6 如何向量化人工智能算法

这里一定坚持住!我们能赢!
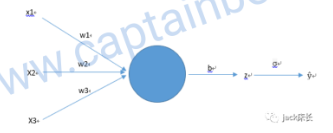
船长大佬先给出了还未进行向量化的人工智能算法。未进行向量化说明什么?说明有循环。
下图是伪代码

大佬分了颜色便于理解。
红色很熟悉for,用来循环遍历的样本的(之前说到一个神经网络需要多个样本,比如训练识别猫的神经网络,一张猫的图片就是一个训练样本)
temp用来存放值,存放什么值?回顾一下下图,一个样本有多个特征,比如RGB矩阵转为特征向量,之前提到的。w是权重。所以这里temp=所有特征*权重的和,b是什么,之前提到了,b是阈值,所以temp+b也就是z也就是逻辑回归函数。
a也就是激活函数,J即损失函数,因为是循环,所以J累加所有样本的损失。y是实际值,训练集已标注好的
dz为什么是a-y?因为 4计算偏导数中计算的
蓝色循环是遍历所有特征,dw为什么是x*dz? 因为也是4计算偏导数中计算的。此处不理解为什么要把所有样本的同一个位置的特征的权重导数都加起来,然后平均。船长评论区说是为了泛化,后面会提到。先标记,后续看看

紫色,b的偏导数为什么要累加所有样本的z的偏导数?好问题,首先b的偏导=? 回顾4计算偏导数,就明白为什么了。b的偏导数和平均,后续用于调整b(阈值)
/m都是算平均值。
所以大致逻辑还是之前的逻辑回归、激活、损失、然后计算变化。
是的这一串仅说明了前向传播过程。

这串理解了,大逻辑理解了,就是改写了。下面一步一步去掉for循环
假设有一个2*3的矩阵,
|1 2 3|
|4 5 6|
m就是2,n就是3,假设权重=[2 7 2]
绿色循环可向量化成
 ----------->
----------->![]()
这里j依次=1、2、3,那么for计算后最终的temp:
j=1时
temp = 0 + 2*1 = 2j=2时
temp = 2 + 7*2 = 16j=3时
temp = 16 + 2*3 = 22对比下向量化后的

![]()
为什么没有.t?t是转置,转置即把行向量变成列向量,就是下边酱紫。不同方法对数据格式要求不同,所以以具体方法为准。(好比你去A公司入职,要你的建行卡号以后发工资;B公司入职,要你的招行卡号以后发工资。不同方法不同内容)


蓝色循环可向量化成
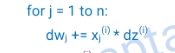 ------------>
------------>![]()
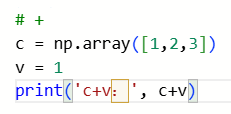
这里的x(i)是一个向量,dz(i)是一个单独的数值。这里是通过python的广播化技术。当遇到两个不同维度的对象进行运算时,python会自动通过复制元素来使两个操作对象的维度相同,如图:
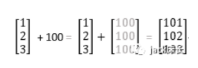
写个小demo
![]()
那么乘法呢?一样的哦~

![]()
所以这里从一个一个*,变成了直接向量*
这样取代了循环,得到如下代码

/同理*了
最后是去掉红色大循环,红色循环去掉后,绿色代码变成如下形式
![]()
这里是大写X,大写X是一个n*m的矩阵,w是n个输入特征的权重,即一个1*m的行向量
 撑住!!!快了快了!!!
撑住!!!快了快了!!!
黑色代码变成了如下形式:
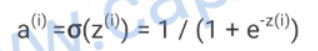 ----->
----->![]()
exp方法是干这个的:

所以上边的逻辑就是,批量算出了逻辑回归结果,然后批量激活,z(i)变Z即最终应用广播化技术得出一个A向量,向量中每个元素对应一个样本的小a(i)
橙色变成这个
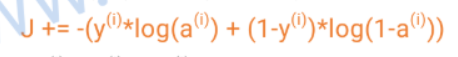 /m ----->
/m ----->![]()
批量log,然后+,然后平均。
灰色变:
 ------>
------> ![]()
蓝色变:
 --------->
--------->![]()
X是n*m的矩阵,dZ.t是一个m*1的列向量,所以np.dot(X,dZ.t)得到n*1的列向量
诶??来复习一下,向量相乘
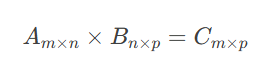
1行*1列写到1行1列
2行*1列写到2行1列
n和m代个值就明白了

这里的取代过程说明:X的每一列对应一个样本的一组输入特征;每一行对应各个样本的同一个位置的特征,即第一行对应所有样本的第一个特征,第二行对应所有样本的第二个特征。
而dZ.t是一个列向量,里面的一个元素就是一个样本对应的dz
所以X的第一行与dZ进行运算=所有样本对应的第一个特征与其对应样本的dz相乘后再把每个乘积结果累加,等价于外面红色循环。
X的所有行与dZ进行运算=所有样本对应的所有特征*对应dz累加
紫色代码变:
![]()

最终整体变:

比原来简短了,但是逻辑是一样的,这篇需要好好盘盘,1遍2遍3遍……就能明白很多了