Hive底层数据存储格式
前言
在大数据领域,Hive是一种常用的数据仓库工具,用于管理和处理大规模数据集。Hive底层支持多种数据存储格式,这些格式对于数据存储、查询性能和压缩效率等方面有不同的优缺点。本文将介绍Hive底层的三种主要数据存储格式:文本文件格式、Parquet格式和ORC格式。
一、三种存储格式
-
文本文件格式:文本文件格式是最基本的数据存储格式之一,它以纯文本方式存储数据,每一行表示一条记录。这种格式简单易用,适用于各种类型的数据,但由于没有压缩和优化,它的存储效率相对较低。同时,在查询性能方面,由于数据没有被结构化,可能会出现较慢的查询速度。
-
Parquet格式:Parquet是一种列式存储格式,它将数据按列进行存储,相同类型的数据被存储在一起,利于数据压缩和编码。这种格式在存储大规模数据时非常高效,可以大幅减少存储空间,并提高查询性能。由于Hive支持谓词下推优化,Parquet格式可以更好地利用这一特性,使得查询更快速。在一个 Parquet 类型的 Hive 表文件中,数据被分成多个行组,每个列块又被拆分成若干的页(Page),如下图所示:
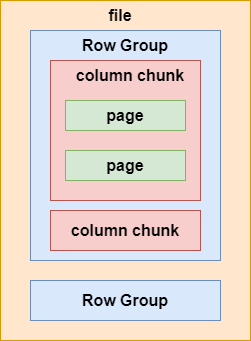
Parquet 在存储数据时,元数据也同 Parquet 的文件结构一样,被分成多层文件级别的元数据、列块级别的元数据及页级别的元数据。