Java HashMap 详解:从原理到实战
在 Java 集合框架中,HashMap 无疑是使用频率最高的容器之一。无论是日常开发中的数据缓存,还是业务逻辑中的键值对存储,HashMap 都以其高效的查询性能成为首选。本文将从底层结构、核心原理到实战技巧,全面解析 HashMap 的工作机制
 。
。
一、HashMap 的底层结构
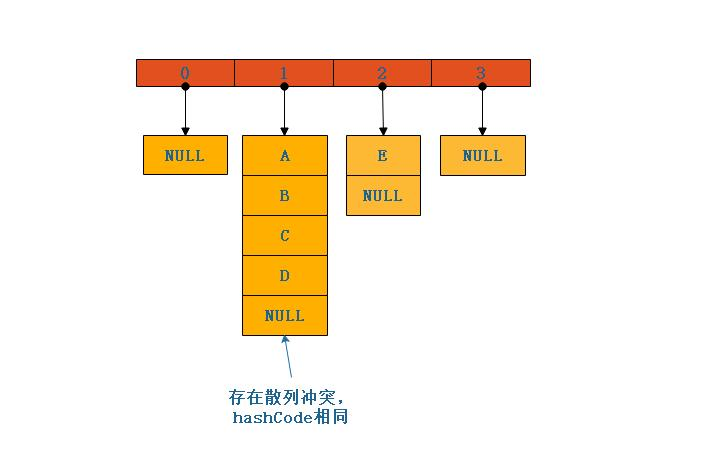
HashMap 在 JDK1.8 及之后采用数组 + 链表 + 红黑树的复合结构,这种设计是为了平衡查询效率和存储空间。
- 数组(哈希桶):作为底层基础容器,数组的每个元素称为 "哈希桶"。数组长度始终保持 2 的 n 次方(默认初始容量 16),这一设计与哈希计算的优化密切相关。
- 链表:当多个键值对映射到同一哈希桶时,会以链表形式存储。链表节点包含 key、value、next 指针和 hash 值四个核心字段。
- 红黑树:当链表长度超过阈值(默认 8)且数组长度≥64 时,链表会转化为红黑树。红黑树的引入将查询时间复杂度从 O (n) 优化至 O (logn),极大提升了大数据量下的查询性能。
二、核心原理:哈希与扩容
1. 哈希计算机制
HashMap 的高效查询依赖于精准的哈希映射:
- 计算 key 的 hashCode () 得到初始哈希值
- 通过扰动函数优化哈希值:(h = key.hashCode()) ^ (h >>> 16),将高 16 位与低 16 位异或,减少哈希冲突
- 计算数组下标:(n - 1) & hash,利用位运算替代取模操作,提升计算效率(仅当 n 为 2 的 n 次方时等效)
2. 扩容机制
当元素数量(size)超过负载因子(默认 0.75)与当前容量的乘积时,HashMap 会触发扩容:
- 新容量为原容量的 2 倍(保证始终是 2 的 n 次方)
- 重新计算所有元素的哈希位置并迁移(rehash)
- JDK1.8 通过高低位拆分优化迁移过程,避免了二次哈希计算
注意:频繁扩容会导致性能损耗,建议在预知数据量时指定初始容量(如new HashMap<>(1024))
三、关键方法解析
1. put () 方法执行流程
put 方法是 HashMap 的核心操作,完整流程如下:
- 计算 key 的 hash 值
- 检查数组是否为空,为空则初始化
- 根据 hash 值定位哈希桶:
- 若桶为空,直接插入新节点
- 若桶非空,检查首节点是否匹配(hash+equals),匹配则更新 value
- 若首节点不匹配,判断是链表还是红黑树:
- 链表:遍历查找匹配节点,找到则更新,否则尾部插入
- 红黑树:调用树节点插入方法
- 插入后检查链表长度,必要时转为红黑树
- 检查元素数量,超过阈值则扩容
2. get () 方法查询逻辑
查询操作体现了 HashMap 的性能优势:
- 计算 key 的 hash 值
- 根据 hash 定位哈希桶
- 优先检查首节点,不匹配则根据结构遍历:
- 链表:顺序遍历比对 hash 和 equals
- 红黑树:按树结构查找
四、常见问题与解决方案
1. 线程安全性问题
HashMap 是非线程安全的容器,多线程环境下可能出现:
- 扩容时的链表环问题(JDK1.7 及之前)
- 数据覆盖问题(put 操作并发执行)
解决方案:
- 使用ConcurrentHashMap替代(推荐)
- 加锁控制(如Collections.synchronizedMap())
2. 键的选择原则
- 推荐使用不可变对象作为 key(如 String、Integer)
- 重写 key 的 hashCode () 和 equals () 时需遵循:
- equals 相等则 hashCode 必须相等
- hashCode 相等 equals 可以不等
- 避免在 equals 中使用可变字段
3. 性能优化技巧
- 初始容量设置:根据预估数据量设置initialCapacity = (预计元素数 / 负载因子) + 1
- 负载因子调整:读写频繁场景可降低负载因子(如 0.5),内存紧张场景可提高(如 0.8)
- 避免使用 null 键:虽然允许 null 键,但会增加空指针风险和调试难度
五、实战案例:HashMap 的正确使用
TypeScript取消自动换行复制
// 推荐:指定初始容量(预估存储1000个元素)
Map<String, User> userMap = new HashMap<>(1334); // 1000/0.75≈1333.33
// 错误示范:使用可变对象作为key
Date key = new Date();
userMap.put(key, user);
key.setTime(0); // 修改key后无法正确获取value
// 正确做法:遍历方式选择
// JDK8+推荐使用forEach
userMap.forEach((k, v) -> {
System.out.println(k + ":" + v.getName());
});
六、总结
HashMap 通过哈希计算实现 O (1) 级别的查询效率,其数组 + 链表 + 红黑树的结构设计体现了典型的空间换时间思想。掌握 HashMap 的工作原理,不仅能写出更高效的代码,更能在出现性能问题时快速定位根源。
建议在实际开发中:
- 根据数据量合理设置初始容量
- 避免在多线程环境下使用 HashMap
- 优先选择不可变对象作为 key
希望本文能帮助你真正理解 HashMap,让这个强大的工具在你的代码中发挥最大价值