string【下】- 内功修炼(搓底层)
前言:本篇仅仅是对string 的一些常用函数 进行编写,目的就是为了更好的了解string 的底层 , C++是一个极度追求效率的一个语言 , 需要了解 , 为啥要少用 某个函数 , 为啥这个函数就坑了程序,导致程序的效率降低。会有一定的难度 , 但 , 加油噢 ~~~
string的文档如下链接:
string - C++ Reference
一、Member functions
对于自己编写的 string , 为了和库里的 string 进行区分 , 我们可以使用 命名空间域 (namespace )进行隔离!
string.h
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once
#include<iostream>
using namespace std;namespace LF
{class string{public://这里我们一般只留一个构造 - 全缺省的默认构造(最后面会有)string();~string();string(const char* str);//比较短的代码就放在类里,内联函数,不用建立函数栈帧了,提高效率const char* c_str() const{return _str;}private:char* _str;size_t _size;size_t _capacity;};
}string.cpp
#include"string.h"namespace LF
{string::string():_str(new char[1] {'\0'}), _size(0), _capacity(0){}string::~string(){delete[] _str;_str = nullptr;_size = 0;_capacity = 0;}string::string(const char* str)//+1 的原因是还有一个 \0 要保存:_size(strlen(str)){_capacity = _size;_str = new char[_size + 1];strcpy(_str, str);}
}
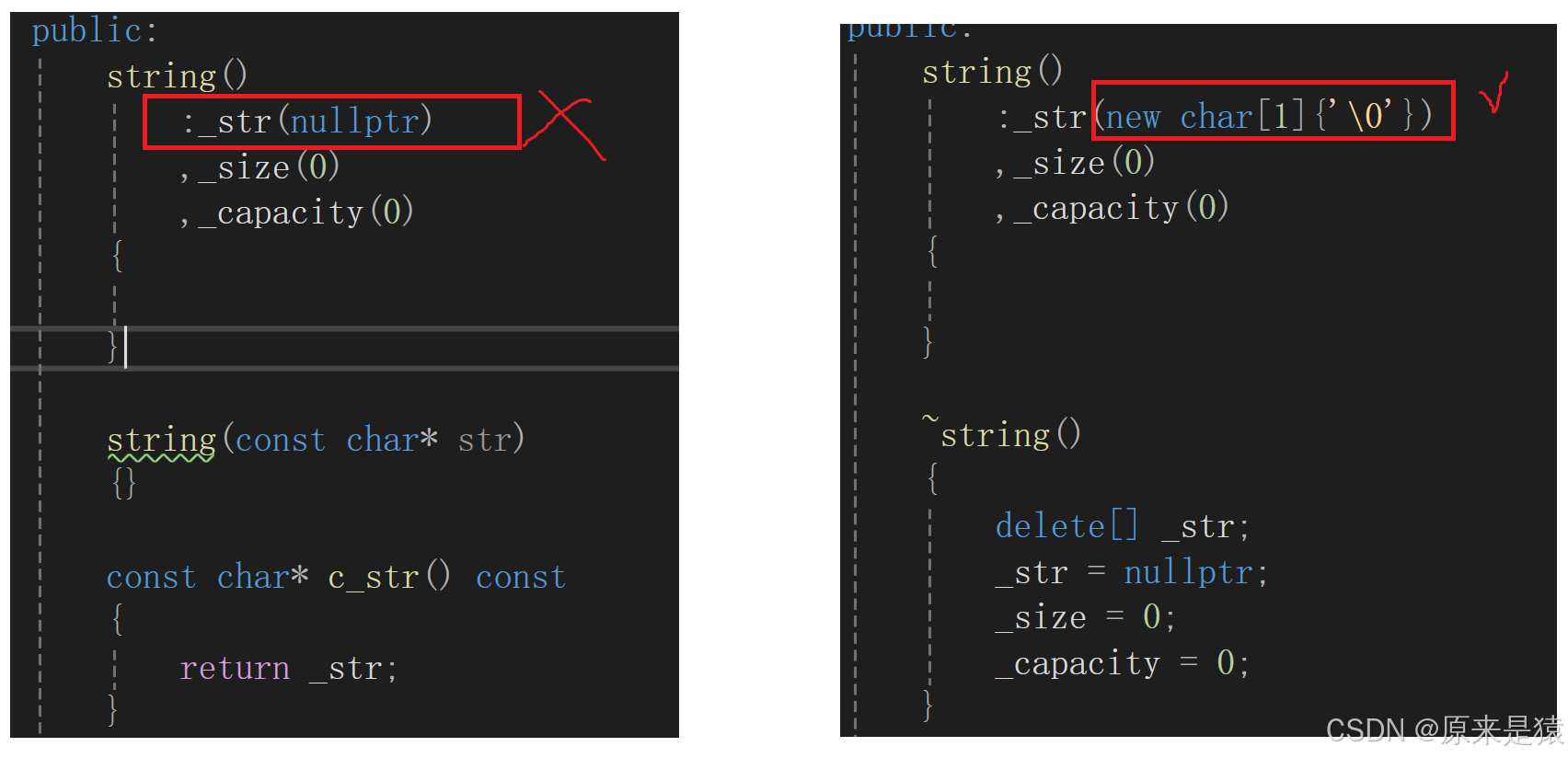
1) 为啥 无参构造的初始化列表的 c_str 需要 new char[1] {'\0'} ?
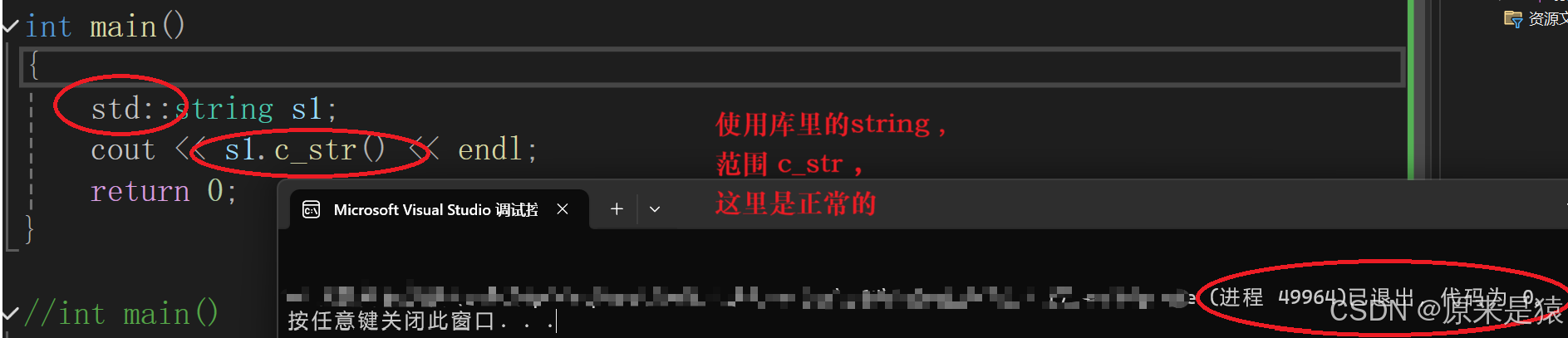
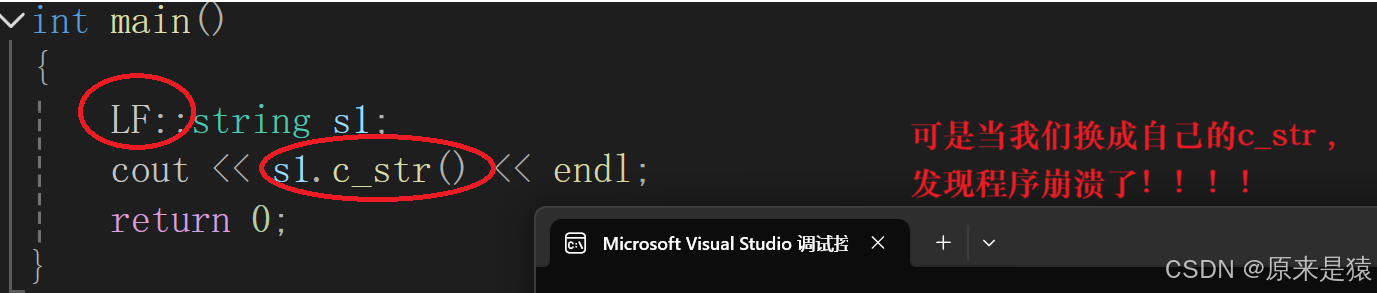
如果我们按照往常一样, 把_str 置为 nullptr 。当你调用 c_str( ) 的时候 , 编译器认为你需要打印的不是指针 , 而是字符串 , 字符串的结束符标志位 '\n' 。 初始化如果为空,就会导致空指针解引用,程序崩溃!!!
2)不是说尽量在初始化列表里面初始化吗 ? 可是在有参构造这里 , 为啥除了 _size , 其他的都在函数体内进行初始化 ?
平常我们就是按照如下的方法来初始化变量 ,尽可能的在 初始化列表 里面 初始化 变量 。 但是 strlen 是在运行时运算的 , 时间复杂度为 O(n) , 这里用三个 O(n) , 有点坑啊 ~

脑袋瓜灵机一动 , 那就先计算 _size , 然后其他的都调用_size !
string(const char* str):_size(strlen(str)),_capacity( _size),_str(new char[_size + 1]){strcpy(_str, str);}这效率的的确确有提高 , 但是这是一个大坑 !!!!

这时候空间没开够 , 数组越界 , 野指针析构 , 程序就崩溃了!!!
一般来说,构造我们仅仅留一个全缺省默认构造即可,注意这里的缺省值不能给空指针,也不能给 '\0' (因为字符串默认后面就有一个 '\0'), 直接给一个空字符串即可。同时 , 当声明和定义分离的时候 , 仅在声明位置给缺省值 。
string.cpp
#include"string.h"namespace LF
{string::string(const char* str):_size(strlen(str)){_capacity = _size;_str = new char[_size + 1];strcpy(_str, str);}string::~string(){delete[] _str;_str = nullptr;_size = 0;_capacity = 0;}
}string.h
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<assert.h>
using namespace std;namespace LF
{class string{public:using iterator = char*;using const_itertor = const char*;string(const char* str = " ");~string();const char* c_str()const{return _str;}private:char* _str;size_t _size;size_t _capacity;
};
}二、遍历
string 有三种方式可以遍历:
1. 下标 + [ ]
2. 迭代器
3. 范围 for
1) 下标 + [ ] :


在自己写代码的时候 , 一般写一个 , 测试一个 !!!
2)迭代器:

string 这里我们可以用原生指针来实现 , 因为string 的物理空间是连续的 !
iterator begin(){return _str;}iterator end(){return _str + _size;}const_itertor begin() const{return _str;}const_itertor end() const{return _str + _size;}
3)范围for :
范围 for 的底层是迭代器支持的 , 意味着支持迭代器就支持范围 for ! (意味着迭代器必须叫iterator , 必须是begin , 必须是end ! 一旦字母大小写不对 或者 使用其他单词来替代 ,则不支持范围for )
test.cpp
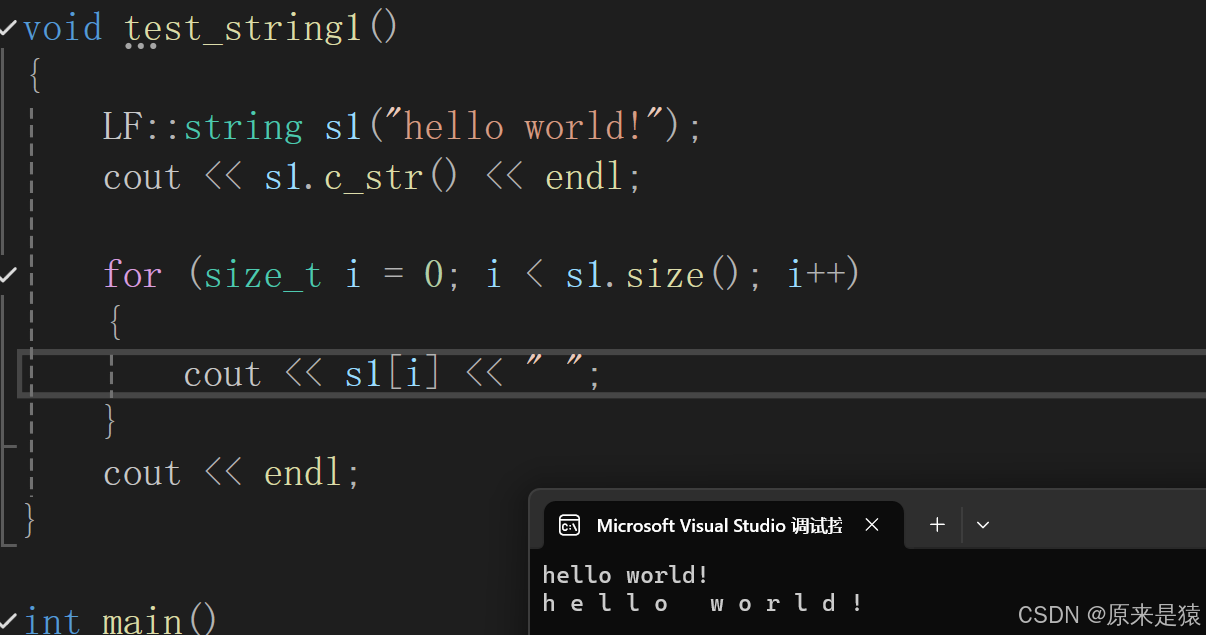
#include"string.h"void test_string1()
{LF::string s1("hello world!");cout << s1.c_str() << endl;//下标 + [ ]for (size_t i = 0; i < s1.size(); i++){cout << s1[i] << " ";}cout << endl;//迭代器LF::string::iterator it1 = s1.begin();while (it1 != s1.end()){cout << *it1 << " ";++it1;}cout << endl;//范围forfor (auto& ch : s1){cout << ch << " ";}cout << endl;}int main()
{test_string1();return 0;
}string.h
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<assert.h>
using namespace std;namespace LF
{class string{public://typedef char* iterator;using iterator = char*;using const_itertor = const char*;string(const char* str = " ");~string();char& operator[](size_t i){assert(i < _size);return _str[i];}const char& operator[](size_t i) const{assert(i < _size);return _str[i];}iterator begin(){return _str;}iterator end(){return _str + _size;}const_itertor begin() const{return _str;}const_itertor end() const{return _str + _size;}size_t size() const{return _size;}const char* c_str()const{return _str;}private:char* _str;size_t _size;size_t _capacity;
};
}
三、Modifiers
这里就不重载+了 , 因为+是在全局 , 不太建议使用,效率会有一定的影响,后面介绍拷贝问题的时候会说明!
3.1 尾插
void string::reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void string::push_back(char ch){if (_size == _capacity){reserve(_capacity == 0 ? 4 : 2 * _capacity);}_str[_size] = ch;++_size;}void string::append(const char* str){size_t len = strlen(str);if (_size + len > _capacity){size_t newCapacity = 2 * _capacity;//扩2倍不够,则需要多少则扩多少if (newCapacity < _size + len)newCapacity = _size + len;reserve(newCapacity);}strcpy(_str + _size, str);_size += len;}string& string::operator+=(char ch){push_back(ch);return *this;}string& string::operator+=(const char* str){append(str);return *this;}
3.2 插入数据
插入一个字符:
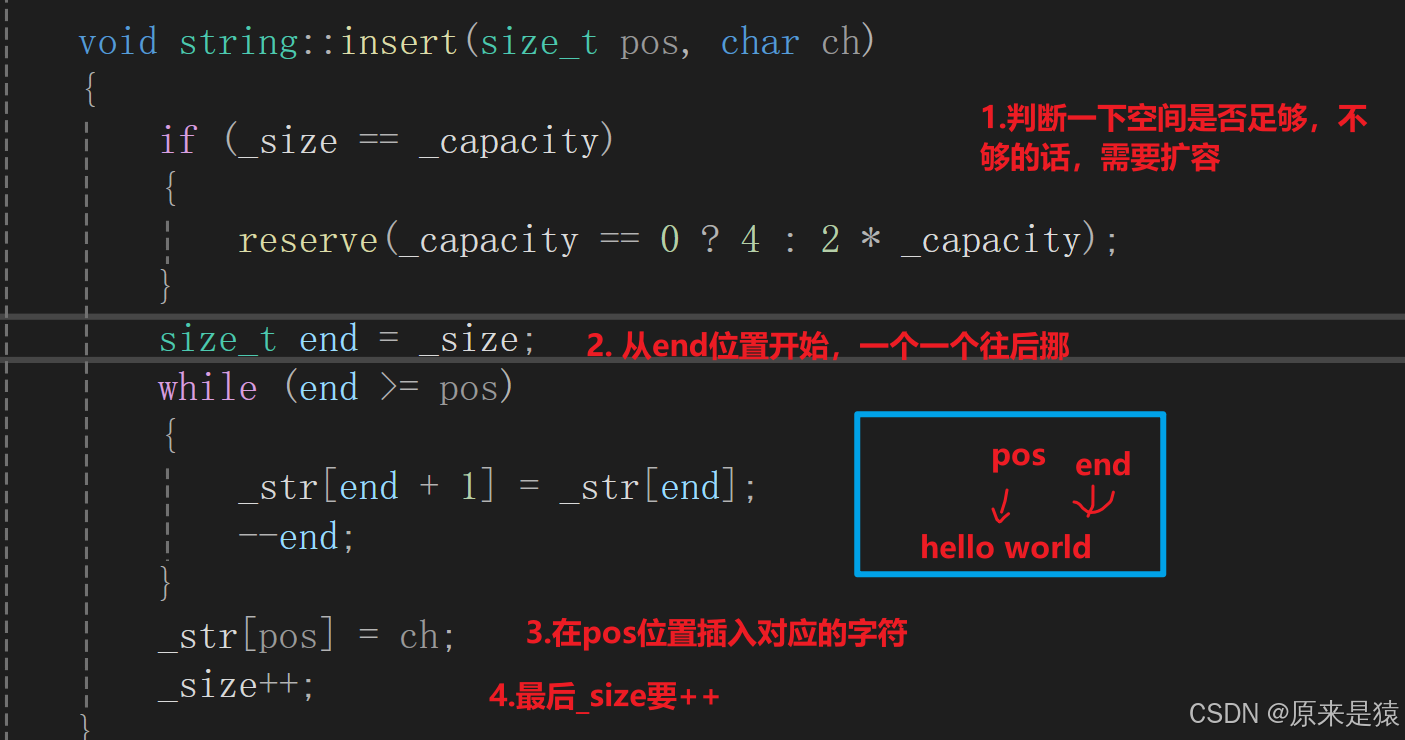
但是在某些特殊场景下会有BUG , (测试的时候,尽量把边界情况都考虑到!)比如头插!!!

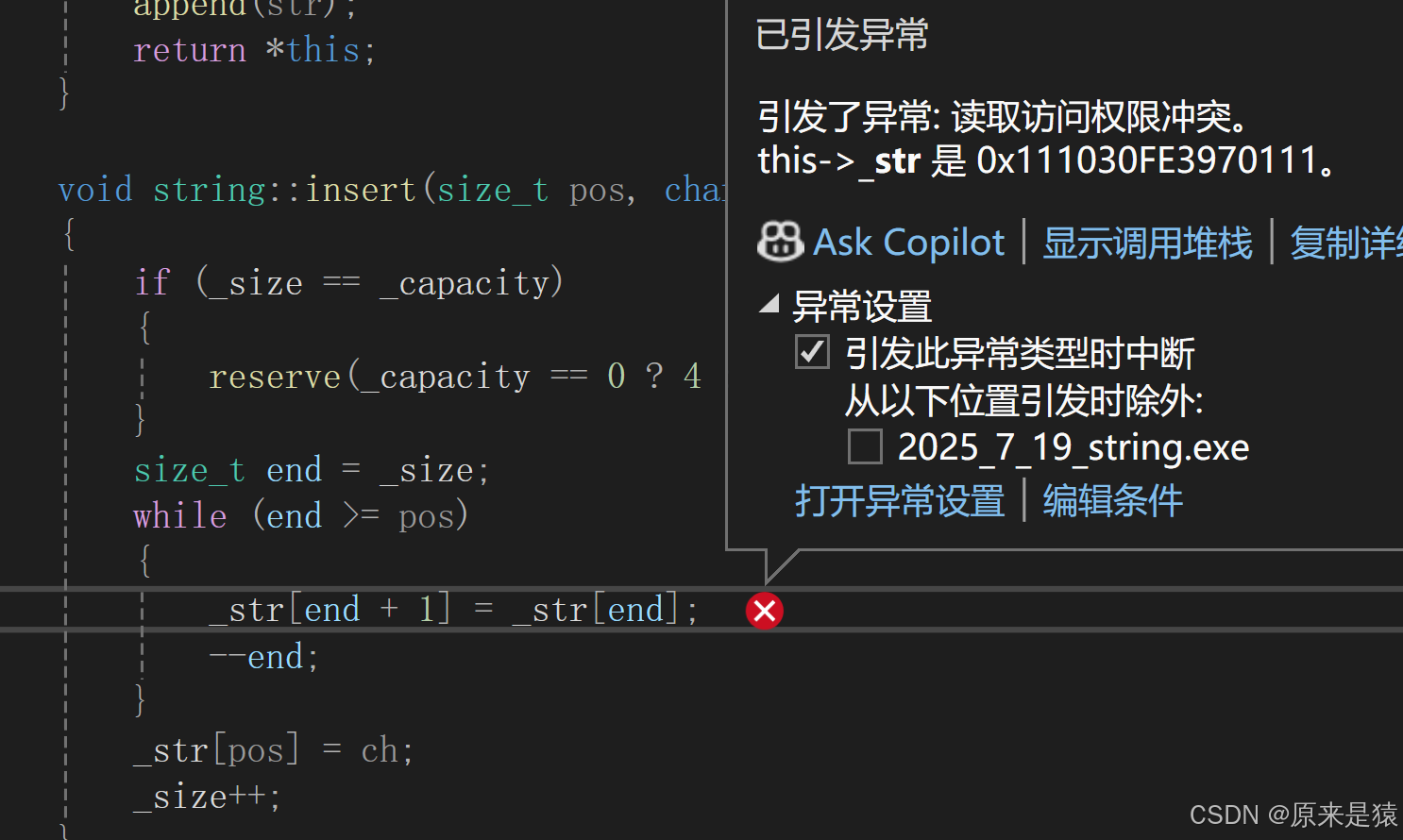
方案一 : 把 end 的类型改为 int , 同时 使用pos的时候 强转 为 (int)
如果不强转pos , 也会异常 , 以为当等式两边的类型不同的时候 , 会发生整形提升(范围小的一般会向范围大的提升) 。我们为了和库里的string保持一致(因为手搓string的目的就是更好的了解string的底层实现逻辑) , pos就保持size_t 的类型 , 因为pos不可能为 负值 , 所以这里我们使用强转解决这一个问题 。
void string::insert(size_t pos, char ch){assert(pos <= _size);if (_size == _capacity){reserve(_capacity == 0 ? 4 : 2 * _capacity);}int end = _size;while (end >= (int)pos){_str[end + 1] = _str[end];--end;}_str[pos] = ch;_size++;}
方案二 : 从 _size + 1 的位置拿前面的数 , 但pos == end的时候跳出循环。(此时pos 和 end的类型均可保持为 size_t )
void string::insert(size_t pos, char ch){assert(pos <= _size);if (_size == _capacity){reserve(_capacity == 0 ? 4 : 2 * _capacity);}size_t end = _size + 1;while (end > pos){_str[end] = _str[end-1];--end;}_str[pos] = ch;_size++;}
插入一个字符串:
void string::insert(size_t pos, const char* str){assert(pos <= _size);size_t len = strlen(str);if (_size + len > _capacity){size_t newCapacity = 2 * _capacity;if (newCapacity < _size + len)newCapacity = _size + len;reserve(newCapacity);}size_t end = _size + len;while (end > pos + len - 1){_str[end] = _str[end - len];--end;}for (size_t i = 0; i < len; i++){_str[pos + i] = str[i];}_size += len;}insert 尽量少用 , 效率比较低,代价比较高。
同时,实现了insert ,我们可以在push_back 和 append里复用 。

3.3 删除数据

首先我们要声明定义 npos , 他是一个静态的const 的遍历 , 静态变量我们是在类里面声明 , 类外定义 。
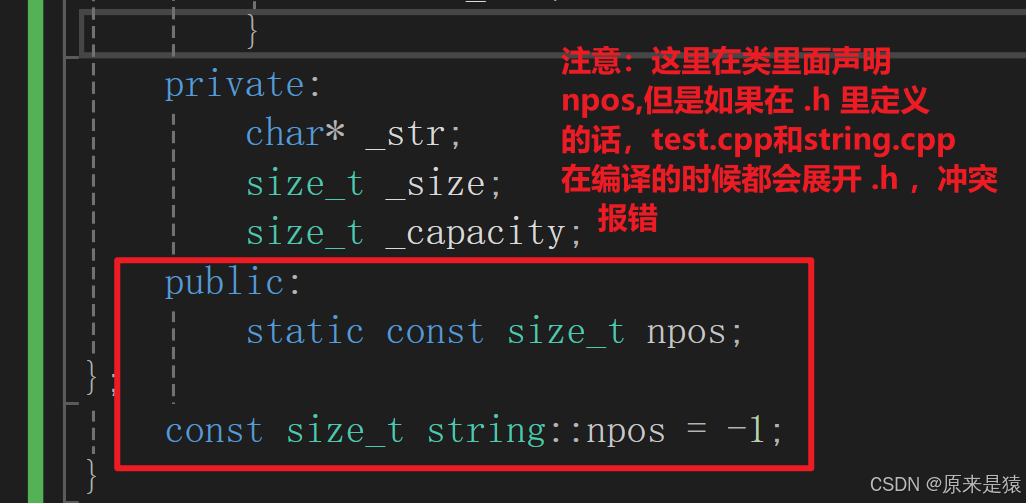

所以我们在 .h 的类里面声明 npos , 在 .cpp文件里面定义 npos !!!! 其实,对于 npos ... VS给了一个特殊权 , 可以在声明的时候给缺省值!!!(不是给初始化列表的哈,就相当于定义)

当删除的数据个数 len , 大于等于 _size - pos 的时候 , 直接在 pos的位置为 '\0' 即可 ;否则就把剩下的数据往前挪动 。
void string::erase(size_t pos, size_t len)
{assert(pos < _size);if (len >= _size - pos){_str[pos] = '\0';_size = pos;}else{size_t end = pos + len;while (end <= _size){_str[end - len] = _str[end];end++;}_size -= len;}
}
四、String operations
4.1 find
查找字符
size_t string::find(char ch, size_t pos){assert(pos < _size);for (size_t i = pos; i < _size; i++){if (ch == _str[i])return i;}return npos;}查找字符串
其实字符串匹配的算法有KMP 和 BM 算法 ,这里我们就不特地来用这些算法了,感兴趣的可以查询一下!这里我们使用 C 库的字符串匹配函数 。

size_t string::find(const char* str, size_t pos = 0)
{assert(pos < _size);const char* ptr = strstr(_str + pos, str);if (ptr == nullptr){return npos;}//拿到指针,期望拿到下标,指针相减else{return ptr - _str;}
}测试:
void test_string4()
{LF::string s1 = "hello world!";cout << s1.c_str() << endl;cout << s1.find(' ') << endl;cout << s1.find("wor") << endl;}4.2 substr

所以这里想要实现 substr , 就不可避免的要谈论深浅拷贝 !
4.2.1 浅拷贝
浅拷贝:也称 位拷贝 , 编译器只是将对象中的值拷贝过来 。 如果对象中管理资源 , 最后就会导致多个对象共用一份资源 , 当一个对象销毁时就会将该资源释放掉 , 而此时另一些对象不知道该资源已经被释放,以为还有效 ,所以当继续对资源进行项操作时,就会发生访问违规。
造成的问题可以总结为:
1)一个对象被析构多次
2) 一个对象的值被修改 , 影响另一个对象
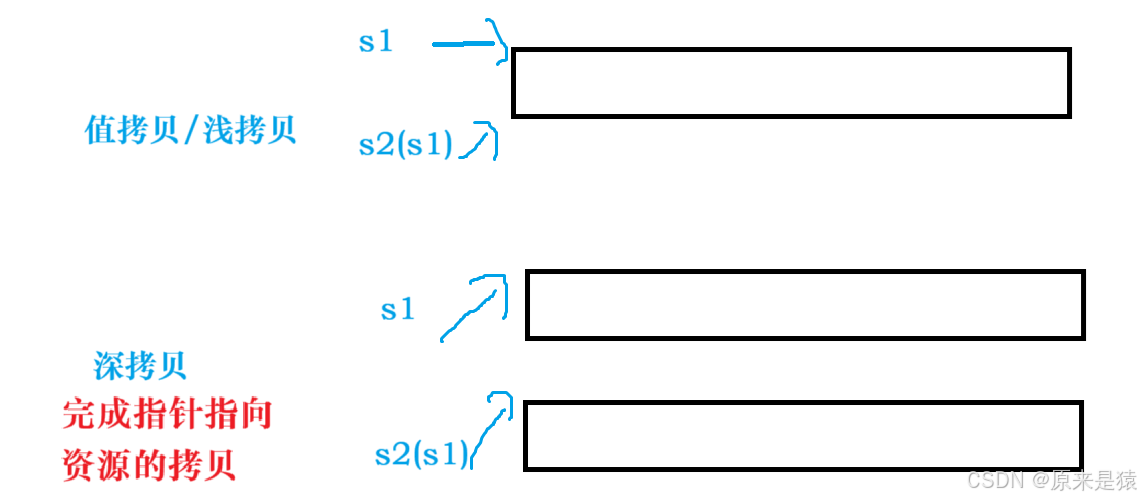
4.2.2 深拷贝
深拷贝:编译器 把对象中的值和资源一并拷贝过来 。
如果一个类中涉及到资源的管理,其拷贝构造函数 、 赋值运算符重载 以及析构函数必须要显示给出 。 一般都是按照深拷贝方式提供。
优点:
1. 每个对象都有独立的内存 , 修改不会互相影响。
2. 析构时不会因重复释放内存而崩溃。

string::string(const string& s){_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}所以,有了拷贝构造之后,我们就能实现substr() ;
string string::substr(size_t pos, size_t len){assert(pos < _size);//大于后面剩余串的长度,则直接取到结尾if (len > (_size - pos)){len = _size - pos;}LF::string sub; sub.reserve(len);for (size_t i = 0; i < len; i++){sub += _str[pos+i];}return sub;}测试:
void test_string5()
{LF::string s1 = "https://blog.csdn.net/khjjjgd/article/details/144165992?spm=1001.2014.3001.5502";size_t pos1 = s1.find(':');size_t pos2 = s1.find('/', pos1 + 3);if (pos1 != string::npos && pos2 != string::npos){LF::string domain = s1.substr(pos1 + 3, pos2 - (pos1 + 3));cout << domain.c_str() << endl;}
}4.3 赋值重载
经过上面的深浅拷贝的介绍 , 赋值这块也需要深拷贝 , 否则会导致内存泄露的问题。

//s1 = s2//this = s//两个已经存在的对象string& string::operator=(const string& s){delete[] _str;_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;return *this;}
测试:
void test_string6()
{LF::string s1("hello world");LF::string s2("xxxxxxxxxxxxxxxxxxx");cout << s1.c_str() << endl;cout << s2.c_str() << endl;s1 = s2;cout << s1.c_str() << endl;cout << s2.c_str() << endl;}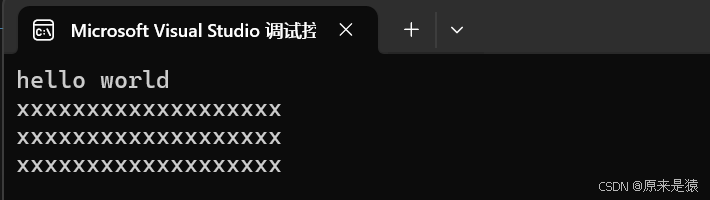
注意:自己和自己赋值,出现随机值 !
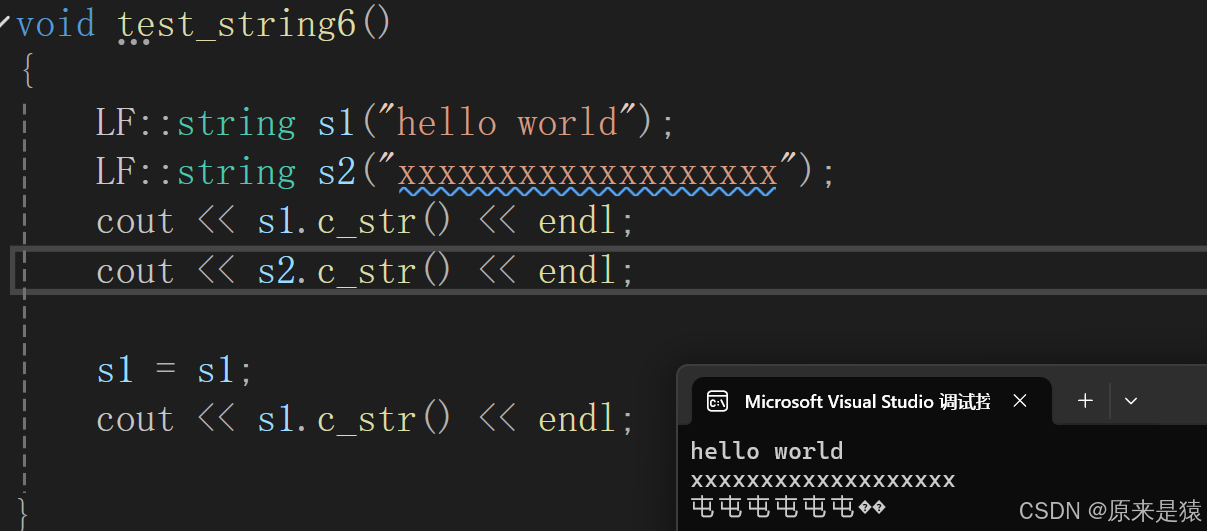
因为一开始就把原空间给释放了 。所以出现随机值。一般来说我们很少会自己给自己赋值,但是语法上是支持自己给自己赋值,不排除有人需要自己给自己赋值 。
string& string::operator=(const string& s){if (this != &s){delete[] _str;_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}return *this;}五、Non-member function overloads
5.1 关系操作符
实现成全局函数 , 主要 希望 支持 string 和 string 的比较 , string 和字符串的比较 。
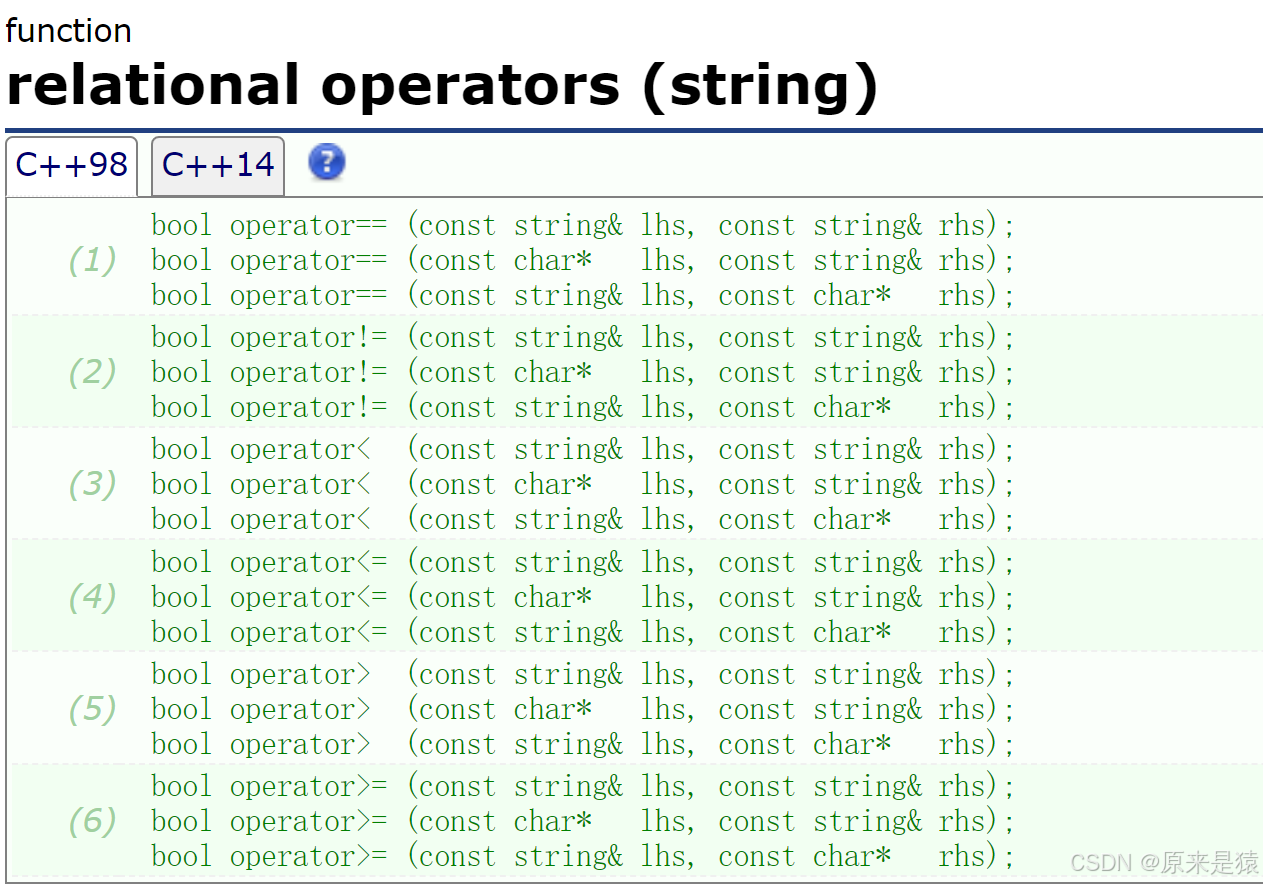
这里我们使用库里的strcmp来实现 (str1 < str2 返回小于 0 .....)。与日期类类似 , 我们只需要实现 小于 , 等于 , 小于等于 , 其余的都可以通过这三者复用实现 。

//字典序比较bool operator==(const string& lhs, const string& rhs){return strcmp(lhs.c_str(), rhs.c_str()) == 0;}bool operator!=(const string& lhs, const string& rhs){return !(lhs == rhs);}bool operator>(const string& lhs, const string& rhs){return !(lhs <= rhs);}bool operator<(const string& lhs, const string& rhs){return (strcmp(lhs.c_str(), rhs.c_str()) < 0);}bool operator>=(const string& lhs, const string& rhs){return !(lhs < rhs);}bool operator<=(const string& lhs, const string& rhs){return !(lhs == rhs || lhs < rhs);}5.2 << 和 >>
1) 流插入 <<
ostream& operator<< (ostream& os, const string& str){for (size_t i = 0; i < str.size(); i++){os << str[i];}return os;}2) 流提取 >>
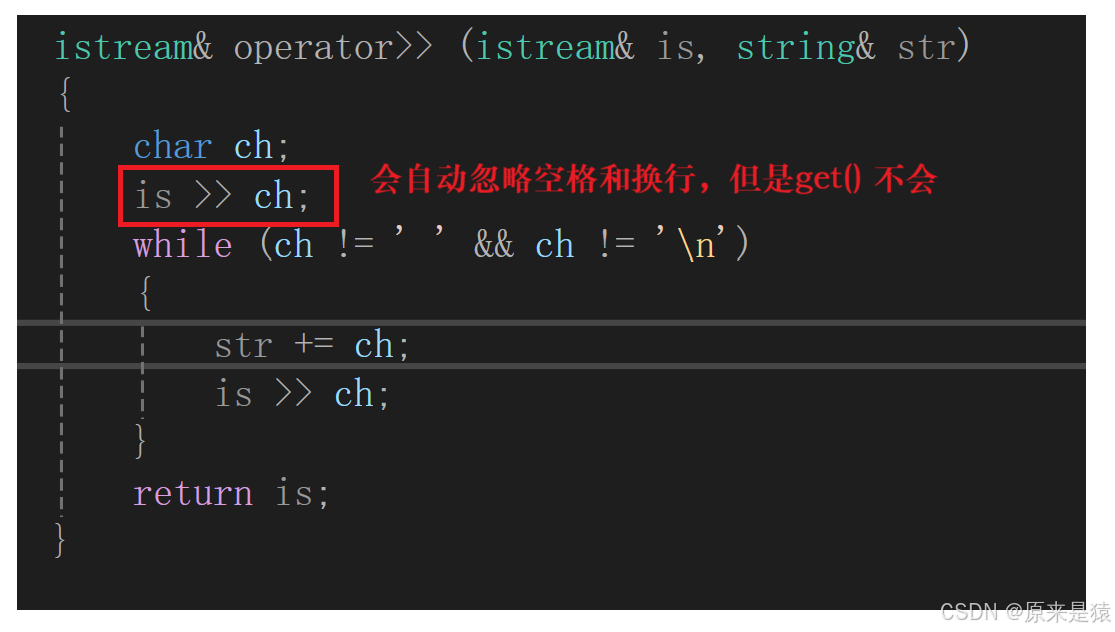
但是这里还是存在一点问题。
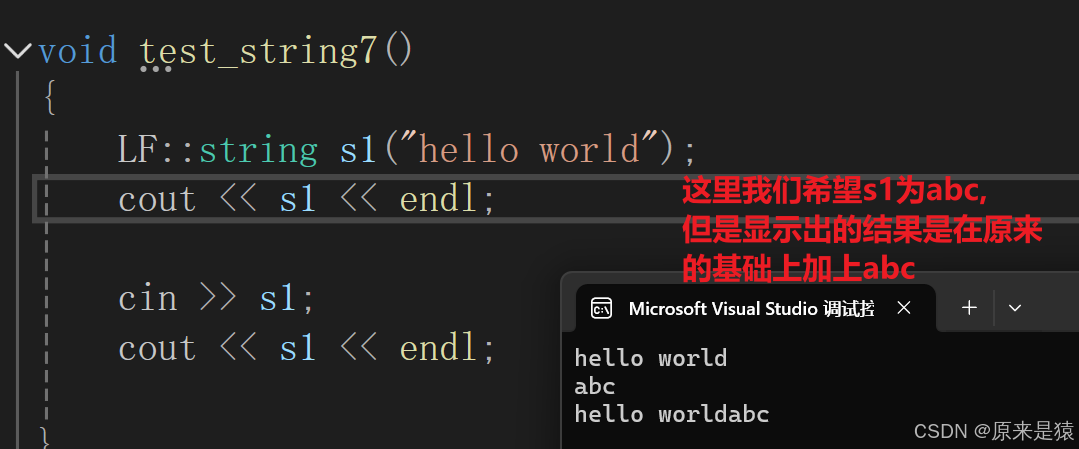
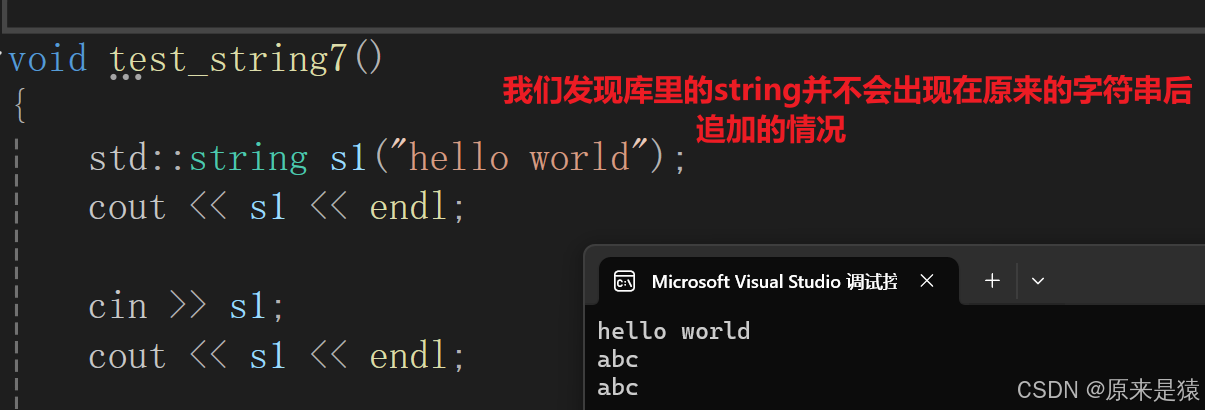
所以需要调用 clear() 函数 , 清除数据 !
//string的成员函数void clear(){_str[0] = '\0';_size = 0;} istream& operator>> (istream& is, string& str){str.clear();char ch;//is >> ch;ch = is.get();while (ch != ' ' && ch != '\n'){str += ch;ch = is.get();}return is;}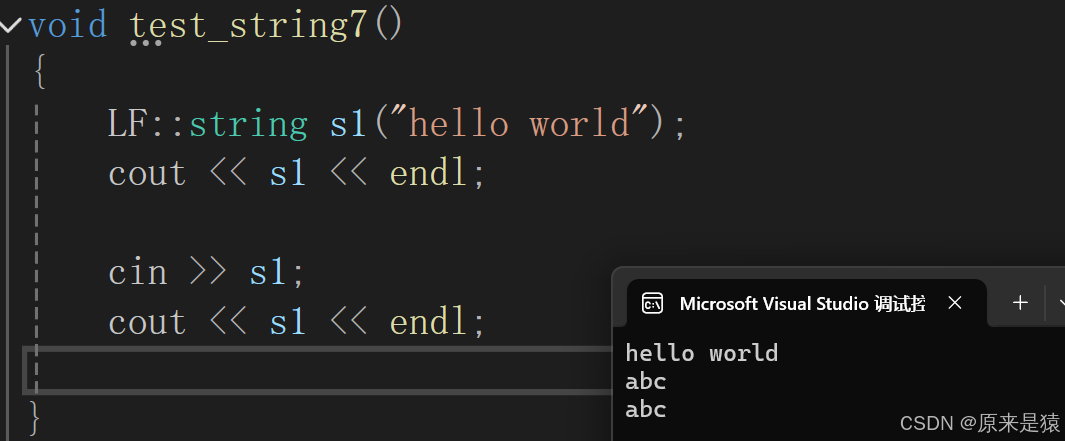
如果我们输入的数据比较大 , 会频繁扩容 , 这里我们可以采用预留一部分空间的方法来优化一下 流提取 。因为再栈上开空间的效率比再堆上高!
istream& operator>> (istream& is, string& str)
{str.clear();int i = 0;char buff[256];char ch;ch = is.get();while (ch != ' ' && ch != '\n'){//先放在buffbuff[i++] = ch;if (i == 255){buff[i] = '\0';str += buff;i = 0;}ch = is.get();}if (i > 0){buff[i] = '\0';str += buff;}return is;
}5.3 getline
和流提取 >> 的逻辑差不多 , 不同的就是getline 可以指定结束标志的字符
istream& getline(istream& is, string& str, char delim ){str.clear();int i = 0;char buff[256];char ch;ch = is.get();while (ch != delim){//先放在buffbuff[i++] = ch;if (i == 255){buff[i] = '\0';str += buff;i = 0;}ch = is.get();}if (i > 0){buff[i] = '\0';str += buff;}return is;}
六、总代码
string.cpp
#include"string.h"namespace LF
{const size_t string::npos = -1;string::string(const char* str):_size(strlen(str)){_capacity = _size;_str = new char[_size + 1];strcpy(_str, str);}string::string(const string& s){_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}//s1 = s2//this = s//两个已经存在的对象string& string::operator=(const string& s){if (this != &s){delete[] _str;_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}return *this;}string::~string(){delete[] _str;_str = nullptr;_size = 0;_capacity = 0;}void string::reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}//void string::push_back(char ch)//{// if (_size == _capacity)// {// reserve(_capacity == 0 ? 4 : 2 * _capacity);// }// _str[_size] = ch;// ++_size;//}void string::push_back(char ch){insert(_size, ch);}void string::append(const char* str){size_t len = strlen(str);if (_size + len > _capacity){size_t newCapacity = 2 * _capacity;//扩2倍不够,则需要多少则扩多少if (newCapacity < _size + len)newCapacity = _size + len;reserve(newCapacity);}strcpy(_str + _size, str);_size += len;}string& string::operator+=(char ch){push_back(ch);return *this;}string& string::operator+=(const char* str){append(str);return *this;}void string::insert(size_t pos, char ch){assert(pos <= _size);if (_size == _capacity){reserve(_capacity == 0 ? 4 : 2 * _capacity);}size_t end = _size + 1;while (end > pos){_str[end] = _str[end-1];--end;}_str[pos] = ch;_size++;}void string::insert(size_t pos, const char* str){assert(pos <= _size);size_t len = strlen(str);if (_size + len > _capacity){size_t newCapacity = 2 * _capacity;if (newCapacity < _size + len)newCapacity = _size + len;reserve(newCapacity);}size_t end = _size + len;while (end > pos + len - 1){_str[end] = _str[end - len];--end;}for (size_t i = 0; i < len; i++){_str[pos + i] = str[i];}_size += len;}void string::erase(size_t pos, size_t len){assert(pos < _size);if (len >= _size - pos){_str[pos] = '\0';_size = pos;}else{size_t end = pos + len;while (end <= _size){_str[end - len] = _str[end];end++;}_size -= len;}}size_t string::find(char ch, size_t pos){assert(pos < _size);for (size_t i = pos; i < _size; i++){if (ch == _str[i])return i;}return npos;}// KMP BMsize_t string::find(const char* str, size_t pos){assert(pos < _size);const char* ptr = strstr(_str + pos, str);if (ptr == nullptr){return npos;}//拿到指针,期望拿到下标,指针相减else{return ptr - _str;}}string string::substr(size_t pos, size_t len){assert(pos < _size);//大于后面剩余串的长度,则直接取到结尾if (len > (_size - pos)){len = _size - pos;}LF::string sub; sub.reserve(len);for (size_t i = 0; i < len; i++){sub += _str[pos+i];}return sub;}//字典序比较bool operator==(const string& lhs, const string& rhs){return strcmp(lhs.c_str(), rhs.c_str()) == 0;}bool operator!=(const string& lhs, const string& rhs){return !(lhs == rhs);}bool operator>(const string& lhs, const string& rhs){return !(lhs <= rhs);}bool operator<(const string& lhs, const string& rhs){return (strcmp(lhs.c_str(), rhs.c_str()) < 0);}bool operator>=(const string& lhs, const string& rhs){return !(lhs < rhs);}bool operator<=(const string& lhs, const string& rhs){return !(lhs == rhs || lhs < rhs);}ostream& operator<< (ostream& os, const string& str){for (size_t i = 0; i < str.size(); i++){os << str[i];}return os;}istream& operator>> (istream& is, string& str){str.clear();int i = 0;char buff[256];char ch;ch = is.get();while (ch != ' ' && ch != '\n'){//先放在buffbuff[i++] = ch;if (i == 255){buff[i] = '\0';str += buff;i = 0;}ch = is.get();}if (i > 0){buff[i] = '\0';str += buff;}return is;}istream& getline(istream& is, string& str, char delim ){str.clear();int i = 0;char buff[256];char ch;ch = is.get();while (ch != delim){//先放在buffbuff[i++] = ch;if (i == 255){buff[i] = '\0';str += buff;i = 0;}ch = is.get();}if (i > 0){buff[i] = '\0';str += buff;}return is;}
}string.h
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<assert.h>
using namespace std;namespace LF
{class string{public://typedef char* iterator;using iterator = char*;using const_itertor = const char*;string(const char* str = "");string(const string& s);string& operator=(const string& s);~string();void reserve(size_t n);void push_back(char ch);void append(const char* str);string& operator+=(char ch);string& operator+=(const char* str);void insert(size_t pos, char ch);void insert(size_t pos, const char* str);void erase(size_t pos, size_t len = npos);size_t find(char ch,size_t pos = 0);size_t find(const char* str,size_t pos = 0);string substr(size_t pos, size_t len = npos);char& operator[](size_t i){assert(i < _size);return _str[i];}const char& operator[](size_t i) const{assert(i < _size);return _str[i];}iterator begin(){return _str;}iterator end(){return _str + _size;}const_itertor begin() const{return _str;}const_itertor end() const{return _str + _size;}size_t size() const{return _size;}const char* c_str()const{return _str;}void clear(){_str[0] = '\0';_size = 0;}private:char* _str;size_t _size;size_t _capacity;public:static const size_t npos ;};bool operator==(const string& lhs, const string& rhs);bool operator!=(const string& lhs, const string& rhs);bool operator>(const string& lhs, const string& rhs);bool operator<(const string& lhs, const string& rhs);bool operator>=(const string& lhs, const string& rhs);bool operator<=(const string& lhs, const string& rhs);ostream& operator<< (ostream& os, const string& str);istream& operator>> (istream& is, string& str);istream& getline(istream& is, string& str, char delim = '\n');
}
test.cpp
#include"string.h"void test_string1()
{LF::string s1("hello world!");cout << s1.c_str() << endl;//下标 + [ ]for (size_t i = 0; i < s1.size(); i++){cout << s1[i] << " ";}cout << endl;//迭代器LF::string::iterator it1 = s1.begin();while (it1 != s1.end()){cout << *it1 << " ";++it1;}cout << endl;//范围forfor (auto& ch : s1){cout << ch << " ";}cout << endl;}void test_string2()
{LF::string s1 = "hello";cout << s1.c_str() << endl;s1.push_back(',');cout << s1.c_str() << endl;s1.append("world");cout << s1.c_str() << endl;s1 += '!';cout << s1.c_str() << endl;s1 += "hahaha";cout << s1.c_str() << endl;}void test_string3()
{LF::string s1 = "hello world!";cout << s1.c_str() << endl;s1.insert(6, 'x');cout << s1.c_str() << endl;s1.insert(0, 'x');cout << s1.c_str() << endl;s1.insert(0,"yyyyy");cout << s1.c_str() << endl;s1.erase(0, 1);cout << s1.c_str() << endl;s1.erase(8, 20);cout << s1.c_str() << endl;
}void test_string4()
{LF::string s1 = "hello world!";cout << s1.c_str() << endl;cout << s1.find(' ') << endl;cout << s1.find("wor") << endl;}void test_string5()
{LF::string s1 = "https://blog.csdn.net/khjjjgd/article/details/144165992?spm=1001.2014.3001.5502";size_t pos1 = s1.find(':');size_t pos2 = s1.find('/', pos1 + 3);if (pos1 != string::npos && pos2 != string::npos){LF::string domain = s1.substr(pos1 + 3, pos2 - (pos1 + 3));cout << domain.c_str() << endl;}
}void test_string6()
{LF::string s1("hello world");LF::string s2("xxxxxxxxxxxxxxxxxxx");cout << s1.c_str() << endl;cout << s2.c_str() << endl;s1 = s1;cout << s1.c_str() << endl;}void test_string7()
{LF::string s1("hello world");cout << s1 << endl;cin >> s1;cout << s1 << endl;}int main()
{//test_string1();//test_string2();//test_string3();//test_string4();//test_string5();//test_string6();test_string7();return 0;
}