OpenCV 官翻 3 - 特征检测 Feature Detection
文章目录
- 理解特征
- 目标
- 解释
- Harris角点检测
- 目标
- 理论
- OpenCV 中的 Harris 角点检测器
- 亚像素级精度角点检测
- 练习
- Shi-Tomasi角点检测器与优质跟踪特征
- 目标
- 理论基础
- 代码
- SIFT(尺度不变特征变换)简介
- 目标
- 理论
- 1、尺度空间极值检测
- 2、关键点定位
- 3、方向分配
- 4、关键点描述符
- 5、关键点匹配
- OpenCV 中的 SIFT 算法
- SURF(加速稳健特征)简介
- 目标
- 理论
- OpenCV 中的 SURF 算法
- FAST角点检测算法
- 目标
- 理论背景
- 使用FAST算法进行特征检测
- 机器学习角点检测器
- 非极大值抑制
- 概述
- OpenCV中的FAST特征检测器
- 附加资源
- BRIEF(二进制鲁棒独立基本特征)
- 目标
- 理论基础
- OpenCV中的STAR(CenSurE)特征检测器
- OpenCV中的BRIEF描述符
- 补充资源
- ORB (定向FAST与旋转BRIEF)
- 目标
- 理论基础
- OpenCV 中的 ORB 特征检测
- 附加资源
- 特征匹配
- 目标
- 暴力匹配器基础
- 使用ORB描述符进行暴力匹配
- 什么是这个匹配器对象?
- 基于 SIFT 描述符与比率测试的暴力匹配
- 基于FLANN的匹配器
- 特征匹配与单应性变换实现物体查找
- 目标
- 基础概念
- 代码
理解特征
https://docs.opencv.org/4.x/df/d54/tutorial_py_features_meaning.html
目标
在本章中,我们将尝试理解什么是特征、为什么特征很重要,以及为什么角点很重要等内容。
解释
大多数人都玩过拼图游戏。你会得到一张图像分割成的许多小块,需要正确组装它们以形成完整的大图。问题在于,你是如何做到的? 能否将同样的原理应用到计算机程序中,让计算机也能玩拼图?如果计算机能玩拼图,为什么我们不能给它许多自然风景的真实照片,让它将这些图像拼接成一张大图呢?如果计算机能将多张自然图像拼接成一张,那么给它大量建筑物或结构的照片,让它创建出3D模型又如何呢?
这些问题和想象不断延伸。但一切都取决于最基本的问题:你如何玩拼图?如何将许多打乱的图像碎片排列成一张完整的大图?如何将多张自然图像拼接成一张?
答案是,我们寻找那些独特、易于追踪和比较的特定模式或特征。如果要给这样的特征下定义,可能很难用语言表达,但我们知道它们是什么。如果有人让你指出一个可以在多张图像间比较的好特征,你一定能指出来。这就是为什么连小孩子都能轻松玩这类游戏。我们在图像中搜索这些特征,找到它们,在其他图像中寻找相同的特征并进行对齐。就这样(在拼图中,我们更关注不同图像间的连续性)。这些能力是我们与生俱来的。
因此,我们的基本问题扩展为更多具体问题:这些特征是什么?(答案也必须是计算机能理解的)。
很难说人类是如何找到这些特征的。这已经编码在我们的大脑中。但如果我们深入观察一些图片并搜索不同模式,会发现一些有趣的东西。例如,看下面这张图:

这张图非常简单。顶部给出了六个小图像块,问题是找出它们在原图中的精确位置。你能找到多少个正确结果?
A和B是平坦区域,覆盖范围很大,很难精确定位这些小块的位置。
C和D则简单得多。它们是建筑物的边缘。你可以找到大致位置,但精确位置仍较难确定,因为边缘上的模式是相同的。但在边缘处,模式会发生变化。因此,边缘比平坦区域是更好的特征,但仍不够理想(在拼图中,边缘适合比较连续性)。
最后,E和F是建筑物的角落,很容易找到。因为无论在哪个角落移动这些小块,看起来都会不同。所以它们可以被视为好的特征。现在我们来看一张更简单(且广泛使用的图像)以便更好理解:
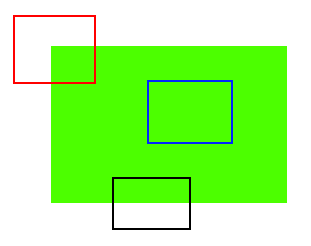
与上面类似,蓝色块是平坦区域,难以找到和追踪。无论怎么移动蓝色块,看起来都一样。黑色块有一条边缘。如果沿垂直方向(即梯度方向)移动,它会变化;如果沿边缘平行移动,看起来则相同。红色块是一个角落,无论怎么移动,看起来都不同,意味着它是唯一的。因此,角落被认为是图像中的好特征(不仅是角落,在某些情况下斑点也被视为好特征)。
现在我们已经回答了"这些特征是什么?"的问题。但下一个问题出现了:如何找到它们?或者说如何找到角落?我们以直观的方式回答了这个问题,即在图像中寻找那些在周围所有区域移动(小幅移动)时变化最大的区域。这将在后续章节中转化为计算机语言。因此,寻找这些图像特征被称为特征检测。
我们在图像中找到了特征。一旦找到,你应该能在其他图像中找到相同的特征。这是如何做到的?我们围绕特征选取一个区域,用自己的语言描述它,比如"上部是蓝天,下部是建筑物区域,建筑物上有玻璃等",然后在其他图像中搜索相同区域。本质上,你是在描述特征。同样,计算机也应该描述特征周围的区域,以便在其他图像中找到它。这种描述被称为特征描述。一旦有了特征及其描述,你就可以在所有图像中找到相同的特征,并对齐、拼接它们或进行其他操作。
因此,在本模块中,我们将探讨OpenCV中的不同算法来寻找特征、描述它们、匹配它们等。
生成于 2025年4月30日 星期三 23:08:42,由 doxygen 1.12.0 生成
Harris角点检测
https://docs.opencv.org/4.x/dc/d0d/tutorial_py_features_harris.html
目标
在本章中,
- 我们将理解 Harris 角点检测背后的概念。
- 我们将学习以下函数:
cv.cornerHarris()、cv.cornerSubPix()
理论
在上一章中,我们了解到角点是图像中所有方向上强度变化剧烈的区域。Chris Harris 和 Mike Stephens 在1988年的论文《A Combined Corner and Edge Detector》中首次尝试寻找这些角点,因此该方法现在被称为 Harris 角点检测器。他们将这一简单想法转化为数学形式,本质上是通过计算位移 \((u,v)\) 在各个方向上的强度差异来实现。其数学表达式如下:
\[E(u,v) = \sum_{x,y} \underbrace{w(x,y)}\text{窗口函数} \, [\underbrace{I(x+u,y+v)}\text{平移后强度}-\underbrace{I(x,y)}_\text{原始强度}]^2\]
窗口函数可以是矩形窗口或高斯窗口,用于为下方像素赋予权重。
为了检测角点,我们需要最大化函数 \(E(u,v)\),即最大化第二项。通过对上述方程应用泰勒展开并进行数学推导(完整推导过程可参考任何标准教材),最终得到:
\[E(u,v) \approx \begin{bmatrix} u & v \end{bmatrix} M \begin{bmatrix} u \\ v \end{bmatrix}\]
其中
\[M = \sum_{x,y} w(x,y) \begin{bmatrix}I_x I_x & I_x I_y \\
I_x I_y & I_y I_y \end{bmatrix}\]
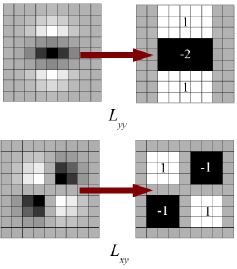
这里,\(I_x\) 和 \(I_y\) 分别是图像在x和y方向上的导数(可通过 cv.Sobel() 轻松计算)。
接下来是关键部分:他们构建了一个评分方程,用于判断窗口是否包含角点:
\[R = \det(M) - k(\operatorname{trace}(M))^2\]
其中
- \(\det(M) = \lambda_1 \lambda_2\)
- \(\operatorname{trace}(M) = \lambda_1 + \lambda_2\)
- \(\lambda_1\) 和 \(\lambda_2\) 是矩阵 \(M\) 的特征值
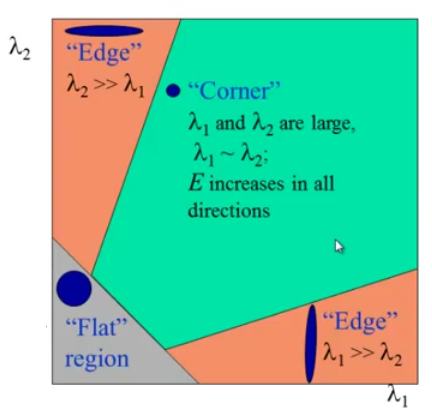
通过特征值的大小可以判定区域类型:
- 当 \(|R|\) 较小(即 \(\lambda_1\) 和 \(\lambda_2\) 都较小时),该区域为平坦区域;
- 当 \(R<0\)(即 \(\lambda_1 >> \lambda_2\) 或相反情况时),该区域为边缘;
- 当 \(R\) 较大(即 \(\lambda_1\) 和 \(\lambda_2\) 都较大且近似相等时),该区域为角点。
这一关系可通过下图直观表示:
Harris角点检测的结果是一幅包含这些评分的灰度图像。通过设定合适的阈值筛选评分,即可得到图像中的角点。我们将通过简单图像进行演示。
OpenCV 中的 Harris 角点检测器
OpenCV 提供了 cv.cornerHarris() 函数来实现这一功能。其参数说明如下:
- img - 输入图像,需为灰度图且类型为 float32
- blockSize - 角点检测时考虑的邻域大小
- ksize - 所用 Sobel 算子的孔径参数
- k - Harris 检测器方程中的自由参数
参考以下示例:
import numpy as np
import cv2 as cvfilename = 'chessboard.png'
img = cv.imread(filename)
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)gray = np.float32(gray)
dst = cv.cornerHarris(gray,2,3,0.04)#result is dilated for marking the corners, not important
dst = cv.dilate(dst,None)# Threshold for an optimal value, it may vary depending on the image.
img[dst>0.01*dst.max()]=[0,0,255]cv.imshow('dst',img)
if cv.waitKey((0) \& 0xff == 27:cv.destroyAllWindows()
以下是三个结果:

亚像素级精度角点检测
有时您可能需要以最高精度定位角点。OpenCV提供了 cv.cornerSubPix() 函数,可对检测到的角点进行亚像素级精度的优化。以下是一个示例:
首先需要检测Harris角点,然后将这些角点的质心(一个角点可能包含多个像素点,我们取其质心)传入函数进行优化。图中红色像素标记的是Harris角点,绿色像素标记的是优化后的角点。
使用该函数时,需要定义迭代终止条件。当达到指定迭代次数或满足特定精度要求时(以先达到的条件为准),迭代将停止。此外,还需定义搜索角点的邻域大小。
import numpy as np
import cv2 as cvfilename = 'chessboard2.jpg'
img = cv.imread(filename)
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)# find Harris corners
gray = np.float32(gray)
dst = cv.cornerHarris(gray,2,3,0.04)
dst = cv.dilate(dst,None)
ret, dst = cv.threshold(dst,0.01*dst.max(),255,0)
dst = np.uint8(dst)# find centroids
ret, labels, stats, centroids = [cv.connectedComponentsWithStats`](https://docs.opencv.org/4.x/d3/dc0/group__imgproc__shape.html#ga107a78bf7cd25dec05fb4dfc5c9e765f)(dst)# define the criteria to stop and refine the corners
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 100, 0.001)
corners = [cv.cornerSubPix`](https://docs.opencv.org/4.x/dd/d1a/group__imgproc__feature.html#ga354e0d7c86d0d9da75de9b9701a9a87e)(gray,np.float32(centroids),(5,5),(-1,-1),criteria)# Now draw them
res = np.hstack((centroids,corners))
res = np.int0(res)
img[res[:,1],res[:,0]]=[0,0,255]
img[res[:,3],res[:,2]] = [0,255,0]cv.imwrite('subpixel5.png',img)
以下是结果展示,其中放大窗口内标注了若干关键位置以便观察:
练习
由 doxygen 1.12.0 生成于 2025年4月30日 星期三 23:08:42,适用于 OpenCV
Shi-Tomasi角点检测器与优质跟踪特征
https://docs.opencv.org/4.x/d4/d8c/tutorial_py_shi_tomasi.html
目标
在本章中,
- 我们将学习另一种角点检测器:Shi-Tomasi角点检测器
- 我们将了解函数:
cv.goodFeaturesToTrack()
理论基础
在上一章中,我们学习了Harris角点检测器。1994年,J. Shi和C. Tomasi在其论文**《Good Features to Track》**中对该算法进行了小幅改进,相比Harris角点检测器取得了更好的效果。Harris角点检测器中的评分函数定义为:
\[R = \lambda_1 \lambda_2 - k(\lambda_1+\lambda_2)^2\]
而Shi-Tomasi算法将其改进为:
\[R = \min(\lambda_1, \lambda_2)\]
当该值大于设定阈值时,即判定为角点。若我们在\(\lambda_1 - \lambda_2\)空间中进行可视化(如同Harris角点检测器中的做法),可得到如下图像:
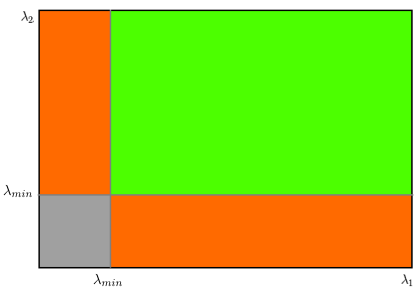
从图中可见,只有当\(\lambda_1\)和\(\lambda_2\)均超过最小值\(\lambda_{\min}\)时,该区域才会被判定为角点(绿色区域)。
代码
OpenCV 提供了一个函数 cv.goodFeaturesToTrack()。该函数通过 Shi-Tomasi 方法(或 Harris 角点检测,如果指定的话)在图像中寻找 N 个最强的角点。通常,图像应为灰度图像。你需要指定要查找的角点数量,以及一个 0-1 之间的质量等级参数,该参数表示角点的最低质量阈值,低于此阈值的角点将被舍弃。此外,还需提供检测到的角点之间的最小欧氏距离。
基于这些信息,函数会在图像中寻找角点。所有低于质量阈值的角点会被舍弃,剩余的角点按质量降序排序。然后函数选取最强的角点,舍弃最小距离范围内的邻近角点,最终返回 N 个最强角点。
在下面的示例中,我们将尝试找出 25 个最佳角点:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as pltimg = cv.imread('blox.jpg')
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)corners = cv.goodFeaturesToTrack(gray,25,0.01,10)
corners = np.int0(corners)for i in corners:x,y = i.ravel()cv.circle(img,(x,y),3,255,-1)plt.imshow(img),plt.show()
查看下方结果:

该函数更适合用于追踪场景,我们将在后续相关部分具体展开说明。
生成于 2025年4月30日 星期三 23:08:42,由 doxygen 1.12.0 为 OpenCV 生成
SIFT(尺度不变特征变换)简介
https://docs.opencv.org/4.x/da/df5/tutorial_py_sift_intro.html
目标
在本章节中,
- 我们将学习SIFT算法的核心概念
- 我们将掌握如何检测SIFT关键点并提取描述符
理论
在前几章中,我们学习了一些角点检测器,如Harris角点检测等。它们具有旋转不变性,这意味着即使图像旋转,我们仍能找到相同的角点。这很直观,因为旋转后的图像中角点依然是角点。但缩放呢?如果图像被缩放,一个角点可能就不再是角点了。例如,观察下面这张简单的图片。在小图像中某个窗口内的角点,当放大到相同窗口时可能就变成了平坦区域。因此,Harris角点不具备尺度不变性。
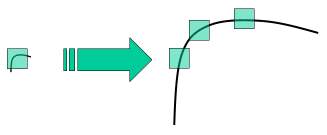
2004年,英属哥伦比亚大学的D.Lowe在其论文《尺度不变关键点的独特图像特征》中提出了一种新算法——尺度不变特征变换(SIFT),该算法能够提取关键点并计算其描述符。(这篇论文易于理解,被认为是关于SIFT的最佳资料。这里的解释只是对该论文的简要概述)。
SIFT算法主要包含四个步骤,我们将逐一介绍。
1、尺度空间极值检测
从上面的图像可以明显看出,我们无法使用相同的窗口来检测不同尺度的关键点。对于小角点没有问题,但要检测更大的角点就需要更大的窗口。为此,我们采用尺度空间滤波技术。该方法通过计算图像在不同σ\sigmaσ值下的高斯拉普拉斯算子(LoG)。由于σ\sigmaσ的变化,LoG作为斑点检测器可以识别不同尺寸的斑点。简而言之,σ\sigmaσ起到了尺度参数的作用。例如在上图中,低σ\sigmaσ的高斯核对小角点响应强烈,而高σ\sigmaσ的高斯核则更适合大角点。因此,我们可以在尺度和空间上寻找局部极大值,从而得到一系列\((x,y,\sigma)\)值,这意味着在σ\sigmaσ尺度下的(x,y)位置可能存在关键点。
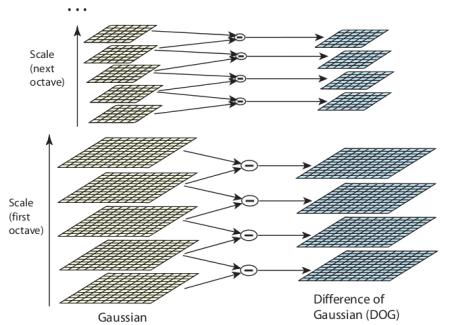
但LoG计算成本较高,因此SIFT算法采用高斯差分(DoG)来近似LoG。高斯差分是通过对图像分别用两个不同σ\sigmaσ(设为σ\sigmaσ和\(k\sigma\))进行高斯模糊后求差得到的。这个过程会在高斯金字塔的不同八度空间中进行。如下图所示:
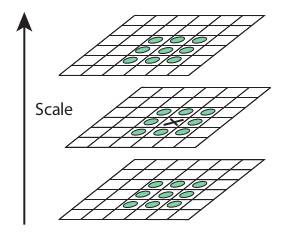
得到DoG后,我们就在不同尺度和空间中搜索局部极值点。例如,将图像中的每个像素与其8个相邻像素、以及相邻尺度上的9+9个像素进行比较。如果它是局部极值点,则视为潜在关键点。这本质上表示该关键点在该尺度下具有最佳表征。如下图所示:
关于参数设置,论文提供了经验数据:最优值为八度空间数=4、尺度层级数=5、初始\(\sigma=1.6\)、\(k=\sqrt{2}\)等。
2、关键点定位
一旦找到潜在的关键点位置,需要对其进行细化以获得更精确的结果。研究者们利用尺度空间的泰勒级数展开来获取极值点的更精确位置,如果该极值点的强度低于阈值(论文中设为0.03),则会被剔除。在OpenCV中,该阈值被称为contrastThreshold。
DoG(差分高斯)对边缘有较强的响应,因此也需要去除边缘点。为此,采用了与Harris角点检测器类似的概念。研究者使用2x2的Hessian矩阵(H)来计算主曲率。根据Harris角点检测器的原理可知,对于边缘点,一个特征值会远大于另一个。因此这里采用了一个简单的判断函数:如果该比值大于某个阈值(OpenCV中称为edgeThreshold),则该关键点会被丢弃。论文中该阈值设为10。
通过这一过程,算法剔除了所有低对比度的关键点和边缘关键点,最终保留的是具有显著特征的点。
3、方向分配
现在为每个关键点分配一个方向,以实现图像旋转不变性。根据关键点的尺度,在其周围选取一个邻域区域,并计算该区域内的梯度幅值和方向。创建一个包含36个柱状区间的方向直方图(覆盖360度范围),该直方图通过梯度幅值和高斯加权圆形窗口(其中σ\sigmaσ等于关键点尺度的1.5倍)进行加权处理。取直方图中的最高峰值,同时任何达到该峰值80%以上的次高峰也会被纳入方向计算。这一过程会生成位置和尺度相同但方向不同的关键点,从而提升匹配的稳定性。
4、关键点描述符
此时关键点描述符已创建完成。具体流程如下:
- 提取关键点周围16x16像素的邻域区域
- 将该区域划分为16个4x4大小的子块
- 为每个子块创建8个方向的梯度直方图
- 最终生成共128维的直方图特征向量作为关键点描述符
此外,还采用了多种措施来确保描述符对光照变化、旋转等因素具有鲁棒性。
5、关键点匹配
通过识别最近邻来匹配两幅图像之间的关键点。但在某些情况下,第二接近的匹配可能与第一接近的匹配非常接近。这可能是由于噪声或其他原因造成的。此时,会计算最接近距离与第二接近距离的比值。如果该比值大于0.8,则拒绝这些匹配点。根据论文所述,这种方法可以消除约90%的错误匹配,同时仅丢弃5%的正确匹配。
以上是SIFT算法的概要。如需了解更多细节和深入理解,强烈建议阅读原始论文。
OpenCV 中的 SIFT 算法
现在让我们看看 OpenCV 提供的 SIFT 功能。需要注意的是,这些功能原先仅存在于 opencv contrib 仓库 中,但由于其专利已在 2020 年过期,因此现在已被纳入主代码库。我们将从关键点检测和绘制开始讲解。
首先需要创建一个 SIFT 对象。我们可以为其传递不同的可选参数,这些参数在文档中都有详细说明。
import numpy as np
import cv2 as cvimg = cv.imread('home.jpg')
gray= cv.cvtColor(img,cv.COLOR_BGR2GRAY)sift = cv.SIFT_create()
kp = sift.detect(gray,None)img=cv.drawKeypoints(gray,kp,img)cv.imwrite('sift_keypoints.jpg',img)sift.detect() 函数用于在图像中寻找关键点。若只需搜索图像的一部分,可以传入掩码参数。每个关键点都是一个特殊结构体,包含多种属性,例如 (x,y) 坐标、有效邻域大小、表示方向的角度、反映关键点强度的响应值等。
OpenCV 还提供了 cv.drawKeyPoints() 函数,可在关键点位置绘制小圆圈。如果传入 cv.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS 标志,函数会绘制与关键点大小匹配的圆圈,并显示其方向。参考以下示例:
查看下方两组结果:

计算描述符时,OpenCV 提供两种方法:
-
若已找到关键点,可调用 sift.compute() 基于现有关键点计算描述符。例如:kp,des = sift.compute(gray,kp)
-
若未检测关键点,可直接通过 sift.detectAndCompute() 函数一步获取关键点和描述符。
我们将演示第二种方法:
sift = cv.SIFT_create()
kp, des = sift.detectAndCompute(gray,None)
这里 kp 将是一个关键点列表,des 是一个形状为 \(\text{(Number of Keypoints)} \times 128\) 的 numpy 数组。
现在我们已经获取了关键点、描述符等信息。接下来我们将学习如何在不同图像中匹配关键点,这部分内容将在后续章节中展开。
生成于 2025年4月30日 星期三 23:08:42,由 doxygen 1.12.0 为 OpenCV 生成
SURF(加速稳健特征)简介
https://docs.opencv.org/4.x/df/dd2/tutorial_py_surf_intro.html
目标
在本章中,
- 我们将了解SURF的基础知识
- 我们将学习OpenCV中的SURF功能
理论
在上一章中,我们学习了用于关键点检测和描述的SIFT算法。但它的速度相对较慢,人们需要更快的版本。2006年,Bay、H.、Tuytelaars、T.和Van Gool、L三人发表了另一篇论文《SURF: Speeded Up Robust Features》,提出了一种名为SURF的新算法。顾名思义,它是SIFT的加速版本。
在SIFT中,Lowe使用高斯差分(Difference of Gaussian)来近似拉普拉斯高斯(Laplacian of Gaussian)以构建尺度空间。SURF更进一步,用盒式滤波器(Box Filter)来近似LoG。下图展示了这种近似方法的示意图。这种近似的一大优势是,盒式滤波器的卷积运算可以借助积分图像轻松计算,并且可以并行处理不同尺度。此外,SURF依赖Hessian矩阵的行列式来确定尺度和位置。
在方向分配阶段,SURF对大小为6s的邻域计算水平和垂直方向的小波响应,并施加适当的高斯权重。然后将这些响应绘制在下图所示的空间中。通过计算60度滑动方向窗口内所有响应的总和来估计主导方向。有趣的是,利用积分图像可以非常容易地在任何尺度下计算小波响应。对于许多不需要旋转不变性的应用场景,可以跳过方向计算步骤,从而加速处理。SURF提供了称为Upright-SURF(U-SURF)的功能,在速度提升的同时能保持对±15°旋转的鲁棒性。OpenCV通过upright标志位支持两种模式:设为0时计算方向,设为1时不计算方向(速度更快)。
在特征描述阶段,SURF使用水平和垂直方向的小波响应(同样借助积分图像简化计算)。取关键点周围20s×20s的邻域(s表示尺度),将其划分为4×4的子区域。每个子区域生成一个向量:\(v=( \sum{d_x}, \sum{d_y}, \sum{|d_x|}, \sum{|d_y|})\),最终形成64维的SURF特征描述符。更低的维度能提高计算和匹配速度,同时保持较好的特征区分度。
为了增强区分度,SURF还提供了128维扩展版本。分别计算\(d_y < 0\)和\(d_y \geq 0\)时的\(d_x\)和\(|d_x|\)之和,类似地根据\(d_x\)的符号对\(d_y\)和\(|d_y|\)进行分组,从而使特征数量翻倍。OpenCV通过extended标志位(0表示64维,1表示128维,默认为128维)支持两种模式。
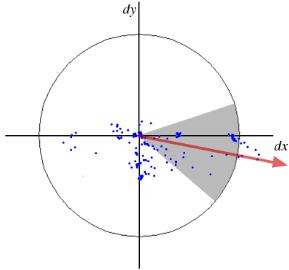
另一个重要改进是利用拉普拉斯算子(Hessian矩阵的迹)的符号信息。由于检测阶段已计算该值,因此不会增加额外开销。拉普拉斯符号可以区分暗背景上的亮斑与相反情况。在匹配阶段,仅对比具有相同对比类型的特征(如下图)。这种方法在不降低描述符性能的前提下加速了匹配过程。
简而言之,SURF通过多项改进提升了各步骤的速度。分析表明其速度比SIFT快3倍,同时保持相当的性能。SURF擅长处理模糊和旋转图像,但在视角变化和光照变化场景下表现不佳。
OpenCV 中的 SURF 算法
OpenCV 提供了与 SIFT 类似的 SURF 功能。您可以通过一些可选条件来初始化 SURF 对象,例如 64/128 维描述符、直立/常规 SURF 等。所有细节在文档中都有详细说明。然后就像我们在 SIFT 中所做的那样,我们可以使用 SURF.detect()、SURF.compute() 等方法来查找关键点和描述符。
首先我们将看到一个简单的演示,展示如何查找 SURF 关键点和描述符并绘制它们。所有示例都在 Python 终端中展示,因为它与 SIFT 的使用方式完全相同。
>>> img = cv.imread('fly.png', cv.IMREAD_GRAYSCALE)# Create SURF object. You can specify params here or later.# Here I set Hessian Threshold to 400
>>> surf = cv.xfeatures2d.SURF_create(400)# Find keypoints and descriptors directly
>>> kp, des = surf.detectAndCompute(img,None)>>> len(kp)699
1199个关键点太多,无法在一张图片中全部显示。我们将其减少到约50个以便在图像上绘制。在匹配时可能需要所有特征点,但现在不需要。因此我们提高了Hessian阈值。
# Check present Hessian threshold
>>> print( surf.getHessianThreshold() )
400.0# We set it to some 50000、Remember, it is just for representing in picture.# In actual cases, it is better to have a value 300-500
>>> surf.setHessianThreshold(50000)# Again compute keypoints and check its number.
>>> kp, des = surf.detectAndCompute(img,None)>>> print( len(kp) )
47
少于50,让我们在图像上绘制它。
>>> img2 = cv.drawKeypoints(img,kp,None,(255,0,0),4)>>> plt.imshow(img2),plt.show()
请查看下方结果。可以看到,SURF 更像是一个斑点检测器。它检测到了蝴蝶翅膀上的白色斑点。你可以用其他图像进行测试。

现在我想应用 U-SURF,这样它就不会检测方向。
# Check upright flag, if it False, set it to True
>>> print( surf.getUpright() )
False>>> surf.setUpright(True)# Recompute the feature points and draw it
>>> kp = surf.detect(img,None)
>>> img2 = cv.drawKeypoints(img,kp,None,(255,0,0),4)>>> plt.imshow(img2),plt.show()
查看下方结果。所有方向都显示为同一朝向,速度比之前更快。如果您处理的场景中方向不是问题(比如全景图拼接等),这种方法更合适。

最后我们检查描述符尺寸,如果仅为64维则将其改为128维。
# Find size of descriptor
>>> print( surf.descriptorSize() )
64# That means flag, "extended" is False.
>>> surf.getExtended()False# So we make it to True to get 128-dim descriptors.
>>> surf.setExtended(True)
>>> kp, des = surf.detectAndCompute(img,None)
>>> print( surf.descriptorSize() )
128
>>> print( des.shape )
(47, 128)
剩余部分将在另一章节中进行匹配处理。
生成于 2025年4月30日 星期三 23:08:42,由 doxygen 1.12.0 为 OpenCV 生成
FAST角点检测算法
https://docs.opencv.org/4.x/df/d0c/tutorial_py_fast.html
目标
在本章节中,
- 我们将了解FAST算法的基础知识
- 我们将使用OpenCV提供的FAST算法功能来寻找角点
理论背景
我们之前探讨了多种特征检测器,其中不少表现优异。但从实时应用的角度来看,它们的处理速度仍显不足。一个典型案例是计算资源有限的SLAM(同步定位与建图)移动机器人。
针对这一问题,Edward Rosten和Tom Drummond在2006年的论文《Machine learning for high-speed corner detection》中提出了FAST(基于加速分段测试的特征)算法(2010年进行了修订)。以下是该算法的核心概要,更多细节请参阅原始论文(本文所有图片均引自该论文)。
使用FAST算法进行特征检测
1、在图像中选择一个待检测是否为兴趣点的像素点\(p\),其灰度值为\(I_p\)。
2、选择合适的阈值\(t\)。
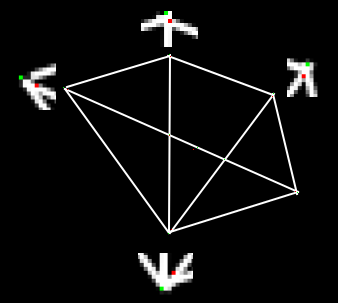
3、以待测像素为中心,取半径为3的圆周上的16个像素点(如下图所示)。

1、如果圆周上存在连续\(n\)个像素点(图中白色虚线所示),这些像素的灰度值均大于\(I_p + t\)或均小于\(I_p − t\),则判定\(p\)为角点。通常取\(n=12\)。
2、提出了一种高速测试法来快速排除大量非角点:仅检测位置1、9、5、13四个像素点(先检测1和9,若符合条件再检测5和13)。如果\(p\)是角点,这四个点中至少有三个点同时满足大于\(I_p + t\)或小于\(I_p − t\)。若不满足该条件,则可立即排除\(p\)为角点的可能。通过该测试的候选点再使用完整的圆周检测进行验证。虽然该检测器本身性能优异,但仍存在以下不足:
* 当n<12时无法有效排除候选点
* 像素点选取策略非最优,其效率依赖于检测顺序和角点分布特征
* 高速测试的中间结果未被充分利用
* 相邻区域会检测出多个特征点
前三个问题通过机器学习方法解决,最后一个问题采用非极大值抑制处理。
机器学习角点检测器
1、选择一组图像用于训练(最好来自目标应用领域)
2、在每张图像上运行FAST算法以寻找特征点
3、对于每个特征点,将其周围16个像素存储为向量。对所有图像执行此操作,得到特征向量\(P\)
4、这16个像素中的每个像素(例如\(x\))可能处于以下三种状态之一:
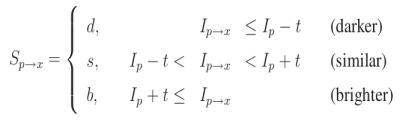
1、根据这些状态,特征向量\(P\)被划分为三个子集:\(P_d\)、\(P_s\)和\(P_b\)
2、定义一个新的布尔变量\(K_p\),当\(p\)是角点时值为真,否则为假
3、使用ID3算法(决策树分类器)通过变量\(K_p\)查询每个子集,获取关于真实类别的知识。算法会选择能提供最多角点判断信息的像素\(x\),该信息量通过\(K_p\)的熵来度量
4、递归地将此方法应用于所有子集,直到熵降为零
5、最终生成的决策树可用于在其他图像中进行快速检测
非极大值抑制
在相邻位置检测到多个兴趣点是另一个常见问题。这可以通过非极大值抑制(Non-maximum Suppression)来解决。
- 为所有检测到的特征点计算评分函数\(V\)。\(V\)表示中心点\(p\)与周围16个像素点绝对差值的总和。
- 比较两个相邻关键点的\(V\)值。
- 舍弃其中\(V\)值较低的关键点。
概述
该算法比其他现有的角点检测器快数倍。
但它对高噪声水平不够鲁棒,且依赖于阈值参数。
OpenCV中的FAST特征检测器
它的调用方式与OpenCV中其他特征检测器相同。如果需要,你可以指定阈值、是否应用非极大值抑制以及使用的邻域类型等参数。
对于邻域类型,定义了三种标志:
- cv.FAST_FEATURE_DETECTOR_TYPE_5_8
- cv.FAST_FEATURE_DETECTOR_TYPE_7_12
- cv.FAST_FEATURE_DETECTOR_TYPE_9_16
下面是一个简单的代码示例,展示如何检测并绘制FAST特征点。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as pltimg = cv.imread('blox.jpg', cv.IMREAD_GRAYSCALE) # \`<opencv_root>/samples/data/blox.jpg\`# Initiate FAST object with default values
fast = cv.FastFeatureDetector_create()# find and draw the keypoints
kp = fast.detect(img,None)
img2 = cv.drawKeypoints(img, kp, None, color=(255,0,0))# Print all default params
print( "Threshold: {}".format(fast.getThreshold()) )
print( "nonmaxSuppression:{}".format(fast.getNonmaxSuppression()) )
print( "neighborhood: {}".format(fast.getType()) )
print( "Total Keypoints with nonmaxSuppression: {}".format(len(kp)) )cv.imwrite('fast_true.png', img2)# Disable nonmaxSuppression
fast.setNonmaxSuppression(0)
kp = fast.detect(img, None)print( "Total Keypoints without nonmaxSuppression: {}".format(len(kp)) )img3 = cv.drawKeypoints(img, kp, None, color=(255,0,0))cv.imwrite('fast_false.png', img3)查看结果。第一张图展示了带非极大值抑制的FAST算法效果,第二张图则是不带非极大值抑制的效果:

附加资源
1、Edward Rosten 和 Tom Drummond 的论文《Machine learning for high speed corner detection》,发表于第9届欧洲计算机视觉会议(ECCV 2006)第1卷,430-443页。
2、Edward Rosten、Reid Porter 和 Tom Drummond 的论文《Faster and better: a machine learning approach to corner detection》,发表于《IEEE模式分析与机器智能汇刊》2010年第32卷,105-119页。
由 doxygen 1.12.0 生成于 2025年4月30日 星期三 23:08:42,适用于 OpenCV
BRIEF(二进制鲁棒独立基本特征)
https://docs.opencv.org/4.x/dc/d7d/tutorial_py_brief.html
目标
在本章中
- 我们将了解 BRIEF 算法的基础知识
理论基础
我们知道SIFT算法使用128维向量作为描述符。由于采用浮点数存储,每个描述符需要占用512字节。类似地,SURF描述符(64维)也至少需要256字节。为成千上万个特征点生成这样的向量会消耗大量内存,这在资源受限的应用场景(尤其是嵌入式系统)中难以实现。内存消耗越大,特征匹配所需的时间也越长。
实际上,并非所有维度都对匹配过程必不可少。我们可以通过PCA(主成分分析)、LDA(线性判别分析)等方法进行数据压缩。甚至还可以采用LSH(局部敏感哈希)等哈希技术,将SIFT的浮点描述符转换为二进制字符串。这些二进制字符串通过汉明距离进行特征匹配,由于现代CPU的SSE指令集能高效执行异或运算和位计数操作,这种方法能显著提升匹配速度。但需要注意的是,我们必须先获取描述符才能进行哈希转换,这并没有解决内存占用的根本问题。
此时BRIEF算法应运而生。它提供了一种直接获取二进制字符串的捷径,无需先计算描述符。该算法对平滑后的图像块进行处理,通过独特方式(论文中有详细说明)选择一组\(n_d\)个(x,y)坐标对,然后对这些坐标点进行像素强度比较。例如,对于第一个坐标对\(p\)和\(q\),若\(I§ < I(q)\)则输出1,否则输出0。对所有\(n_d\)个坐标对执行此操作,最终生成\(n_d\)维的比特串。
这个\(n_d\)可以取值128、256或512。OpenCV支持所有这些维度,但默认使用256(OpenCV以字节为单位表示,因此实际值为16、32和64)。获得比特串后,就可以使用汉明距离进行描述符匹配。
需要特别强调的是,BRIEF是一种特征描述符算法,本身不包含特征检测功能。因此需要配合SIFT、SURF等其他特征检测器使用。原论文推荐使用CenSurE快速检测器,实验表明BRIEF对CenSurE特征点的描述效果甚至略优于SURF特征点。
简而言之,BRIEF是一种更高效的特征描述符计算与匹配方法。除非存在大幅度的平面内旋转,否则该方法都能保持较高的识别率。
OpenCV中的STAR(CenSurE)特征检测器
STAR是一种源自CenSurE的特征检测器。但与使用正方形、六边形和八边形等多边形来逼近圆形的CenSurE不同,STAR通过两个重叠的正方形(一个直立,一个旋转45度)来模拟圆形。这些多边形是双层结构的,可以看作具有粗边框的多边形,其边框与内部区域的权重符号相反。
相比其他尺度空间检测器,STAR具有更优的计算特性,能够实现实时处理。与SIFT和SURF在子采样像素上寻找极值(这会影响较大尺度下的精度)不同,CenSurE在金字塔所有尺度上都使用全空间分辨率来创建特征向量。
OpenCV中的BRIEF描述符
以下代码展示了如何借助CenSurE检测器计算BRIEF描述符。
注意:使用此功能需要安装opencv contrib。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as pltimg = cv.imread('simple.jpg', cv.IMREAD_GRAYSCALE)# Initiate FAST detector
star = cv.xfeatures2d.StarDetector_create()# Initiate BRIEF extractor
brief = cv.xfeatures2d.BriefDescriptorExtractor_create()# find the keypoints with STAR
kp = star.detect(img,None)# compute the descriptors with BRIEF
kp, des = brief.compute(img, kp)print( brief.descriptorSize() )
print( des.shape )函数 brief.getDescriptorSize() 返回以字节为单位的 \(n_d) 大小,默认值为 32。匹配操作将在后续章节中讨论。
补充资源
1、Michael Calonder、Vincent Lepetit、Christoph Strecha 和 Pascal Fua 合著的论文《BRIEF: 二进制鲁棒独立基本特征》,发表于2010年9月在希腊克里特岛伊拉克利翁举行的第11届欧洲计算机视觉会议(ECCV),由Springer出版社LNCS系列收录。
2. 维基百科关于局部敏感哈希(LSH)的条目。
本文档由 doxygen 1.12.0 生成于 2025年4月30日 星期三 23:08:42,针对 OpenCV 项目。
ORB (定向FAST与旋转BRIEF)
https://docs.opencv.org/4.x/d1/d89/tutorial_py_orb.html
目标
在本章中,
- 我们将了解ORB的基础知识
理论基础
作为OpenCV的爱好者,ORB最令人振奋的一点在于它诞生于"OpenCV实验室"。该算法由Ethan Rublee、Vincent Rabaud、Kurt Konolige和Gary R. Bradski在2011年的论文**《ORB:SIFT与SURF的高效替代方案》**中提出。正如标题所示,ORB在计算成本、匹配性能以及专利问题上都是SIFT和SURF的优秀替代方案。是的,SIFT和SURF受专利保护,使用时需要付费,但ORB完全免费!
ORB本质上是FAST关键点检测器与BRIEF描述符的融合体,并通过多项改进来提升性能。首先使用FAST算法定位关键点,然后应用Harris角点测量筛选出最优的N个点。算法还采用图像金字塔来生成多尺度特征。但存在一个问题:FAST不计算方向。那么如何实现旋转不变性呢?研究者们提出了以下改进方案。
算法会计算以角点为中心的图像块强度加权质心。从角点指向质心的向量方向即为该点的朝向。为增强旋转不变性,在半径为\(r\)的圆形区域内计算x和y方向的矩,其中\(r\)表示图像块尺寸。
在描述符方面,ORB采用BRIEF描述符。但我们已经知道BRIEF在旋转情况下表现欠佳。因此ORB根据关键点方向对BRIEF进行"导向"调整:对于包含\(n\)个二进制测试的特征集\((x_i, y_i)\),定义一个\(2 \times n\)的坐标矩阵\(S\),然后利用图像块方向\(\theta\)计算旋转矩阵,对\(S\)进行旋转得到导向版本\(S_\theta\)。
ORB将角度离散化为\(2 \pi /30\)(12度)的增量,并预先计算BRIEF模式的查找表。只要关键点方向\(\theta\)在不同视角下保持一致,就能使用正确的点集\(S_\theta\)来计算描述符。
BRIEF有个重要特性:每个二进制特征都具有高方差且均值接近0.5。但经过关键点方向调整后,这个特性会减弱导致分布更分散。高方差使特征更具区分度,因为其对不同输入会产生差异化响应。另一个理想特性是测试间不相关,这样每个测试都能独立发挥作用。为解决这些问题,ORB通过贪婪搜索从所有可能的二进制测试中筛选出同时具备高方差、均值接近0.5且互不相关的组合,最终得到rBRIEF。
在描述符匹配方面,采用改进传统局部敏感哈希(LSH)的多探针LSH算法。论文指出ORB速度远超SURF和SIFT,且ORB描述符性能优于SURF。对于全景拼接等低功耗设备应用场景,ORB是绝佳选择。
OpenCV 中的 ORB 特征检测
通常,我们需要通过 cv.ORB() 函数或使用 feature2d 通用接口来创建 ORB 对象。该函数包含多个可选参数,其中最常用的有:
nFeatures:指定要保留的最大特征数量(默认为 500)scoreType:决定使用 Harris 评分还是 FAST 评分对特征进行排序(默认为 Harris 评分)
另一个重要参数 WTA_K 决定了生成定向 BRIEF 描述符每个元素所需的点数。默认值为 2,即每次选择两个点。此时匹配使用 NORM_HAMMING 距离。若 WTA_K 设为 3 或 4(表示需要 3 或 4 个点来生成 BRIEF 描述符),则匹配距离由 NORM_HAMMING2 定义。
以下是一个展示 ORB 用法的简单代码示例:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as pltimg = cv.imread('simple.jpg', cv.IMREAD_GRAYSCALE)# Initiate ORB detector
orb = cv.ORB_create()# find the keypoints with ORB
kp = orb.detect(img,None)# compute the descriptors with ORB
kp, des = orb.compute(img, kp)# draw only keypoints location,not size and orientation
img2 = cv.drawKeypoints(img, kp, None, color=(0,255,0), flags=0)
plt.imshow(img2), plt.show()
查看下方结果:

ORB特征匹配我们将在另一章节中实现。
附加资源
1、Ethan Rublee、Vincent Rabaud、Kurt Konolige、Gary R. Bradski 合著:ORB:SIFT 或 SURF 的高效替代方案。ICCV 2011:2564-2571。
本文档由 doxygen 1.12.0 生成于 2025年4月30日 星期三 23:08:42,适用于 OpenCV。
特征匹配
https://docs.opencv.org/4.x/dc/dc3/tutorial_py_matcher.html
目标
在本章中:
- 我们将学习如何在一幅图像中匹配其他图像的特征点。
- 我们将使用OpenCV中的暴力匹配器(Brute-Force matcher)和快速近似最近邻匹配器(FLANN Matcher)。
暴力匹配器基础
暴力匹配器原理很简单。它会提取第一组特征中的一个描述符,通过某种距离计算方式与第二组中的所有其他特征进行匹配,然后返回最接近的那个匹配结果。
使用BF匹配器时,首先需要通过 cv.BFMatcher() 创建BFMatcher对象。该函数接收两个可选参数:第一个是normType,用于指定距离度量方式,默认使用 cv.NORM_L2(cv.NORM_L1 也可用),适用于SIFT、SURF等算法。对于ORB、BRIEF、BRISK等基于二进制字符串的描述符,则应使用 cv.NORM_HAMMING 以汉明距离作为度量标准。若ORB使用WTA_K == 3或4,则需改用 cv.NORM_HAMMING2。
第二个参数是布尔变量crossCheck,默认为false。若设为true,匹配器仅返回满足双向匹配条件的特征对——即集合A中的第i个描述符与集合B中的第j个描述符互为最佳匹配。这种方式能提供稳定的匹配结果,可作为SIFT论文中D.Lowe提出的比率检验法的替代方案。
创建匹配器后,有两个核心方法:BFMatcher.match() 返回最佳匹配结果,BFMatcher.knnMatch() 则返回用户指定数量k的最佳匹配(适用于需要进一步处理的场景)。
类似于用 cv.drawKeypoints() 绘制关键点,cv.drawMatches() 可绘制匹配结果:水平堆叠两幅图像并绘制连接线显示最佳匹配。另有 cv.drawMatchesKnn 可绘制所有k个最佳匹配(例如k=2时为每个关键点绘制两条匹配线),此时需要通过掩码选择性绘制。
下面我们将分别展示SIFT和ORB的示例(两者使用不同的距离度量方式)。
使用ORB描述符进行暴力匹配
这里我们将看到一个简单的特征匹配示例。在这个案例中,我有一张查询图像(queryImage)和一张训练图像(trainImage)。我们将尝试通过特征匹配在训练图像中定位查询图像。(使用的图像是/samples/data/box.png和/samples/data/box_in_scene.png)
我们使用ORB描述符进行特征匹配。现在让我们从加载图像、查找描述符等步骤开始。
import numpy as np
import cv2 as cv
import matplotlib.pyplot as pltimg1 = cv.imread('box.png',cv.IMREAD_GRAYSCALE) # queryImage
img2 = cv.imread('box_in_scene.png',cv.IMREAD_GRAYSCALE) # trainImage# Initiate ORB detector
orb = cv.ORB_create()# find the keypoints and descriptors with ORB
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
接下来我们创建一个使用 cv.NORM_HAMMING 距离度量(因为我们使用的是 ORB)的 BFMatcher 对象,并开启 crossCheck 以获得更好的结果。然后使用 Matcher.match() 方法获取两幅图像中的最佳匹配。我们按距离升序排序,使最佳匹配(距离较小)排在前面。最后仅绘制前 10 个匹配(仅为可视化考虑,可根据需要增加数量)。
# create BFMatcher object
bf = cv.BFMatcher(cv.NORM_HAMMING, crossCheck=True)# Match descriptors.
matches = bf.match(des1,des2)# Sort them in the order of their distance.
matches = sorted(matches, key = lambda x:x.distance)# Draw first 10 matches.
img3 = cv.drawMatches(img1,kp1,img2,kp2,matches[:10],None, flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)plt.imshow(img3),plt.show()
我得到的结果如下:

什么是这个匹配器对象?
matches = bf.match(des1,des2) 这行代码的结果是一个 DMatch 对象列表。这个 DMatch 对象具有以下属性:
- DMatch.distance - 描述符之间的距离。数值越小,匹配效果越好。
- DMatch.trainIdx - 训练描述符集合中描述符的索引
- DMatch.queryIdx - 查询描述符集合中描述符的索引
- DMatch.imgIdx - 训练图像的索引
基于 SIFT 描述符与比率测试的暴力匹配
这次我们将使用 BFMatcher.knnMatch() 方法来获取 k 个最佳匹配。在本例中,我们设定 k=2,以便应用 D.Lowe 在其论文中阐述的比率测试方法。
import numpy as np
import cv2 as cv
import matplotlib.pyplot as pltimg1 = cv.imread('box.png',cv.IMREAD_GRAYSCALE) # queryImage
img2 = cv.imread('box_in_scene.png',cv.IMREAD_GRAYSCALE) # trainImage# Initiate SIFT detector
sift = cv.SIFT_create()# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)# BFMatcher with default params
bf = cv.BFMatcher()
matches = bf.knnMatch(des1,des2,k=2)# Apply ratio test
good = []
for m,n in matches:if m.distance < 0.75*n.distance:good.append([m])# cv.drawMatchesKnn expects list of lists as matches.
img3 = cv.drawMatchesKnn(img1, kp1, img2, kp2, good,None, flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)plt.imshow(img3),plt.show()
查看下方结果:

基于FLANN的匹配器
FLANN代表快速近似最近邻库(Fast Library for Approximate Nearest Neighbors)。它包含了一系列针对大数据集和高维特征进行快速最近邻搜索优化的算法。在处理大型数据集时,FLANN比BFMatcher运行得更快。我们将通过第二个示例来了解基于FLANN的匹配器。
使用基于FLANN的匹配器时,需要传递两个字典参数来指定使用的算法及其相关参数等。第一个是IndexParams。对于不同算法,需要传递的参数信息在FLANN文档中有详细说明。简而言之,对于SIFT、SURF等算法,可以传递以下参数:
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
使用 ORB 时,可以传递以下参数。文档中建议使用注释中的值,但在某些情况下这些值无法提供所需结果。其他值则工作正常:
FLANN_INDEX_LSH = 6
index_params= dict(algorithm = FLANN_INDEX_LSH, table_number = 6, # 12key_size = 12, # 20multi_probe_level = 1) #2
第二个字典是 SearchParams。它指定了索引中的树应该被递归遍历的次数。数值越高精度越好,但耗时也越长。如需修改该值,请传入 search_params = dict(checks=100)。
掌握这些信息后,我们就可以开始了。
import numpy as np
import cv2 as cv
import matplotlib.pyplot as pltimg1 = cv.imread('box.png',cv.IMREAD_GRAYSCALE) # queryImage
img2 = cv.imread('box_in_scene.png',cv.IMREAD_GRAYSCALE) # trainImage# Initiate SIFT detector
sift = cv.SIFT_create()# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)# FLANN parameters
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks=50) # or pass empty dictionaryflann = cv.FlannBasedMatcher(index_params,search_params)matches = flann.knnMatch(des1,des2,k=2)# Need to draw only good matches, so create a mask
matchesMask = [[0,0] for i in range(len(matches))]# ratio test as per Lowe's paper
for i,(m,n) in enumerate(matches):if m.distance < 0.7*n.distance:matchesMask[i]=[1,0]draw_params = dict(matchColor = (0,255,0), singlePointColor = (255,0,0), matchesMask = matchesMask, flags = cv.DrawMatchesFlags_DEFAULT)img3 = cv.drawMatchesKnn(img1,kp1,img2,kp2,matches,None,**draw_params)plt.imshow(img3,),plt.show()
查看下方结果:

生成于 2025年4月30日 星期三 23:08:42,由 doxygen 1.12.0 为 OpenCV 生成
特征匹配与单应性变换实现物体查找
https://docs.opencv.org/4.x/d1/de0/tutorial_py_feature_homography.html
目标
在本章中,
- 我们将结合使用 calib3d 模块的特征匹配和 findHomography 功能,在复杂图像中识别已知物体。
基础概念
在上一次课程中我们做了什么?我们使用了一张查询图像(queryImage),在其中找到了一些特征点;然后选取另一张训练图像(trainImage),同样提取其特征,并在两幅图像间寻找最佳匹配。简而言之,我们在杂乱的图像中定位到了目标物体的某些部分。这些信息足以在训练图像上精确定位目标物体。
为此,我们可以调用calib3d模块中的 cv.findHomography() 函数。当传入两组图像中的匹配点集时,该函数会计算出物体的透视变换矩阵。接着通过 cv.perspectiveTransform() 即可定位目标物体,此过程至少需要四个正确匹配点才能计算变换。
我们注意到匹配过程中可能存在误差,这些误差会影响最终结果。为了解决这个问题,算法采用RANSAC或LEAST_MEDIAN方法(可通过标志位选择)。那些能提供正确估计的良好匹配被称为内点(inliers),其余则称为外点(outliers)。cv.findHomography() 会返回一个掩码,用于标识内点和外点。
现在就开始实践吧!
代码
首先,按照惯例,我们会在图像中寻找 SIFT 特征,并通过比率测试来筛选最佳匹配项。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as pltMIN_MATCH_COUNT = 10img1 = cv.imread('box.png', cv.IMREAD_GRAYSCALE) # queryImage
img2 = cv.imread('box_in_scene.png', cv.IMREAD_GRAYSCALE) # trainImage# Initiate SIFT detector
sift = cv.SIFT_create()# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks = 50)flann = cv.FlannBasedMatcher(index_params, search_params)matches = flann.knnMatch(des1,des2,k=2)# store all the good matches as per Lowe's ratio test.
good = []
for m,n in matches:if m.distance < 0.7*n.distance:good.append(m)
现在我们设定一个条件:至少需要10个匹配点(由MIN_MATCH_COUNT定义)才能判定找到目标物体。否则,直接显示"匹配点数量不足"的提示信息。
如果找到足够的匹配点,我们会提取两幅图像中匹配关键点的位置坐标。这些坐标被用于计算透视变换矩阵。得到这个3x3变换矩阵后,我们用它来将queryImage的角点坐标转换为trainImage中对应的点坐标,最后绘制出转换结果。
if len(good)>MIN_MATCH_COUNT:src_pts = np.float32([ kp1[m.queryIdx].pt for m in good ]).reshape(-1,1,2)dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good ]).reshape(-1,1,2)M, mask = [cv.findHomography`](https://docs.opencv.org/4.x/d9/d0c/group__calib3d.html#ga4abc2ece9fab9398f2e560d53c8c9780)(src_pts, dst_pts, cv.RANSAC,5.0)matchesMask = mask.ravel().tolist()h,w = img1.shapepts = np.float32([ [0,0],[0,h-1],[w-1,h-1],[w-1,0] ]).reshape(-1,1,2)dst = cv.perspectiveTransform(pts,M)img2 = cv.polylines(img2,[np.int32(dst)],True,255,3, cv.LINE_AA)else:print( "Not enough matches are found - {}/{}".format(len(good), MIN_MATCH_COUNT) )matchesMask = None最后,我们绘制出内点(如果成功找到目标)或匹配的关键点(如果失败)。
draw_params = dict(matchColor = (0,255,0), # draw matches in green colorsinglePointColor = None, matchesMask = matchesMask, # draw only inliersflags = 2)img3 = cv.drawMatches(img1,kp1,img2,kp2,good,None,**draw_params)plt.imshow(img3, 'gray'),plt.show()
查看下方结果。在杂乱的图像中,目标物体以白色标记:

生成于 2025年4月30日 星期三 23:08:42,由 doxygen 1.12.0 为 OpenCV 创建
2025-07-19(六)