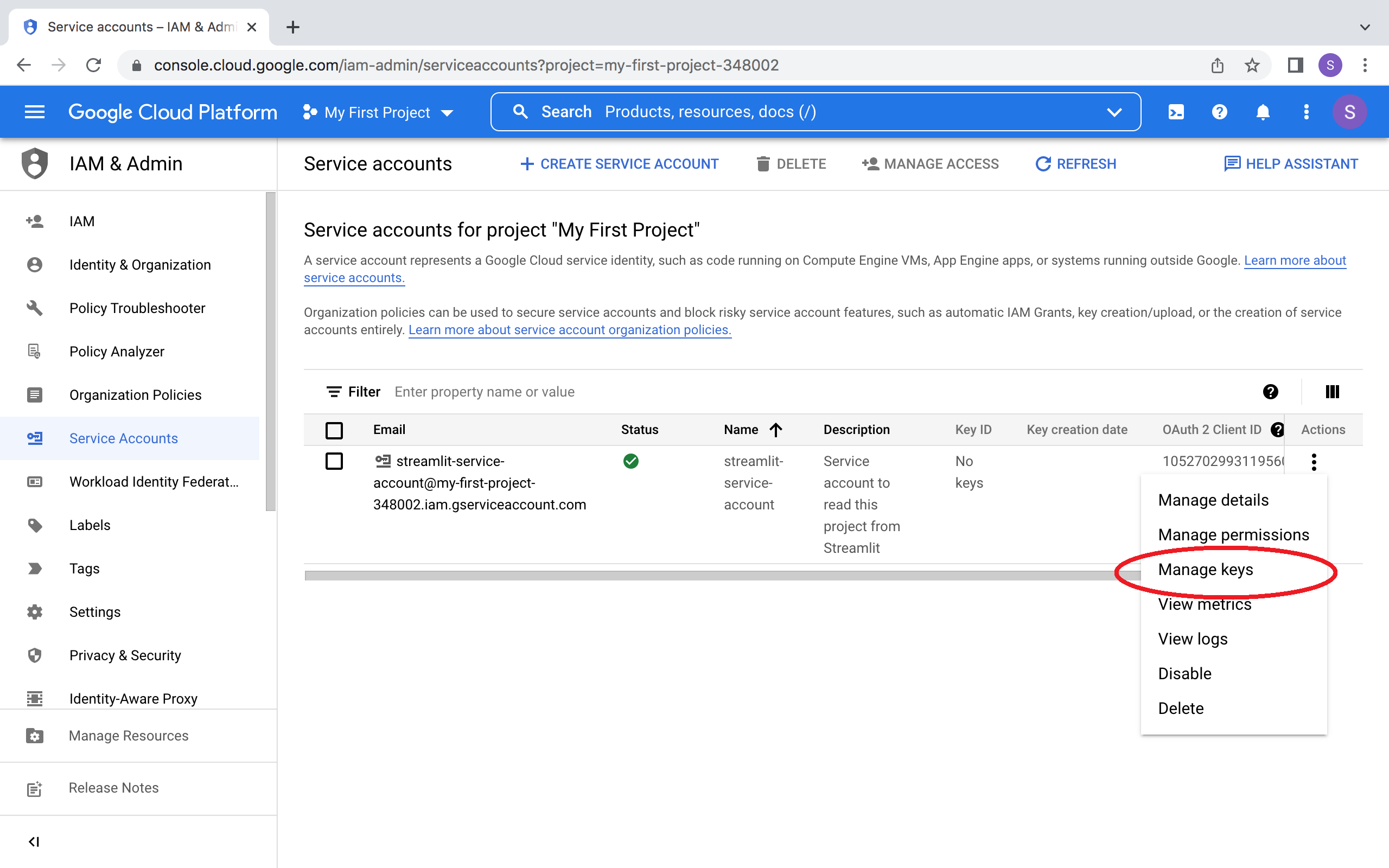
要在 Streamlit 中使用 Google Cloud Storage API,你需要一个 Google Cloud Platform 服务账号(专用于程序化数据访问的特殊类型)。
前往服务账号页面,创建一个具有 查看者 权限的账号。
注意:
如果 CREATE SERVICE ACCOUNT 按钮显示为灰色,说明您没有相应权限。
请联系您的 Google Cloud 项目管理员寻求帮助。
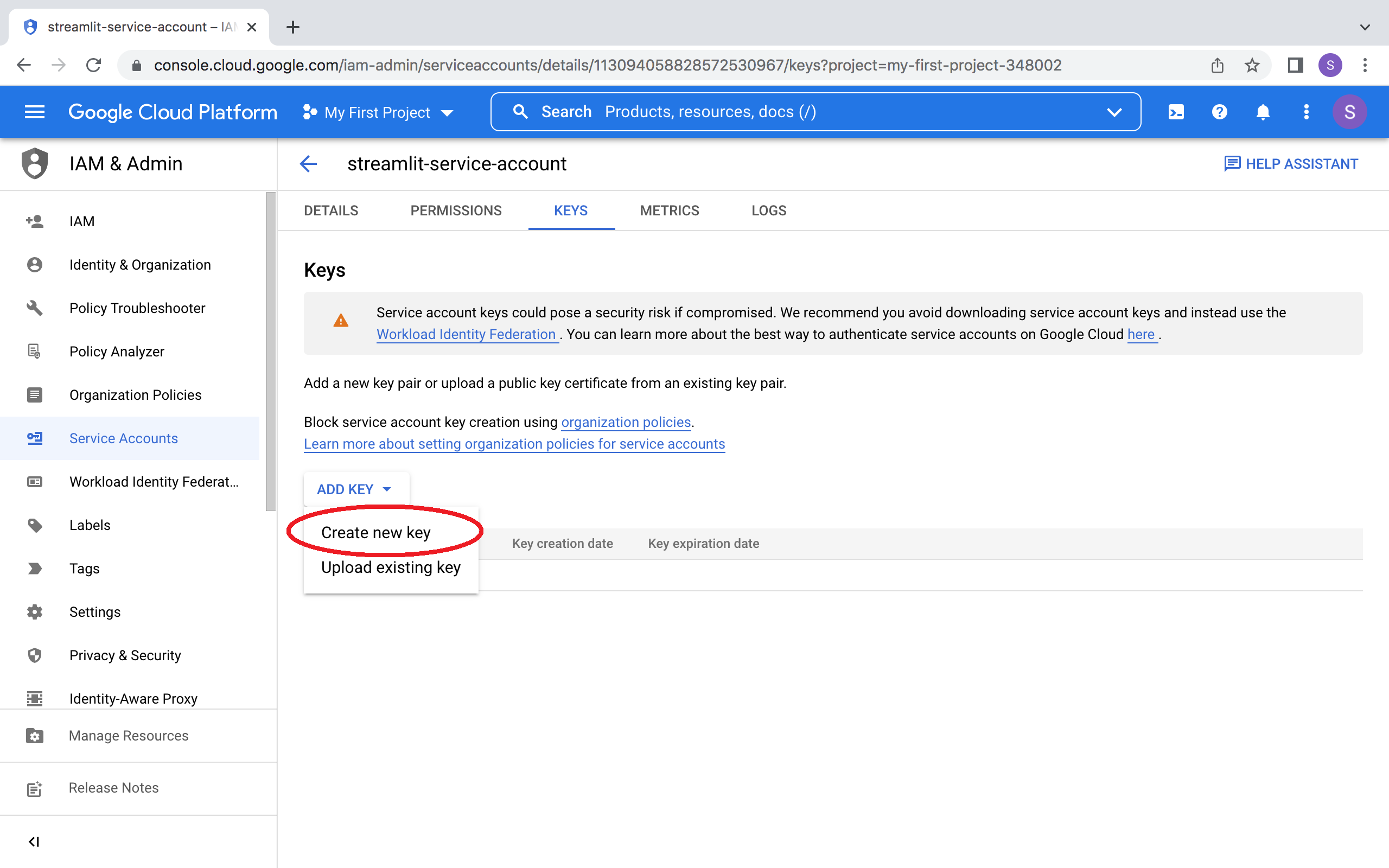
点击 DONE 后,您将返回服务账号概览页面。
请为新账号创建 JSON 密钥文件并下载:
将密钥添加到本地应用机密配置中
您的本地 Streamlit 应用会从项目根目录下的 .streamlit/secrets.toml 文件中读取机密配置。
如果该文件不存在,请创建它并按以下方式添加访问密钥:
# .streamlit/secrets.toml[connections.gcs]
type = "service_account"
project_id = "xxx"
private_key_id = "xxx"
private_key = "xxx"
client_email = "xxx"
client_id = "xxx"
auth_uri = "https://accounts.google.com/o/oauth2/auth"
token_uri = "https://oauth2.googleapis.com/token"
auth_provider_x509_cert_url = "https://www.googleapis.com/oauth2/v1/certs"
client_x509_cert_url = "xxx"
重要提示
将此文件添加到 .gitignore 中,不要将其提交到你的 GitHub 仓库!
将应用密钥同步至云端
由于上述 secrets.toml 文件未提交至 GitHub,您需要单独将其内容传递至已部署的应用(在 Streamlit Community Cloud 上)。
请前往应用仪表盘,在应用下拉菜单中选择 Edit Secrets,然后将 secrets.toml 的内容复制到文本区域。
更多信息请参阅密钥管理。
将 FilesConnection 和 gcsfs 添加到你的 requirements 文件
将 FilesConnection 和 gcsfs 包添加到你的 requirements.txt 文件中,建议固定版本号(将 x.x.x 替换为你想要安装的版本):
# requirements.txt
gcsfs==x.x.x
st-files-connection
编写你的 Streamlit 应用
将以下代码复制到你的 Streamlit 应用中并运行。
请确保根据实际情况修改存储桶名称和文件名。
注意:Streamlit 会自动将 secrets 文件中的访问密钥转换为环境变量。
# streamlit_app.pyimport streamlit as st
from st_files_connection import FilesConnection# Create connection object and retrieve file contents.
# Specify input format is a csv and to cache the result for 600 seconds.
conn = st.connection('gcs', type=FilesConnection)
df = conn.read("streamlit-bucket/myfile.csv", input_format="csv", ttl=600)# Print results.
for row in df.itertuples():st.write(f"{row.Owner} has a :{row.Pet}:")
看到上面的 st.connection 了吗?它负责处理密钥获取、设置、结果缓存和重试。
默认情况下,read() 的结果会被永久缓存。
在这个例子中,我们设置 ttl=600 来确保文件内容缓存不超过 10 分钟。
你也可以设置 ttl=0 来禁用缓存。
了解更多请参阅缓存机制。
如果一切顺利(并且你使用了上面提供的示例文件),你的应用应该会显示如下效果:
上一篇:Firestore
下一篇:Microsoft SQL Server
将Streamlit连接到Microsoft SQL Server
https://docs.streamlit.io/develop/tutorials/databases/mssql
简介
本指南介绍如何从 Streamlit Community Cloud 安全访问远程 Microsoft SQL Server 数据库。
方案使用 pyodbc 库和 Streamlit 的密钥管理功能。
创建 SQL Server 数据库
注意:
如果您已经有一个想要使用的远程数据库,可以直接跳转到下一步。
首先,按照微软文档安装 SQL Server 和 sqlcmd 工具。
微软提供了详细的安装指南,包括:
- 在 Windows 上安装 SQL Server
- 在 Red Hat Enterprise Linux 上安装
- 在 SUSE Linux Enterprise Server 上安装
- 在 Ubuntu 上安装
- 在 Docker 中运行
- 在 Azure 中配置 SQL 虚拟机
安装完 SQL Server 后,请记录下安装过程中设置的 SQL Server 名称、用户名和密码。
本地连接
若需进行本地连接,请使用 sqlcmd 工具连接至新建的本地 SQL Server 实例。
- 在终端中运行以下命令:
sqlcmd -S localhost -U SA -P '<YourPassword>'
由于是本地连接,SQL Server 名称为 localhost,用户名为 SA,密码为 SA 账户设置时提供的密码。
2、如果连接成功,您应该会看到 sqlcmd 命令提示符 1>。
3、若遇到连接失败问题,请参考 Microsoft 针对您操作系统的连接故障排除建议(Linux 和 Windows)。
提示
远程连接时,SQL Server名称应为机器名或IP地址。
您可能还需要在防火墙上开放SQL Server的TCP端口(默认端口为1433)。
创建 SQL Server 数据库
现在,你已经运行了 SQL Server 并通过 sqlcmd 连接到它!🥳 让我们通过创建一个包含示例数据表的数据库来实际使用它。
- 在
sqlcmd命令提示符下,执行以下 Transact-SQL 命令来创建测试数据库mydb:
CREATE DATABASE mydb`2、To execute the above command, type `GO` on a new line:`GO`
***
### Insert some dataNext create a new table, `mytable`, in the `mydb` database with three columns and two rows.1、Switch to the new `mydb` database:`USE mydb`2、Create a new table with the following schema:```sql
CREATE TABLE mytable (name varchar(80), pet varchar(80))
3、Insert some data into the table:
INSERT INTO mytable VALUES ('Mary', 'dog'), ('John', 'cat'), ('Robert', 'bird')
4、Type GO to execute the above commands:
GO
To end your sqlcmd session, type QUIT on a new line.
Add username and password to your local app secrets
Your local Streamlit app will read secrets from a file .streamlit/secrets.toml in your app’s root directory. Create this file if it doesn’t exist yet and add the SQL Server name, database name, username, and password as shown below:
# .streamlit/secrets.tomlserver = "localhost"
database = "mydb"
username = "SA"
password = "xxx" (注:根据核心翻译原则第1条,代码块内容保持原样未翻译)Important
When copying your app secrets to Streamlit Community Cloud, be sure to replace the values of server, database, username, and password with those of your remote SQL Server!
And add this file to .gitignore and don’t commit it to your GitHub repo.
Copy your app secrets to Streamlit Community Cloud
As the secrets.toml file above is not committed to GitHub, you need to pass its content to your deployed app (on Streamlit Community Cloud) separately. Go to the app dashboard and in the app’s dropdown menu, click on Edit Secrets. Copy the content of secrets.toml into the text area. More information is available at Secrets management.
Add pyodbc to your requirements file
To connect to SQL Server locally with Streamlit, you need to pip install pyodbc, in addition to the Microsoft ODBC driver you installed during the SQL Server installation.
On Streamlit Cloud, we have built-in support for SQL Server. On popular demand, we directly added SQL Server tools including the ODBC drivers and the executables sqlcmd and bcp to the container image for Cloud apps, so you don’t need to install them.
All you need to do is add the pyodbc Python package to your requirements.txt file, and you’re ready to go! 🎈
# requirements.txt
pyodbc==x.x.x
Replace x.x.x ☝️ with the version of pyodbc you want installed on Cloud.
Note :
At this time, Streamlit Community Cloud does not support Azure Active Directory authentication. We will update this tutorial when we add support for Azure Active Directory.
Write your Streamlit app
Copy the code below to your Streamlit app and run it. Make sure to adapt query to use the name of your table.
***
```python
import streamlit as stimport pyodbc
初始化连接
使用 st.cache_resource 确保只运行一次
@st.cache_resource
def init_connection():
return pyodbc.connect(
“DRIVER={ODBC Driver 17 for SQL Server};SERVER=”
- st.secrets[“server”]
- “;DATABASE=”
- st.secrets[“database”]
- “;UID=”
- st.secrets[“username”]
- “;PWD=”
- st.secrets[“password”]
)
conn = init_connection()
执行查询
使用 st.cache_data 仅在查询变更或10分钟后重新运行
@st.cache_data(ttl=600)
def run_query(query):
with conn.cursor() as cur:
cur.execute(query)
return cur.fetchall()
rows = run_query(“SELECT * from mytable;”)
打印结果
for row in rows:
st.write(f"{row[0]} has a :{row[1]}😊
看到上面的st.cache_data了吗?如果没有它,每次应用重新运行时(例如在小部件交互时),Streamlit都会重新执行查询。
而使用st.cache_data后,查询只会在数据变更或10分钟缓存到期后执行(这正是ttl参数的作用)。
注意:如果数据库更新更频繁,你应该调整ttl或禁用缓存,以确保用户始终看到最新数据。
了解更多请参阅缓存机制。
如果一切正常(并且使用了我们之前创建的示例表),你的应用应该如下图所示:
上一页:Google Cloud Storage
下一页:MongoDB
连接 Streamlit 到 MongoDB
https://docs.streamlit.io/develop/tutorials/databases/mongodb
简介
本指南介绍如何从 Streamlit Community Cloud 安全访问远程 MongoDB 数据库。
它使用了 PyMongo 库和 Streamlit 的 Secrets 管理功能。
创建 MongoDB 数据库
注意:
如果您已有现成的数据库可供使用,请直接跳转至下一步。
首先,请按照官方教程完成MongoDB安装、设置认证(请记录用户名和密码!)以及连接MongoDB实例。
连接成功后,打开mongo shell并执行以下两条命令来创建包含示例值的集合:
use mydb
db.mycollection.insertMany([{"name" : "Mary", "pet": "dog"}, {"name" : "John", "pet": "cat"}, {"name" : "Robert", "pet": "bird"}])
将用户名和密码添加到本地应用密钥中
你的本地 Streamlit 应用会从项目根目录下的 .streamlit/secrets.toml 文件中读取密钥。
如果该文件不存在,请创建它并按照以下方式添加数据库信息:
# .streamlit/secrets.toml[mongo]
host = "localhost"
port = 27017
username = "xxx"
password = "xxx"
重要提示
将应用密钥复制到 Streamlit Community Cloud 时,请务必用远程 MongoDB 数据库的对应值替换 host、port、username 和 password 字段!
请将此文件添加到 .gitignore 中,不要将其提交到 GitHub 仓库!
将应用密钥复制到云端
由于上述 secrets.toml 文件未提交至 GitHub,您需要将其内容单独传递至已部署的应用(在 Streamlit Community Cloud 上)。
请前往应用仪表盘,在应用的下拉菜单中点击 Edit Secrets。
将 secrets.toml 的内容复制到文本区域。
更多信息请参阅密钥管理。
将 PyMongo 添加到依赖文件
请将 PyMongo 包添加至你的 requirements.txt 文件中,建议锁定其版本(将 x.x.x 替换为你需要安装的具体版本号):
# requirements.txt
pymongo==x.x.x
编写你的 Streamlit 应用
将以下代码复制到你的 Streamlit 应用中并运行。
请确保根据实际情况修改数据库和集合的名称。
# streamlit_app.pyimport streamlit as st
import pymongo# Initialize connection.
# Uses st.cache_resource to only run once.
@st.cache_resource
def init_connection():return pymongo.MongoClient(**st.secrets["mongo"])client = init_connection()# Pull data from the collection.
# Uses st.cache_data to only rerun when the query changes or after 10 min.
@st.cache_data(ttl=600)
def get_data():db = client.mydbitems = db.mycollection.find()items = list(items) # make hashable for st.cache_datareturn itemsitems = get_data()# Print results.
for item in items:st.write(f"{item['name']} has a :{item['pet']}:")
看到上面的st.cache_data了吗?如果没有它,Streamlit 会在每次应用重新运行时(例如在小部件交互时)执行查询。
而使用st.cache_data后,查询只会在查询内容变化或10分钟后才会重新执行(这就是ttl的作用)。
注意:如果你的数据库更新更频繁,应该调整ttl或移除缓存,以确保查看者始终看到最新数据。
了解更多请参阅缓存机制。
如果一切正常(并且使用了我们之前创建的示例数据),你的应用应该如下图所示:
上一页:Microsoft SQL Server
下一页:MySQL
MySQL数据库教程
连接 Streamlit 到 MySQL
简介
本指南介绍如何从Streamlit Community Cloud安全访问远程MySQL数据库。
它使用了st.connection和Streamlit的Secrets管理功能。
请注意,以下示例代码仅适用于Streamlit 1.28及以上版本,因为st.connection是在该版本中添加的。
创建 MySQL 数据库
注意:
如果您已有现成的数据库可供使用,可以直接跳转到下一步。
首先,请按照本教程安装MySQL并启动MySQL服务器(请记录用户名和密码!)。
当MySQL服务器正常运行后,使用mysql客户端连接服务器,并执行以下命令来创建数据库及包含示例数据的表:
CREATE DATABASE pets;USE pets;CREATE TABLE mytable (name varchar(80),pet varchar(80)
);INSERT INTO mytable VALUES ('Mary', 'dog'), ('John', 'cat'), ('Robert', 'bird');
为本地应用添加用户名和密码到机密配置
您的本地 Streamlit 应用会从项目根目录下的 .streamlit/secrets.toml 文件中读取机密配置。
了解更多关于 Streamlit 机密管理的信息。
如果该文件不存在,请创建它,并按照以下示例添加您的 MySQL 服务器数据库名称、用户名和密码:
# .streamlit/secrets.toml[connections.mysql]
dialect = "mysql"
host = "localhost"
port = 3306
database = "xxx"
username = "xxx"
password = "xxx"
query = { charset = "xxx" }
如果你在定义连接时使用了 query,则必须使用 streamlit>=1.35.0。
重要提示
将应用密钥复制到 Streamlit Community Cloud 时,请务必用远程 MySQL 数据库的对应值替换 host、port、database、username 和 password 的值!
请将此文件添加到 .gitignore 中,不要将其提交到 GitHub 仓库!
将应用密钥同步至云端
由于上述 secrets.toml 文件未提交至 GitHub,您需要将其内容单独传递至已部署的应用(在 Streamlit Community Cloud 上)。
请前往应用仪表盘,在应用下拉菜单中点击 Edit Secrets,然后将 secrets.toml 的内容复制到文本区域。
更多信息请参阅密钥管理。
将依赖项添加到 requirements 文件
请将 mysqlclient 和 SQLAlchemy 包添加到你的 requirements.txt 文件中,建议固定版本号(将 x.x.x 替换为你需要安装的具体版本):
# requirements.txt
mysqlclient==x.x.x
SQLAlchemy==x.x.x
编写你的 Streamlit 应用
将以下代码复制到你的 Streamlit 应用中并运行。
请确保调整 query 以使用你的表名。
# streamlit_app.pyimport streamlit as st# Initialize connection.
conn = st.connection('mysql', type='sql')# Perform query.
df = conn.query('SELECT * from mytable;', ttl=600)# Print results.
for row in df.itertuples():st.write(f"{row.name} has a :{row.pet}:")
注意到上面的 st.connection 了吗?它负责处理密钥获取、初始化设置、查询缓存和重试机制。
默认情况下,query() 的返回结果会被永久缓存。
在这个例子中,我们设置了 ttl=600 来确保查询结果最多缓存10分钟。
你也可以通过设置 ttl=0 来完全禁用缓存功能。
更多细节请参阅 缓存机制。
如果一切运行正常(并且使用了我们之前创建的示例表),你的应用界面应该如下图所示:
上一章:MongoDB
下一章:Neon
将 Streamlit 连接到 Neon
https://docs.streamlit.io/develop/tutorials/databases/neon
简介
本指南介绍如何从 Streamlit 安全地访问 Neon 数据库。
Neon 是一个完全托管的无服务器 PostgreSQL 数据库,它通过分离存储和计算来提供即时分支和自动扩展等功能。
前提条件
- 您的 Python 环境中必须安装以下软件包:
streamlit>=1.28
psycopg2-binary>=2.9.6
sqlalchemy>=2.0.0
注意:
你可以使用 psycopg2 替代 psycopg2-binary。
不过,构建 Psycopg 需要一些先决条件(例如 C 编译器)。
若要在 Community Cloud 上使用 psycopg2,你必须在仓库根目录的 packages.txt 文件中包含 libpq-dev。
psycopg2-binary 是一个独立的包,适合用于测试和开发。
- 你必须拥有 Neon 账户。
- 你应该对
st.connection和 Secrets management 有基本了解。
创建 Neon 项目
如果您已有可用的 Neon 项目,可以直接跳转至下一步。
- 登录 Neon 控制台并进入 Projects 页面
- 若界面显示项目名称输入提示,请跳过此步骤。
否则点击 “New Project” 按钮创建新项目 - 输入项目名称 “Streamlit-Neon”,保持其他默认设置,点击 “Create Project”
当 Neon 完成项目创建并生成可立即使用的 neondb 数据库后,系统会自动跳转至项目快速入门页面
4. 从左侧边栏点击 “SQL Editor”
5. 将输入框内的文本替换为以下代码,点击 “Run” 按钮为项目添加示例数据
CREATE TABLE home (id SERIAL PRIMARY KEY,name VARCHAR(100),pet VARCHAR(100)
);INSERT INTO home (name, pet)
VALUES('Mary', 'dog'),('John', 'cat'),('Robert', 'bird');
将 Neon 连接字符串添加到本地应用密钥中
1、在 Neon 项目中,点击左侧边栏的 “Dashboard”。
2、在 “Connection Details” 卡片中,找到数据库连接字符串。
它应该类似于以下格式:
postgresql://neondb_owner:xxxxxxxxxxxx@ep-adjective-noun-xxxxxxxx.us-east-2.aws.neon.tech/neondb?sslmode=require
3、如果应用根目录下还没有 .streamlit/secrets.toml 文件,请创建一个空白的密钥文件。
4、复制连接字符串,并按以下方式将其添加到应用的 .streamlit/secrets.toml 文件中:
# .streamlit/secrets.toml[connections.neon]
url="postgresql://neondb_owner:xxxxxxxxxxxx@ep-adjective-noun-xxxxxxxx.us-east-2.aws.neon.tech/neondb?sslmode=require"
重要提示
将此文件添加到 .gitignore 中,不要提交到你的 GitHub 仓库!
编写你的 Streamlit 应用
1、将以下代码复制到你的 Streamlit 应用中并保存。
# streamlit_app.pyimport streamlit as st# Initialize connection.
conn = st.connection("neon", type="sql")# Perform query.
df = conn.query('SELECT * FROM home;', ttl="10m")# Print results.
for row in df.itertuples():st.write(f"{row.name} has a :{row.pet}:")
上述 st.connection 对象负责处理密钥获取、连接设置、查询缓存及重试机制。
默认情况下,query() 的查询结果会被永久缓存。
将 ttl 参数设为 "10m" 可确保查询结果最多缓存 10 分钟。
您也可以设置 ttl=0 来完全禁用缓存功能。
更多细节请参阅 缓存机制。
2、运行您的 Streamlit 应用。
streamlit run streamlit_app.py
如果一切顺利(并且你使用了我们之前创建的示例表格),你的应用应该会呈现如下效果:
从Community Cloud连接Neon数据库
本教程假设使用的是本地Streamlit应用,但你也可以从托管在Community Cloud上的应用连接Neon数据库。
额外步骤如下:
- 在代码仓库中添加
requirements.txt文件。
需包含前提条件中列出的所有包及其他依赖项。 - 在Community Cloud中为你的应用添加密钥。
上一篇:MySQL
下一篇:PostgreSQL
将Streamlit连接到PostgreSQL
https://docs.streamlit.io/develop/tutorials/databases/postgresql
简介
本指南介绍如何从 Streamlit Community Cloud 安全访问远程 PostgreSQL 数据库。
它使用了 st.connection 和 Streamlit 的 Secrets 管理功能。
请注意,以下示例代码仅适用于 Streamlit 1.28 及以上版本,因为 st.connection 是在该版本中引入的。
创建 PostgreSQL 数据库
注意:
如果您已有现成的数据库可供使用,请直接跳转到下一步。
首先,请按照本教程安装PostgreSQL并创建数据库(请记录数据库名称、用户名及密码!)。
打开SQL Shell (psql)后,执行以下两条命令来创建包含示例数据的表:
CREATE TABLE mytable (name varchar(80),pet varchar(80)
);INSERT INTO mytable VALUES ('Mary', 'dog'), ('John', 'cat'), ('Robert', 'bird');
为本地应用添加用户名和密码配置
您的本地 Streamlit 应用会从项目根目录下的 .streamlit/secrets.toml 文件中读取密钥配置。
如果该文件尚未存在,请创建它,并按照以下示例添加数据库的名称、用户名及密码:
# .streamlit/secrets.toml[connections.postgresql]
dialect = "postgresql"
host = "localhost"
port = "5432"
database = "xxx"
username = "xxx"
password = "xxx"
重要提示
将应用密钥复制到 Streamlit Community Cloud 时,请务必用远程 PostgreSQL 数据库的 host、port、database、username 和 password 值替换原有内容!
请将此文件添加到 .gitignore 中,不要将其提交到 GitHub 仓库!
将应用密钥复制到云端
由于上述 secrets.toml 文件未提交至 GitHub,您需要将其内容单独传递至已部署的应用(在 Streamlit Community Cloud 上)。
请前往应用仪表板,在应用的下拉菜单中点击 Edit Secrets。
将 secrets.toml 的内容复制到文本区域。
更多信息请参阅密钥管理。
将依赖项添加到你的 requirements 文件
将 psycopg2-binary 和 SQLAlchemy 包添加到你的 requirements.txt 文件中,建议固定其版本(将 x.x.x 替换为你想要安装的版本):
# requirements.txt
psycopg2-binary==x.x.x
sqlalchemy==x.x.x
编写你的 Streamlit 应用
将以下代码复制到你的 Streamlit 应用中并运行。
请确保调整 query 以使用你的表名。
# streamlit_app.pyimport streamlit as st# Initialize connection.
conn = st.connection("postgresql", type="sql")# Perform query.
df = conn.query('SELECT * FROM mytable;', ttl="10m")# Print results.
for row in df.itertuples():st.write(f"{row.name} has a :{row.pet}:")
看到上面的 st.connection 了吗?它负责处理密钥检索、设置、查询缓存和重试。
默认情况下,query() 的结果会被永久缓存。
在这个例子中,我们设置了 ttl="10m" 来确保查询结果最多缓存 10 分钟。
你也可以设置 ttl=0 来禁用缓存。
更多信息请参阅 缓存机制。
如果一切顺利(并且你使用了我们之前创建的示例表),你的应用应该会显示如下效果:
上一节:Neon
下一节:私有 Google 表格
将Streamlit连接到私有Google表格
https://docs.streamlit.io/develop/tutorials/databases/private-gsheet
简介
本指南介绍如何从Streamlit Community Cloud安全访问私有Google Sheet。
它使用了st.connection、Streamlit GSheetsConnection以及Streamlit的密钥管理功能。
如果您可以接受启用Google Sheet的链接共享(即任何拥有链接的人都能查看),指南将Streamlit连接到公共Google Sheet展示了一种更简单的实现方式。
如果您的Sheet包含敏感信息且不能启用链接共享,请继续阅读下文。
前提条件
本教程要求您的 Python 环境中安装 streamlit>=1.28 和 st-gsheets-connection。
创建 Google 表格
如果您已有现成的表格,可以直接跳至下一步。
请按以下示例数据创建表格:
| name | pet |
|---|---|
| Mary | dog |
| John | cat |
| Robert | bird |
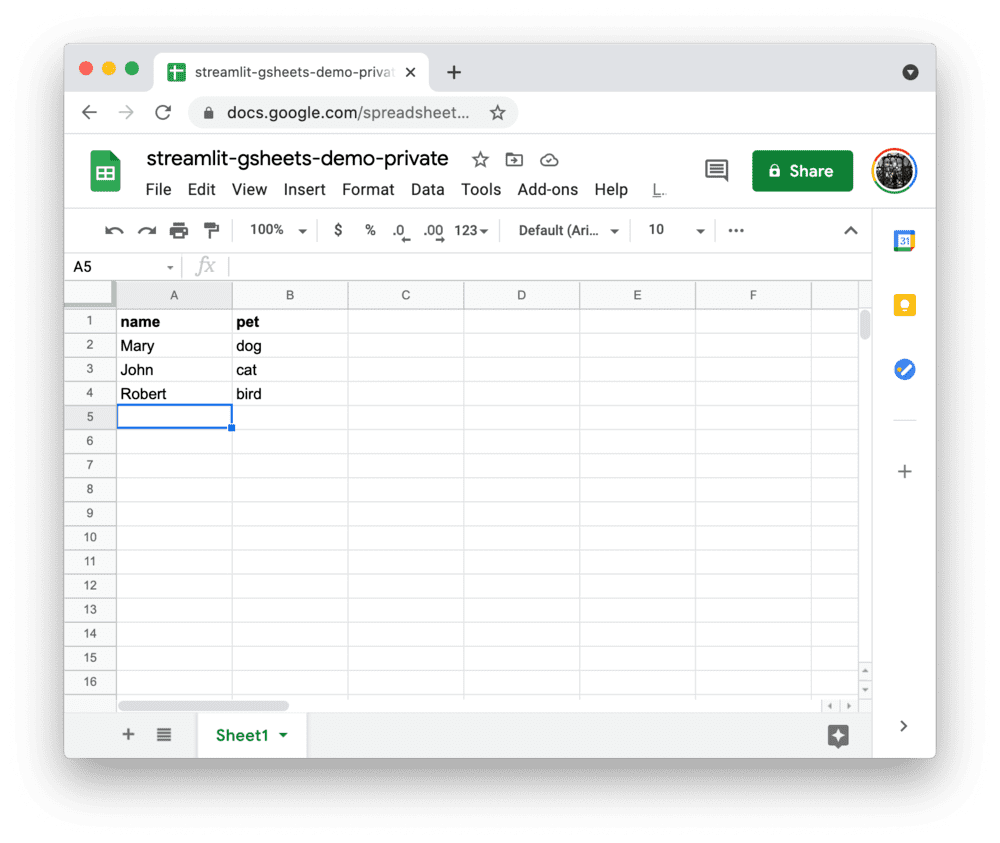
启用 Sheets API
要通过编程方式访问 Google Sheets,需通过 Google Cloud Platform 进行控制。
请创建账户或登录后,前往 APIs 和服务 仪表盘(如系统询问,请选择或创建项目)。
如下图所示,搜索 Sheets API 并启用它:
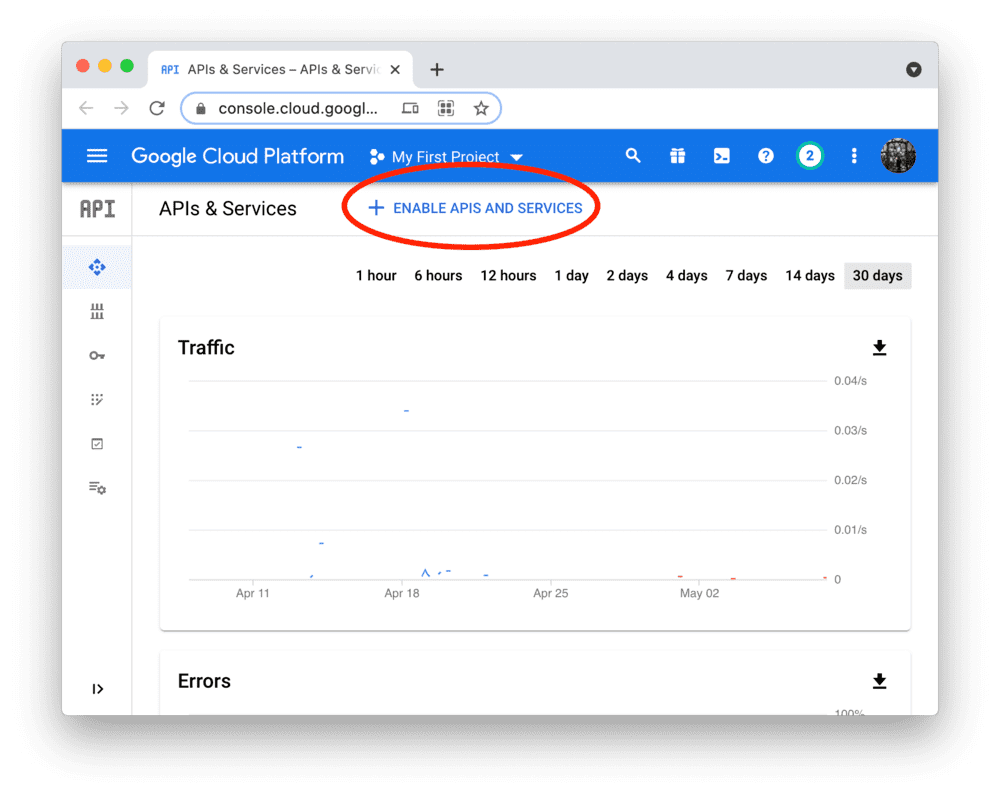

创建服务账号及密钥文件
要在 Streamlit Community Cloud 中使用 Sheets API,你需要一个 Google Cloud Platform 服务账号(一种用于程序化数据访问的特殊账号类型)。
前往 服务账号页面 并创建一个具有 查看者 权限的账号(该权限允许账号访问数据但不可修改):
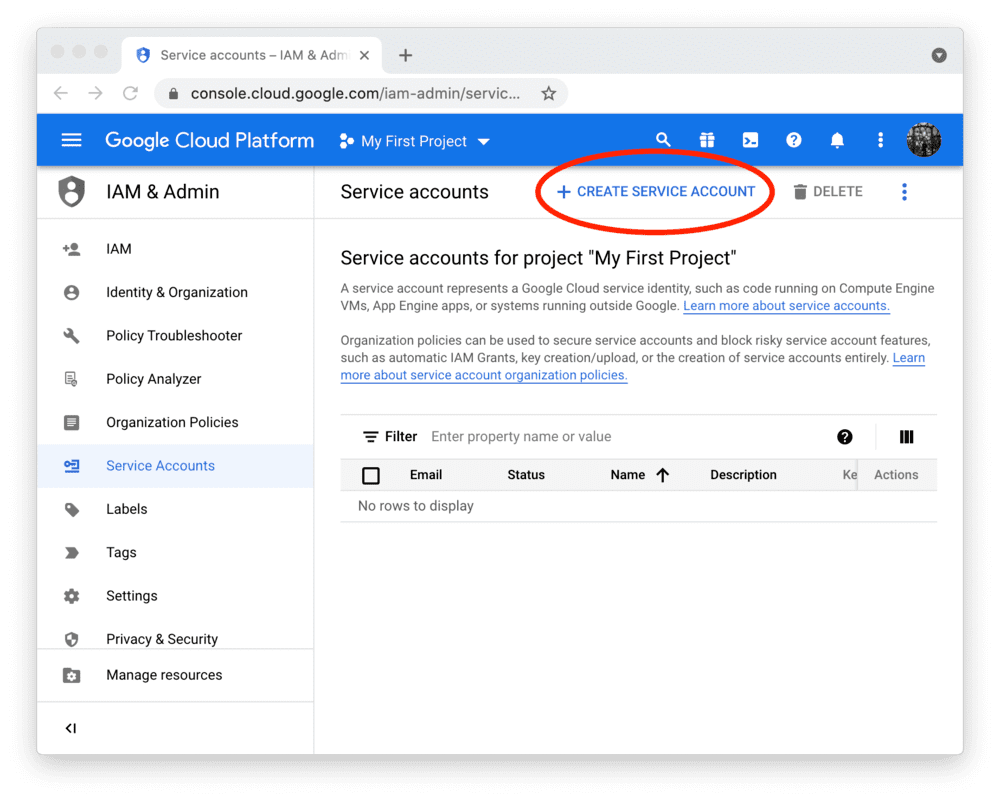
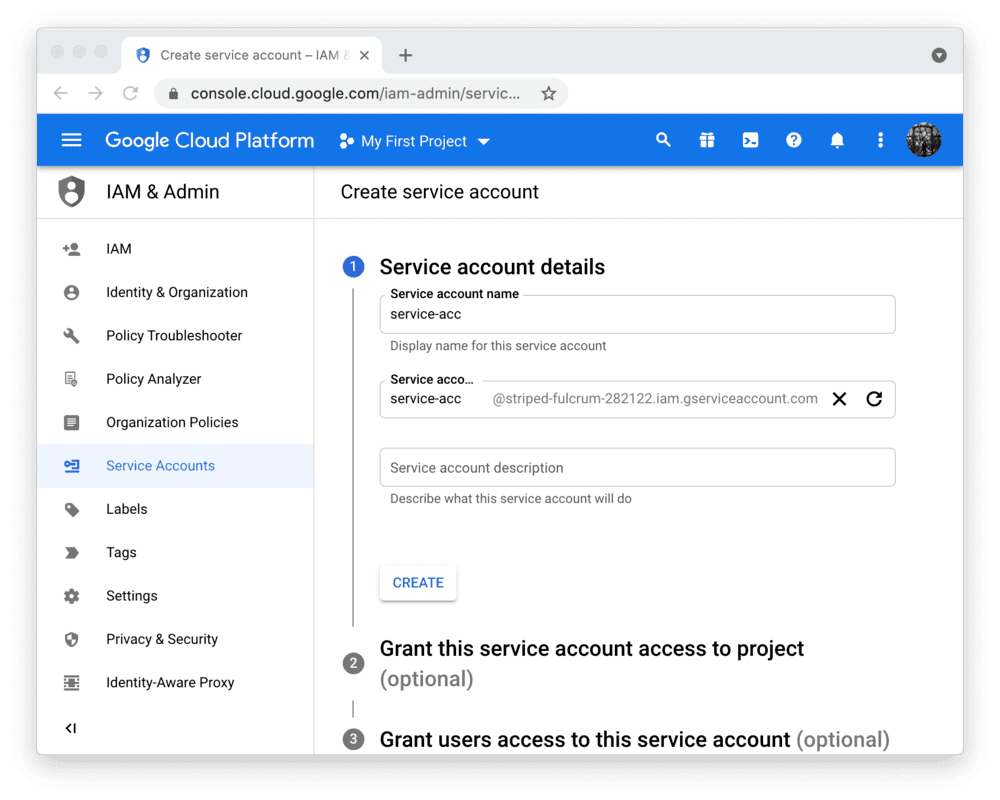
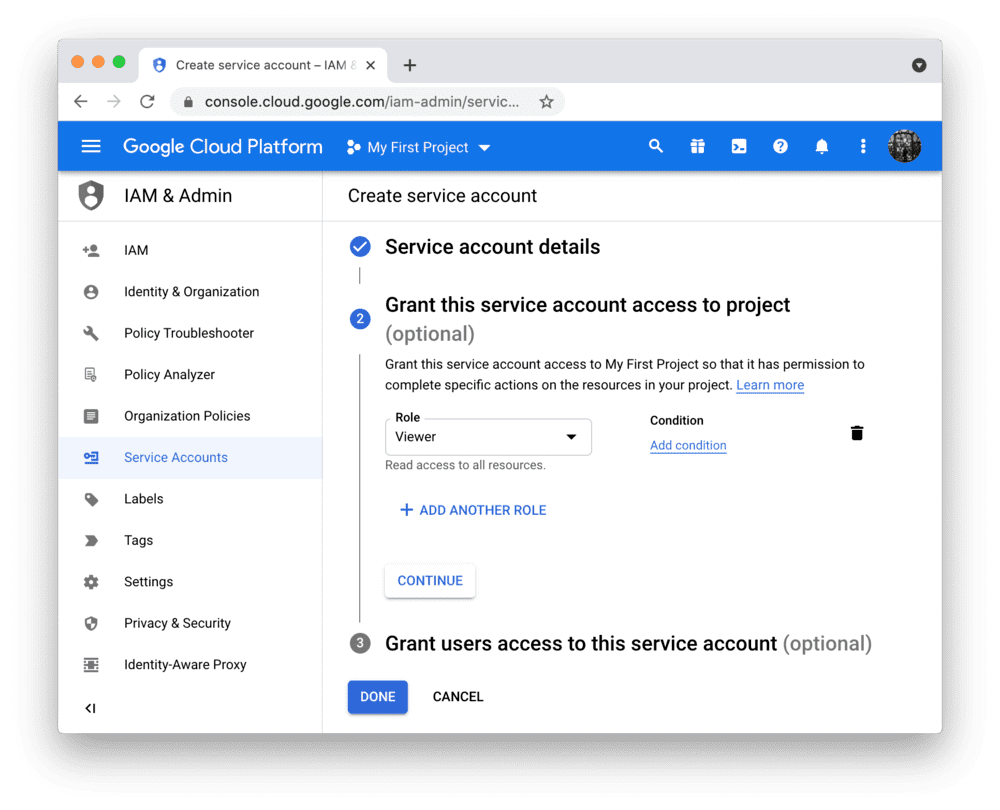
注意:
按钮"CREATE SERVICE ACCOUNT"显示为灰色,说明您没有正确的权限。
请向您的Google Cloud项目管理员寻求帮助。
点击"DONE"后,您将返回服务账户概览页面。
首先,请记录下刚创建账户的电子邮件地址(下一步非常重要!)。
然后,为该新账户创建JSON密钥文件并下载:
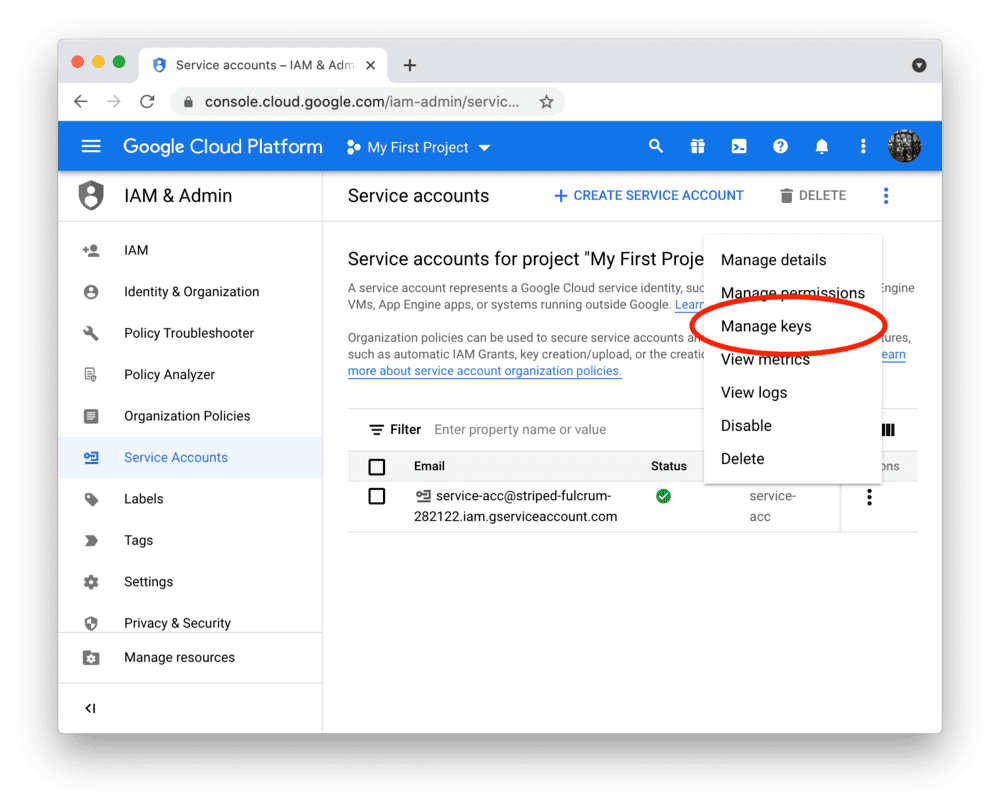
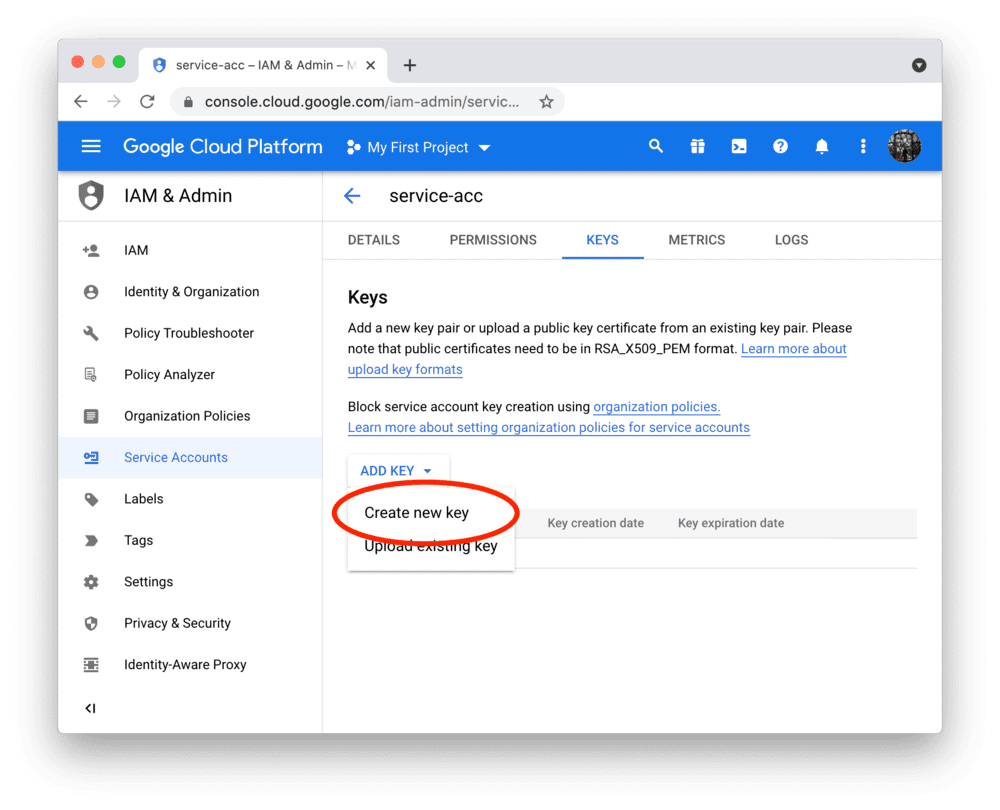
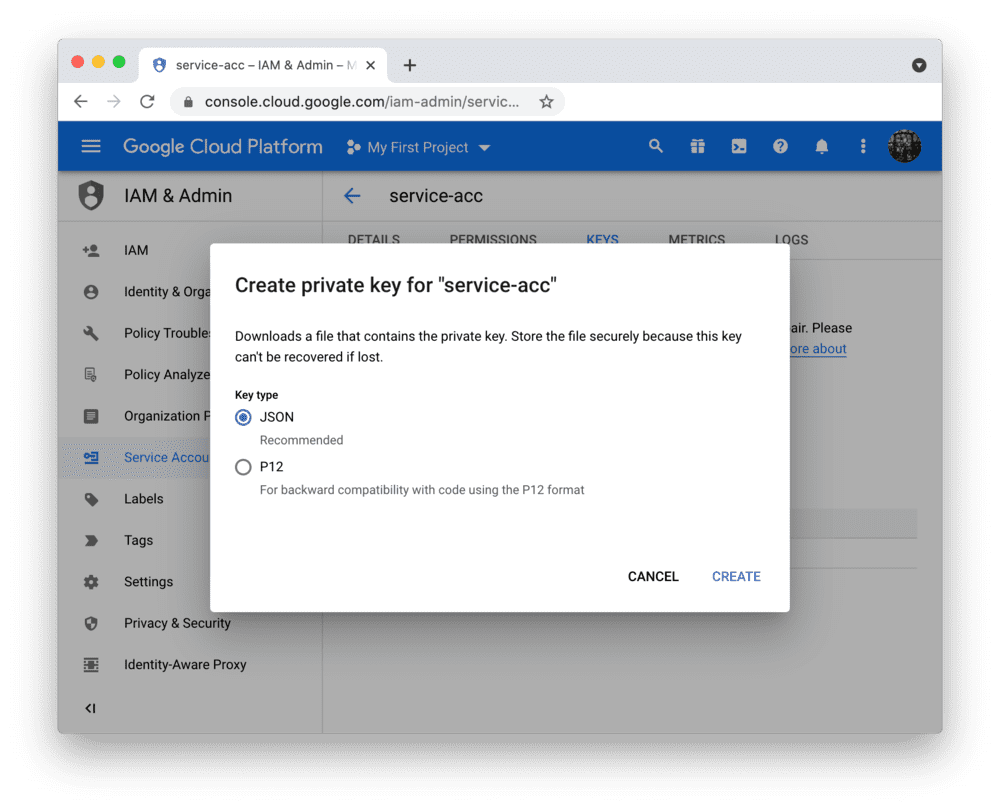
与服务账号共享Google表格
默认情况下,您刚创建的服务账号无法访问您的Google表格。
要授予访问权限,请点击表格中的"共享"按钮,添加服务账号的邮箱地址(在步骤2中记录的那个),并选择合适的权限(如果只需要读取数据,"查看者"权限就足够了):
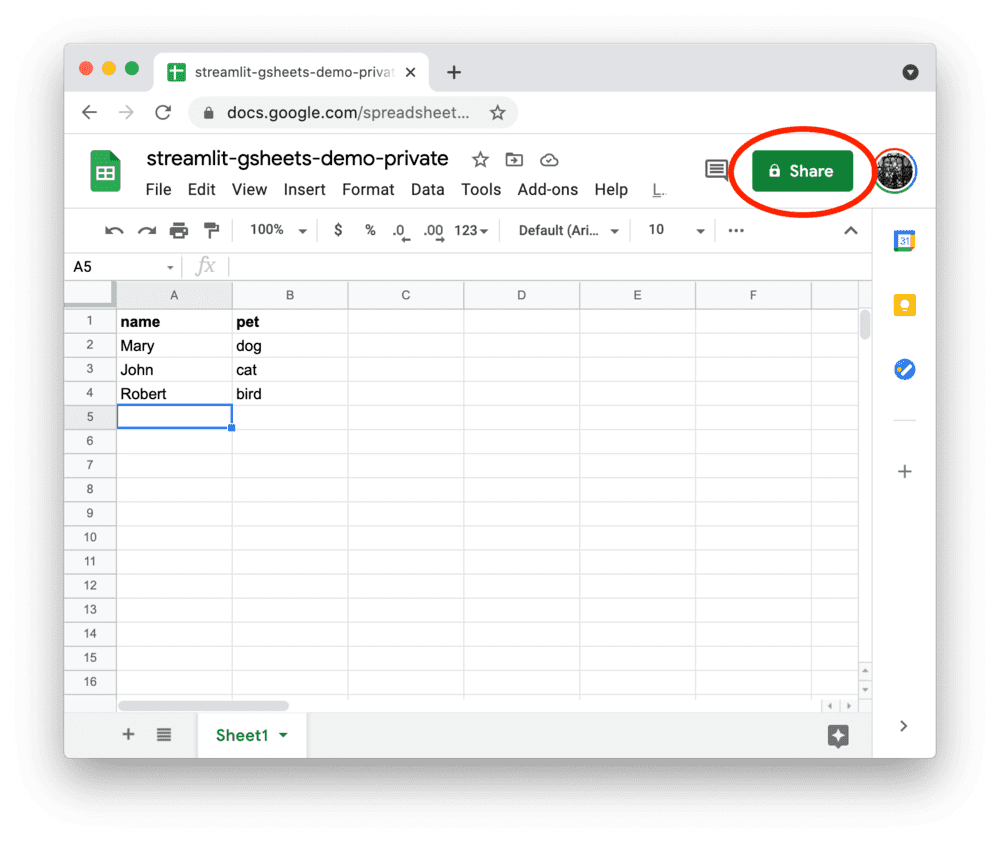
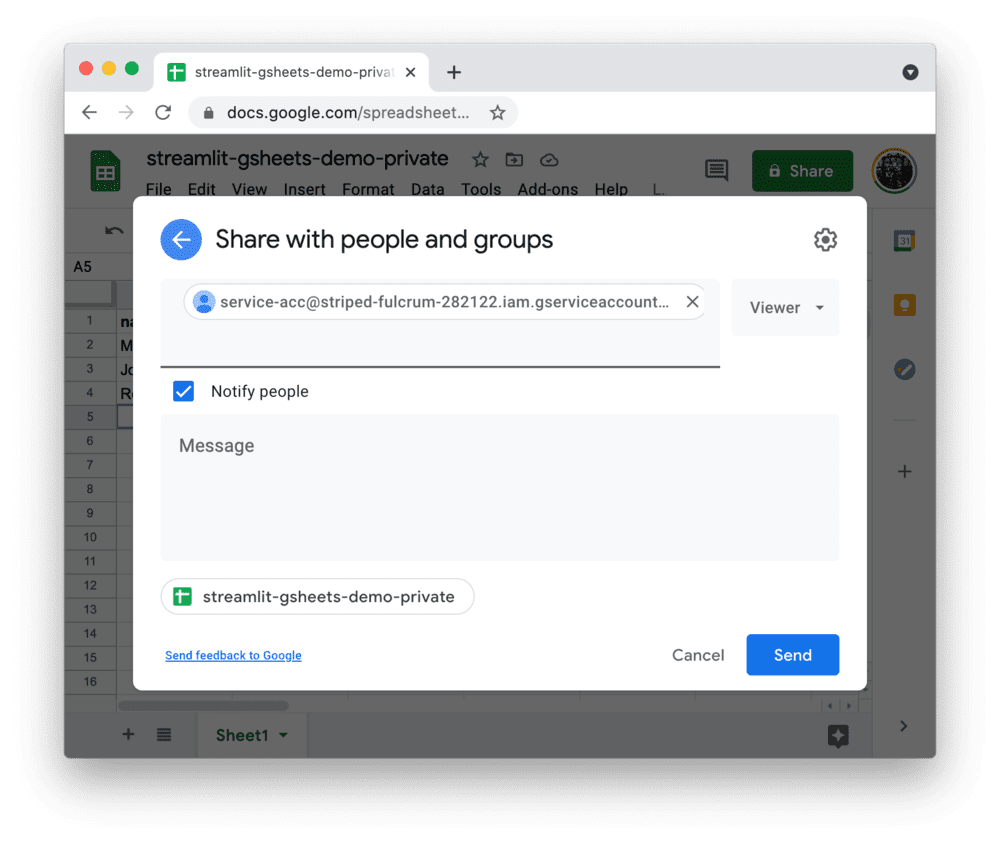
将密钥文件添加到本地应用配置中
您的本地 Streamlit 应用会从项目根目录下的 .streamlit/secrets.toml 文件中读取配置信息。
如果该文件不存在,请先创建它,然后按照以下示例添加您的 Google Sheet 链接以及下载的密钥文件内容:
# .streamlit/secrets.toml[connections.gsheets]
spreadsheet = "https://docs.google.com/spreadsheets/d/xxxxxxx/edit#gid=0"# From your JSON key file
type = "service_account"
project_id = "xxx"
private_key_id = "xxx"
private_key = "xxx"
client_email = "xxx"
client_id = "xxx"
auth_uri = "https://accounts.google.com/o/oauth2/auth"
token_uri = "https://oauth2.googleapis.com/token"
auth_provider_x509_cert_url = "https://www.googleapis.com/oauth2/v1/certs"
client_x509_cert_url = "xxx"
重要提示
请将此文件添加到 .gitignore 中,不要将其提交到你的 GitHub 仓库!
编写你的 Streamlit 应用
将以下代码复制到你的 Streamlit 应用中并运行它。
# streamlit_app.pyimport streamlit as st
from streamlit_gsheets import GSheetsConnection# Create a connection object.
conn = st.connection("gsheets", type=GSheetsConnection)df = conn.read()# Print results.
for row in df.itertuples():st.write(f"{row.name} has a :{row.pet}:")
看到上面的 st.connection 了吗?它负责处理密钥检索、设置、查询缓存和重试。
默认情况下,.read() 的结果会被永久缓存。
你可以向 .read() 传递可选参数来自定义连接。
例如,可以指定工作表名称、缓存过期时间,或者像这样传递 pandas.read_csv 的透传参数:
df = conn.read(worksheet="Sheet1",ttl="10m",usecols=[0, 1],nrows=3,
)
在这种情况下,我们将 ttl="10m" 设置为确保查询结果缓存不超过10分钟。
您也可以设置 ttl=0 来禁用缓存。
了解更多请参阅缓存机制。
我们声明了可选参数 usecols=[0,1] 和 nrows=3 供 pandas 内部使用。
如果一切正常(并且您使用了我们上面创建的示例表格),您的应用应该如下图所示:
从Community Cloud连接Google Sheets
本教程假设使用的是本地Streamlit应用,但你也可以从托管在Community Cloud的应用连接Google Sheets。
主要增加的步骤包括:
- 通过
requirements.txt文件包含依赖项信息,需添加st-gsheets-connection及其他依赖项。 - 将你的密钥添加到Community Cloud应用。
上一篇:PostgreSQL
下一篇:公开Google Sheet