SGLang 推理框架核心组件解析:请求、内存与缓存的协同工作
SGLang 推理框架核心组件解析:请求、内存与缓存的协同工作
在当今大语言模型(LLM)服务的浪潮中,高效的推理框架是决定服务质量与成本的关键。SGLang 作为一个高性能的 LLM 推理和部署库,其内部精巧的设计确保了高吞吐量和低延迟。为了实现这一目标,SGLang 在其核心调度与内存管理机制中,通过一系列紧密协作的对象来处理用户请求和优化计算资源,特别是对 KV 缓存的管理。在 SGLang 的调度批次(ScheduleBatch)中,reqs、req_to_token_pool、token_to_kv_pool_allocator 和 tree_cache 这四个关键字段,分别代表了从请求到底层缓存管理的不同层面,它们之间的协同关系构成了 SGLang 高效推理的基石。
请求的表示:Req 对象
一切处理始于请求。在 SGLang 中,每一个进入系统的用户请求都被封装成一个 Req 对象(位于 managers.schedule_batch.Req)。这个对象是请求在系统内流转的基本单位,包含了与该请求相关的所有信息,例如请求的唯一标识符(rid)、输入的文本序列(prompt)、生成的配置参数(如温度、最大新 token 数)以及请求当前的状态(如等待中、运行中、已完成)。
在 ScheduleBatch 中,reqs 字段是一个列表,容纳了当前批次中所有正在被处理的 Req 对象。调度器根据一定的策略(如先到先服务、最长前缀匹配等)从等待队列中挑选 Req 对象,将它们组合成一个 ScheduleBatch 进行统一处理。因此,reqs 字段是整个推理流程的入口,后续所有的内存分配和计算都围绕着这个列表中的请求展开。
两级内存池:从请求到物理内存的映射
为了高效管理 GPU 内存,尤其是占用巨大的 KV 缓存,SGLang 采用了一种精巧的两级内存池机制。req_to_token_pool 和 token_to_kv_pool_allocator 正是这一机制的核心体现。
首先是 ReqToTokenPool(请求到 Token 池的映射)。这个组件在 ScheduleBatch 中表现为 req_to_token_pool 字段,其核心作用是建立每个请求(Req)与其包含的 token 在逻辑缓存池中位置的映射关系。它本质上可以理解为一个二维表,第一维由请求的池索引(req_pool_idx)确定,第二维则是该请求内部 token 的序列位置。表中的值是一个逻辑索引(out_cache_loc),指向该 token 在全局 Token 缓存池中的具体位置。通过这种方式,系统无需关心每个请求的具体 token 内容,只需通过索引就能快速定位其缓存信息。
比如下面这个就是一个ScheduleBatch批次有两个Req请求时的情况(batch_size最大为48,但当前batch_size=2):
req_to_token字段的张量形状:torch.Size([48, 131076])
{ 'size': 48, 'max_context_len': 131076, 'device': 'cuda', 'req_to_token': tensor([[1, 2, 3, ..., 0, 0, 0],[1, 8, 9, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]], device='cuda:0', dtype=torch.int32), 'free_slots': [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47]}
接下来是 TokenToKVPoolAllocator(Token 到 KV 缓存池的分配器)。req_to_token_pool 提供的仅仅是逻辑位置,而 token_to_kv_pool_allocator 则负责将这个逻辑位置与 GPU 上的物理内存块对应起来。它管理着一个巨大的、为所有请求共享的物理 KV 缓存池。当一个 token 需要被存储时,token_to_kv_pool_allocator 会为其分配具体的内存地址。这个物理缓存池通常是三维或四维的结构,维度包括模型层数、注意力头数量和头维度等。当 req_to_token_pool 将一个请求的 token 映射到一个逻辑索引后,token_to_kv_pool_allocator 就利用这个索引,在物理池的相应位置存取实际的 Key-Value 向量数据。
比如上面两个批次的ScheduleBatch对应的TokenToKVPoolAllocator内容如下:
free_slots字段表示未分配的token缓存,形状为:torch.Size([154788])
ipdb> batch.token_to_kv_pool_allocator.__dict__
{'size': 154801, 'dtype': torch.float16, 'device': 'cuda', 'page_size': 1,
'free_slots': tensor([ 15, 16, 17, ..., 154800, 154801, 7], device='cuda:0'),
'is_not_in_free_group': True, 'free_group': [],
'_kvcache': <sglang.srt.mem_cache.memory_pool.MHATokenToKVPool object at 0x7f3cdde850d0>}
前缀共享的利器:RadixCache
在多用户、多请求的服务场景中,不同请求的输入(prompt)往往有重叠的前缀。例如,多个用户可能都在进行相似主题的问答。如果能复用这些相同前缀的 KV 缓存,将极大减少重复计算,提升系统吞吐量。这正是 RadixCache(基数缓存,在 ScheduleBatch 中体现为 tree_cache 字段)发挥作用的地方。
RadixCache 采用树状结构(Trie Tree 或称前缀树)来组织和存储所有处理过的 token 的 KV 缓存。树的每条边代表一个 token ID,从根节点到任意节点的路径就构成了一个 token 序列(即前缀)。每个节点则存储着对应 token 的 KV 缓存的逻辑索引(out_cache_loc)。
当一个新的请求进入系统时,SGLang 会利用 RadixCache 查找其输入序列的最长公共前缀。一旦找到匹配的前缀,该前缀对应的所有 token 的 KV 缓存就可以被直接复用,无需重新计算。系统只需从前缀结束的位置开始进行新的计算。这个过程涉及到与 ReqToTokenPool 和 TokenToKVPoolAllocator 的紧密交互:RadixCache 负责找到可复用的 token 及其逻辑索引,然后更新 req_to_token_pool,将当前请求的相应 token 位置指向这些已存在的逻辑索引。TokenToKVPoolAllocator 则根据这些逻辑索引提供对底层物理内存的访问。
对于新生成的 token,RadixCache 也会将其插入到树中,并由 TokenToKVPoolAllocator 为其分配新的缓存空间,从而不断扩充可供复用的缓存池。
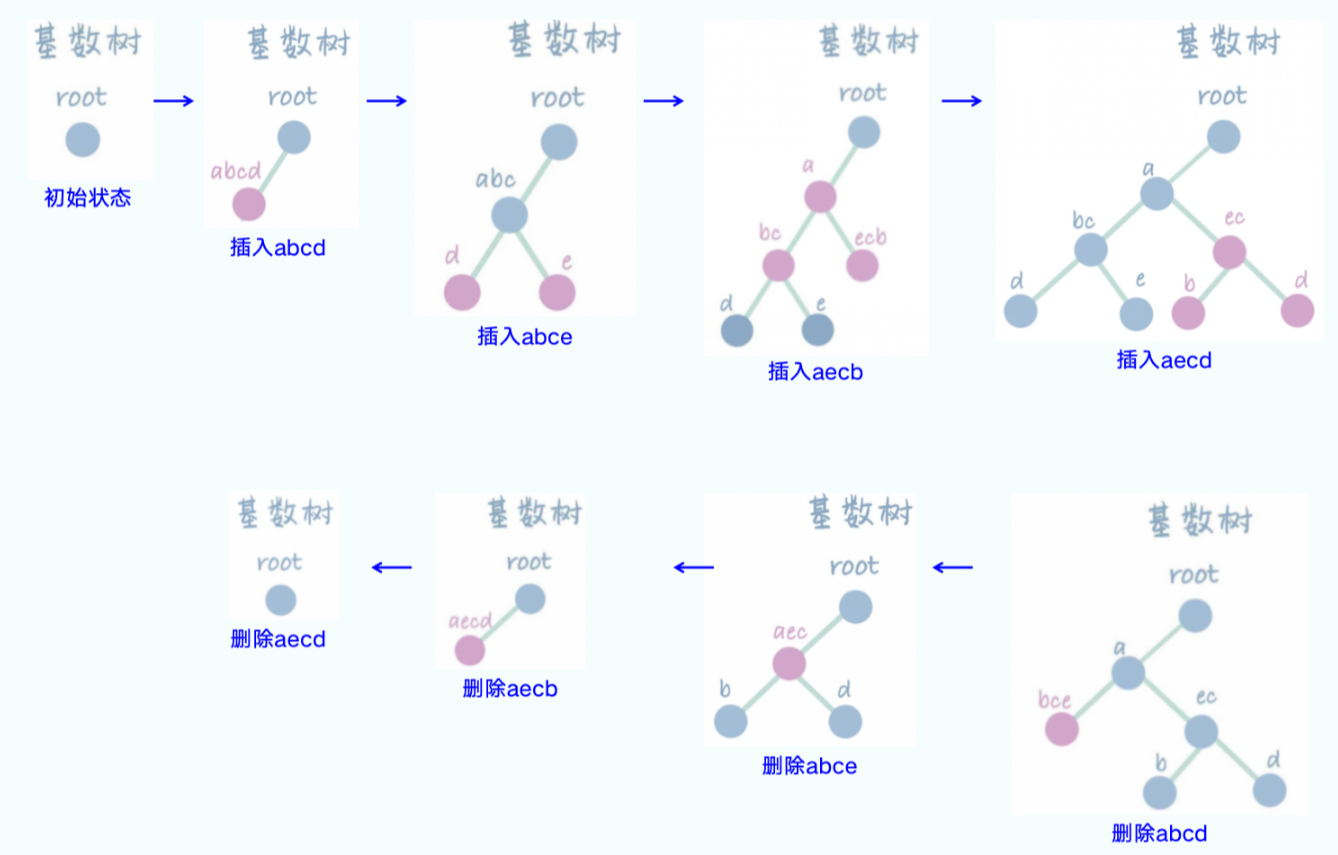
协同工作的流程
这四个组件在 ScheduleBatch 中的关系可以总结为一个清晰的流程:
- 请求聚合:调度器将多个
Req对象收集到ScheduleBatch的reqs字段中。 - 前缀匹配与复用:系统利用
tree_cache(RadixCache) 对reqs列表中的每个请求进行前缀匹配。对于匹配到的公共前缀,直接复用其在RadixCache中已有的 KV 缓存信息。 - 逻辑映射建立:
tree_cache将找到的或新创建的 token 的逻辑缓存索引(out_cache_loc)填充到req_to_token_pool中,从而建立了每个请求与其 token 逻辑缓存位置的映射。 - 物理内存分配与访问:当模型需要进行注意力计算时,它会通过
req_to_token_pool获取到所需 token 的逻辑索引,再由token_to_kv_pool_allocator将这些逻辑索引转换为 GPU 上的物理内存地址,最终读取或写入实际的 Key-Value 数据。
通过 Req 对象对请求进行封装,再经由 RadixCache 实现高效的前缀共享,最后通过 ReqToTokenPool 和 TokenToKVPoolAllocator 这两级内存池完成从逻辑请求到物理内存的精确映射与管理,SGLang 构建了一个强大而高效的推理引擎。这四个组件环环相扣,共同确保了 GPU 资源的最大化利用和推理服务的高性能表现。