计算机的算术运算之浮点数
3.5 浮点运算
科学计数法:小数点左边只有一位数字的表示数的方法。
规格化:没有前导0的浮点表示法。
二进制小数格式:
1.xxxxxxxxx X 2^yyyyy
浮点:二进制小数点不固定的数的计算机表示。
3.5.1 浮点表示
尾数:该值通常在0和1之间,放置在尾数字段中。上面的x
指数:在浮点运算的数值表示系统中,放置在指数字段中的值。上面的y
浮点数通常占用多个字的长度。下图S是浮点数的符号(1表示负数),指数由8位指数字段(包括指数的符号)表示,尾数由23位数表示。这种表示称为符号和数值,符号和数值的位是相互分离的。

通常来讲,浮点数可以这样表示:
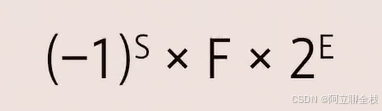
F是尾数字段中表示的值,而E是指数字段表示的值。
使的RISC-V计算机具有很大的运算范围,小到2.0x10^-38,大到2.0x10^38,计算机都能表示出来。
但仍然会存在数太大和太小表示不出来的情况,和整数一样,浮点运算也会发生溢出问题。
上溢:正指数太大而无法用指数字段表示的情况。
下溢:负指数太大而无法用指数字段表示的情况。
双精度:以64位双字表示的浮点数。
单精度:以32位字表示的浮点值。
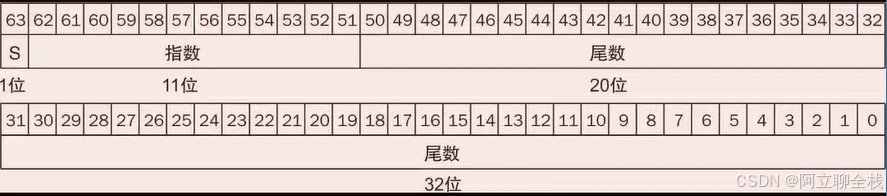
双精度浮点数需要一个RISC-V双字才能表示,如图所示,S仍然是数的符号位,指数字段为11位,尾数字段为52位。
表示实数范围,小到2.0x10^-308,大到2.0x10^308。
3.5.2 例外和中断
有些计算机会通过引发例外,有时称作中断来告知问题的出现。
例外:也称为中断,打扰程序执行的意外事件,用于检测溢出。
中断:来自处理器之外的例外(有些体系结构用术语中断表示所有的例外)。
3.5.3 IEEE 754 浮点数标准
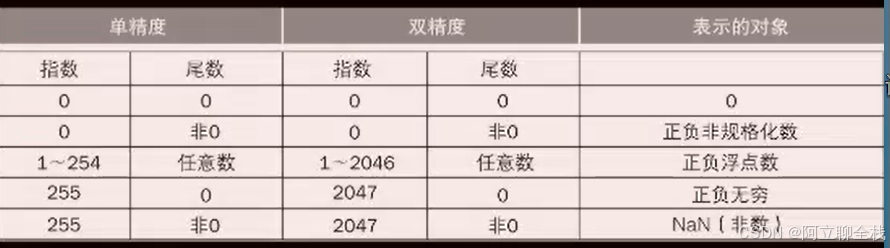
例如:0/0或无穷减去无穷,这个符号是NaN,表示不是一个数。
3.5.4 浮点加法
9.999x10^1+1.610x10^-1,有效数位保存4位十进制,指数字段保存两位十进制数字。
- 第一步:指数较小的数的小数点和指数较大的数的小数点对齐,0.01610x10^1
- 第二步:将两个数有效位相加,9.999+0.016=10.015
- 第三步:对和进行移位,调整指数大小,1.0015x10^2
- 第四步:我们假定有效位数可能只有四位(不包括符号位),对结果四舍五入,1.002x10^2
例题:二进制浮点数加法
尝试将0.5和-0.4375用二进制相加
答案:假设保持4位精度
0.5=1/2=1.000x2^-1
-0.4375=-7/16=-7/2^4=-111/2^4=-0.0111=1.110x2^-2
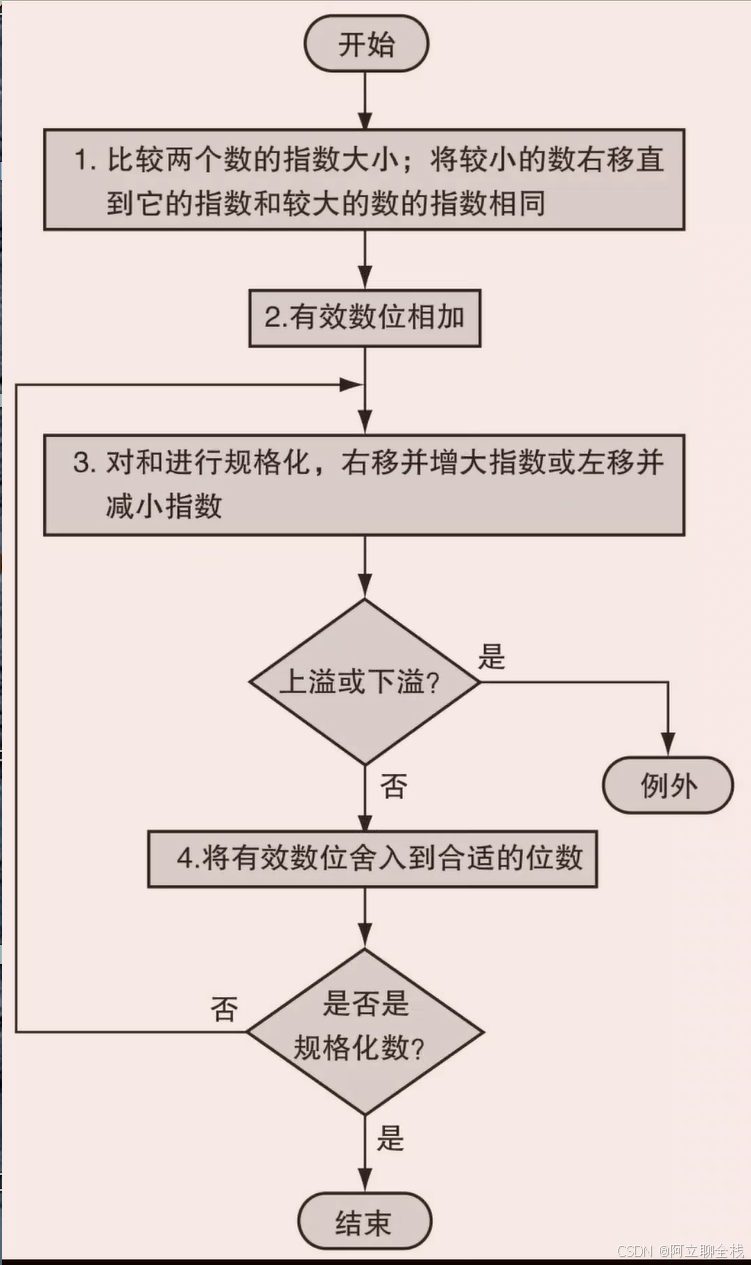
以最高次幂为准,1.000x2^-1-0.111x2^-1=0.001x2^-1=1.000x2^-4=1/16=0.0625
3.5.5 浮点数乘法
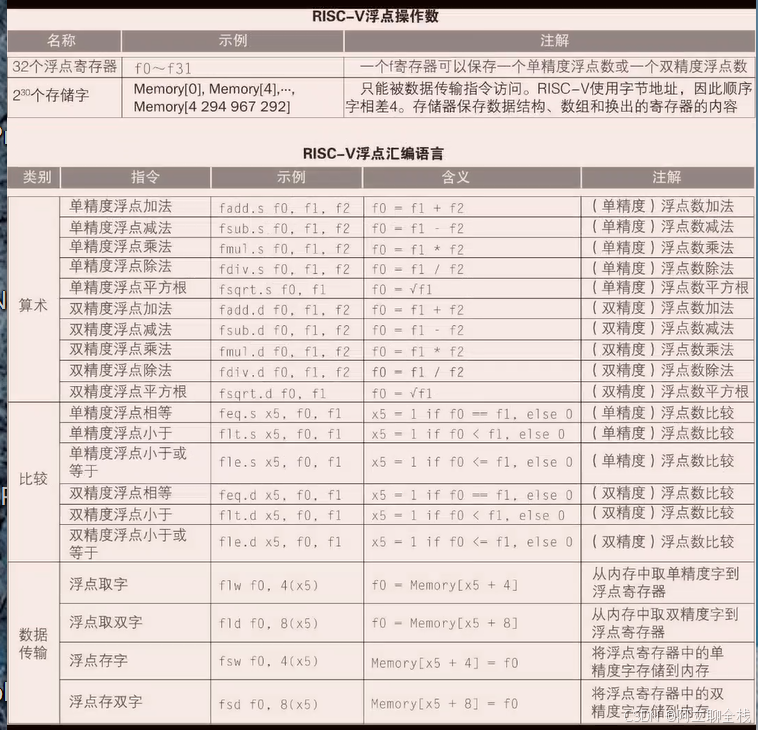
3.5.6 RISC-V 中的浮点指令
3.5.7 精确算术
浮点数无法做到真正的精确的表示,通常只能用近似值来表示。
保护位:在浮点运算的中间计算中,保留在右侧的两个额外位的第一位,用于提高舍入精度。
舍入位:是中间结果符合浮点格式的方法,目标通常是找到符合格式的最接近的数,它也是在浮点运算的中间运算中保留在右侧的两个额外位的第二位,可以提高舍入精度。
例题:利用保护位进行舍入
最后位置单位(ulp):用于表示在实际数和可表示数之间的有效数位中最低有效位上的误差位数。
粘滞位:用于舍入时除了保护位和舍入位之外的位,当右侧有非零位时就设为1.
混合乘加:一条既执行乘法又执行加法的浮点指令,但只有在加法后进行舍入。
0.30000000000000004
转为二进制
=001100110011001100110010
3.5.8 总结

3.6 并行性与计算机算术:子字并行
许多图形系统最初使用8位数据来表示三原色中的一种,外加8位来表示一个像素的位置。
在电话会议和视频游戏中添加了扬声器和麦克风对声音的支持,音频采样需要8位以上的精度,但16位精度就已经足够了。
通过对128位加法器内划分进位链,处理器可以同时对16个8位操作数,8个16位,4个32位和2个64位操作数的短向量进行并行操作。这种分割加法器的开销很小,但带来的加速可能很大。将这种在一个宽字内部进行的并行操作称为子字并行,更通用的名称是数据级并行(data level parallelism)。对于单指令多数据,他们也被称为向量或SIMD。
3.7 实例:x86中的SIMD扩展和高级向量拓展
x86的原始MMX(MultiMedia eXtension,多媒体扩展)包含操作整数短向量的指令。而后,SSE(Streaming SIMD Extension,流式SIMD扩展)提供了操作单精度浮点数短向量的指令。在2001年,Intel在其体系结构中增加了包含双精度浮点寄存器及其操作的144条指令作为SSE2的一部分,它包含了8个可用于浮点数操作数的64位寄存器。AMD将其拓展到16个寄存器,作为AMD64的一部分,称为XMM,Intel将其标记为EM64T以供使用。
下图为:x86的SSE/SSE2浮点指令

除了在寄存器中存放单精度和双精度数,Intel还允许将多个浮点操作数组合(packed)到单个128位SSE2寄存器中:4个单精度或2个双精度。因此,SSE2的16个浮点寄存器实际为128位宽。如果操作数能够在存储器中组织成128位对齐的数据,则每条128位数据传输指令可以载入和存储多个操作数。这种组合的浮点数格式可以并行运算4个单精度(PS)或2个双精度(PD)数。
2011年,Intel使用高级向量拓展(Advanced Vector Extensions,AVX)将寄存器的位宽再次翻倍,现称为YMM。因此,现在单精度操作可以指定8个32位浮点运算或4个64位浮点运算。原有的SSE和SSE2指令现在可以操作YMM寄存器的低128位,因此,为了使用128位和256位操作,在SSE2操作的汇编指令前加上字母"v"表示向量,然后使用YMM寄存器名而不是XMM寄存器名,例如:执行2个64位浮点加法的SSE2指令。
addpd %xmm0, %xmm4
变为
vaddpd %ymm0, %ymm4
该指令现在产生4个64位浮点加法,2015年,英特尔将寄存器扩展至512位,现在称为ZIMM,在某些微处理器中使用了AVX512。英特尔已宣布计划在x86架构的最新版本中将AVX寄存器扩展到1024位。
3.8 性能提升:子字并行和矩阵乘法
前面一大段没耐心看。。。
结论:该AVX版本的速度提高了7.8倍,这非常接近于使用子字并行单次执行8倍的操作量时所期望的8倍提速。
3.9 谬误和陷阱
算术谬误和陷阱通常来源于计算机算术的有限精度和自然算术的无限精度之间的差异。
谬误:正如左移指令可以替代一个乘以2的幂的整数,右移等同于除以一个2的幂的整数。
陷阱:浮点加法不满足结合律,由于浮点数是实数的近似值,且计算机算术的精度有限,因此结合律不适用于浮点数。
谬误:适用于整型数据类型的并行执行策略也适用于浮点数据类型。
谬误:只有理论数学家关心浮点精度。
Intel为用户免费更换新版Pentium处理器,损失5亿美金。