Elasticsearch:使用 Logstash 构建从 Kafka 到 Elasticsearch 的管道 - Nodejs
在我之前的文章 “Elastic:使用 Kafka 部署 Elastic Stack”,我构建了从 Beats => Kafka => Logstash => Elasticsearch 的管道。在今天的文章中,我将描述从 Nodejs => Kafka => Logstash => Elasticsearch 这样的一个数据流。在之前的文章 “Elastic:Data pipeline:使用 Kafka => Logstash => Elasticsearch” 中,我也展示了使用 Python 的方法。我的配置如下:

在上面的架构中,有几个重要的组件:
- Kafka Server:这就是数据首先发布的地方。
- Producer:扮演将数据发布到 Kafka topic 的角色。 在现实世界中,你可以具有任何可以为 kafka 主题生成数据的实体。 在我们的示例中,我们将生成伪造的用户注册数据。
- Elasticsearch:这将充当将用户注册数据存储到其自身的数据库,并提供搜索及分析。
- Logstash:Logstash 将扮演中间人的角色,在这里我们将从 Kafka topic 中读取数据,然后将其插入到 Elasticsearch 中。
- Kibana:Kibana 将扮演图形用户界面的角色,它将以可读或图形格式显示数据。
为了演示的方便,你可以在地址下载演示文件 GitHub - liu-xiao-guo/data-pipeline8。我的文件目录是这样的:
$ pwd
/Users/liuxg/data/data-pipeline8
$ tree -L 3
.
├── README.md
├── docker-elk
│ ├── docker-compose.yml
│ └── logstash_pipeline
│ └── kafka-elastic.conf
├── docker-kafka
│ └── kafka-docker-compose.yml
└── kafka_producer.js$ pwd
/Users/liuxg/data/data-pipeline8/docker-elk
$ ls -al
total 16
drwxr-xr-x 5 liuxg staff 160 May 14 2021 .
drwxr-xr-x 8 liuxg staff 256 Mar 5 07:36 ..
-rw-r--r-- 1 liuxg staff 29 May 7 2021 .env
-rw-r--r-- 1 liuxg staff 1064 May 13 2021 docker-compose.yml
drwxr-xr-x 3 liuxg staff 96 May 13 2021 logstash_pipeline
$ vi .env
$ cat .env
ELASTIC_STACK_VERSION=8.6.2上面的其它文件将在我下面的章节中介绍。如果你自己想通过手动的方式部署 Kafka 请参阅我的另外一篇文章 “使用 Kafka 部署 Elastic Stack”。
安装
Kafka,Zookeeper 及 Kafka Manager
我将使用 docker-compose 来进行安装。一旦安装好,我们可以看到:
- Kafka 在 PORT 9092 侦听
- Zookeeper 在 PORT 2181 侦听
- Kafka Manager 侦听 PORT 9000 侦听
kafka-docker-compose.yml
version: "3"
services:zookeeper:image: zookeeperrestart: alwayscontainer_name: zookeeperhostname: zookeeperports:- 2181:2181environment:ZOO_MY_ID: 1kafka:image: wurstmeister/kafkacontainer_name: kafkaports:- 9092:9092environment:KAFKA_ADVERTISED_HOST_NAME: 192.168.0.3 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181kafka_manager:image: hlebalbau/kafka-manager:stablecontainer_name: kakfa-managerrestart: alwaysports:- "9000:9000"environment:ZK_HOSTS: "zookeeper:2181"APPLICATION_SECRET: "random-secret"command: -Dpidfile.path=/dev/null我们可以使用如下的命令来进行启动(在 Docker 运行的前提下):
docker-compose -f kafka-docker-compose.yml up
一旦运行起来后,我们可以使用如下的命令来进行查看:
docker ps$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a4acc0730467 zookeeper "/docker-entrypoint.…" About a minute ago Up About a minute 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp, 8080/tcp zookeeper
02ec8e8a1e30 hlebalbau/kafka-manager:stable "/kafka-manager/bin/…" About a minute ago Up About a minute 0.0.0.0:9000->9000/tcp kakfa-manager
a85c32c0c08e wurstmeister/kafka "start-kafka.sh" About a minute ago Up About a minute 0.0.0.0:9092->9092/tcp kafka我们发现 Kafka Manager 运行于 9000 端口。我们打开本地电脑的 9000 端口:


 在上面它显示了一个默认的 topic,虽然不是我们想要的。
在上面它显示了一个默认的 topic,虽然不是我们想要的。



这样,我们就把 Kafka 上的 kafka_logstash topic 创建好了。
我们可以登录 kafka 容器来验证我们已经创建的 topic。我们使用如下的命令来找到 kafka 容器的名称:
docker ps -s$ docker ps -s
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES SIZE
de7453250529 hlebalbau/kafka-manager:stable "/kafka-manager/bin/…" 9 minutes ago Up 9 minutes 0.0.0.0:9000->9000/tcp kakfa-manager 117kB (virtual 427MB)
65eba68350f1 zookeeper "/docker-entrypoint.…" 9 minutes ago Up 9 minutes 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp, 8080/tcp zookeeper 33kB (virtual 288MB)
3394868b23e9 wurstmeister/kafka "start-kafka.sh" 9 minutes ago Up 9 minutes 0.0.0.0:9092->9092/tcp kafka 210kB (virtual 457MB)上面显示 kafka 的容器名称为 wurstmeister/kafka。我们使用如下的命令来进行登录:
docker exec -it wurstmeister/kafka /bin/bash然后我们在容器里 打入如下的命令:
$ docker exec -it kafka /bin/bash
root@3394868b23e9:/# kafka-topics.sh --list -zookeeper zookeeper:2181
__consumer_offsets
kafka_logstash上面的命令显示已经存在的被创建的 kafka_logstash topic。我们可以使用如下的命令来向这个被创建的 topic 来发送数据:
kafka-console-consumer.sh --bootstrap-server 192.168.0.3:9092 --topic kafka_logstash --from-beginningroot@3394868b23e9:/# kafka-console-consumer.sh --bootstrap-server 192.168.0.3:9092 --topic kafka_logstash --from-beginningElastic Stack 安装
我们接下来安装 Elastic Stack。同样地,我使用 docker-compose 来部署 Elasticsearch, Logstash 及 Kibana。你们可以参考我之前的文章 “Logstash:在 Docker 中部署 Logstash”。为了能够把数据传入到 Elasticsearch 中,我们需要在 Logstash 中配置一个叫做 kafka-elastic.conf 的配置文件:
kafka-elastic.conf
input {kafka {bootstrap_servers => "192.168.0.3:9092"topics => ["kafka_logstash"]}
}output {elasticsearch {hosts => ["elasticsearch:9200"]index => "kafka_logstash"workers => 1}
}请注意:在上面的 192.168.0.3 为我自己电脑的本地 IP 地址。为了说明问题的方便,我们没有对来自 kafka 里的 registered_user 这个 topic 做任何的数据处理,而直接发送到 Elasticsearch 中。
我们的 docker-compose.yml 配置文件如下:
docker-compose.yml
version: "3.9"
services:elasticsearch:image: elasticsearch:${ELASTIC_STACK_VERSION}container_name: elasticsearchenvironment:- discovery.type=single-node- ES_JAVA_OPTS=-Xms1g -Xmx1g- xpack.security.enabled=falsevolumes:- type: volumesource: es_datatarget: /usr/share/elasticsearch/dataports:- target: 9200published: 9200networks:- elastickibana:image: kibana:${ELASTIC_STACK_VERSION}container_name: kibanaports:- target: 5601published: 5601depends_on:- elasticsearchnetworks:- elastic logstash:image: logstash:${ELASTIC_STACK_VERSION}container_name: logstashports:- 5200:5200volumes: - type: bindsource: ./logstash_pipeline/target: /usr/share/logstash/pipelineread_only: truenetworks:- elastic volumes:es_data:driver: localnetworks:elastic:name: elasticdriver: bridge为方便起见,在我的安装中,我没有配置安全。如果你需要为 Elasticsearch 设置安全的话,请参考我之前的文章 “Elasticsearch:使用 Docker compose 来一键部署 Elastic Stack 8.x”。
我们使用如下的命令来启动 Elastic Stack。在 docker-compose.yml 所在的目录中打入如下的命令:
$ pwd
/Users/liuxg/data/data-pipeline8/docker-elk
$ ls
docker-compose.yml logstash_pipeline
$ docker-compose up
等所有的 Elastic Stack 运行起来后,我们再次通过如下的命令来进行查看:
docker ps$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3db5e4e6e23e kibana:8.6.2 "/bin/tini -- /usr/l…" About a minute ago Up About a minute 0.0.0.0:5601->5601/tcp kibana
210b673dd89a logstash:8.6.2 "/usr/local/bin/dock…" About a minute ago Up About a minute 5044/tcp, 9600/tcp, 0.0.0.0:5200->5200/tcp logstash
05c434edd823 elasticsearch:8.6.2 "/bin/tini -- /usr/l…" About a minute ago Up About a minute 0.0.0.0:9200->9200/tcp, 9300/tcp elasticsearch
de7453250529 hlebalbau/kafka-manager:stable "/kafka-manager/bin/…" 51 minutes ago Up 51 minutes 0.0.0.0:9000->9000/tcp kakfa-manager
65eba68350f1 zookeeper "/docker-entrypoint.…" 51 minutes ago Up 51 minutes 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp, 8080/tcp zookeeper
3394868b23e9 wurstmeister/kafka "start-kafka.sh" 51 minutes ago Up 51 minutes 0.0.0.0:9092->9092/tcp kafka我们可以看到 Elasticsearch 运用于 9000 端口,Kibana 运行于 5601 端口,而 Logstash 运行 5000 端口。 我们可以访问 Kibana 的端口地址 5601:

运行 Nodejs 应用导入模拟数据
我们接下来建立一个 Nodejs 的应用来模拟一些数据。首先,我们需要安装如下的包:
npm install kafkajs uuid randomstring random-mobile
我们在根目录下打入如下的命令:
npm init -y$ npm init -y
Wrote to /Users/liuxg/data/data-pipeline8/package.json:{"dependencies": {"kafkajs": "^2.2.4"},"name": "data-pipeline8","description": "This is a sample code showing how to realize the following data pipeline:","version": "1.0.0","main": "kafka_producer.js","devDependencies": {},"scripts": {"test": "echo \"Error: no test specified\" && exit 1"},"repository": {"type": "git","url": "git+https://github.com/liu-xiao-guo/data-pipeline8.git"},"keywords": [],"author": "","license": "ISC","bugs": {"url": "https://github.com/liu-xiao-guo/data-pipeline8/issues"},"homepage": "https://github.com/liu-xiao-guo/data-pipeline8#readme"
}
上述命令生成一个叫做 package.json 的文件。在以后安装的 packages,它也会自动添加到这个文件中。默认的设置显然不是我们想要的。我们需要对它做一些修改。
kafka_producer.js
// import { Kafka, logLevel } from "kafkajs";
const { Kafka } = require('kafkajs');
const logLevel = require("kafkajs");// import { v4 as uuidv4 } from "uuid";
const { v4: uuidv4 } = require('uuid');console.log(uuidv4());const kafka = new Kafka({clientId: "random-producer",brokers: ["localhost:9092"],connectionTimeout: 3000,
});var randomstring = require("randomstring");
var randomMobile = require("random-mobile");
const producer = kafka.producer({});
const topic = "kafka_logstash";const produce = async () => {await producer.connect();let i = 0;setInterval(async () => {var event = {};try {event = {globalId: uuidv4(),event: "USER-CREATED",data: {id: uuidv4(),firstName: randomstring.generate(8),lastName: randomstring.generate(6),country: "China",email: randomstring.generate(10) + "@gmail.com",phoneNumber: randomMobile(),city: "Hyderabad",createdAt: new Date(),},};await producer.send({topic,acks: 1,messages: [{value: JSON.stringify(event),},],});// if the message is written successfully, log it and increment `i`console.log("writes: ", event);i++;} catch (err) {console.error("could not write message " + err);}}, 5000);
};produce().catch(console.log)我们运行上面的 Nodejs 代码:
npm start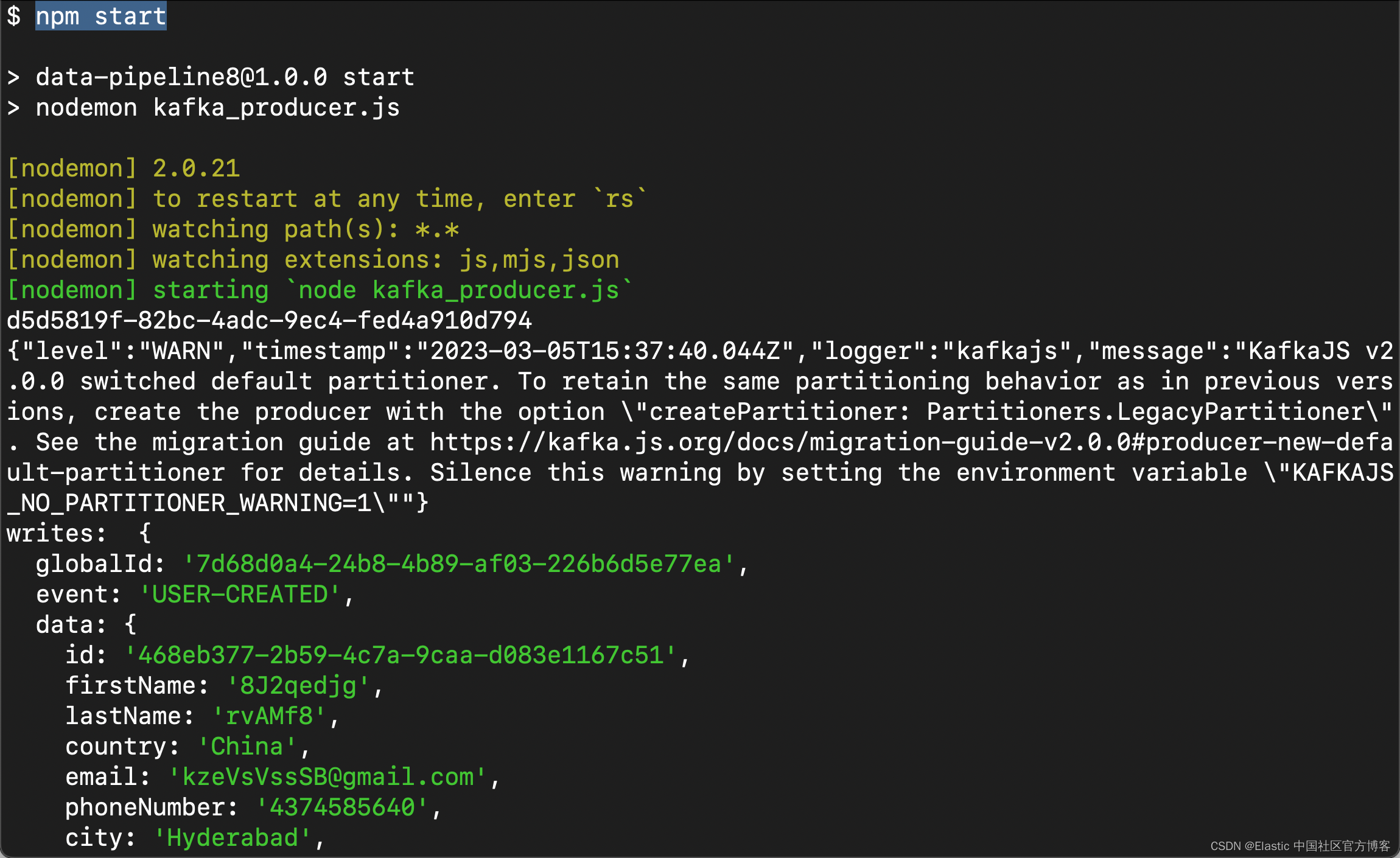
我们接下来在 Kibana 中来查看索引 kafka_logstash:
GET kafka_logstash/_count{"count": 103,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0}
}我们可以看到文档的数值在不断地增加。我们可以查看文档:
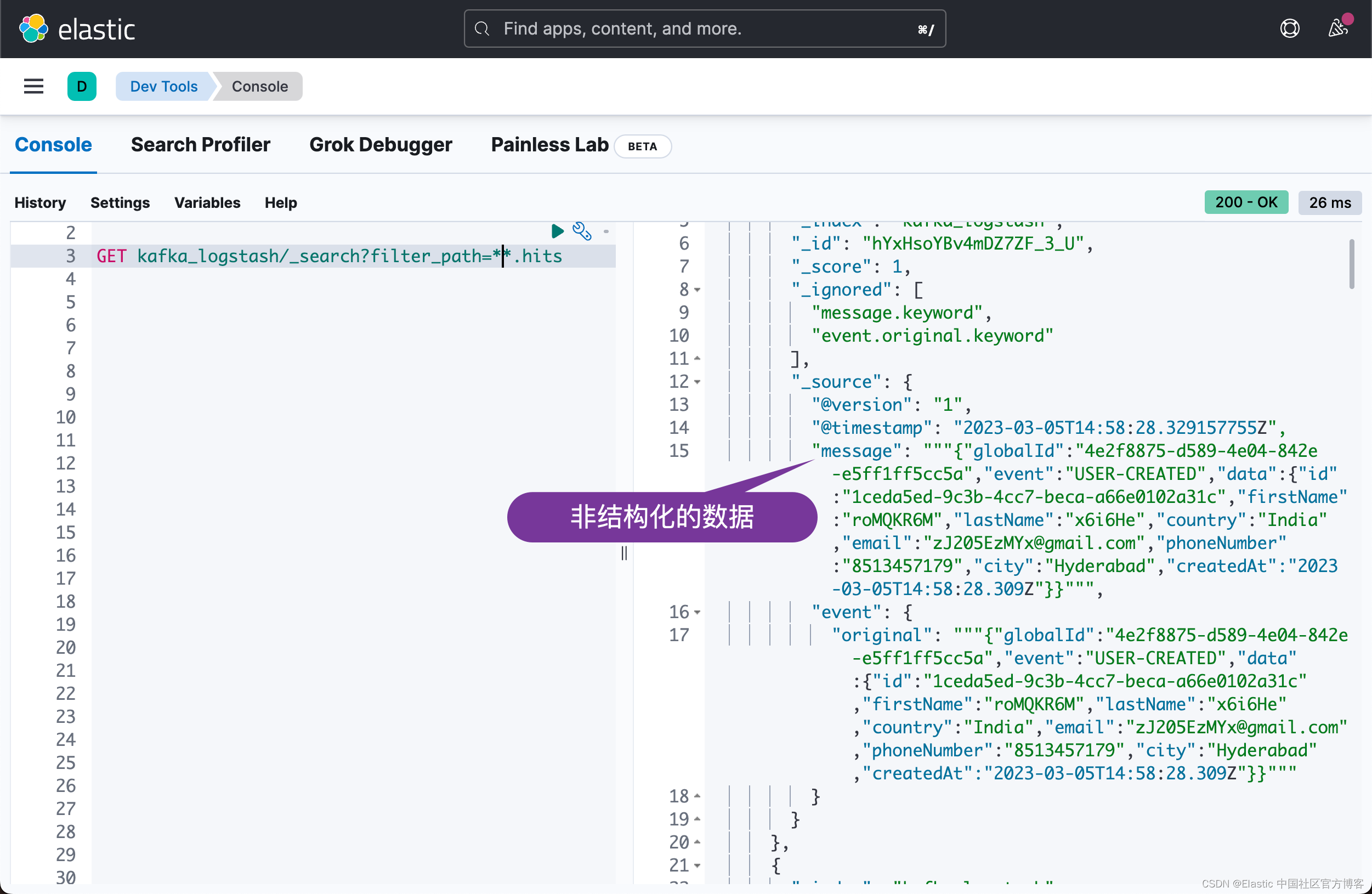
很显然我们收到了数据。从上面的结果中,我们可以看出来是一些非结构化的数据。我们可以针对 Logstash 的 pipeline 进行修改:
kafka-elastic.conf
input {kafka {bootstrap_servers => "192.168.0.3:9092"topics => ["kafka_logstash"]}
}filter {json {source => "message"}mutate {add_field => {"id" => "%{[data][id]}"}add_field => {"firstName" => "%{[data][firstName]}"}add_field => {"lastName" => "%{[data][lastName]}"}add_field => {"city" => "%{[data][city]}"}add_field => {"country" => "%{[data][country]}"}add_field => {"email" => "%{[data][email]}"}add_field => {"phoneNumber" => "%{[data][phoneNumber]}"}add_field => {"createdAt" => "%{[data][createdAt]}"}remove_field => ["data", "@version", "@timestamp", "message", "event", "globalId"]}
}output {elasticsearch {hosts => ["elasticsearch:9200"]index => "kafka_logstash"workers => 1}
}我们在 Kibana 中删除 kafka_logstash:
DELETE kafka_logstash我们停止运行 Nodejs 应用。我们把运行 Elastic Stack 的 docker-compose 关掉,并再次重新启动它:
docker-compose down
docker-compose up
我们再次运行 Nodejs 应用:

我们再次到 Kibana 中进行查看:
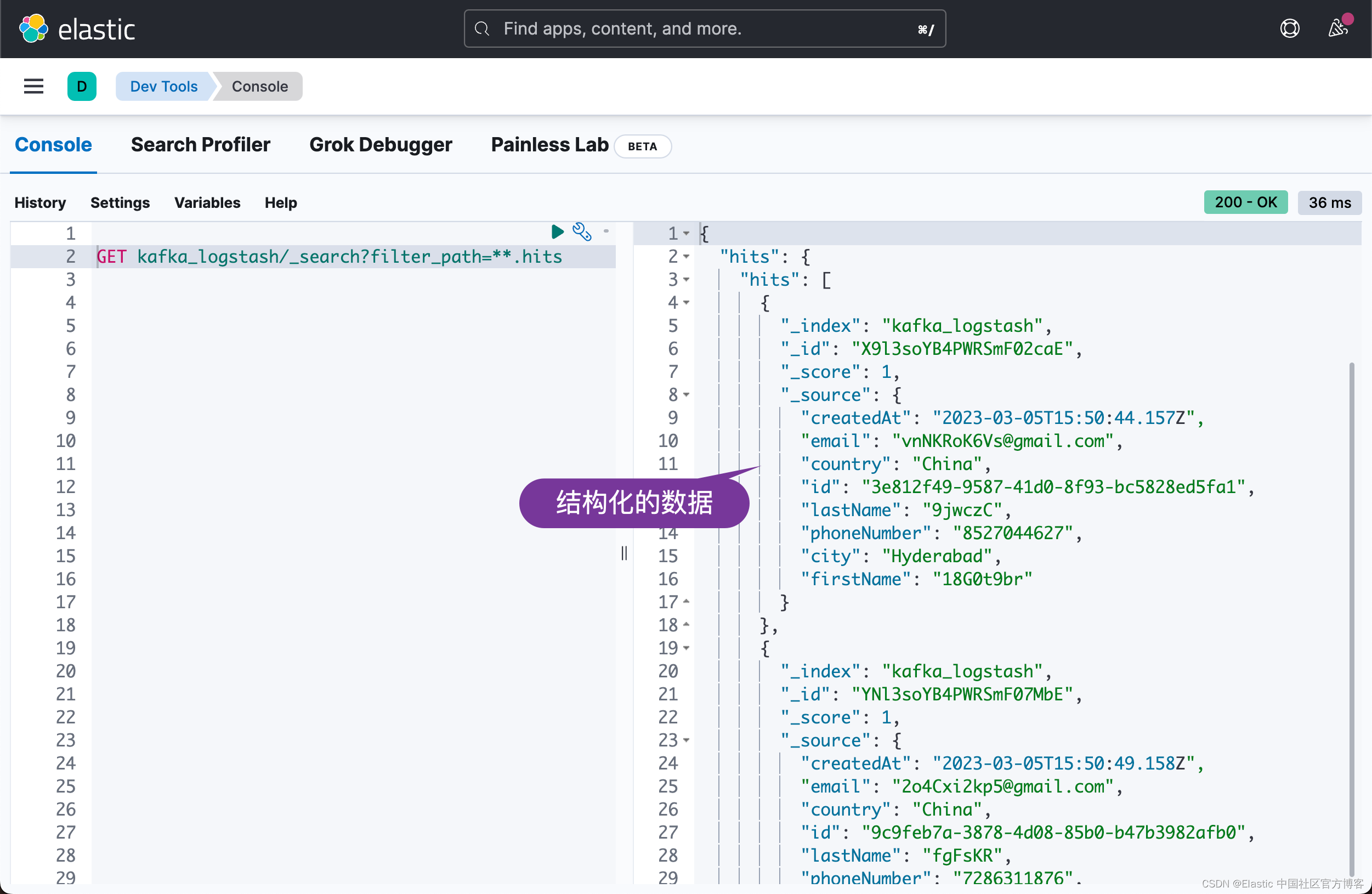
很显然,这次,我们看到结构化的输出文件。