下一场范式革命:Transformer架构≠最终解法
Transformer 奠定了大模型的王朝,却也背上了沉重的算力枷锁。 随着模型参数冲破千亿、处理文本长度不断拉长,其核心的 Attention 机制带来的计算量爆炸,让训练成本飙升、端侧部署步履维艰。预测显示,到2030年训练AI将需近2000万颗H100级别的GPU,这条路的尽头已清晰可见。
变革的种子早已破土而出:Mamba、RWKV、RetNet等新一代架构,正以“线性复杂度”为矛,直指Transformer的效率软肋! 它们宣称无需笨重的Attention,也能实现高性能、低消耗。腾讯、Minimax的混合架构产品落地,更宣告这场底层效率革命已从实验室杀入实战。
如今,Transformer 仍是舞台中央的王者,但 “唯一解” 的神话正在悄然瓦解。一场关乎 AI 未来成本、速度与落地广度的架构之战,已在无声中打响。谁能在性能与效率的天平上找到终极平衡,或许就将定义下一个十年的技术航向。
一、回顾大模型架构演进历史
- 从深度学习革命到 GPT 开启Transformer 时代
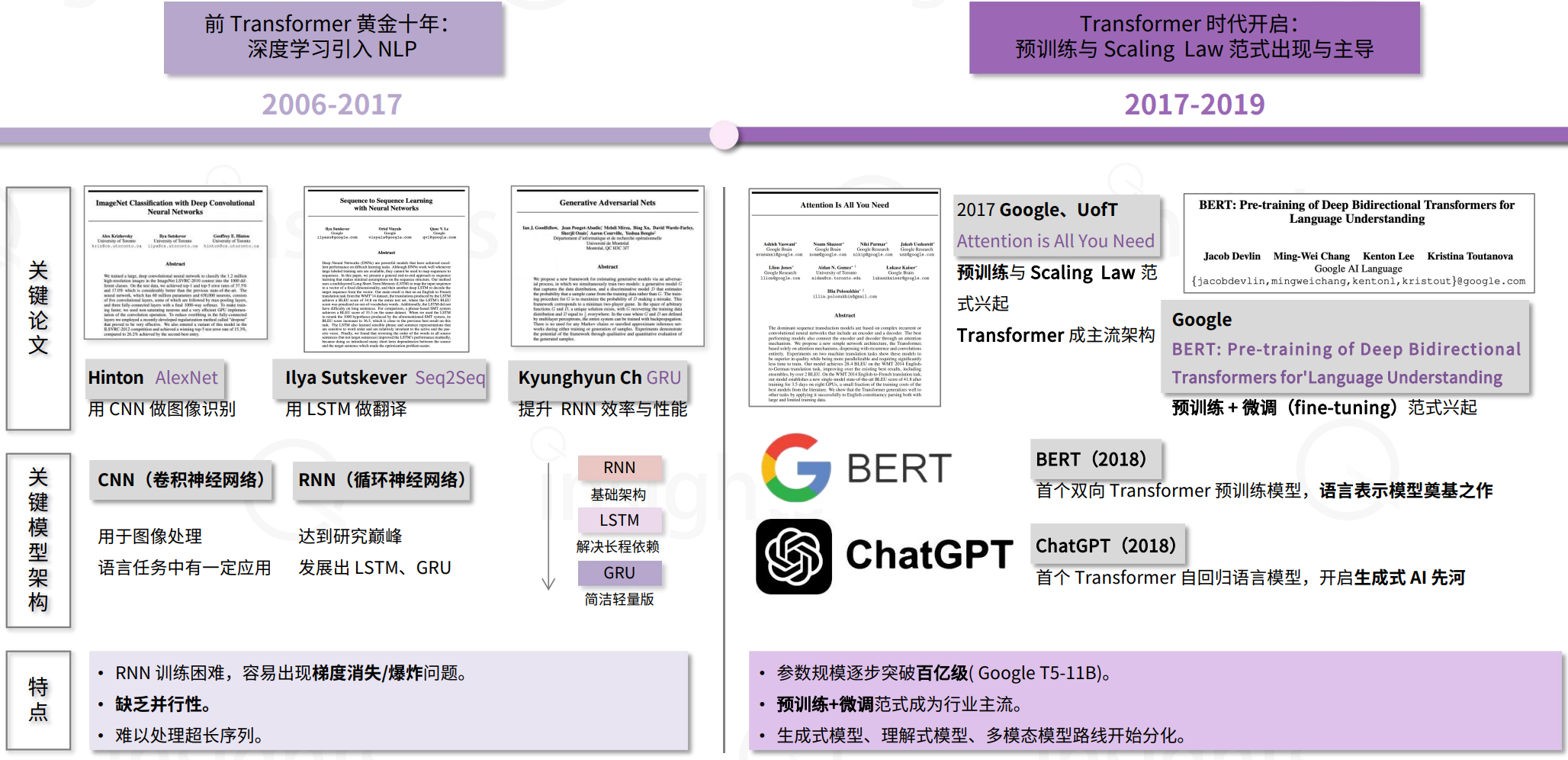
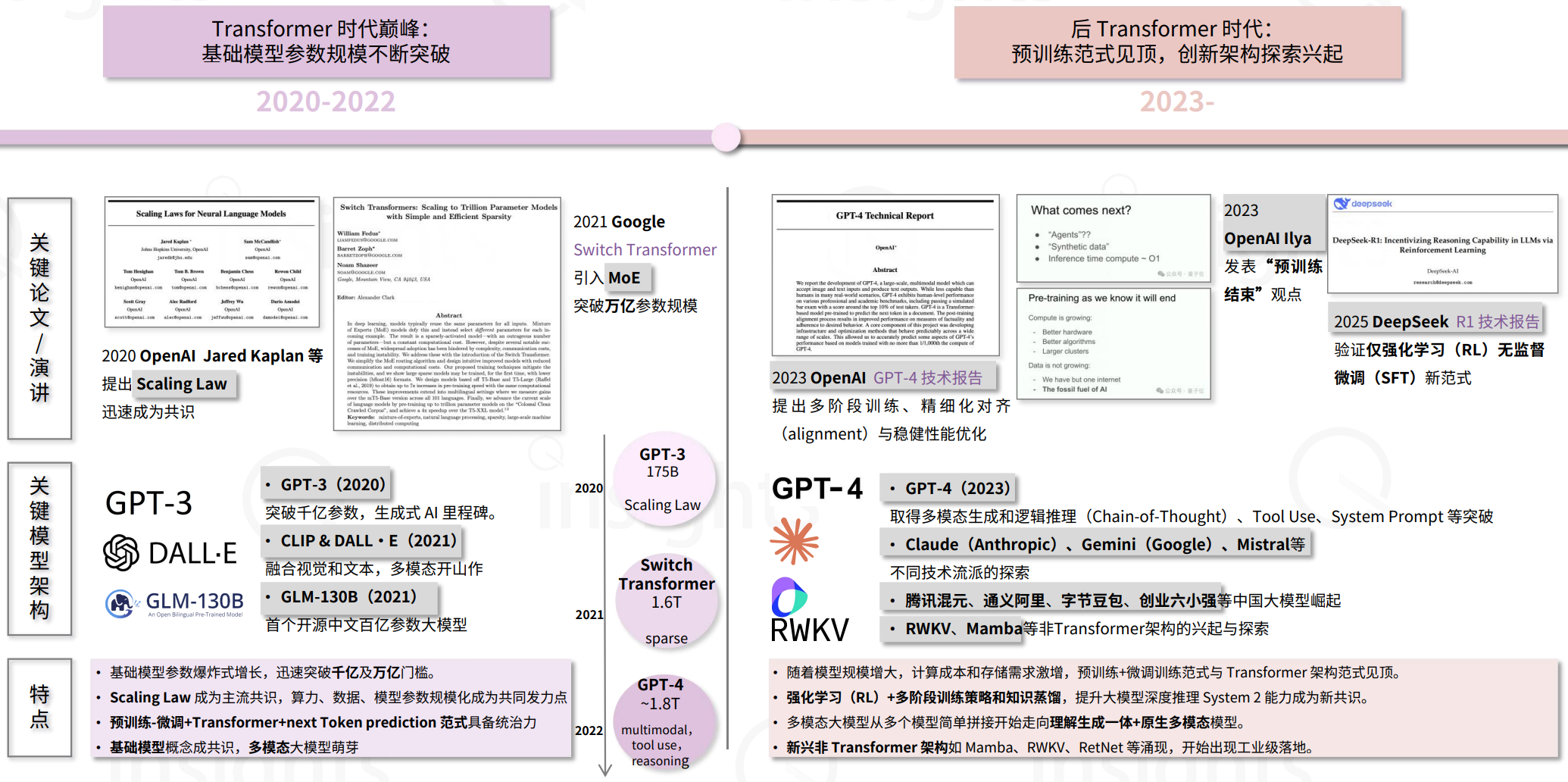
- 主流范式从共识到见顶,后Transformer 时代开启
- Transformer架构逐渐暴露出三大局限性:
- 计算复杂度高,算力消耗剧增:Transformer采用二次复杂度的Attention机制,随着模型和序列长度的提升,算力需求急剧增加,已成为大模型进一步普及和规模扩展的主要瓶颈。
- 主流范式见顶:基于Next-Token Prediction(下一个词预测)和Scaling Law(扩展法则)的技术框架逐渐逼近性能天花板,预训练范式的红利趋于耗尽,创新增量变得有限。
- 端侧部署与长序列任务受限:Transformer在部署到终端设备(如移动端、边缘端)时受限于高算力和内存消耗,难以高效支持长序列处理等实际应用需求,效率瓶颈突出。
根据 Epoch AI 在 2024 年 8 月的研究,当前AI 训练规模正以每年 4 倍的速度增长,预计到 2030 年将需要近2000万个H100级别的 GPU。
二、后Transformer时代:混合化与创新型大模型架构崛起
自2017年《Attention Is All You Need》提出Transformer架构后,Transformer凭借其高度并行化、强大的通用性与扩展性,迅速主导了NLP、CV以及多模态等多个领域,彻底取代了RNN和CNN等传统架构,成为当前主流大模型的首选基础框架,并借助丰富的优化生态保持绝对领先地位。
但随着大模型应用日益细分,开发成本、推理效率和终端响应等现实需求不断提高,Transformer固有的计算和内存瓶颈逐步显现,成为进一步创新和落地的主要掣肘。这推动了底层架构的技术革新步伐加快。
目前,业界主要沿以下路径探索大模型架构创新:
- Transformer架构优化:围绕Attention机制进行高效化改进,如稀疏Attention等,旨在提升训练速度和推理效率。
- 非Transformer架构探索:如新型RNN、状态空间模型(SSM)等,突破传统Attention范式,在长序列建模和资源利用率方面展现潜力。
- 训练范式革新:如DeepSeek-R1,跳过SFT直接进行RL、GRPO价值模型优化。
- 工程优化:如DualPipe 流水线、FP8 混合精度。
2025年,非Transformer架构实现了“0-1”工业级落地突破——如Minimax推出MiniMax-01,率先将线性架构用于千亿级参数模型;腾讯混元T1正式版Turbo-S则采用了Transformer+Mamba混合架构,标志着这一路径由科研迈入商业化阶段。

总的来看,混合化创新已成新趋势,越来越多模型融合多种架构优势,追求性能与效率的最优平衡。尽管Transformer仍为大模型基石,但底层架构创新正成为AI持续演进的核心动力,未来混合型和创新型架构将在大模型竞争格局中扮演愈发重要的角色。
三、非Transformer路线:创新架构的探索与突破
尽管Transformer已经成为当前AI领域的核心支柱,凭借其独特的注意力机制,实现了高效的并行处理和卓越的长距离依赖建模能力,但在算力和内存消耗方面依然存在显著瓶颈。这些限制推动了非Transformer架构的崛起,其目标是在接近甚至超越Transformer性能的同时,实现更优的算力效率和推理速度。
当前,主流的非Transformer研究主要聚焦于对attention机制的优化或替代,探索如高效RNN等具备线性计算复杂度的新结构,以实现资源消耗的进一步降低。虽然RNN在处理长序列和并行能力方面不及Transformer,但其推理时计算复杂度恒定,且内存和算力需求随序列长度线性增长,更适用于资源受限或需要端侧部署的场景。因此,越来越多的创新型架构致力于融合RNN的高效推理优势,努力缩小与Transformer在综合性能上的差距,并在特定任务或应用领域实现突破,逐步成为Transformer架构的重要挑战者。
1. Mamba架构
核心特点:
- 基于状态空间模型(SSM)的现代版RNN
- 线性复杂度,处理长序列更高效
- 固定内存占用,适合资源受限环境
工作原理:
- 类似人类大脑的“压缩记忆”,每步仅摘要前文关键信息
- 采用选择性SSM机制,动态决定哪些信息保留、哪些遗忘
- 利用线性递推和硬件友好型scan算法
- 并行化训练+串行化低成本推理
性能表现:
- Mamba-3B可超越等规模Transformer,接近6B Transformer
- 长序列、音频、DNA序列等多领域SOTA表现
- 推理速度快、显存消耗低,适合大规模部署
- 但个别任务、极长依赖场景下略逊传统Attention
2. RWKV架构
核心特点:
- RNN与Transformer优点结合
- 时序线性计算复杂度,“无限”上下文长度
- 内存固定、推理生成速度恒定
工作原理:
- 堆叠残差块,包括时间混合Time-mixing与通道混合Channel-mixing两类子结构
- 采用Token shift(token平移+线性插值)优化输入流动
- 状态向量(Dynamic State Evolution)存储信息,动态更新
- 不含自注意力机制,完全靠状态递归传递
性能表现:
- 持续迭代升级(RWKV-5→V7),长序列任务上具优势
- 训练推理资源需求低于Transformer 1~2个数量级
- 与Transformer精度相当,适合资源受限场景
- 对Prompt格式敏感,复杂回溯/检索任务有待加强
3. RetNet架构
核心特点:
- 引入Retention机制,融合Transformer与RNN优势
- 支持并行训练与线性O(1)推理
- 长序列建模能力优异、资源节省显著
工作原理:
- 多尺度Retention层替换多头Attention
- 三种范式(并行、递归、分块递归)结合
- 分块局部并行+全局递归建模,提升算力利用率
- 实现训练-推理解耦及低延迟部署
性能表现:
- 训练加速7倍、内存降低25-50%,推理内存减70%
- 解码速度远快于KV缓存Transformer
- 长距离依赖能力仍在验证,应用成熟度有待提升
4. Monarch Mixer
核心特点:
- 利用结构化混合器(结构化稀疏矩阵)替代Attention
- 关注训练-推理高效性
- 支持大规模序列/图/音视频建模
工作原理:
- 分解输入为局部和全局混合模块
- 运用高效矩阵乘法/低秩近似提升计算性能
- 无需自注意力,靠混合层捕获长短依赖关系
性能表现:
- 在列表排序/图建模等任务媲美或超越Transformer
- 理论复杂度低,硬件亲和
- 实际应用生态正在拓展
5. Longformer/稀疏Attention类
核心特点:
- 在自注意力中引入稀疏图(滑窗+全局部分关键节点)
- 降低长序列计算复杂度至O(N)或O(N logN)
- 兼顾全局与本地关系
工作原理:
- 滑动窗口Attention捕捉局部依赖,全局Attention处理关键token
- 部分采用多头扩张边覆盖更远依赖
- 部分模型可支持超长文本序列
性能表现:
- 适用于文档、科学文献、长代码等长文本领域
- 长序列推理及批量效率大幅提升
- 性能接近标准Transformer,泛化能力好
- 较复杂的链式推理/全局依赖仍较弱
6. Hyena架构
核心特点:
- 基于隐式长卷积和门控机制的注意力替代
- 复杂度远低于Transformer,亚线性可扩展
- 上下文支持极长、算力友好
工作原理:
- 用卷积和门控算子替代自注意力
- 隐式定义长距离关系操作,参数效率高
- 支持Toplitz矩阵技术,允许高效并行与长序列训练
- 门控结构用于信息流控制
性能表现:
- 长序列推理速度超Transformer百倍(如64k序列下)
- 2k~8k序列能耗和速度显著优于Flash Attention
- 但当前未支持masked训练,生成式领域限制较大
- 在全局依赖/复杂推理等任务需进一步完善
7. 线性注意力(如Agent Attention/TransNormerLLM/MiniMax-01)
核心特点:
- 将传统Attention的Softmax操作线性化,O(N)复杂度
- 支持巨型输入,极大提升吞吐效率
- 高度适配分布式并行
工作原理:
- 构造可分解的Attention内核,省略全体对全体的乘法
- 采用分块计算/Lightning Attention进一步降内存
- Agent Attention引入代理向量,增强表达力
性能表现:
- 在视觉/多模态/大规模文本领域取得进展
- 内存消耗降低2-4倍,速度提升2-8倍
- 长距离依赖及In-context学习目前仍有差距
8. DeepSeek架构(以V3为例)
核心特点:
- 大规模混合专家(MoE)架构,参数量极高
- 注重推理、高速生成和极低训练成本
- 技术细节持续创新,开源友好、适合商用
工作原理:
- 多头潜在注意力与高效激活路由
- 大规模负载均衡、训练目标调整
- 框架/算法/硬件协同优化,提升整体效率
性能表现:
- 综合测评接近/超越主流闭源大模型
- 数学、知识、编码等多任务强劲
- 提供成本低、速度快、嵌入免费等优势
- 在自我认知、提示词适应、复杂多模态弱于顶尖对手
Transformer架构的成功并非偶然,它在表达能力、灵活性和可扩展性等方面都达到了前所未有的高度。任何试图取代Transformer的架构,都必须在各个方面都展现出明显的优势,才能真正赢得市场的认可。更重要的是,人工智能技术的发展并非一场零和游戏,各种架构的相互竞争和融合,最终将推动整个领域不断向前发展。Transformer架构的挑战者们,或许无法完全取代Transformer的地位,但它们所带来的创新思路和技术突破,给人工智能的未来发展注入了新的活力。
四、非Transformer架构:能力上限与生态壁垒的双重考验
1. 上限尚未验证,规模化能力待突破
虽然非Transformer架构的研究不断涌现,并在中小规模下取得了优于同等规模Transformer的评测成绩,但其核心挑战在于:当参数规模扩展到千亿、万亿级别时,是否仍能保持性能与效率的优势?目前,参数量最大的RWKV仅有140亿,而GPT-3和GPT-4分别高达1750亿乃至万亿级。这意味着,非Transformer架构亟需推出千亿级参数的大模型来验证其理论“天花板”。
尽管RWKV等代表性架构已有部分落地应用,主流资本和大厂仍偏向观望。原因在于,一方面,端侧部署Transformer困难,需依赖强大云端算力,无法兼顾速度与体验;另一方面,随着硬件性能不断提升,当前非Transformer在轻量化上的优势可能被“摊平”,届时Transformer也能顺利适配终端设备,底层架构创新并非唯一突破口。投资者普遍认为,只有在实现顶级效果并兼具小型轻量化的情况下,非Transformer路线才具有长期价值,否则“为本地化而本地化”可能流于伪命题。以RWKV为例,目前推理效果大致接近GPT-3.5的60分,距GPT-4仍有明显差距,过度追求轻量化可能反而限制了模型的能力上限。
2. Transformer生态壁垒带来巨大挑战
除了技术路线自身的考验,非Transformer架构还必须直面Transformer日益坚固的生态护城河。目前,无论在硬件适配、系统接口还是评测标准上,整个产业链几乎都围绕Transformer体系优化,形成了极强的生态垄断地位。资本、资源和团队等方面的巨大投入也进一步强化了这一优势,使得其他架构在打破生态壁垒、获得广泛应用上面临更高的门槛与挑战。
五、架构创新展望:迈向融合与突破的新纪元
1. 混合架构趋势明显
展望未来,大模型架构正呈现出明显的“混合化”趋势。无论是纯SSM(状态空间模型)还是纯Attention架构,都存在各自的局限,最优方案很可能来自两者的有机融合,例如Mamba-2-Hybrid和NVIDIA等公司的混合模型,这类架构有望兼顾高效性与表现力,突破现有单一架构的瓶颈。
2. 线性复杂度突破
在算力效率方面,越来越多模型关注于解决Transformer的二次复杂度难题,通过线性注意力等创新机制,实现对长序列任务的高效支持,这为落地和应用拓展提供了更广阔的空间。
3. 原始数据处理
新架构倾向于直接处理原始数据,减少对Tokenization等预处理的依赖,更加契合深度学习端到端学习的精神。
从深度学习的发展历史来看,每一次主流架构的变革——从CNN到RNN,再到Transformer——都遵循了“突破—优化—再突破”的技术迭代周期律。
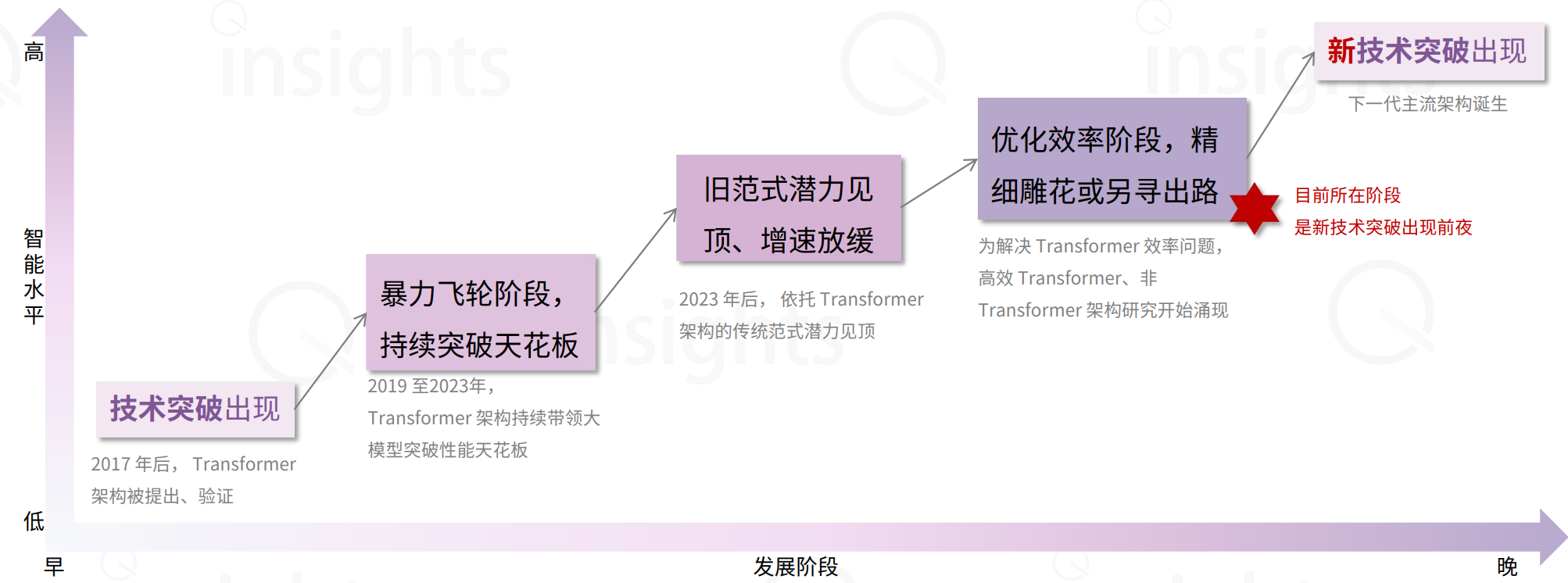
当前,Transformer依然是事实上的“最强架构”,无论在性能还是生态体系上都具有明显优势。然而,技术进化不可逆、不可停,行业也不可能由单一架构永远占据主导。非Transformer路径能否实现大规模突破、达到“顶级效果”,仍需时间检验;与此同时,Transformer自身在面对更大规模、极长序列或多模态任务时,也会遇到新的挑战。
无论架构流派如何更迭,持续扩展规模、不断优化算法,始终是驱动AI不断逼近通用智能(AGI)目标的关键动力。
参考:
https://cloud.tencent.com/developer/article/2407792
https://www.51cto.com/aigc/3884.html
https://jkhbjkhb.feishu.cn/wiki/W5D7wuDcbiPXDLkaRLQcAJpOn8f