ICMR-2025 | 杭电多智能体协作具身导航框架!MMCNav:基于MLLM的多智能体协作户外视觉语言导航

作者:Ziheng Zhang, Minghao Chen, Suguo Zhu, Tingting Han, Zhou Yu
单位:杭州电子科技大学
论文标题:MMCNav: MLLM-empowered Multi-agent Collaboration for Outdoor Visual Language Navigation
论文链接:https://dl.acm.org/doi/abs/10.1145/3731715.3733393
代码链接:https://github.com/zzhaesc/MMCNav
主要贡献
首次将多智能体框架应用于户外视觉语言导航任务,多智能体协作显著优于单智能体系统,能够更好地处理复杂的导航指令。
引入多模态大模型(MLLMs)增强场景理解,实现了对复杂户外环境的精确和细粒度场景解释,这对于导航至关重要。
构建了反思机制,通过构建探索地图,解决了仅依赖文本输入信息时的冗余问题,提高了错误识别能力。
在两个户外导航数据集上取得了优于先前基线模型的性能,验证了所提出方法的有效性。
研究背景
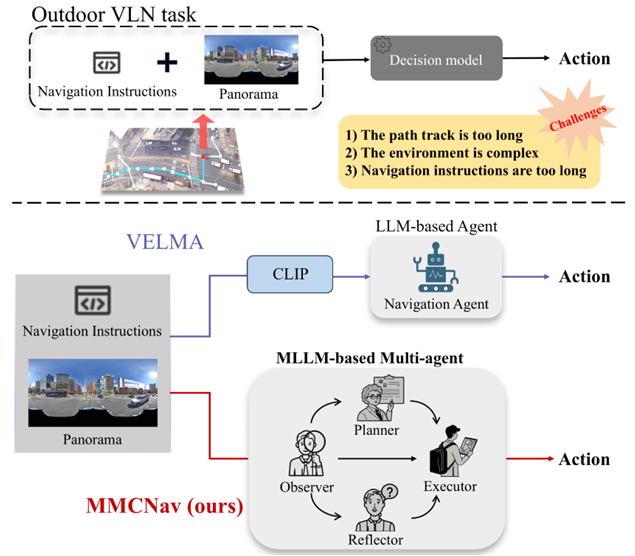
- 视觉语言导航(VLN)任务的挑战:
在真实世界环境中导航,如城市街道视图,需要根据环境信息寻找通往目的地的清晰路径。
现有的利用大语言模型(LLMs)的方法虽然取得了显著成就,但在需要复杂视觉理解的场景中仍面临挑战。
户外导航任务具有路径长、环境复杂、导航指令冗长等特点,增加了智能体理解指令和执行任务的难度。
- 多智能体系统的优势:
多智能体系统通过多个自主智能体的协作,在处理复杂任务方面表现出色。通过结构化交互和实时适应,智能体可以协商行动、共享见解并集体调整以适应不同情况。
这种协同效应在多个领域显示出巨大潜力,包括机器人技术、游戏开发和视觉语言导航等。
研究方法
框架概述
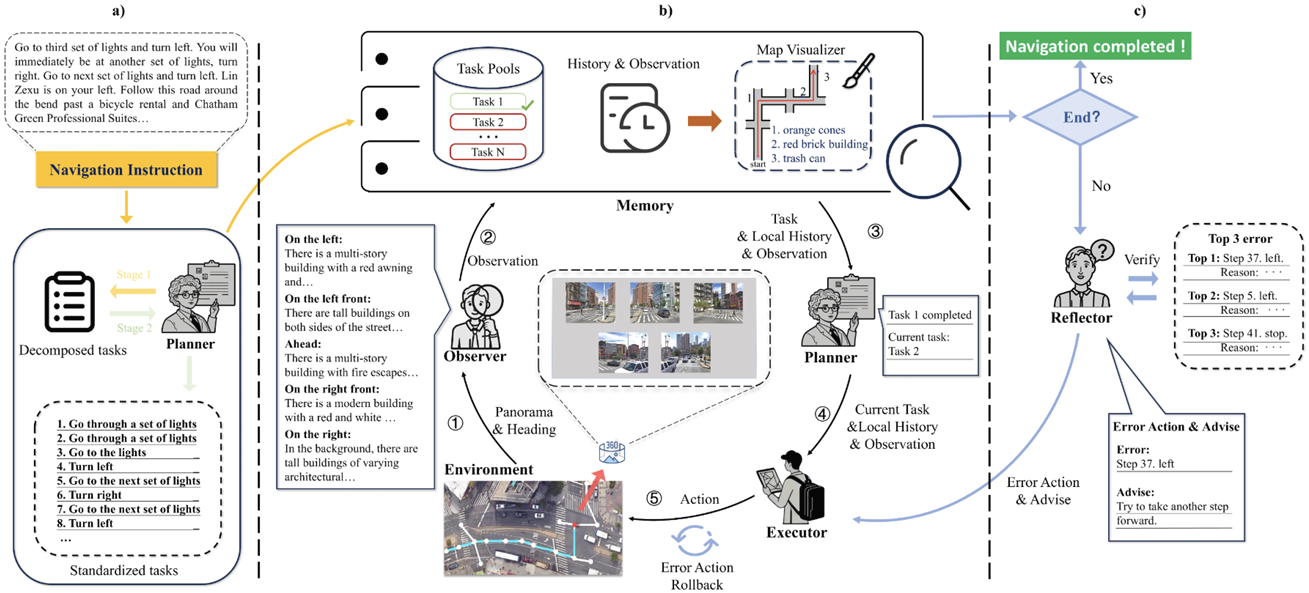
- MMCNav框架:整个系统包含四个核心角色(规划者、观察者、执行者、反思者)以及一个记忆模块。框架分为两个主要循环:
内循环(Inner Navigation Loop):负责具体的导航任务执行,包括任务分配、环境观察、决策和行动。
外循环(Outer Reflection Loop):在导航结束后进行反思和错误纠正。
规划阶段:规划者分析导航指令并将其分解为多个子任务,存储在任务池中。
- 内循环:
观察者获取当前环境的全景视图并生成描述。
执行者根据当前任务、历史信息和环境描述做出决策。
重复上述步骤,直到导航任务完成。
- 外循环:
反思者基于探索地图和历史任务信息进行反思,识别潜在错误并提出修正建议。
执行者根据反思者的建议返回错误点并重新导航。
规划者
- 任务分解:
规划者利用LLM的知识将复杂的导航指令分解为多个子任务。例如,“直行经过2个路口”被分解为两个“直行经过一个路口”的任务。
分解后的任务通过思维链(Chain-of-Thought, CoT)方法进行标准化,以确保任务描述的一致性。
- 任务分配:
规划者根据当前任务的执行情况评估任务是否完成。如果完成,则分配下一个子任务。
规划者向执行者提供当前任务、多视角观测数据和历史决策记录,以便执行者做出准确决策。
观察者
- 环境观察:
观察者将当前状态的全景视图投影到标准视角,并分割为五个方向的视图。
利用MLLM为每个方向生成详细的场景描述,帮助理解当前环境。
- 地标识别:
观察者利用MLLM中的世界知识对导航指令中提到的地标进行推断和投票识别。例如,即使“贝果店”没有明显的标识,观察者也可以根据周围环境推断出其位置。
这种方法比传统的地标识别方法更具灵活性和准确性。
执行者
- 决策机制:
执行者根据当前任务、历史信息和多视角观测数据选择下一步的动作。
为了避免全局历史信息过于冗长,执行者仅提取与当前任务相关的局部历史信息。
- 动作选择:
执行者将问题描述、规则、当前任务、局部历史和多视角观测数据组合成一个结构化的提示(prompt),输入到LLM中。
LLM根据这些信息预测最优动作,执行者执行该动作并进入下一个循环。
反思者
- 反思机制:
反思者在导航结束后,基于探索地图和历史任务信息进行反思。
通过分析历史路径和任务,识别可能导致导航失败的潜在错误点。
- 错误纠正:
反思者从记忆模块中检索与错误状态相关的观测信息,进一步分析导致错误的具体动作。
识别出真正的错误后,反思者提出修正建议,指导执行者返回错误点并重新尝试导航。
记忆模块
- 信息存储:
记忆模块存储全局历史、每一步的观测数据以及任务池中的所有任务。
在导航结束后,利用全局历史信息构建探索地图,简化交叉口形状并标记地标信息。
- 探索地图:
探索地图用于帮助智能体直观地理解历史路径,减少信息冗余。
地图的简化设计使得智能体能够更高效地进行反思和错误纠正。
实验
实验设置
- 数据集:
使用了Touchdown和Map2seq两个数据集进行实验。Touchdown包含9326条路线及人类编写的导航指令,Map2seq包含7672条导航指令。这两个数据集的主要区别在于指令的性质和复杂性。
- 基线模型:
选取了从零开始训练的模型(如RConcat、GA、VLN Transformer等)、基于LLMs的模型(如VELMA、VELMA-RBL)以及基于MLLMs的模型作为基线进行比较。
- 评估指标:
采用任务完成率(TC)、关键点准确率(kpa)、最短路径距离(spd)和归一化动态时间弯曲(nDTW)等指标来评估智能体的性能。
结果分析
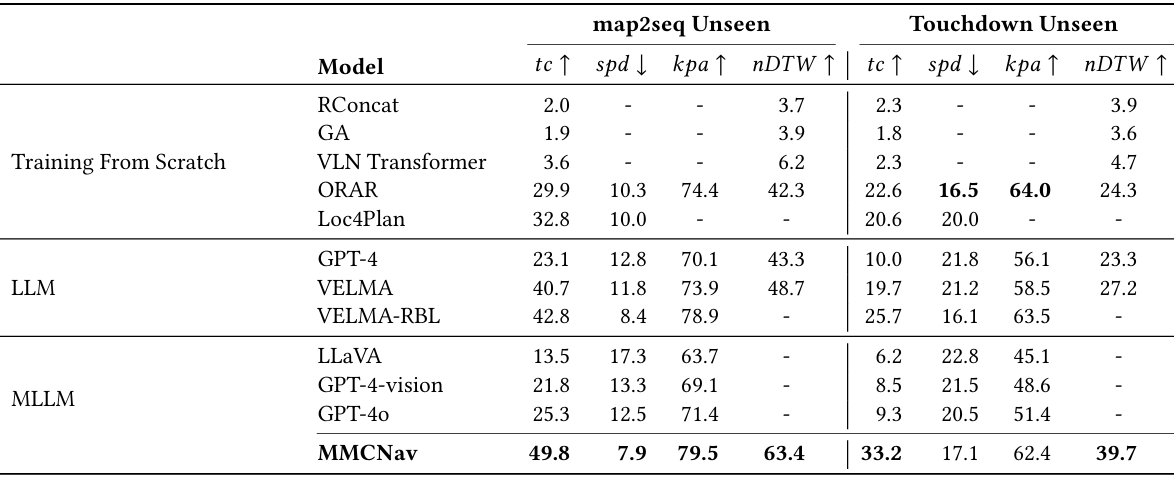
- 实验结果:
MMCNav在map2seq和touchdown数据集上均取得了显著的性能提升。
与Loc4Plan相比,在map2seq数据集上任务完成率提高了17%,最短路径距离提高了2.1%;与ORAR相比,在touchdown数据集上任务完成率提高了10.7%,最短路径距离提高了4%。
此外,MMCNav还优于VELMA和VELMA-RBL等基于预训练模型的方法,表明其在决策和反思机制上的有效性。
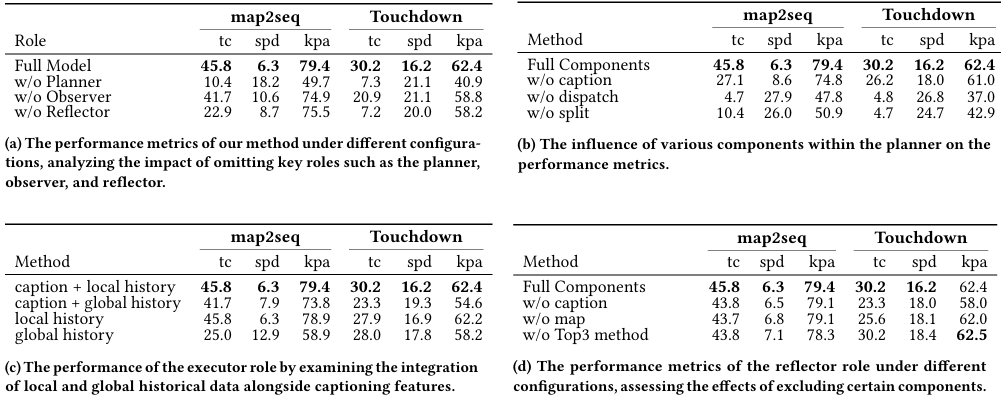
- 消融研究:
通过移除或替换特定角色模块或其核心组件,验证了各模块对系统性能的影响。
结果表明,规划者、观察者和反思者等角色对于系统的导航能力至关重要。
此外,还分析了执行者在局部历史和全局历史信息融合方面的表现,以及反思者在不同配置下的性能变化。
结论与未来工作
- 结论:
MMCNav通过多智能体协作,有效地解决了户外视觉语言导航任务中的复杂挑战。
各智能体通过角色分工和协作,显著提高了导航的准确性和效率。
反思机制的引入增强了系统的鲁棒性,尤其是在长时间导航任务中,显著提高了成功率。
- 未来工作:
进一步优化多智能体协作机制,探索更高效的智能体角色分工和交互方式。
此外,还可以考虑将该方法应用于更复杂的户外环境或与其他导航技术相结合,以进一步提升导航性能。
