缓慢变化维 常用的处理方法
什么是缓慢变化维
维度
在数仓中,表往往会被划分成两种类型,一种是 事实表,另一种是维度表,举个例子,比如说:
❝2024年2月14日,健鑫在12306上买了两张火车票,每张火车票400元,一共花了800元
在这个过程中,可以这样划分:
事实:买火车票、买两张、一张400、一共800;也就是买了多少东西、花了多少钱
维度:2024年2月14日、健鑫、12306、火车票;也就是在哪买的、谁买的,啥时候买的
缓慢变化维
我们会将分析的各种角度存储在维度表当中,但是维度数据是会发生变化的,而且时间跨度非常久
比如部门的变更,一个员工最初是在部门a工作,后面由于一些原因转到了部门b
这是缓慢变化维的一种可能
这种维度变化,业务系统往往不会保存历史数据,但是站在分析的角度上,我们要保留这种变化的痕迹
处理方法
重写
和业务数据保持一致,直接更新到最新的数据
这种方法可以用于以下两种情况:
-
必须正确的数据。比如说身份证号,这种数据需要更改只能证明之前数据错了
-
不需要考虑历史变化。比如用户更换头像,这种历史头像往往不具备分析价值
优点: 省事(直接update就行了)、节省内存空间(不需要保存历史数据)
缺点: 不保存历史数据
添加新行
如果只需要保存历史数据,可以使用更新时间戳的形式记录新值,也就是拉链表
在这里随便找了一个制作拉链表过程的图片
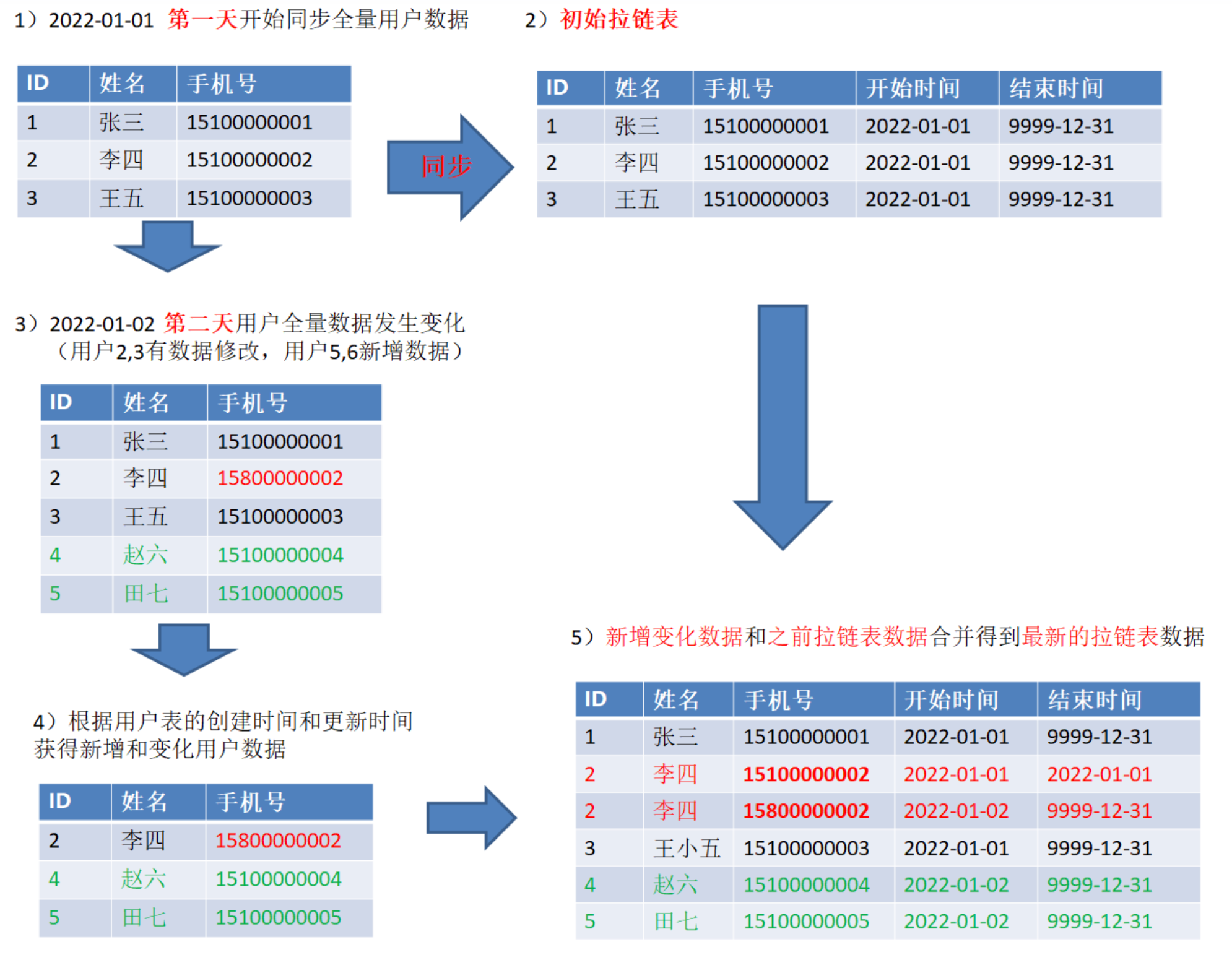
❝自然键即指有业务意义的唯一ID,例如数据库ID、表ID、用户ID等。代理键则可以简单理解为该表的自增ID值
在上面图片中ID就是自然键,开始和结束时间就是代理键
维度值更新之后可以根据代理键就可以获取最新或者历史的数据
增加属性
如果分析的场景同时包含旧值和新值,那么前两种方法就不能满足要求
比如部门的名称突然出现变化,但是想暂时保留旧名称用于同比/环比的分析
也就是,通过新名称可以进行分析,同时通过旧名称也可以进行分析,好像什么都没发生过
如果使用第一个方法,只有新值无法满足用旧值进行分析的场景
如果使用第二个方法,旧的事实保存旧的维度,新的事实保存新的维度,满足不了上面任何一个场景
这时可以新增一个字段来保存新值
| id | name | dept_2023 | dept_2024 |
|---|---|---|---|
| 1 | jx | 部门a | 部门aa |
总结
本文写了缓慢变化维最常见的处理方法,但是不包含所有的方法,希望可以帮助到你