Linux | Bash 子字符串提取
注:本文为 “ Bash 子字符串提取” 相关合辑。
英文引文,机翻未校。
如有内容异常,请看原文。
How to Extract Bash Substring? [5 methods]
如何提取 Bash 子字符串?[5 种方法]
2024-04-28 00:00:00
In Bash, a substring is a part of a string derived or extracted from the string. Substring provides powerful features for text manipulation and processing. Substring extraction is essential for text manipulation.
在 Bash 中,子字符串是从字符串中派生或提取出来的一部分。子字符串为文本处理和操作提供了强大的功能。子字符串提取是文本操作中必不可少的环节。
You can use the following methods to extract Bash substring:
你可以使用以下方法提取 Bash 子字符串:
-
Using Bash’s substring expansion:
${input_string:start_index:length}
使用 Bash 的子字符串扩展:${input_string:start_index:length} -
Using the “cut” command:
cut -c N-M <<< input_string
使用 “cut” 命令:cut -c N-M <<< input_string -
Using the “awk” command:
awk '{print substr($input_string,start_index, length)}'
使用 “awk” 命令:awk '{print substr($input_string,start_index, length)}' -
Using the “expr” command:
expr substr input_string start_index length
使用 “expr” 命令:expr substr input_string start_index length -
Using the “grep” command:
echo input_string | grep -o “substring”
使用 “grep” 命令:echo input_string | grep -o “substring”
There are two types of bash substring extraction: index-based and pattern-based.
Bash 子字符串提取有两种类型:基于索引的和基于模式的。
In this article, I’ll explain 4 methods of index-based substring extraction and 3 methods of pattern-based substring extraction in Bash. So let’s get started!
在本文中,我将介绍 Bash 中 4 种基于索引的子字符串提取方法和 3 种基于模式的子字符串提取方法。让我们开始吧!
A. Index-Based Substring Extraction
A. 基于索引的子字符串提取
Index-based extraction involves extracting a substring from an original string based on specified start and end positions of characters. Bash strings are zero-indexed. You can extract a substring based on the index in various ways like Bash’s substring expansion, using the “cut” command, using the “awk” command, and using the “expr” command.
基于索引的提取是指根据指定的字符起始和结束位置从原始字符串中提取子字符串。Bash 字符串是零索引的。你可以通过多种方式基于索引提取子字符串,例如使用 Bash 的子字符串扩展、“cut” 命令、“awk” 命令和 “expr” 命令。
1. Using Bash’s Substring Expansion
使用 Bash 的子字符串扩展
The simplest method to extract a substring from a string is to use the expression ${string:start_index:length} where the string variable holds the main text or string. The start_index denotes the initial position of characters from which the extraction begins, while the length specifies the size of the resulting substring.
从字符串中提取子字符串最简单的方法是使用表达式 ${string:start_index:length},其中字符串变量包含主要文本或字符串。start_index 表示提取开始的字符初始位置,而 length 指定结果子字符串的长度。
You can check the following examples of substring extraction for a clearer understanding of the topic:
你可以查看以下子字符串提取示例,以更清晰地理解该主题:
i. From the Start of the String
i. 从字符串开头
To extract a substring from the start of the string set the “start_index” value to 0 and specify the “length” as your preference. For example, to extract a substring of length 11 from the starting, you can check the following script:
要从字符串开头提取子字符串,请将 “start_index” 设置为 0,并根据需要指定 “length”。例如,要从开头提取长度为 11 的子字符串,你可以查看以下脚本:
#!/bin/bash#Define a string variable
string="Linuxsimply and Linux"#Print the string variable
printf "The main string:\n$string"#Extract a substring from the first character of the string
substring="${string:0:11}"#Print the substring value
printf "\n\nThe substring:\n$substring\n"
EXPLANATION
解释
The syntax ${string:0:11} extracts a substring from the first character (index 0) and includes the next 11 characters of the string variable.
语法 ${string:0:11} 从第一个字符(索引 0)开始提取子字符串,并包含字符串变量接下来的 11 个字符。

The output shows the extracted substring of a specified length from the main string.
输出显示了从主字符串中提取的指定长度的子字符串。
ii. From the Middle of the String
ii. 从字符串中间
To extract a substring from the middle of the string set the “start_index” to any index value rather than 0 and the “last_index” of the string, and specify the “length”.
要从字符串中间提取子字符串,请将 “start_index” 设置为除 0 和字符串 “last_index” 之外的任何索引值,并指定 “length”。
You can check the following example to extract a substring of length 9 from the original string, starting at index 8:
你可以查看以下示例,从原始字符串的索引 8 开始提取长度为 9 的子字符串:
#!/bin/bash#Define a string variable
string="Extract substring from middle."#Print the string variable
printf "The main string:\n$string"#Extract a substring from the first character of the string
substring="${string:8:9}"#Print the substring value
printf "\n\nThe substring:\n$substring\n"
EXPLANATION
解释
In the script, substring="${string:8:9}" extract a substring from the string variable. The substring is extracted from the index 8 to index 16. As the substring length is 9, the ending index is 8+9-1=16.
在脚本中,substring="${string:8:9}" 从字符串变量中提取子字符串。子字符串从索引 8 提取到索引 16。由于子字符串长度为 9,结束索引为 8+9-1=16。

The output shows the extracted substring from the middle of the main string.
输出显示了从主字符串中间提取的子字符串。
iii. From the Positive Index Position
iii. 从正索引位置
Positive position refers to the positions or indices counted from the beginning of the string, starting with 0 for the first character.
正位置是指从字符串开头开始计数的位置或索引,第一个字符为 0。
To extract a string from the positive position, provide the “start_index” to indicate from which the extraction should begin. Follow the script below:
要从正位置提取字符串,请提供 “start_index” 以指示提取开始的位置。遵循以下脚本:
#!/bin/bash#Define a string variable
string="Extract substring from positive starting position."#Print the string variable
printf "The main string:\n$string"#Extract a substring from a positive starting position
substring="${string:18}"#Print the substring value
printf "\n\nThe substring:\n$substring\n"
EXPLANATION
解释
The code snippet substring="${string:18}" extracts a substring from the variable string, starting at index 18 and extending to the end of the string as length is not mentioned.
代码片段 substring="${string:18}" 从变量字符串中提取子字符串,从索引 18 开始,由于未提及长度,一直延伸到字符串末尾。

The result displays the substring obtained from the positive starting position and continuing until the end index.
结果显示了从正起始位置获取并一直延续到结束索引的子字符串。
iv. From the Negative Starting Index Position
iv. 从负起始索引位置
The negative starting position refers to the character index counted backward of the string, with -1 representing the last character. To extract a substring from the negative starting position use the syntax, substring="${string: -start_index: length}".
负起始位置是指从字符串末尾向后计数的字符索引,-1 表示最后一个字符。要从负起始位置提取子字符串,请使用语法 substring="${string: -start_index: length}"。
See the following bash scripts to extract a substring from a negative position:
查看以下 bash 脚本,从负位置提取子字符串:
To simply specify the negative “start_index” use the code below:
只需指定负 “start_index”,请使用以下代码:
#!/bin/bash#Define a string variable
string="Extract substring from the negative starting position."#Print the string variable
printf "The main string:\n$string"#Extract a substring from the negative starting position
substring="${string: -27}"#Print the substring value
printf "\n\nThe substring:\n$substring\n"
EXPLANATION
解释
Here, substring="${string: -27}" extracts a substring from the negative “start_index” -27 which is n and continues until the end of the string.
在这里,substring="${string: -27}" 从负 “start_index” -27(即 n)开始提取子字符串,并一直延续到字符串末尾。

The output shows the extracted substring from the negative starting position of the main string.
输出显示了从主字符串的负起始位置提取的子字符串。
You can set both “start_index” and “length” too. In that case, follow the below script:
你也可以同时设置 “start_index” 和 “length”。在这种情况下,请遵循以下脚本:
#!/bin/bash#Define a string variable
string="Extract substring from the negative starting position."#Print the string variable
printf "The main string:\n$string"#Extract a substring from the negative starting position
substring="${string: -27: 8}"#Print the substring value
printf "\n\nThe substring:\n$substring\n"

The output shows the extracted substring from the negative starting position which is 27th character from the end of the string, with a length of 8 characters.
输出显示了从负起始位置(即从字符串末尾数第 27 个字符)提取的子字符串,长度为 8 个字符。
2. Using the “cut” command
使用 “cut” 命令
If you want to extract the Nth to Mth character of a main string using the “cut” command along with the -c option, you can use the syntax cut -c N-M <<< input_string.
如果你想使用 “cut” 命令结合 -c 选项提取主字符串的第 N 到第 M 个字符,可以使用语法 cut -c N-M <<< input_string。
Check the following example:
查看以下示例:
cut -c 9-17<<< 'Extract Substring'
EXPLANATION
解释
Here, the cut command with the -c option extracts a substring consisting of characters 9 to 17 from the main string Extract Substring.
在这里,带有 -c 选项的 cut 命令从主字符串 Extract Substring 中提取由第 9 到第 17 个字符组成的子字符串。

The output shows the extracted “Substring” from the main string “Extract Substring”.
输出显示了从主字符串 “Extract Substring” 中提取的 “Substring”。
3. Using the “awk” Command
使用 “awk” 命令
The awk command is equipped with a built-in substr($s, i, n) function that allows to directly invoke the function for obtaining substrings. The “substr($s, i, n)” function has three arguments which are input string (s), start index (i), and length (n). The syntax to extract a substring using the “awk” command is as below:
awk 命令配备了内置的 substr($s, i, n) 函数,可以直接调用该函数获取子字符串。“substr($s, i, n)” 函数有三个参数,分别是输入字符串(s)、起始索引(i)和长度(n)。使用 “awk” 命令提取子字符串的语法如下:
awk '{print substr($s, i, n)}'
You can check the following example:
你可以查看以下示例:
awk '{print substr($0, 11, 9)}' <<< 'Extract a substring'
EXPLANATION
解释
The awk command extracts a substring from the input string ‘Extract a substring’. It starts at the 11th character (‘s’) and includes the next 9 characters.
awk 命令从输入字符串 ‘Extract a substring’ 中提取子字符串。它从第 11 个字符(‘s’)开始,并包含接下来的 9 个字符。

The output shows the extracted substring from the input string.
输出显示了从输入字符串中提取的子字符串。
4. Using the “expr” command
使用 “expr” 命令
The expr command extracts a substring from a string based on a specific starting index and length whose syntax is expr substr input_string start_index length. Here, substr is a subcommand of expr. Check the following example:
expr 命令根据特定的起始索引和长度从字符串中提取子字符串,其语法为 expr substr input_string start_index length。这里,substr 是 expr 的一个子命令。查看以下示例:
expr substr "Extracting substring using awk" 12 9
EXPLANATION
解释
The expr command extracts a substring from the given string, starting at position 12 and including the next 9 characters.
expr 命令从给定字符串中提取子字符串,从位置 12 开始,并包含接下来的 9 个字符。

The output displays the extracted substring from the main string.
输出显示了从主字符串中提取的子字符串。
B. Pattern-Based Extraction
B. 基于模式的提取
Pattern-based substring extraction in Bash involves using patterns or regular expressions to identify and isolate specific substrings within a larger string. This is usually achieved through tools like ‘grep’, ‘sed’, or ‘awk commands. In this section, 3 ways of pattern-based substring extraction will be discussed.
Bash 中基于模式的子字符串提取涉及使用模式或正则表达式来识别和分离较大字符串中的特定子字符串。这通常通过 ‘grep’、‘sed’ 或 ‘awk’ 等工具实现。在本节中,将讨论 3 种基于模式的子字符串提取方法。
1. Using “cut” Command
使用 “cut” 命令
To extract a substring, utilize the “cut” command with the -d option to define a delimiter and the -f option to designate the field number of the desired substring. The syntax is, cut -d '<delimiter>' -f <field_number>.
要提取子字符串,请使用带有 -d 选项的 “cut” 命令定义分隔符,并使用 -f 选项指定所需子字符串的字段编号。语法为 cut -d '<delimiter>' -f <field_number>。
For a pattern-based substring extraction using the cut command, use the following Bash script:
要使用 cut 命令进行基于模式的子字符串提取,请使用以下 Bash 脚本:
#!/bin/bash# Declare a variable
string="Extract Substring"# Extract the substring
substring1=$(echo ${string} | cut -d ' ' -f 1)
substring2=$(echo ${string} | cut -d ' ' -f 2)#Print the string variable
printf "The main string:\n$string\n\n"# Print the substring
echo "First substring: $substring1"
echo "Second substring: $substring2"
EXPLANATION
解释
The cut command along with the echo command extracts the fields (substring) from the original string based on the delimiter (space), which is specified by the option -d. The -f option specifies which field to extract.
cut 命令与 echo 命令一起,根据由 -d 选项指定的分隔符(空格)从原始字符串中提取字段(子字符串)。-f 选项指定要提取的字段。
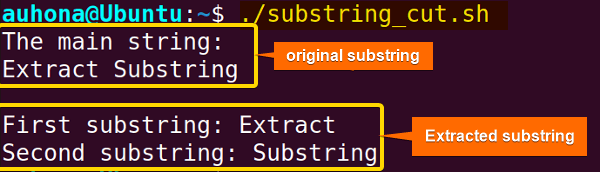
The output shows the extracted fields from the main string using the space as a delimiter.
输出显示了使用空格作为分隔符从主字符串中提取的字段。
2. Using “awk” Command
使用 “awk” 命令
You can utilize the awk command along with the field separator option -F. Follow the below script to extract pattern-based substring using the awk command:
你可以将 awk 命令与字段分隔符选项 -F 一起使用。遵循以下脚本,使用 awk 命令提取基于模式的子字符串:
#!/bin/bash#Define a string variable
string="Try to extract substring using awk."#Print the string variable
printf "The main string:\n$string\n\n"#Extract a substring
awk -F 'to |using ' '{print $2}' <<< "$string"
EXPLANATION
解释
Here, awk -F 'to |using ' sets the field separator -F to a regular expression that matches either “to ” or “using “. As a result, the awk command treats the text “to ” and “using ” as separate fields. So the string is separated into three fields. The '{print $2}' instructs awk to print the second field which is the text between “to” and “using”.
在这里,awk -F 'to |using ' 将字段分隔符 -F 设置为一个正则表达式,该表达式匹配 “to ” 或 “using ”。因此,awk 命令将文本 “to ” 和 “using ” 视为单独的字段。这样,字符串被分成三个字段。'{print $2}' 指示 awk 打印第二个字段,即 “to” 和 “using” 之间的文本。
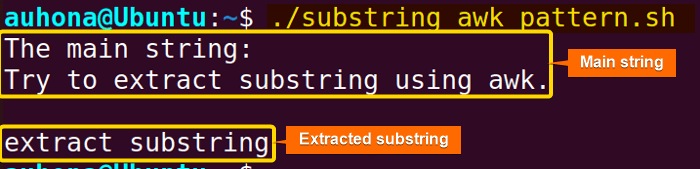
Here’s the extracted substring shown in the output.
这是输出中显示的提取的子字符串。
3. Using “grep” Command
使用 “grep” 命令
The grep command can search for a specific substring along with the -o option. Check the following example to extract substring using the “grep” command:
grep 命令可以结合 -o 选项搜索特定的子字符串。查看以下示例,使用 “grep” 命令提取子字符串:
echo "Extracting substring using patterns" | grep -o 'substring'
EXPLANATION
解释
The grep command with the -o option searches for the specified pattern substring in the input string “Extracting substring using patterns”.
带有 -o 选项的 grep 命令在输入字符串 “Extracting substring using patterns” 中搜索指定的模式 substring。

The output shows the searched substring from the input string.
输出显示了从输入字符串中搜索到的子字符串。
Common Issues of Bash Substring Extraction
Bash 子字符串提取的常见问题
When working with substring and its extraction, users may encounter some common issues like off-by-one errors, handling spaces, and unintended option interpretation. This section will discuss these issues with their corresponding solutions:
在处理子字符串及其提取时,用户可能会遇到一些常见问题,如差一错误、空格处理和意外的选项解释。本节将讨论这些问题及其相应的解决方案:
1. Off-By-One Errors
差一错误
As Bash strings are zero-indexed, sometimes off-by-errors can occur if you start counting from 1 instead of 0. So be mindful that the initial character of the string is located at position 0 to prevent potential off-by-one errors.
由于 Bash 字符串是零索引的,如果你从 1 而不是 0 开始计数,有时会出现差一错误。因此,要注意字符串的第一个字符位于位置 0,以防止潜在的差一错误。
2. Handling spaces
处理空格
Handling spaces in Bash substring extraction requires careful consideration. Spaces can affect the interpretation of field separators and indices. When handling spaces in Bash:
在 Bash 子字符串提取中处理空格需要谨慎考虑。空格会影响字段分隔符和索引的解释。在 Bash 中处理空格时:
- Use double quotes for variable expansion (
"${variable:start:length}"). - 对变量扩展使用双引号(
"${variable:start:length}")。 - Quote arguments in commands to preserve spaces (
cut -d ' ' -f2). - 在命令中引用参数以保留空格(
cut -d ' ' -f2)。
3. Unintended Option Interpretation
意外的选项解释
When utilizing negative indices, it’s important to include a space before the ‘–’. Omitting this space may lead Bash to interpret the negative index (say -10) as an option for the command rather than as a negative index. For example,
使用负索引时,在 ‘–’ 前加一个空格很重要。省略这个空格可能会导致 Bash 将负索引(例如 -10)解释为命令的选项,而不是负索引。例如:
#!/bin/bash#Define the string
string='Bash substring extraction'#substring extraction
#with a space before the negative index
substring1=${string: -10}#without a space before the negative index
substring2=${string:-10}echo "The substring with space before negative index:"
echo $substring1
echo "The substring without space before negative index:"
echo $substring2

Here, due to not using space before the negative index, the second substring extraction doesn’t occur and the main string is shown instead of the extracted substring.
在这里,由于在负索引前没有使用空格,第二次子字符串提取没有进行,显示的是主字符串而不是提取的子字符串。
Conclusion
结论
In conclusion, mastering substring and its manipulation is a valuable skill for any Bash script developer. It’s necessary for parsing log files and manipulating text or data. This article discusses 4 methods of index-based substring extraction and 3 methods of pattern-based substring extraction. It also shows the common issues with their solutions that can cause problems while working with Bash substring. Hope this guide clears your concepts on the Bash substring and its extraction and eases your advanced approaches.
总之,掌握子字符串及其操作对于任何 Bash 脚本开发人员来说都是一项有价值的技能。它对于解析日志文件和处理文本或数据是必不可少的。本文讨论了 4 种基于索引的子字符串提取方法和 3 种基于模式的子字符串提取方法。它还展示了在处理 Bash 子字符串时可能出现的常见问题及其解决方案。希望本指南能澄清你对 Bash 子字符串及其提取的概念,并简化你的高级操作。
People Also Ask
人们还会问
What are the applications of substring in Bash?
Bash 中子字符串的应用有哪些?
Bash substring extraction is commonly used in scripting for various purposes, such as:
Bash 子字符串提取在脚本中通常用于多种目的,例如:
- Data processing and extraction.
数据处理和提取 - Text manipulation
文本操作 - Data cleaning
数据清洗 - String manipulation in automation
自动化中的字符串操作 - Filename manipulation
文件名操作
How do you replace a substring in Bash?
如何在 Bash 中替换子字符串?
In Bash, you can replace a substring in a string using the ‘awk’ command. Here’s a simple example:
在 Bash 中,你可以使用 ‘awk’ 命令替换字符串中的子字符串。以下是一个简单示例:
echo 'Hello, World!' | awk '{gsub(/World/, "Universe"); print}'
Here, gsub function inside the “awk” command searches for the regular expression /World/ in the input text and replaces all occurrences with the string “Universe”.
在这里,“awk” 命令中的 gsub 函数在输入文本中搜索正则表达式 /World/,并将所有出现的地方替换为字符串 “Universe”。
How to find a substring in a string in Bash?
如何在 Bash 中查找字符串中的子字符串?
In Bash, you can find a substring using the [[ ]] operator along with the * wildcard for pattern matching. Here’s an example:
在 Bash 中,你可以使用 [[ ]] 运算符结合 * 通配符进行模式匹配来查找子字符串。以下是一个示例:
#!/bin/bashstring="Hello, World!"
substring="World"if [[ $string == *"$substringd"* ]]; then
echo "Substring found in the string."
else
echo "Substring not found in the string."
fi
What is the “substr” function in Unix?
Unix 中的 “substr” 函数是什么?
The ‘substr’ function is a text-processing tool for extracting substring from a string based on a specific starting position and optional length. The syntax is substr(string, start [, length]). In AWK, the “substr” function is used to extract a portion of a string.
‘substr’ 函数是一种文本处理工具,用于根据特定的起始位置和可选长度从字符串中提取子字符串。其语法为 substr(string, start [, length])。在 AWK 中,“substr” 函数用于提取字符串的一部分。
Extracting a Substring in Bash
在 Bash 中提取子字符串
2025-06-04 00:00:00
1. Overview
概述
Extracting a substring from a string is a fundamental and common operation of text processing in Linux.
从字符串中提取子字符串是 Linux 中文本处理的一项基本且常见的操作。
In this tutorial, we’ll examine various ways to extract substrings using the Linux command line.
在本教程中,我们将探讨使用 Linux 命令行提取子字符串的多种方法。
2. Introduction to the Problem
问题介绍
As the name suggests, a substring is a part of a string. The problem is pretty straightforward; we want to extract a part of a given string. However, there are two different types of extraction requirements: index-based and pattern-based.
顾名思义,子字符串是字符串的一部分。这个问题相当直接,我们希望从给定的字符串中提取一部分。然而,提取需求有两种不同的类型:基于索引的和基于模式的。
Let’s illustrate the two different requirements with a couple of examples.
让我们通过几个例子来说明这两种不同的需求。
An index-based substring is defined by the start and end indexes of the original string. Let’s look at a scenario of extracting an index-based substring.
基于索引的子字符串由原始字符串的起始和结束索引定义。让我们看看提取基于索引的子字符串的场景。
Given that we have an input string, “0123Linux9“, we want to extract the substring from index positions 4 through 8. The expected result will be “Linux“.
假设我们有一个输入字符串 “0123Linux9”,我们想要提取从索引位置 4 到 8 的子字符串。预期结果是 “Linux”。
Next, let’s see an example of the pattern-based substring.
接下来,让我们看看基于模式的子字符串的例子。
For instance, say we have an input string, “Eric,Male,28,USA“. It’s a string of comma-separated values (Name,Gender,Age,Country).
例如,假设我们有一个输入字符串 “Eric,Male,28,USA”。这是一个逗号分隔值的字符串(姓名、性别、年龄、国家)。
Now, let’s say we want to extract the third field, 28, which is the age of Eric. In this case, we can’t predict the start index of the target substring, since the Name and Gender have dynamic length. Therefore, the implementation will be different from the index-based extraction.
现在,假设我们想要提取第三个字段 28,也就是 Eric 的年龄。在这种情况下,我们无法预测目标子字符串的起始索引,因为姓名和性别的长度是动态的。因此,其实现方式与基于索引的提取不同。
In this article, we’ll address some common ways to extract substrings in the Linux command line. Of course, we’ll cover both extraction types.
在本文中,我们将介绍在 Linux 命令行中提取子字符串的一些常见方法。当然,我们会涵盖这两种提取类型。
3. Extracting an Index-Based Substring
提取基于索引的子字符串
First, let’s have a look at how to extract index-based substrings. We’ll introduce four ways to do this:
首先,让我们看看如何提取基于索引的子字符串。我们将介绍四种方法:
- Using the cut command
使用 cut 命令 - Using the awk command
使用 awk 命令 - Using Bash’s substring expansion
使用 Bash 的子字符串扩展 - Using the expr command
使用 expr 命令
Next, we’ll see them in action.
接下来,我们将看看它们的实际应用。
3.1. Using the cut Command
3.1 使用 cut 命令
We can extract from the Nth to the Mth character from the input string using the cut command:
我们可以使用 cut 命令从输入字符串中提取第 N 个到第 M 个字符:
cut -c N-M
As we discussed in an earlier section, our requirement is to take the substring from index 4 through index 8.
正如我们在前面部分讨论的,我们的需求是提取从索引 4 到 8 的子字符串。
Here, when we talk about the index, it’s in Bash’s context, which means it’s a 0-based index.
在这里,当我们谈论索引时,是在 Bash 的语境下,这意味着它是零索引的。
Therefore, if we want to solve the problem using the cut command, we need to add one to the beginning and ending index. Thus, the range will become 5-9.
因此,如果我们想使用 cut 命令解决这个问题,需要在起始索引和结束索引上各加 1。这样,范围就变成了 5-9。
Now let’s see if the cut command can solve the problem:
现在让我们看看 cut 命令是否能解决这个问题:
$ cut -c 5-9 <<< '0123Linux9'
Linux
As the output shows, we got the expected substring, “Linux“, so problem solved.
如输出所示,我们得到了预期的子字符串 “Linux”,问题解决了。
In the example above, we passed the input string to the cut command via a here-string and saved an echo process.
在上面的例子中,我们通过 here-string 将输入字符串传递给 cut 命令,省去了 echo 过程。
3.2. Using the awk Command
3.2 使用 awk 命令
When we need to solve a text processing problem in Linux, we shouldn’t forget the Swiss army knife: awk.
当我们需要在 Linux 中解决文本处理问题时,不应忘记“瑞士军刀”——awk。
Awk script has a built-in substr() function, so we can directly call the function to get the substring.
Awk 脚本有一个内置的 substr() 函数,因此我们可以直接调用该函数来获取子字符串。
The substr(s, i, n) function accepts three arguments. Let’s take a closer look at them:
substr(s, i, n) 函数接受三个参数。让我们仔细看看它们:
- s – The input string
s – 输入字符串 - i – The start index of the substring ( awk uses the 1-based index system)
i – 子字符串的起始索引(awk 使用 1 基索引系统) - n – The length of the substring. If it’s omitted, awk will return from index i until the last character in the input string as the substring.
n – 子字符串的长度。如果省略,awk 将返回从索引 i 到输入字符串最后一个字符的部分作为子字符串。
Now let’s see if awk‘s substr() function can give us the expected result:
现在让我们看看 awk 的 substr() 函数是否能给我们预期的结果:
$ awk '{print substr($0, 5, 5)}' <<< '0123Linux9'
Linux
Good! The awk command works as expected.
很好!awk 命令按预期工作。
Here we pass i=5. This is because we need the 1-based index. The second argument, 5, is the length of the target substring, and we get it by 8-4+1.
这里我们传入 i=5,这是因为我们需要 1 基索引。第二个参数 5 是目标子字符串的长度,由 8-4+1 计算得出。
3.3. Using Bash’s Substring Expansion
3.3 使用 Bash 的子字符串扩展
We’ve seen how cut and awk can easily extract index-based substrings.
我们已经了解了 cut 和 awk 如何轻松提取基于索引的子字符串。
Alternatively, Bash is sufficient to solve the problem, since it supports substring expansion via ${VAR:start_index:length}.
此外,Bash 本身也足以解决这个问题,因为它支持通过 ${VAR:start_index:length} 进行子字符串扩展。
Today, Bash is the default shell for many modern Linux distros. In other words, we can solve the problem without using any external command:
如今,Bash 是许多现代 Linux 发行版的默认 shell。换句话说,我们无需使用任何外部命令就能解决这个问题:
$ STR="0123Linux9"
$ echo ${STR:4:5}
Linux
As we can see in the output above, we solved the problem using pure Bash.
从上面的输出可以看出,我们使用纯 Bash 解决了这个问题。
3.4. Using the expr Command
3.4 使用 expr 命令
Even if Bash is available on most Linux distros, there are still a few Linux systems that ship without Bash, particularly in the embedded Linux world.
尽管大多数 Linux 发行版都有 Bash,但仍有一些 Linux 系统没有预装 Bash,特别是在嵌入式 Linux 领域。
The expr command is a member of the Coreutils package. Therefore, it’s available on all Linux systems.
expr 命令是 Coreutils 软件包的一部分。因此,它在所有 Linux 系统上都可使用。
Further, expr also has a substr subcommand that we can use to extract index-based substrings easily:
此外,expr 还有一个 substr 子命令,我们可以用它轻松提取基于索引的子字符串:
expr substr <input_string> <start_index> <length>
It’s worth mentioning that the expr command uses the 1-based index system.
值得一提的是,expr 命令使用 1 基索引系统。
Let’s use expr with the substr command to solve our problem:
让我们使用 expr 和 substr 命令来解决我们的问题:
$ expr substr "0123Linux9" 5 5
Linux
The output above shows that the expr command has solved the problem.
上面的输出表明 expr 命令解决了这个问题。
4. Extracting a Pattern-Based Substring
4. 提取基于模式的子字符串
We’ve learned several ways to extract index-based substrings. Next, in this section, we’ll look into the pattern-based substrings.
我们已经学习了几种提取基于索引的子字符串的方法。接下来,在本节中,我们将研究基于模式的子字符串。
The solutions may look different from the index-based ones, but they’re also pretty straightforward to learn.
这些解决方案可能看起来与基于索引的不同,但学习起来也相当简单。
We’ll address two approaches to solve our problem:
我们将介绍两种解决问题的方法:
- Using the cut command
使用 cut 命令 - Using the awk command
使用 awk 命令
Further, we’ll have a look at a different pattern-based substring extraction problem.
此外,我们还将看看另一个不同的基于模式的子字符串提取问题。
4.1. Using the cut Command
4.1 使用 cut 命令
The cut command is a handy tool for working with field-based data.
cut 命令是处理基于字段的数据的便捷工具。
Let’s review our problem quickly. Our input string is comma-separated values, “Eric,Male,28,USA”, and our goal is to extract the third field, “28“.
让我们快速回顾一下我们的问题。我们的输入字符串是逗号分隔值 “Eric,Male,28,USA”,我们的目标是提取第三个字段 “28”。
To solve the problem, we can tell cut that the string is separated by commas (-d ,), and ask cut to give us the third field (-f 3):
为了解决这个问题,我们可以告诉 cut 字符串由逗号分隔(-d ,),并要求 cut 给出第三个字段(-f 3):
$ cut -d , -f 3 <<< "Eric,Male,28,USA"
28
We got the expected result and solved the problem.
我们得到了预期的结果,问题解决了。
4.2. Using the awk Command
4.2 使用 awk 命令
awk is also good at handling field-based data. A compact awk one-liner can solve the problem:
awk 也擅长处理基于字段的数据。一个简洁的 awk 单行命令就能解决这个问题:
$ awk -F',' '{print $3}' <<< "Eric,Male,28,USA"
28
Moreover, since awk‘s field separator (FS) supports regex, we can build more general solutions with awk.
此外,由于 awk 的字段分隔符(FS)支持正则表达式,我们可以用 awk 构建更通用的解决方案。
For instance, if we change the input string by adding a space after each comma, we have “Eric, Male, 28, USA“. This is a common format we can see in the real world.
例如,如果我们修改输入字符串,在每个逗号后加一个空格,得到 “Eric, Male, 28, USA”。这是现实世界中常见的格式。
In that case, the cut command wouldn’t be a good choice to solve the problem. This is because the cut command only supports a single character as the field delimiter.
在这种情况下,cut 命令就不是解决问题的好选择了。这是因为 cut 命令只支持单个字符作为字段分隔符。
However, it’s still a piece of cake for awk:
然而,这对 awk 来说仍然是小菜一碟:
$ awk -F', ' '{print $3}' <<< "Eric, Male, 28, USA"
28
We can even write one awk command to work for both cases. This could be a useful trick in the real world:
我们甚至可以编写一个 awk 命令来处理这两种情况。这在实际应用中可能是一个有用的技巧:
$ awk -F', ?' '{print $3}' <<< "Eric, Male, 28, USA"
28
4.3. A Different Pattern-Based Substring Case
4.3 另一个基于模式的子字符串案例
So far, we’ve solved our “Eric’s age” problem. In this problem, our input is a field-based value.
到目前为止,我们已经解决了“Eric 的年龄”问题。在这个问题中,我们的输入是基于字段的值。
However, in practice, the pattern-based substring may not always be located in a CSV entry. Let’s see another example.
然而,在实际中,基于模式的子字符串可能并不总是位于 CSV 条目中。让我们看看另一个例子。
Given that we have an input string, “whatever dataBEGIN:Interesting dataEND:something else“, our goal is to extract the substring between “BEGIN:” and “END:“. That is, between two patterns.
假设我们有一个输入字符串 “whatever dataBEGIN:Interesting dataEND:something else”,我们的目标是提取 “BEGIN:” 和 “END:” 之间的子字符串,也就是两个模式之间的部分。
Obviously, the cut command can’t help us in this case. But it’s still not a challenge for awk. It can solve this problem in different ways.
显然,在这种情况下,cut 命令帮不上忙。但这对 awk 来说仍然不是挑战。它可以通过多种方式解决这个问题。
So let’s see how awk solves it. We save the input string in a variable $STR to make the commands easier to read:
让我们看看 awk 是如何解决的。我们将输入字符串保存在变量 $STR 中,使命令更易于阅读:
$ STR="whatever dataBEGIN:Interesting dataEND:something else"
$ awk -F'BEGIN:|END:' '{print $2}' <<< "$STR"
Interesting data$ awk '{ sub(/.*BEGIN:/, ""); sub(/END:.*/, ""); print }' <<< "$STR"
Interesting data
The first awk command defines “BEGIN:” or “END:” as the field separator and takes the second field.
第一个 awk 命令将 “BEGIN:” 或 “END:” 定义为字段分隔符,并提取第二个字段。
However, the second awk solution doesn’t tweak the field separator. Instead, it applies two regex substitutions to achieve the goal:
然而,第二个 awk 解决方案没有调整字段分隔符。相反,它通过两次正则表达式替换来实现目标:
sub(/.*BEGIN:/, “”)– Removes everything from the beginning of the string until “BEGIN:“
sub(/.*BEGIN:/, “”)– 移除从字符串开头到 “BEGIN:” 的所有内容sub(/END:.*/, “”)– Removes from “END:” until the end of the input string
sub(/END:.*/, “”)– 移除从 “END:” 到输入字符串末尾的所有内容
After the execution of these two substitutions, we’ll have our expected result. All we need to do is print it out.
执行这两次替换后,我们就会得到预期的结果。我们所要做的就是将其打印出来。
5. Conclusion
5.结论
Extracting a substring is a fundamental technique of text processing in Linux. Depending on the requirement, the substring extraction can be index-based or pattern-based.
提取子字符串是 Linux 中文本处理的一项基本技术。根据需求不同,子字符串提取可以是基于索引的,也可以是基于模式的。
In this article, we addressed how to extract substrings in both types through examples.
在本文中,我们通过示例介绍了如何提取这两种类型的子字符串。
We also explored the power of the handy text processing utility awk.
我们还探讨了便捷的文本处理工具 awk 的强大功能。
via:
-
How to Extract Bash Substring? [5 methods] - LinuxSimply
https://linuxsimply.com/bash-scripting-tutorial/string/substring/ -
Extracting a Substring in Bash | Baeldung on Linux
https://www.baeldung.com/linux/bash-substring