【2025最新】使用neo4j实现GraphRAG所需的向量检索
学习笔记,比较混乱,介意慎点。
背景
在将UMLS或者LightRAG构造的数据库存入neo4j之后,我开始将知识图谱运用到实际场景的使用中、例如查询、推理。然而,由于字符串匹配导致大量术语在检索时出现缺失。导致检索效果不佳。我们需要使用embedding模型,将对应的实体或者关系转为vector,存入向量数据库。利用向量数据库已有的高效存储技术和查询方法。帮助我们快速查询到相关实体或者关系。通过确定相似度的阈值,来保留最终查询结果。
目标:
向量化UMLS的实体(筛选过的)
embeding 千问的嵌入模型
向量数据库 在实践中,我们推荐大家使用开源 Milvus,或它的全托管版本 Zilliz Cloud,来存储并搜索 graph 结构中大量的 entities 和 relationships。(AI大模型:知识图谱融入向量数据库,带来 RAG 效果飞升(附教程)_知识图谱 向量数据库-CSDN博客)
【
在这句话中,“全托管” 指的是一种软件服务模式,具体来说,Zilliz Cloud 作为 Milvus 向量数据库的全托管版本,意味着用户无需自行搭建、部署、维护数据库的底层基础设施(如服务器、存储、网络等),也无需手动处理数据库的安装、配置、更新、备份、扩容等运维工作,这些任务全部由服务提供商(此处即 Zilliz 团队)来负责。
用户只需通过简单的接口或控制台操作,就能直接使用数据库的核心功能(如存储、搜索向量数据等),专注于自身业务逻辑的开发,而不必投入精力在基础设施管理上。这种模式的优势在于降低了技术门槛、减少了运维成本,同时能借助专业团队的维护保障服务的稳定性和安全性,常见于云服务中的数据库、服务器等领域。
】
【
全托管版本 Zilliz Cloud收费吗?
Zilliz Cloud 有免费版本,也有付费版本,具体如下:
- 免费版本:Serverless cluster 是 Zilliz Cloud 的入门版本,用户可在 GCP 上部署免费 cluster,适合入门者和想要尝试 Zilliz Cloud 的开发人员,无需信用卡和复杂配置,即可快速体验向量数据库功能。
- 付费版本:包括标准版、企业版和专有部署版。标准版适合小型团队和个人开发者,支持在 AWS 和 GCP 上部署,注册可获赠价值 $100 的 credit,享受 30 天免费试用。企业版适合大型组织或企业,提供高可用、数据安全和专家技术支持等。专有部署版适用于高度注重数据隐私和合规的场景,这两种版本无免费试用,具体价格需根据用户实际使用情况和配置确定。
】
学习过程
通过博文了解使用的具体过程为:定义数据模式,(包括知道dim = 1536 # OpenAI embedding维度),创建存放向量的集合,写入
代码比较简单,如下:
# 定义数据模式
collection_name = "products"
dim = 1536 # OpenAI embedding维度
# 创建集合
collection = Collection(name=collection_name)
collection.create_field(FieldSchema("id", DataType.INT64, is_primary=True))
collection.create_field(FieldSchema("title", DataType.VARCHAR, max_length=200))
collection.create_field(FieldSchema("description", DataType.VARCHAR, max_length=2000))
collection.create_field(FieldSchema("embedding", DataType.FLOAT_VECTOR, dim=dim))
# 写入数据
with collection:for index, row in df.iterrows():embedding = get_embedding(row.title + " " + row.description)collection.insert([[index], [row.title], [row.description], [embedding]])
向量数据库可能会返回那些字符表面相似,但是语义不相似的内容,这会造成“上下文污染”,使得大语言模型生成的推荐不够精确。
这里的解决是把一个概念的所有特征用知识图谱检索出来,把特征和原有的描述一起向量化检索。
再用知识图谱对向量化检索结果进一步处理,例如:# 筛选出真正具备防水和跑步功能的产品
query = """ SELECT ?product ?title ?description WHERE { ?product hasFeature ?feature1. ?product hasFeature ?feature2. ?product name ?title. ?product description ?description. FILTER (?product IN (%s) && ?feature1 IN (%s) && ?feature2 IN (%s)) } """
(等我回来好好品一下这个查询
我懂了,核心就是各种同时满足已知条件。如select product,如何满足一堆feature
)
上面我们已经大概有个印象了。接下来开始对比开源 Milvus,或它的全托管版本 Zilliz Cloud,我们选哪个,由于我非常赶时间,需要决策一个技术选型并且快速收集情报进行了解,再部署。
学习[深入了解Zilliz Cloud与Milvus:从安装到应用的全方位指南]_milvus安装-CSDN博客
高效向量搜索与管理:使用Zilliz Cloud和Milvus_milvus zilliz-CSDN博客
一文带你入门向量数据库milvus:含docker安装、milvus安装使用、attu 可视化,完整指南启动 Milvus 进行了向量相似度搜索-CSDN博客
Milvus 向量数据库介绍及使用-CSDN博客
决定了,其实对我来说都差不多,我决定安装Milvus,作为一个开源的软件,学习它对我来说未来的可用性更强。边学边做吧。
概念学习
最火向量数据库Milvus安装使用一条龙!_milvus安装脚本-CSDN博客从该博客学了不少的概念和了解,我的理念是要学就要尽量了解自己在用的是什么,为甚要用它。
向量数据库是大模型应用开发必备组件之一,因为它在知识库、语义搜索、检索增强生成(RAG)等人工智能应用中发挥着举足轻重的作用。但向量数据有很多,为什么要使用 Milvus 呢?
常见的向量数据库有以下这些:
Chroma
Elasticsearch
Milvus
Neo4j
OpenSearch
Redis
PGVector
然而目前市面上使用最多的向量数据库还是 Milvus,为什么呢?
Milvus 设计之初就是为 AI 而生的一个高效的向量数据库系统,在大多数情况下,Milvus 的性能是其他向量数据库的 2-5 倍,它能实现万亿级向量的毫秒级相似性搜索,而且 Milvus 还是开源的向量数据库。
PS:也就说 Milvus 既开源(可以免费使用+支持二次开发)又具备高性能,这样的数据库谁不爱呢?
为什么 Milvus 这么快?
Milvus 运行比较快的原因有以下几个:
硬件感知优化:为了让 Milvus 适应各种硬件环境,我们专门针对多种硬件架构和平台优化了其性能,包括 AVX512、SIMD、GPU 和 NVMe SSD。
高级搜索算法:Milvus 支持多种内存和磁盘索引/搜索算法,包括 IVF、HNSW、DiskANN 等,所有这些算法都经过了深度优化。与 FAISS 和 HNSWLib 等流行实现相比,Milvus 的性能提高了 30%-70%。
C++ 搜索引擎:向量数据库性能的 80% 以上取决于其搜索引擎。由于 C++ 语言的高性能、底层优化和高效资源管理,Milvus 将 C++ 用于这一关键组件。最重要的是,Milvus 集成了大量硬件感知代码优化,从汇编级向量到多线程并行化和调度,以充分利用硬件能力。
面向列:Milvus 是面向列的向量数据库系统。其主要优势来自数据访问模式。在执行查询时,面向列的数据库只读取查询中涉及的特定字段,而不是整行,这大大减少了访问的数据量。此外,对基于列的数据的操作可以很容易地进行向量化,从而可以一次性在整个列中应用操作,进一步提高性能。
Milvus 支持的搜索类型
Milvus 支持各种类型的搜索功能,以满足不同用例的需求:
ANN 搜索:查找最接近查询向量的前 K 个向量。
过滤搜索:在指定的过滤条件下执行 ANN 搜索。
范围搜索:查找查询向量指定半径范围内的向量。
混合搜索:基于多个向量场进行 ANN 搜索。
全文搜索:基于 BM25 的全文搜索。
Rerankers:根据附加标准或辅助算法调整搜索结果顺序,完善初始 ANN 搜索结果。
根据主键检索数据。
查询使用特定表达式检索数据。
Milvus 安装
Milvus 有三种部署方式:
Milvus Lite:Milvus Lite 是一个 Python 库,可导入到您的应用程序中。作为 Milvus 的轻量级版本,它非常适合在 Jupyter 笔记本或资源有限的智能设备上运行快速原型。Milvus Lite 支持与 Milvus 其他部署相同的 API。与 Milvus Lite 交互的客户端代码也能与其他部署模式下的 Milvus 实例协同工作。
Milvus Standalone:Milvus Standalone 是单机服务器部署。Milvus Standalone 的所有组件都打包到一个 Docker 镜像中,部署起来非常方便。
Milvus Distributed:Milvus Distributed 可部署在 Kubernetes 集群上。这种部署采用云原生架构,摄取负载和搜索查询分别由独立节点处理,允许关键组件冗余。它具有最高的可扩展性和可用性,并能灵活定制每个组件中分配的资源。Milvus Distributed 是在生产中运行大规模向量搜索系统的企业用户的首选。
PS:当然中小型公司生产环境也可以直接购买 XXX 云的 Milvus 实例直接使用。
我们这里使用 Milvus Standalone 单机版部署方式。
硬件要求

如何确定自己的电脑性能:
有几核:按 Win + R 输入 “cmd” 后按回车,打开命令提示符。输入命令 “wmic CPU get NumberOfCores,NumberOfLogicalProcessors” 并回车,输出会显示核心数(NumberOfCores)和逻辑处理器数。
CPU型号:任务管理器:右键点击任务栏,选择 “任务管理器”,或使用快捷键 Ctrl + Shift + Esc 直接打开。在任务管理器中,点击 “性能” 标签,选择 “CPU”
安装
0.如何确定自己有没有安装docker desktop、wsl
Docker Desktop:在 Windows、macOS 或 Linux 系统中,打开命令提示符、PowerShell 或终端,输入 “docker --version” 或 “docker version” 命令。若显示 Docker 的版本信息,则说明已安装。还可输入 “docker info” 命令,若能获取到 Docker 系统的详细信息,如镜像数量、容器数量等,也表明已安装且服务正常运行。
【pps,我突然想到,自己安装只能安装在windows,而未来公司用多半是服务器或者linux系统。我装在学校服务器的话,容易遇到服务器维护,没卡啥的,还是调接口吧,或者直接调用之前的neo4j。于是以下废弃,欢迎大家调到下一个一级标题】
1.安装wsl
2从安装到测试安装完成【Windows系统】向量数据库Milvus安装教程-CSDN博客
【
一些我的小疑问
Docker 是一种开源的容器化技术,通过 “容器” 封装应用程序及其所有依赖的底层系统环境(如操作系统库、配置文件、系统工具等),实现 “一次构建,到处运行”。
容器与宿主机系统隔离,确保应用在不同操作系统(如 Windows、Linux、macOS)或服务器上的运行环境完全一致,解决 “在我这能跑,在你那跑不了” 的问题。
容器类似轻量级虚拟机,包含应用运行所需的代码、库、环境变量等,但共享主机操作系统内核,启动快、资源占用低。 通过 Docker,开发者可在一致环境中开发、测试和部署应用,也便于规模化管理和分发应用。
Docker Compose 是 Docker 官方提供的用于定义和运行多容器 Docker 应用程序的工具,通过 YAML 文件配置应用所需的所有服务,再用一条命令即可创建并启动所有服务。
在该场景中,安装 Milvus 服务需使用其提供的 docker - compose.yml 文件,而 Docker Compose 正是解析和执行该文件的必备工具,只有安装它,才能通过 “docker - compose up -d” 命令启动 Milvus 相关的容器服务。
Docker Desktop 是一款适用于 Windows 和 macOS 系统的桌面应用程序,是 Docker 官方提供的集成工具。
它的主要功能包括:
- 提供图形化界面,方便用户管理 Docker 容器、镜像、网络等资源,无需完全依赖命令行操作。
- 内置了 Docker Engine,可在本地构建、运行和测试 Docker 容器。
- 集成了 Docker Compose 工具,支持通过配置文件定义和运行多容器应用。
- 对于 Windows 系统,通常需要配合 WSL(Windows 子系统 for Linux)使用,以提供更高效的容器运行环境。
简单来说,它是简化本地 Docker 环境搭建和使用的工具,让开发者能更便捷地进行容器化应用的开发、测试等工作。
】
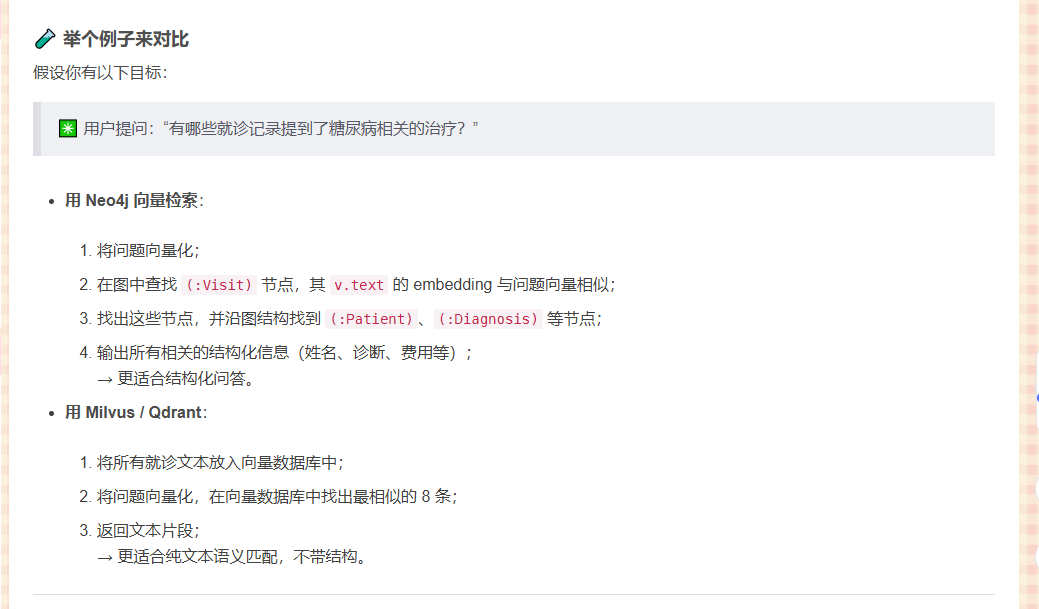
neo4j
Neo4j 的向量搜索(Neo4jVector)和常见的向量数据库(比如 Milvus、Qdrant)之间的区别与联系_neo4j向量化-CSDN博客
根据上文,感觉neo4j更适合我的研究,开源现由特定节点出发,再沿着图结构查询
“Neo4j 向量搜索擅长将“结构化图信息”与“语义相似度”结合起来;而 Milvus、Qdrant 等专用向量数据库更适合做超大规模、高性能的纯向量相似度检索。”
存入向量数据库
【neo4j】win/linux安装和使用+cypher+langchian+向量索引_neo4j desktop linux-CSDN博客
通过上文对条件再做个了解
向量索引内容
neo4j版本5以上,部分函数要求5.18以上
官网介绍Vector indexes - Cypher Manual
csdn给出的安装方法Neo4j安装apoc插件的详细教程-CSDN博客
根据上文完成了安装apoc
原因如下:
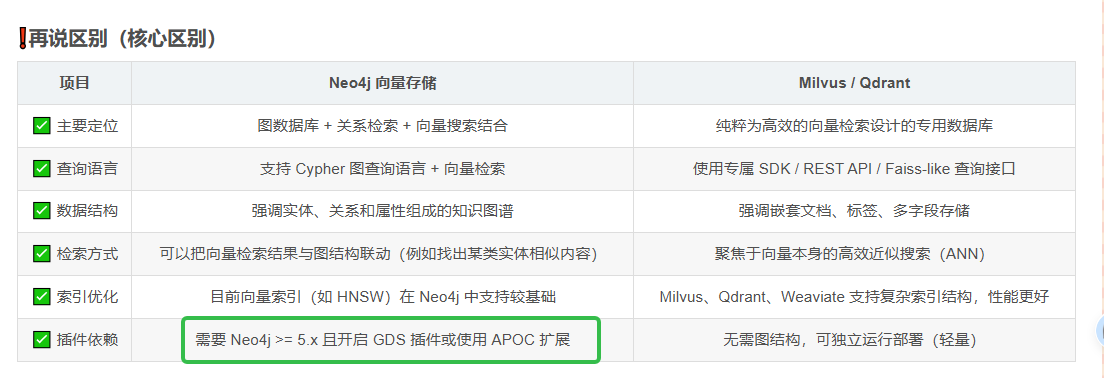
neo4j有两种索引方式,一种是索引文本(整个三元组full-text,即Relationship),一种是向量化Node或者Relation。
full-text向量化Full-text indexes - Cypher Manual
貌似不能向量化整个三元组?
官网向量化例子
同理,添加关系的embedding函数是db.create.setRelationshipVectorProperty
官网代码1Cypher Cheat Sheet - Neo4j Documentation Cheat Sheet
官网代码2Find movies given a search prompt - Embeddings & Vector Indexes Tutorial
def add_vectors():model = BertEmb() # 自定义的 model.embed_query(str) 返回一个list 装的是embedding# step1: get embeddingscode = "MATCH (e) RETURN e.id as id, e.name as name"entity_names = driver.execute_query(code)entity_list = []print(f'Begin generate embeddings ...')for idx, record in enumerate(tqdm(entity_names.records)):id = record.get('id')name = record.get('name')curr_emb = {'id': id,'name': name,'embedding': model.embed_query(name)} entity_list.append(curr_emb)# step2: set NodeVectorPropertyprint(f'Begin adding embeddings as property...')batch = 100total_num = len(entity_names.records)pbar = tqdm(total=total_num)for step in range(0, total_num, batch):range_start = steprange_end = min(total_num, range_start+batch)batch_entities = entity_list[range_start:range_end]create_embeddings_code = """UNWIND $entities as entityMATCH (e:Entity {id:entity.id})CALL db.create.setNodeVectorProperty(e, 'embedding', entity.embedding)"""driver.execute_query(create_embeddings_code, entities=batch_entities) pbar.update(range_end-range_start) pbar.close()# step3: add indexprint(f'Begin adding index...')create_index_code = """CREATE VECTOR INDEX entity_embeddings IF NOT EXISTSFOR (e:Entity)ON e.embeddingOPTIONS {indexConfig: {`vector.dimensions`: 768,`vector.similarity_function`: 'cosine'}}"""driver.execute_query(create_index_code)
具体操作
在 Neo4j 中实现向量化存储:从文本到高效语义搜索_neo4j 向量化-CSDN博客
neo4j图数据库基本概念和向量使用_neo4j_辛一一-DeepSeek技术社区
1.数据填充
假设你有一些文本数据(例如一个文本文件 dune.txt),需要将这些文本数据处理后存储到 Neo4j 中。这通常需要以下步骤:
读取文本数据:从文件中读取文本内容。
分段处理:将文本分割成较小的段落或句子。
生成向量:使用某种嵌入模型(如 OpenAI 的 text-embedding-ada-002 或 Hugging Face 的 sentence-transformers)将文本转换为向量。
存储到 Neo4j:将文本和对应的向量存储到 Neo4j 数据库中。
以下是一个简单的 Python 示例代码,展示如何完成这些步骤:
import os
import neo4j
from transformers import AutoModel, AutoTokenizer
import torch# 1.连接到 Neo4j 数据库
uri = os.getenv("NEO4J_URI")
username = os.getenv("NEO4J_USERNAME")
password = os.getenv("NEO4J_PASSWORD")
driver = neo4j.GraphDatabase.driver(uri, auth=(username, password))# 2.加载文本嵌入模型
model_name = "sentence-transformers/all-MiniLM-L6-v2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)# 3.读取文本文件
with open("dune.txt", "r") as file:text = file.read()# 4.分段处理文本
paragraphs = text.split("\n\n") # 假设每两行是一个段落# 5.将文本和向量存储到 Neo4j
def store_paragraphs(paragraphs):with driver.session() as session:for i, paragraph in enumerate(paragraphs):# 生成向量inputs = tokenizer(paragraph, return_tensors="pt", padding=True, truncation=True)outputs = model(**inputs)vector = outputs.last_hidden_state.mean(dim=1).detach().numpy().tolist()[0]# 存储到 Neo4jsession.run("""CREATE (p:Paragraph {id: $id, text: $text, embedding: $embedding})""",id=i,text=paragraph,embedding=vector)store_paragraphs(paragraphs)
下面是我根据上面代码进行的一些定制化修改
1. 链接的信息从一开始安装neo4j时候的来,等号右边换成字符串就行。
2.嵌入用的是Qwen/Qwen3-Embedding-8B,从硅基流动用户系统,统一登录 SSO调用,需要付费,但不用部署。教程如下:创建嵌入请求 - SiliconFlow
import requestsurl = "https://api.siliconflow.cn/v1/embeddings"payload = {"model": "BAAI/bge-large-zh-v1.5","input": "Silicon flow embedding online: fast, affordable, and high-quality embedding services. come try it out!"
}
headers = {"Authorization": "Bearer <token>","Content-Type": "application/json"
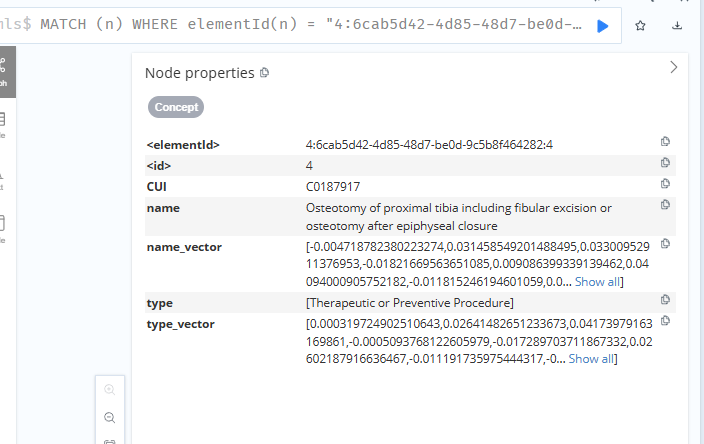
}response = requests.request("POST", url, json=payload, headers=headers)print(response.text)3.我要文本化的内容是neo4j中已有Concept节点的name属性,type属性的值,并将向量后的内容加入知识图谱Concept节点中的两个向量属性,concept节点示例如下:
{"identity": 8,"labels": ["Concept"],"properties": {"CUI": "C0187921","name": "Radical resection for tumor of fibula","type": ["Therapeutic or Preventive Procedure" ]},"elementId": "4:6cab5d42-4d85-48d7-be0d-9c5b8f464282:8"
}
4.我要在neo4jConcept节点中新添的两个属性中增加向量索引
5.完成需要的查询语句
给出一个名词,查出0.8阈值以上的top3节点
6.关系的RELA也变成向量,如果关系能被抽取的化,后续开源单独匹配(但是太麻烦了不想考虑,之后再说吧)
2:创建向量索引
在 Neo4j 中,为了高效地查询向量数据,需要创建向量索引。向量索引可以帮助快速计算向量之间的相似性。
以下是一个创建向量索引的 Cypher 查询示例:
CREATE VECTOR INDEX `paragraph-embeddings`
FOR (p:Paragraph) ON (p.embedding)
OPTIONS {indexConfig: {`vector.dimensions`: 384, // 假设向量维度是 384`vector.similarity_function`: 'cosine' // 使用余弦相似性
}}
vector.dimensions:向量的维度,取决于你使用的嵌入模型。vector.similarity_function:用于计算相似性的函数,常见的有余弦相似性(cosine)和欧几里得距离(euclidean)。
3.查询向量索引
创建索引后,可以通过向量查询来找到与给定向量最相似的节点。以下是一个查询示例:
CALL db.index.vector.queryNodes('paragraph-embeddings', 10, $queryVector)
YIELD node AS paragraph, score
RETURN paragraph.text AS text, score
ORDER BY score DESC
paragraph-embeddings:向量索引的名称。10:返回最相似的 10 个结果。$queryVector:查询向量,你需要提前生成这个向量。
例如,如果你想查询与某个文本最相似的段落,可以先将文本转换为向量,然后作为 $queryVector 传入查询。
存进去了这么查找
使用Neo4j Vector Index进行向量相似性搜索的实战指南_neo4jvector 使用-CSDN博客
4.
另外一种方法,在节点中设置向量属性
如果需要为节点或关系设置向量属性,可以使用以下 Cypher 查询:
MATCH (n:Paragraph {id: $id})
CALL db.create.setNodeVectorProperty(n, 'embedding', $vector)
RETURN n
n:Paragraph:目标节点。embedding:向量属性的名称。$vector:要设置的向量值。
节点向量存储和检索
1.节点需要添加向量数组
可以选择一开添加节点的时候加一个向量属性
create (n:GroupProductA {name:'保高空',description: "保险产品可以保高空作业",embedding: [向量的具体值]}) return n
或者后续添加
MATCH (a:GroupProductA {name:'保高空' })
SET a+= { embedding: [向量具体数值] }
RETURN b;
2.给节点增加向量索引
CREATE VECTOR INDEX 索引名称 IF NOT EXISTS
FOR (具体的节点标签)
ON n.embedding
OPTIONS { indexConfig: {
`vector.dimensions`: 向量维度数值,
`vector.similarity_function`: 向量计算方法
}}
例如:
CREATE VECTOR INDEX HighDutyIdx IF NOT EXISTS
FOR (n:HighDuty)
ON n.embedding
OPTIONS { indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}}
3.计算向量余弦相似度
MATCH (a:GroupProductA)
WHERE a.embedding IS NOT NULL
WITH n,
// 计算向量余弦相似度或欧氏距离
vector.similarity.cosine(n.embedding, [0.1, 0.2, ...]) AS similarity
RETURN n.name, similarity
ORDER BY similarity DESC
LIMIT 10;
4.查询两个节点的向量相似度
MATCH (a:GroupProductA {name: '保高空'})
MATCH (b:GroupProductA {name:'团意'})
RETURN vector.similarity.cosine(a.embedding, b.embedding)
5.查询所有向量索引
SHOW VECTOR INDEXES
6.删除指定向量索引
DROP INDEX moviePlots
三.全文索引检索
1.要检索前首先要创建全文索引.
CREATE FULLTEXT INDEX 索引名称 FOR (n:标签) ON EACH [n.节点属性]
OPTIONS {
indexConfig: {
`fulltext.analyzer`: 'cjk',
`fulltext.eventually_consistent`: true
}
}
fulltext.analyzer是选用的分词器
fulltext.eventually_consistent设置为true,索引将处于最终一致性更新模式。这意味着更新将“尽快”在后台线程中应用,而不是像其他索引那样在事务提交期间应用
2.查看neo4j支持哪些分词器
call db.index.fulltext.listAvailableAnalyzers()
3.查询所有全文索引
SHOW FULLTEXT INDEXES
4.全文索引查询语句
CALL db.index.fulltext.queryNodes(索引名称, 查询的文本) YIELD node, score
RETURN node.节点属性, score
三.RAG向量检索最佳实践
1.先查询出所有符合的向量节点,有个阈值,比如大于0.8的查询出所有符合的节点
2.然后再通过这些符合的节点,根据节点之间的关系,找到想要查询出来的节点属性
3.根据查询出来的节点属性和用户问题,给大模型总结
4.可以考虑用全文索引和向量索引做混合搜索的RAG
其它
【
LangChain 是一个用于构建基于大语言模型(LLM)的应用程序的框架。它的核心作用是将语言模型与其他工具、数据来源等进行连接和协调,让开发者能更便捷地搭建复杂的 LLM 应用,比如问答系统、聊天机器人、智能检索等。
从网页内容关联来看,LangChain 可以与 Neo4j 结合使用,实现基于知识图谱的增强型应用。例如,借助 LangChain 调用 Neo4j 时,需要安装 APOC 插件,并在配置文件中进行相应设置(如添加 dbms.security.procedures.unrestricted=apoc.*,algo.*),从而利用知识图谱中的结构化数据提升 LLM 应用的准确性和逻辑性。
】
【
在这段关于Neo4j数据库的描述中,**全文索引检索**是一种针对节点属性的文本内容进行高效搜索的技术,核心是通过预先创建“全文索引”,实现对节点属性中关键词、短语的快速匹配和检索。以下是具体解析: ### 1. 核心作用 全文索引检索的目的是解决“对节点属性的文本内容进行灵活搜索”的需求。例如,若节点(如“电影”标签的节点)有“简介”属性(包含长文本描述),通过全文索引可以快速找到包含“科幻”“导演XXX”等关键词的所有节点,而无需逐行扫描所有节点的属性,大幅提升检索效率。 ### 2. 关键特点 - **依赖预创建的全文索引**:必须先通过`CREATE FULLTEXT INDEX`语句创建索引,明确要索引的节点标签(`n:标签`)和具体属性(`n.节点属性`),否则无法进行全文检索。 - **支持分词器配置**:通过`fulltext.analyzer`指定分词规则(如示例中的`cjk`,适用于中文、日文、韩文等东亚语言的分词),将文本拆分为有意义的“词”,确保搜索时能准确匹配关键词(例如中文“人工智能”会被正确拆分为“人工”“智能”,而非单个字符)。 - **索引更新模式**:`fulltext.eventually_consistent: true`表示索引采用“最终一致性”更新,即节点属性变化后,索引不会立即更新,而是在后台异步处理,适合对实时性要求不高但追求写入性能的场景;若设为`false`,则索引在事务提交时同步更新,实时性高但可能影响写入速度。 ### 3. 操作流程 - **创建索引**:通过`CREATE FULLTEXT INDEX`语句定义索引规则(关联的节点标签、属性、分词器等)。 - **查询索引**:使用`CALL db.index.fulltext.queryNodes(索引名称, 查询文本)`执行检索,返回匹配的节点(`node`)和匹配得分(`score`,得分越高表示匹配度越高)。 - **辅助操作**:可通过`call db.index.fulltext.listAvailableAnalyzers()`查看支持的分词器,通过`SHOW FULLTEXT INDEXES`查看已创建的全文索引。 ### 4. 与RAG向量检索的关系 文中提到“全文索引和向量索引做混合搜索的RAG”,说明两者是互补的检索方式: - 全文索引依赖关键词匹配,适合精确查找包含特定词汇的内容; - 向量检索(如RAG中常用的)则通过文本语义向量的相似度匹配,适合理解“语义相关性”(例如“如何入门机器学习”和“机器学习新手教程”虽关键词不同,但语义相近)。 混合使用可结合两者优势,提升检索的准确性和全面性。 总结来说,全文索引检索是Neo4j中针对文本内容的高效关键词检索方案,通过预定义索引和分词规则,实现对节点属性的快速文本匹配,是处理结构化图形数据库中文本搜索需求的重要工具。
】
最终我的代码如下:
# 导入所需模块
import os # 用于读取环境变量(如Neo4j连接参数和API token)
import requests # 用于调用嵌入向量API
import json # 用于处理JSON数据
from neo4j import GraphDatabase # 用于连接Neo4j图数据库
from tqdm import tqdm # 用于添加处理进度条
import numpy as np # 用于处理数值型数据(虽然此处未直接使用)# ---------- 配置Neo4j连接 ----------
uri = os.getenv("NEO4J_URI", "bolt://localhost:7687") # 支持默认本地连接
username = os.getenv("NEO4J_USERNAME", "neo4j") # 默认用户名
password = os.getenv("NEO4J_PASSWORD", "xxxx") # 默认密码
driver = GraphDatabase.driver(uri, auth=(username, password)) # 创建Neo4j驱动器# ---------- 配置Qwen嵌入接口 ----------
API_URL = "https://api.siliconflow.cn/v1/embeddings" # 嵌入API URL
API_MODEL = "Qwen/Qwen3-Embedding-8B" # 嵌入模型名
API_TOKEN = "sk-jy
xxxxx" # 嵌入服务Token(默认示例)
HEADERS = {"Authorization": f"Bearer {API_TOKEN}", # Bearer鉴权头"Content-Type": "application/json" # 数据格式为JSON
}# ---------- 获取向量函数 ----------
def get_embedding(text):payload = {"model": API_MODEL,"input": text}response = requests.post(API_URL, headers=HEADERS, json=payload) # 发送POST请求if response.status_code == 200:return response.json()["data"][0]["embedding"] # 返回嵌入向量else:print("Embedding API error:", response.text) # 打印错误信息return None# ---------- 正式批量更新Concept节点向量 ----------
def update_concepts_with_embeddings():with driver.session() as session:result = session.run("MATCH (c:Concept) RETURN elementId(c) AS eid, c.name AS name, c.type AS type")for record in tqdm(result):node_eid = record["eid"]name = record["name"]type_list = record["type"]type_str = ", ".join(type_list) if isinstance(type_list, list) else str(type_list)name_vec = get_embedding(name)type_vec = get_embedding(type_str)if name_vec:session.run("MATCH (c:Concept) WHERE elementId(c) = $eid CALL db.create.setNodeVectorProperty(c, 'name_vector', $vec) RETURN c", eid=node_eid, vec=name_vec)if type_vec:session.run("MATCH (c:Concept) WHERE elementId(c) = $eid CALL db.create.setNodeVectorProperty(c, 'type_vector', $vec) RETURN c", eid=node_eid, vec=type_vec)# ---------- 小规模测试:仅更新前N个Concept节点 ----------
def test_update_concepts_with_embeddings(sample_size=5):print(f"🔍 测试开始:选取前 {sample_size} 个 Concept 节点进行嵌入更新")with driver.session() as session:result = session.run("""MATCH (c:Concept)RETURN elementId(c) AS eid, c.name AS name, c.type AS typeLIMIT $limit""",limit=sample_size)for record in result:node_eid = record["eid"]name = record["name"]type_list = record["type"]type_str = ", ".join(type_list) if isinstance(type_list, list) else str(type_list)print(f"\n🧠 节点ID: {node_eid}")print(f"📌 名称: {name}")print(f"📎 类型: {type_str}")name_vec = get_embedding(name)type_vec = get_embedding(type_str)if name_vec:print(f"✅ name_vector 维度: {len(name_vec)}")session.run("MATCH (c:Concept) WHERE elementId(c) = $eid CALL db.create.setNodeVectorProperty(c, 'name_vector', $vec) RETURN c", eid=node_eid, vec=name_vec)else:print("❌ 获取 name_vector 失败")if type_vec:print(f"✅ type_vector 维度: {len(type_vec)}")session.run("MATCH (c:Concept) WHERE elementId(c) = $eid CALL db.create.setNodeVectorProperty(c, 'type_vector', $vec) RETURN c", eid=node_eid, vec=type_vec)else:print("❌ 获取 type_vector 失败")print("✅ 测试完成,请前往 Neo4j Studio 检查节点属性是否正确更新。")# ---------- 创建向量索引(Neo4j 5+) ----------
def create_vector_index():vector_dim = 4096 # Qwen 模型返回向量维度为 4096with driver.session() as session:session.run(f"""CREATE VECTOR INDEX concept_name_vector_indexFOR (c:Concept) ON (c.name_vector)OPTIONS {{indexConfig: {{`vector.dimensions`: {vector_dim}, `vector.similarity_function`: 'cosine'}}}}""")session.run(f"""CREATE VECTOR INDEX concept_type_vector_indexFOR (c:Concept) ON (c.type_vector)OPTIONS {{indexConfig: {{`vector.dimensions`: {vector_dim}, `vector.similarity_function`: 'cosine'}}}}""")# ---------- 相似节点查询函数 ----------
def query_similar_concepts(input_term):query_vec = get_embedding(input_term)if not query_vec:return []with driver.session() as session:try:result = session.run("""CALL db.index.vector.queryNodes('concept_name_vector_index', 3, $embedding)YIELD node, scoreWHERE score >= 0.8RETURN node.CUI AS cui, node.name AS name, scoreORDER BY score DESC""",embedding=query_vec)return result.data()except Exception as e:print("❌ 查询失败,请确认索引是否创建:", str(e))return []# ---------- 主程序入口 ----------
if __name__ == "__main__":# ✅ 创建索引(若首次运行)create_vector_index()# ✅ 测试模式:小批量处理# test_update_concepts_with_embeddings(sample_size=5)# ⚠️ 正式运行时请取消注释以下行# update_concepts_with_embeddings()# ✅ 查询测试concept_results = query_similar_concepts("Retired procedure")for item in concept_results:print(f"CUI: {item['cui']}, 名称: {item['name']}, 相似度: {item['score']:.4f}")
测试效果如下:
neo4j中向量也放上去了