Mongodb分布式id
1、分布式id使用场景
分布式ID是指在分布式系统中用于唯一标识每个元素的数字或字符串。在分布式系统中,各个节点或服务可能独立运行在不同的服务器、数据中心或地理位置,因此需要一种机制来确保每个生成的ID都是全局唯一的,以避免ID冲突。
以下是分布式ID的一些关键特点:
-
全局唯一性:分布式ID必须保证在全系统中的唯一性,即使在大规模分布式环境中也能确保没有重复。
-
高可用性:分布式ID的生成机制需要高可用,确保在任何时候都能生成ID。
-
高性能:ID生成过程应该快速且对系统性能影响小。
-
高并发:在高并发场景下,分布式ID生成机制应能支持大量ID的生成。
-
无单点依赖:分布式ID的生成不应依赖于单个中心服务,以避免成为系统瓶颈。
-
易于分配:分布式ID应易于在各个节点上分配和生成。
-
可扩展性:随着系统规模的扩大,ID生成机制应能够水平扩展以满足需求。
-
安全性:分布式ID不应包含敏感信息,且不易被预测。
-
有序性:虽然不是严格要求,但在某些场景下,有序的ID可以帮助优化数据库存储和查询性能。
2、常见的分布式id生成算法
- UUID(Universally Unique Identifier):基于特定算法生成的全局唯一标识符。
- 数据库自增ID:依赖于数据库的自增字段来保证唯一性。
- Redis生成ID:使用Redis的原子操作来生成唯一ID。
- Snowflake算法:由Twitter开发的算法,生成一个64位的长整型ID。
- 分段步长:从数据库批量获取ID段,然后由应用逐步分配。
3、mongodb分布式id解决方案
3.1、分布式id生成规则
MongoDB内置分布式id是指在MongoDB数据库中,有一个内置的机制可以生成全局唯一的、递增的分布式id。这个分布式id被称为ObjectId。每当在MongoDB中创建一个新文档时,都会自动生成一个ObjectId作为该文档的唯一标识符。
mongodb分布式id思想有点类似于雪花算法。
ObjectId是一个12字节的唯一标识符,由以下三个部分组成:
- 时间戳:前4个字节表示该ObjectId的生成时间戳,可以精确到秒级别。这样可以保证新创建的文档的ObjectId总是比旧的文档的ObjectId大。
- 机器标识符:接下来的3个字节表示MongoDB服务器的唯一标识符,如果是在同一台机器上创建的文档,那么这部分是相同的。
- 进程标识符:接下来的2个字节是MongoDB进程的唯一标识符,用于区分同一机器上不同的MongoDB进程。
- 随机数:最后的3个字节是一个随机数,用于避免在同一秒内生成相同的ObjectId。
由于ObjectId是全局唯一的,因此可以在分布式系统中使用它作为文档的唯一标识符,而不需要进行复杂的分布式id生成和管理。
对于一个特定的id,比如6641a6afda7b897ba34d5a81
前4个字节(8个十六进制),即6641a6af,将十六进制转为10进制的1715578543,单位为秒数,再乘以1000得到时间戳毫秒数,用js计算得到的即为生成id的时间(精确到秒)

最后3个字节(6个十六进制),即4d5a81,表示一个计数器,用于保证在同一秒产生的id不重复。3个字节,总共有3*8位,最大可表示2^24=16777216,一千六百多万,绝对够用的。
3.2、不同集合也能保证全局唯一??
网上大部分都是说这个id只保证在同一个集合(表)里是唯一的,在不同集合是没有保证的。也就是说,假设有A,B,C三张表,自动生成的id保证在三张表内部是唯一的,但不同表之间的id可以重复。针对这个说法,笔者做了一个演示。
循环1w次,每次循环生成表1的id和表2的id,分别把生成id放到一个有序的集合里。
最后发现两个集合没有交集,也就是说,两个表的id不会重复,生成的id是全集合唯一的。
public void testUid() {Set<String> set1 = new LinkedHashSet<>();Set<String> set2 = new LinkedHashSet<>();for (int i = 0; i < 10000; i++) {Table1 t = new Table1();table1Repository.insert(t);set1.add(t.getId());Table2 t2 = new Table2();table2Repository.insert(t2);set2.add(t2.getId());}System.out.println(set1);System.out.println(set2);System.out.println("两个表id交集" + Sets.intersection(set1, set2));}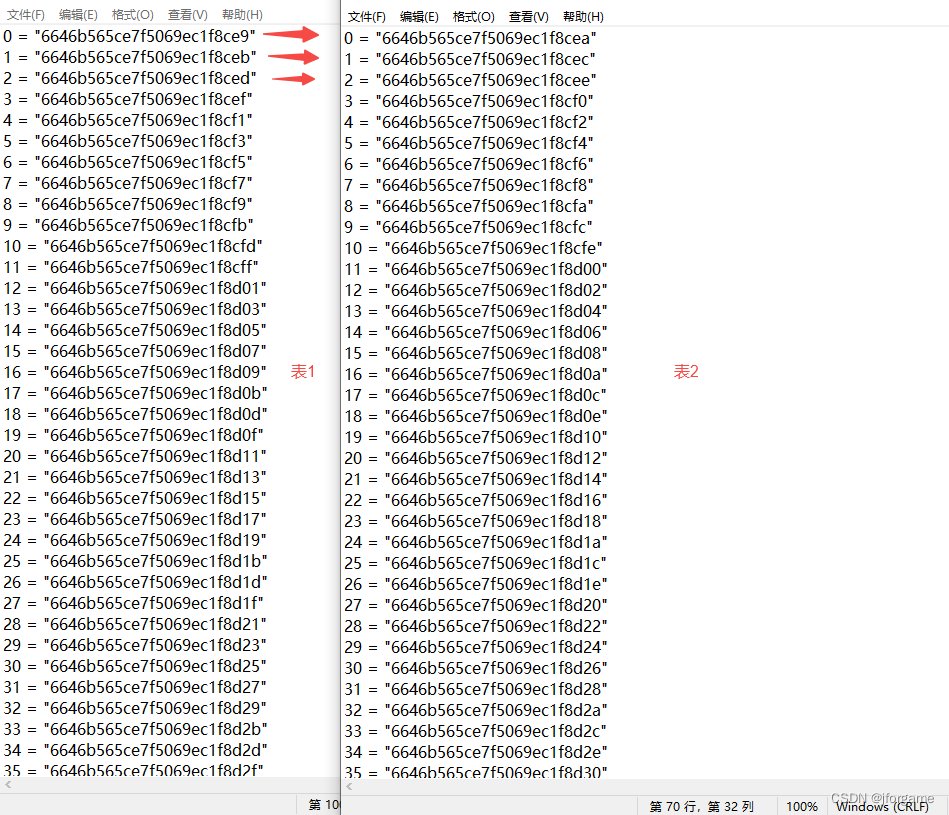
从生成的id, 表1的第一个id为e9,表2的第一个元素为ea,表1的第二个id为eb,表2的第二个元素为ec... 刚好是十六进制的递增顺序。
至于出现这种情况是否为巧合,可能需要从mongodb源码找到答案。
3.3、客户端生成API
虽然mongodo生成的id是全局唯一的,但过度依赖数据库生成id可能会给数据库带来压力,因此,也可以选择客户端api在应用程序内部生成id,再设置到数据库里。(如下为java版本相关API,存放于org.mongodb.bson依赖)
