JavaScript字符串拓展:实用方法与示例全解析
一、引言:为什么要学习 JS 字符串拓展

在前端开发的世界里,JavaScript 如同基石般支撑着网页的交互与动态呈现。而字符串作为我们日常操作中最频繁接触的数据类型之一,其原生方法在面对复杂多变的业务需求时,有时难免显得捉襟见肘。此时,JS 字符串拓展方法就如同一个个得力助手,闪亮登场。它们不仅能够帮助我们以更简洁、高效的方式处理字符串,还能让代码的可读性大大提升,减少代码冗余,为开发工作注入强大动力,让我们在构建 Web 应用的征程中如虎添翼。接下来,就一起深入探索这些实用的字符串拓展技巧吧。
二、ES6 带来的强大变革

(一)模板字符串:优雅拼接的艺术
ES6 引入的模板字符串,宛如一位优雅的舞者,轻盈地踏入字符串处理的舞台,让拼接操作变得赏心悦目。它以反引号 (`) 作为标识,与传统的单引号、双引号区分开来。
比如,在构建一个包含变量的欢迎语句时,以往我们只能借助繁琐的 + 运算符,像这样:
let name = "Alice";
let age = 25;
let message = "Hello, " + name + "! You are " + age + " years old.";但有了模板字符串,一切瞬间变得简洁明了:
let name = "Alice";
let age = 25;
let message = `Hello, ${name}! You are ${age} years old.`;不仅如此,模板字符串还能轻松驾驭多行文本。假设我们要生成一段 HTML 片段:
let html = `
<ul><li>Item 1</li><li>Item 2</li><li>Item 3</li>
</ul>
`;那些换行与缩进都被原汁原味地保留下来,输出的格式与我们编写的一模一样,大大提升了代码的可读性,仿佛是直接在书写最终的文本内容。
(二)Unicode 表示法升级:轻松应对生僻字
在处理文本时,偶尔会邂逅一些生僻字或特殊字符,它们的 Unicode 码点超出了常规的 \uFFFF 范围。ES6 之前,JavaScript 在这方面有些力不从心,常常出现乱码或错误解析的情况。但 ES6 挺身而出,改进了 Unicode 表示法,只需将码点放入大括号中,就能精准解读。
例如,对于字符 “?”(码点为 \u {20BB7}),在 ES6 中可以这样表示:
let specialChar = "\u{20BB7}";
console.log(specialChar); // 输出:?这看似微小的改变,实则为处理复杂文本、尤其是涉及多语言或古文字研究等领域的开发,打开了一扇顺畅的大门,让那些神秘的字符得以准确呈现。
(三)遍历器接口:for...of 循环的新玩法
ES6 赋予了字符串遍历器接口,这使得字符串能够与 for...of 循环完美配合,开启了一种全新的遍历方式。相较于传统的 for 循环,它的优势在处理 Unicode 字符时展露无遗。
考虑这样一个包含特殊字符的字符串:
let text = "abc?def";使用 for 循环遍历:
for (let i = 0; i < text.length; i++) {console.log(text[i]);
}输出结果会是:
a
b
c
�
�
d
e
f因为 JavaScript 内部以 UTF - 16 格式存储字符,对于需要 4 个字节存储的 “?”,for 循环误将其当作两个不可打印字符处理。
而换用 for...of 循环:
for (let char of text) {console.log(char);
}输出则是:
a
b
c
?
d
e
ffor...of 循环能够智能地识别出完整的 Unicode 字符,确保遍历结果准确无误,为处理各类文本内容提供了坚实保障。
三、常用拓展方法大揭秘

(一)判断类方法:includes、startsWith、endsWith
在日常开发中,我们常常需要判断一个字符串是否包含另一个字符串,或者是否以特定字符串开头、结尾。ES6 之前,我们主要依靠 indexOf 方法,通过返回值是否为 - 1 来判断,但这种方式不够直观。ES6 带来了更便捷的方法:includes、startsWith 和 endsWith,它们都返回布尔值,让判断逻辑一目了然。
- includes:用于判断当前字符串是否包含指定的参数字符串。语法为 includes(searchString[, position]),其中 searchString 是要搜索的字符串,position 是可选参数,指定开始搜索的位置,默认从 0 开始。例如:
let str = "Hello, world!"; console.log(str.includes("world")); // true console.log(str.includes("o", 5)); // false,从索引5位置开始找'o',此位置后没有'o' - startsWith:判断当前字符串是否以参数字符串开头。语法是 startsWith(searchString[, position]),参数含义与 includes 类似。如:
let greeting = "Good morning"; console.log(greeting.startsWith("Good")); // true console.log(greeting.startsWith("morning", 5)); // true,从索引5开始到末尾是'morning' - endsWith:确定当前字符串是否以参数字符串结尾。语法为 endsWith(searchString[, length]),这里的 length 是可选的,用于限定要检查的字符串长度,默认是 str.length。例如:
let url = "https://example.com/page"; console.log(url.endsWith("page")); // true console.log(url.endsWith("com", 15)); // true,检查前15个字符,是以'com'结尾这三个方法极大地简化了字符串包含关系的判断逻辑,让代码更加清晰易懂,是日常开发中不可或缺的工具。
(二)重复与补全:repeat、padStart、padEnd
除了判断,字符串的重复与补全在实际应用中也极为常见,比如构建有规律的文本、格式化输出等,ES6 新增的几个方法在这些场景中大放异彩。
- repeat:能将原字符串重复指定次数,生成新字符串。语法为 repeat(count),count 是重复次数,若为小数则向下取整,若小于等于 - 1 的负数或 Infinity 会报错,0 到 - 1 之间的小数不报错。示例如下:
let star = "*".repeat(5); console.log(star); // ***** let repeated = "abc".repeat(2.5); console.log(repeated); // abcabc,向下取整为2次重复 - padStart:用于在字符串开头补全字符,使其达到指定长度。语法为 padStart(targetLength[, padString]),targetLength 是目标长度,padString 是可选的补全字符串,默认用空格补全。若 targetLength 小于等于原字符串长度,则原字符串不变。例如:
let num = "7"; console.log(num.padStart(3, "0")); // 007,常用于格式化数字,如时间的秒数补0 let text = "abc"; console.log(text.padStart(5, "x")); // xxabc - padEnd:和 padStart 类似,不过是在字符串末尾补全。语法 padEnd(targetLength[, padString]),参数作用相同。如:
let code = "123"; console.log(code.padEnd(6, "-")); // 123--- let message = "Hi"; console.log(message.padEnd(4, "!")); // Hi!!这些方法为字符串的格式化和构建提供了强大支持,让文本处理更加灵活高效。
(三)转换方法:fromCodePoint 与 codePointAt
在处理 Unicode 字符时,ES6 之前的 String.fromCharCode 方法存在局限,无法识别码点大于 0xFFFF 的字符。ES6 引入的 fromCodePoint 和 codePointAt 方法弥补了这一不足,为 Unicode 字符处理开辟了新途径。
- fromCodePoint:用于从 Unicode 码点返回对应的字符,可接收多个码点参数,会将它们合并成一个字符串返回。定义在 String 对象上,与 codePointAt 互为逆向操作。例如:
console.log(String.fromCodePoint(0x20BB7)); // 𠮷 console.log(String.fromCodePoint(0x78, 0x1f680, 0x79)); // x?y,多个码点合并成字符串 - codePointAt:能正确返回 32 位 UTF - 16 字符的码点,参数是字符在字符串中的位置(从 0 开始)。对于常规 2 字节字符,返回结果与 charCodeAt 相同;对于 4 字节字符,能精准识别。返回值是十进制码点,若要十六进制,可用 toString(16) 转换。如:
let str = "吉a"; console.log(str.codePointAt(0)); // 134071,十进制码点,对应'吉' console.log(str.codePointAt(0).toString(16)); // 20bb7,十六进制表示这两个方法配合使用,让 JavaScript 在处理复杂 Unicode 字符时更加得心应手,无论是多语言文本解析还是特殊符号处理,都能轻松应对。
四、实战案例:让理论落地生根
(一)表单验证:精准把关用户输入
在 Web 开发中,表单验证是保障数据质量的第一道防线。假设我们正在构建一个用户注册页面,需要确保用户输入的用户名、邮箱和密码符合特定规则。
首先,验证用户名是否包含非法字符:
let username = "user_123";
if (!username.match(/^[a-zA-Z0-9_]+$/)) {console.log("用户名只能包含字母、数字和下划线");
}这里使用了正则表达式结合字符串的 match 方法进行验证。但如果利用 ES6 的 includes 方法,代码可以更清晰:
let illegalChars = "~!@#$%^&*()";
for (let char of illegalChars) {if (username.includes(char)) {console.log(`用户名不能包含特殊字符 ${char}`);break;}
}对于邮箱验证,传统方式可能是复杂的正则表达式:
let email = "user@example.com";
let emailRegex = /^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$/;
if (!emailRegex.test(email)) {console.log("邮箱格式不正确");
}有了 ES6 新增的字符串方法,我们可以分步验证,增强可读性:
if (!email.includes("@") ||!email.endsWith(".com")) {console.log("邮箱格式不正确");
}这种方式虽然简单粗暴,对于一些复杂的邮箱后缀可能不适用,但在初步验证或教学示例中,能让逻辑一目了然。
密码强度验证也能借助字符串方法。比如要求密码至少包含一个大写字母、一个小写字母和一个数字:
let password = "Passw0rd";
let hasUpper = false;
let hasLower = false;
let hasNumber = false;
for (let char of password) {if (char >= 'A' && char <= 'Z') {hasUpper = true;} else if (char >= 'a' && char <= 'z') {hasLower = true;} else if (char >= '0' && char <= '9') {hasNumber = true;}
}
if (!(hasUpper && hasLower && hasNumber)) {console.log("密码强度不足");
}这里通过遍历字符串,结合字符的 Unicode 范围判断,使密码验证逻辑更加直观,易于理解与维护。
(二)文本处理:打造优质阅读体验
在内容展示类的 Web 应用中,文本处理至关重要。例如,我们从后端获取一篇文章内容,需要在前端进行格式化展示。
文章标题可能需要补全长度,使其在页面上排列整齐:
let title = "JavaScript字符串拓展技巧";
let formattedTitle = title.padEnd(30, " ");
console.log(formattedTitle); 这会在标题末尾添加空格,使其长度达到 30,适配特定的排版设计,增强页面美观度。
正文内容里,若要对一些关键词加粗突出显示,可利用 replace 方法结合模板字符串:
let content = "ES6为JavaScript带来了强大的字符串处理能力,如模板字符串。";
let keyword = "模板字符串";
content = content.replace(keyword, `<b>${keyword}</b>`);
console.log(content); 如此,文章中的关键词在展示时就会以加粗样式呈现,提升读者对重点内容的关注度,优化阅读体验。
又比如,将一段连续的文本按指定长度换行:
let longText = "这是一段很长很长的文本,需要按照一定规则进行换行处理,以适应页面布局,让文本显示更加美观。";
let lineLength = 20;
let lines = [];
while (longText.length > 0) {lines.push(longText.slice(0, lineLength));longText = longText.slice(lineLength);
}
let formattedText = lines.join("\n");
console.log(formattedText); 通过循环与字符串切片操作,配合换行符拼接,实现文本的合理换行,确保在不同屏幕尺寸下都能优雅展示。
在享受 JS 字符串拓展方法带来便利的同时,我们不得不直面兼容性这一关键问题。不同浏览器厂商、不同版本对 ES6 及后续版本特性的支持程度参差不齐,就像一条坑洼不平的道路,给开发者带来诸多挑战。
五、兼容性考量:确保万无一失
例如,一些老旧浏览器如 IE11 及以下版本,对模板字符串的支持并不完美,可能会出现语法报错。而部分小众浏览器在处理 Unicode 相关的新方法时,也可能存在兼容性漏洞,导致字符显示异常或方法无法识别。
为了跨越这些兼容性障碍,我们有几种实用的工具和策略。首先,Babel 是一款强大的转译器,它能够将 ES6 及以上版本的 JavaScript 代码转换为向后兼容的 ES5 代码,让那些先进的字符串拓展方法在老旧浏览器中也能正常运行。在 Webpack 等构建工具的配置中,通过引入 Babel 相关插件,如 @babel/preset-env,可以根据目标浏览器的版本范围,精准地将新语法转换为兼容语法。
另外,对于一些特定的方法,如果不确定兼容性,还可以采用渐进增强的策略。先使用传统的原生方法进行兜底,再尝试使用新的拓展方法,确保功能在各种环境下都能平稳运行。例如,在判断字符串是否包含某个子串时:
function checkIncludes(str, searchStr) {if (typeof str.includes === 'function') {return str.includes(searchStr);}return str.indexOf(searchStr)!== -1;
}这样,无论浏览器是否支持 includes 方法,都能得到准确的判断结果,为用户提供一致的体验,让我们的 Web 应用在兼容性的轨道上稳健前行。
六、总结与展望:砥砺前行
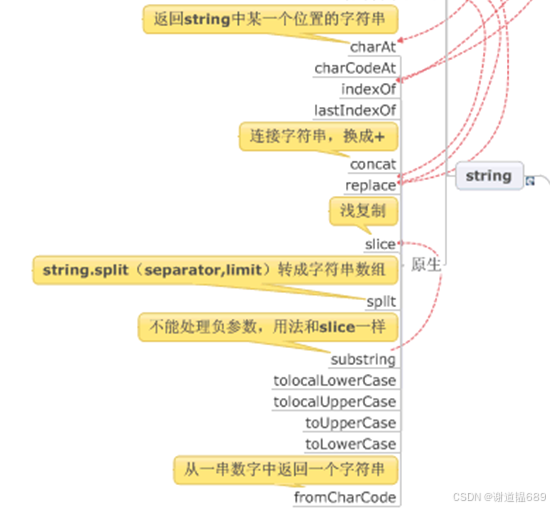
至此,我们一同深入探索了 JS 字符串拓展的精彩世界,领略了从 ES6 引入的模板字符串、Unicode 表示法升级、遍历器接口,到常用拓展方法如判断类、重复与补全类、转换类方法的强大魅力,并通过表单验证、文本处理等实战案例见证了它们在实际开发中的卓越表现,还针对兼容性问题找到了切实可行的应对策略。
然而,技术的发展如滚滚浪潮,永不停息。JavaScript 的世界依旧在不断演进,字符串处理方面或许会在未来迎来更多高效、智能的拓展方法,以适应日益复杂的前端需求。作为开发者,我们要时刻保持学习的热情,紧跟技术潮流,将这些新特性巧妙融入日常开发,持续提升用户体验,在 Web 开发的道路上不断探索前行,用代码书写更加精彩的数字篇章。