Kafka生产者的粘性分区算法
分区算法分类
kafka在生产者投递消息时,会根据是否有key采取不用策略来获取分区。
存在key时会根据key计算一个hash值,然后采用hash%分区数的方式获取对应的分区。
而不存在key时采用随机算法选取分区,然后将所有的消息封装到这个batch上直到达到限定数量,然后才发送出去。
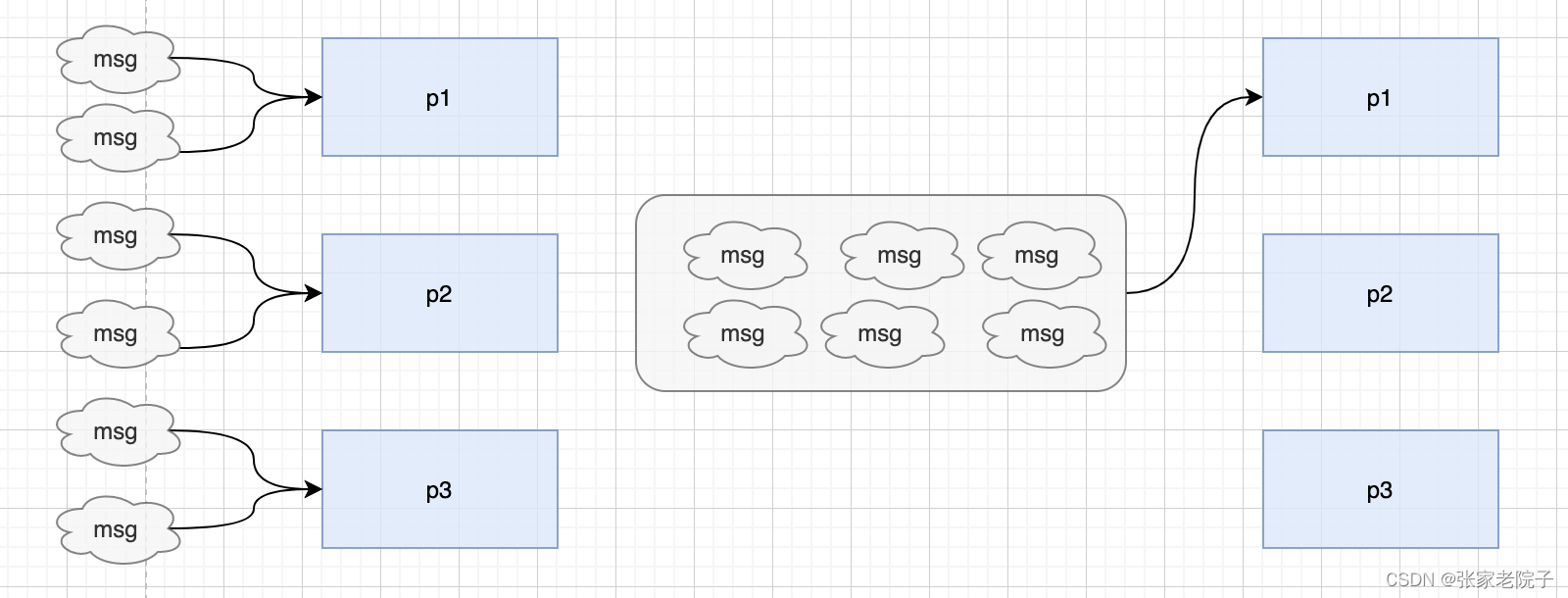
如下图,6条消息采用key可能分三次发送到三个不同的分区,需要3次网络请求。如果没有key将封住成一个批次发送。这样一次网路请求就可以发送多条消息,大大提高了效率。
源码分析
producer根据keyBytes是否有值采用不同的分区策略。有key的计算hash % numPartitions得到分区。
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,int numPartitions) {if (keyBytes == null) {return stickyPartitionCache.partition(topic, cluster);}// hash the keyBytes to choose a partitionreturn Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;}并且kafka在这里做了缓存,如果第一次获取到了粘性分区后面会缓存起来。
public int partition(String topic, Cluster cluster) {Integer part = indexCache.get(topic);if (part == null) {return nextPartition(topic, cluster, -1);}return part;}没有key的采用stickyPartitionCache的策略,这里是分区算法的主要代码。获取所有的availablePartitions,然后如果availablePartitions大于1,获取一个随机数random,然后通过random % availablePartitions.size()的方式获取分区。
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);if (availablePartitions.size() < 1) {Integer random = Utils.toPositive(ThreadLocalRandom.current().nextInt());newPart = random % partitions.size();} else if (availablePartitions.size() == 1) {newPart = availablePartitions.get(0).partition();} else {while (newPart == null || newPart.equals(oldPart)) {int random = Utils.toPositive(ThreadLocalRandom.current().nextInt());newPart = availablePartitions.get(random % availablePartitions.size()).partition();}}abortForNewBatch表示需要发送到新的批次,然后调用onNewBatch获取新的分区。
if (result.abortForNewBatch) {int prevPartition = partition;partitioner.onNewBatch(record.topic(), cluster, prevPartition);partition = partition(record, serializedKey, serializedValue, cluster);tp = new TopicPartition(record.topic(), partition);...public void onNewBatch(String topic, Cluster cluster, int prevPartition) {stickyPartitionCache.nextPartition(topic, cluster, prevPartition);}在下一个批次发送时会检测是否和上一个分区相同,如果相同将会缓存一个新的分区。
// Check that the current sticky partition for the topic is either not set or that the partition that // triggered the new batch matches the sticky partition that needs to be changed.if (oldPart == null || oldPart == prevPartition) {总结
为了提升kafka发送消息的速率,在对消息顺序没有特殊的要求情况下,应该尽量避免设置消息的key,这样可以提交发送消息的吞吐量。