洞见AI时代数据底座的思考——YashanDB亮相2025可信数据库发展大会
7月16日,由中国通信标准化协会主办、中国信息通信研究院、中国通信标准化协会大数据技术标准推进委员会(CCSA TC601)承办的2025可信数据库发展大会在北京隆重召开,深圳计算科学研究院(深算院)携崖山数据库全栈解决方案参展,并在同期举办的“多模与分析型数据库&云原生数据库”论坛上,YashanDB技术总监欧伟杰发表《YashanDB:AI时代数据底座的思考》主旨演讲。作为国产数据库领域的创新代表,YashanDB此次参会不仅展示了其在AI时代数据库技术的前沿探索,更通过多项技术突破和行业实践案例,向业界展示了其作为新一代数据基础设施的核心价值。
会上,中国信息通信研究院权威发布《数据库发展研究报告(2025年)》与《中国数据库产业图谱(2025年)》。YashanDB深度参与报告核心章节“数据库关键技术”的研讨,基于其共享集群两地三中心容灾、集群节点秒级扩容以及领先的智能自治数据库体系,贡献了YashanDB在共享集群架构与AI for DB领域的突破性实践与前瞻洞察。


此次发布的产业图谱中,YashanDB再次强势入选「事务型数据库」领域,覆盖金融、政务及能源三大关键行业,更在金融行业事务型数据库领域获评“竞争者”;同时,其安全性能力亦获认可,入选「数据库安全」领域。 此次多维度入选,是业界对YashanDB核心技术实力、产品竞争力及安全能力的高度认可。

在随后的论坛分享中,面对IDC预测2028年全球数据量达393.8ZB的爆炸式增长,欧伟杰表示,“当生成式AI每天创造数十亿文本、图像、代码时,这场数据基础设施的深层变革,将决定未来AI产业的天花板高度。”欧伟杰援引近期Databricks收购Neon、Couchbase被高价收购等案例,表示数据管理与AI深度融合已成必然趋势,但随之也面临“3V+1S”挑战。
数据爆发式增长(Volume):非结构化数据占比超80%,高维向量计算复杂度飙升;
数据实时变化(Velocity):大模型需动态知识注入,传统批处理难以满足金融、医疗等行业的毫秒级响应;
多模态数据的语义鸿沟(Variety):传统数据库无法兼顾语义对齐、扩展性、实时性,且表征对齐不彻底,缺乏统一数据管理框架;
安全隐私困境(Security):大模型数据需求与隐私保护矛盾突出,实时脱敏要求超越传统加密能力,亟需新型安全系统。

针对这些挑战,YashanDB基于自主创新的技术路线,通过持续的理论突破和工程实践,构建了完整的AI底座数据管理能力。
基于原创理论提出“受限资源扩展”方案,在保障查询确定精度前提下实测效率提升5个数量级,有效解决了关系数据的大数据规模挑战。
基于语义连接实现多模态异构数据的跨模计算,支持关系&向量的混合查询,高效支撑AI多模态数据融合处理。
通过自适应异步处理方法,实现可扩展的实时数据更新及查询技术,同时兼顾更新查询效率与数据的实时性。
构建多模态安全架构,涵盖分层加密、动态访问控制、支持TEE的隐私保护跨模计算及轻量化隐私增强技术,全面保障数据全生命周期安全。
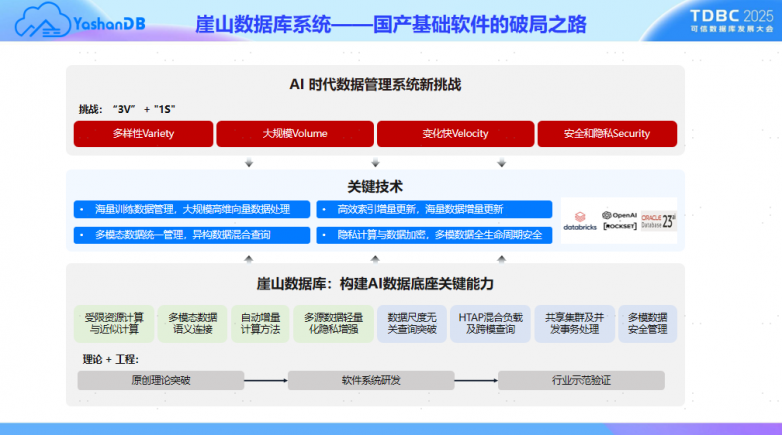
此外,YashanDB在HTAP混合负载、共享集群及并发事务处理等领域的突破,共同构建了其作为AI时代高性能大数据处理的核心基础能力。欧伟杰特别强调,YashanDB在早期进行内核设计时,就前瞻性地考虑了向高端共享集群形态的演进,并原创性地采用细粒度多版本并发管理机制、自适应异步事务调度、全局资源运行时调度、去中心化事务管理等技术,突破分布式数据库硬件依赖瓶颈,其4节点TPC-C性能突破618万tpmC,单节点横向扩展比大于0.8,全国产环境下实现与非国产环境下国际产品性能持平。目前,YashanDB已应用于央行数研所底层数据库升级、头部证券公司核心资产估值系统数据库升级、深圳燃气集团核心业务迁移、深圳水务集团“深水云脑”等重点项目。
未来,YashanDB将持续深化“理论+工程”的创新模式,围绕AI时代的数据管理需求,重点突破多模态数据处理、实时计算和隐私保护等关键技术,为企业的数字化转型提供更强大、更可靠、更安全的数据底座。