精进不休丨MogDB 数据库预读特性进一步提升20%+查询性能

7月底发布的 MogDB 5.0.8版本引入了几个新特性,其中预读特性将全表扫描能力再度提升了至少20%以上(最大提升达到52%)。
什么是 MogDB 预读特性
数据库中的数据是按照一个个页面进行组织管理的,CPU以页面为单位对数据进行处理,这就使得CPU处理和I/O之间形成了串行交替执行的现象。在该处理模型中,由于一个页面的I/O时延明显大于CPU处理一个页面的时间,导致CPU处理过程会被I/O操作频繁打断,使CPU利用率低下,这是导致如全表扫描等场景性能差的主要原因。
顺序扫描预读机制改变了该处理模型,将顺序扫描的CPU处理过程与I/O操作并行化,尽量避免CPU因为等待I/O而阻塞。理想状态是,当CPU将要处理下一个数据页时,刚好I/O服务例程已经将该数据页准备好放在内存中。我们把这种模型定义为数据页预读机制(data prefetch)。
本特性在全表扫描类查询(如TPCH场景)中,SeqScan算子性能提升20%-60%,端到端性能提升10%-20%。
注:
并非所有SQL在任何测试场景下,都有上述性能提升。预读性能提升主要和查询语句的复杂度(CPU计算和I/O耗时)及磁盘带宽有关,其他影响因素包括是否为全缓存场景、是否为混合查询负载。
算子性能提升明显的SQL特征:CPU计算耗时重,I/O带宽未达到磁盘最大带宽。端到端性能提升明显的SQL特征:CPU计算和I/O耗时各占50%左右,I/O带宽未达到磁盘最大带宽。本特性默认关闭,设置GUC参数enable_ios = on,enable_heap_async_prefetch = on启用Astore顺序扫描预读。设置GUC参数 enable_ios = on,enable_uheap_async_prefetch = on启用Ustore顺序扫描预读。
预读特性的应用场景和说明
MogDB 的顺序扫描预读针对较大数据量下的纯数据表顺序扫描场景(全表扫描场景)进行优化,提升扫描性能。本特性支持Astore和Ustore两种存储引擎,并且支持并行扫描下预读,适用于OLAP场景。
如何使用 MogDB seqscan预读
++astore
enable_ios = true // 系统级别,重启数据库生效,默认为false
enable_heap_async_prefetch=true // 会话级别,支持在线配置,默认为false++ustore
enable_ios = true // 系统级别,重启数据库生效,默认为false
enable_uheap_async_prefetch=true // 会话级别,支持在线配置,默认为false补充说明:
1、如果使用普通的机械硬盘,磁盘IO带宽可能是系统瓶颈,所以不能体现出预读的优势。
2、顺序预读机制主要适用于数据量很大的表(至少为GB级别),对于数据量很小的表,不建议开启预读。目前默认1GB触发预读,可以设置的触发预读的最小表大小为512MB,用户可以由GUC参数min_table_block_num_enable_ios和min_uheap_table_block_num_enable_ios调整触发预读的表大小。
MogDB Astore测试效果
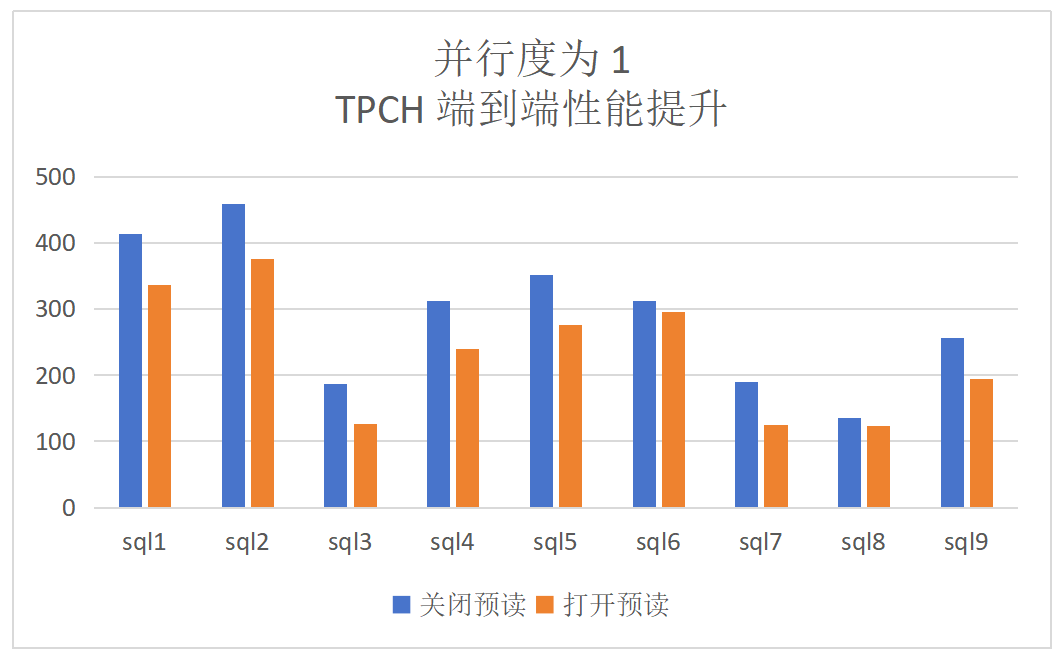
dop=1:TPCH顺序扫描算子提升为52%,端到端的提升为27%: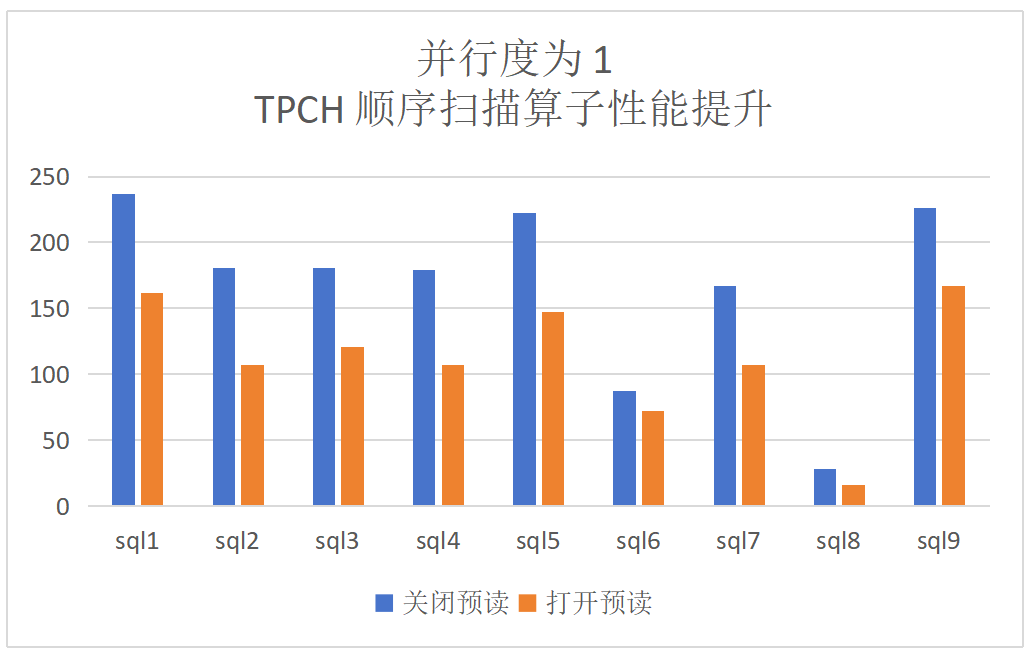
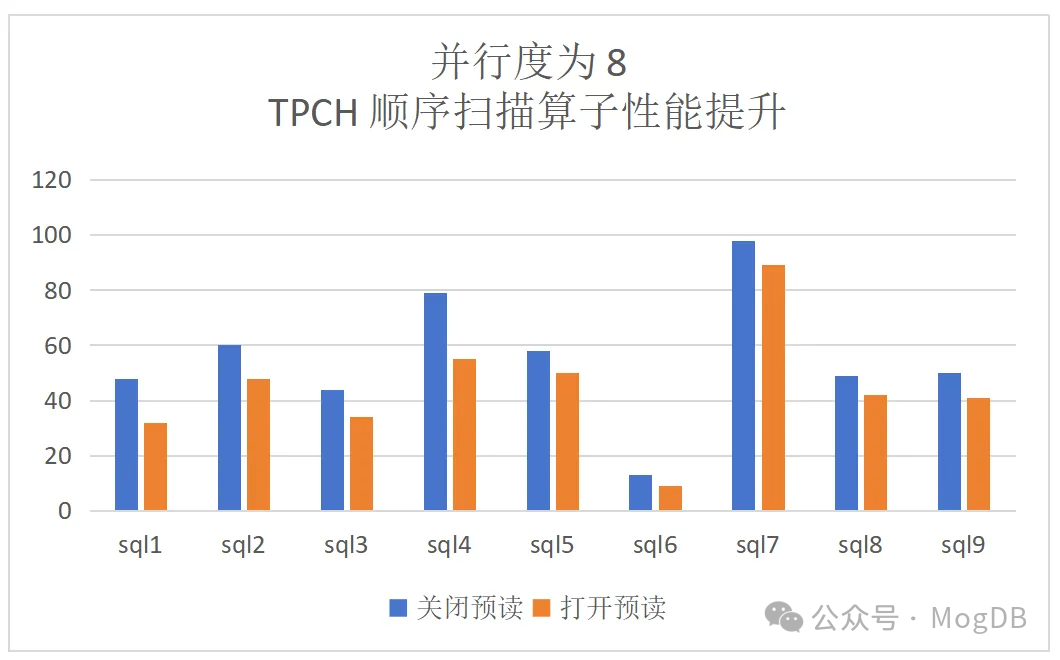
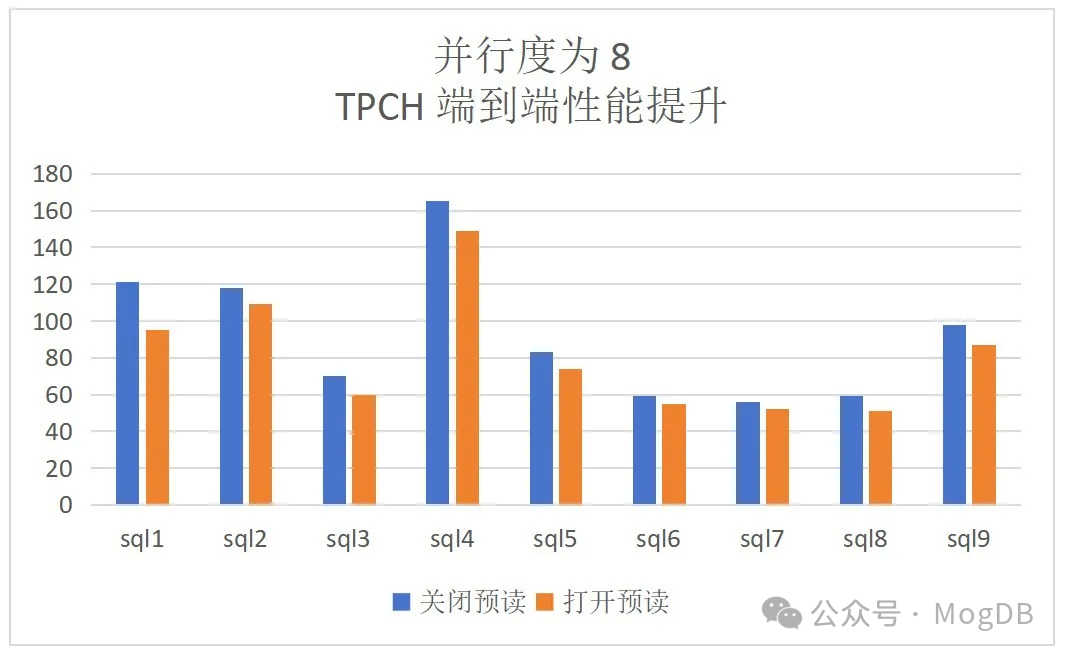
dop=8:TPCH顺序扫描算子提升为28%,端到端的提升为13%:
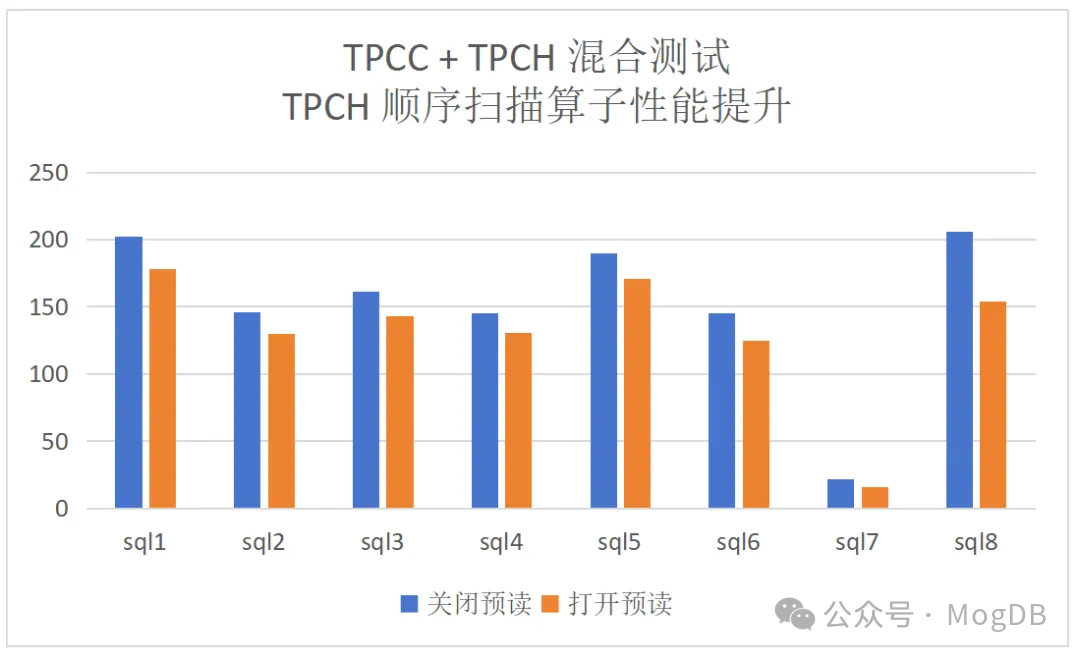
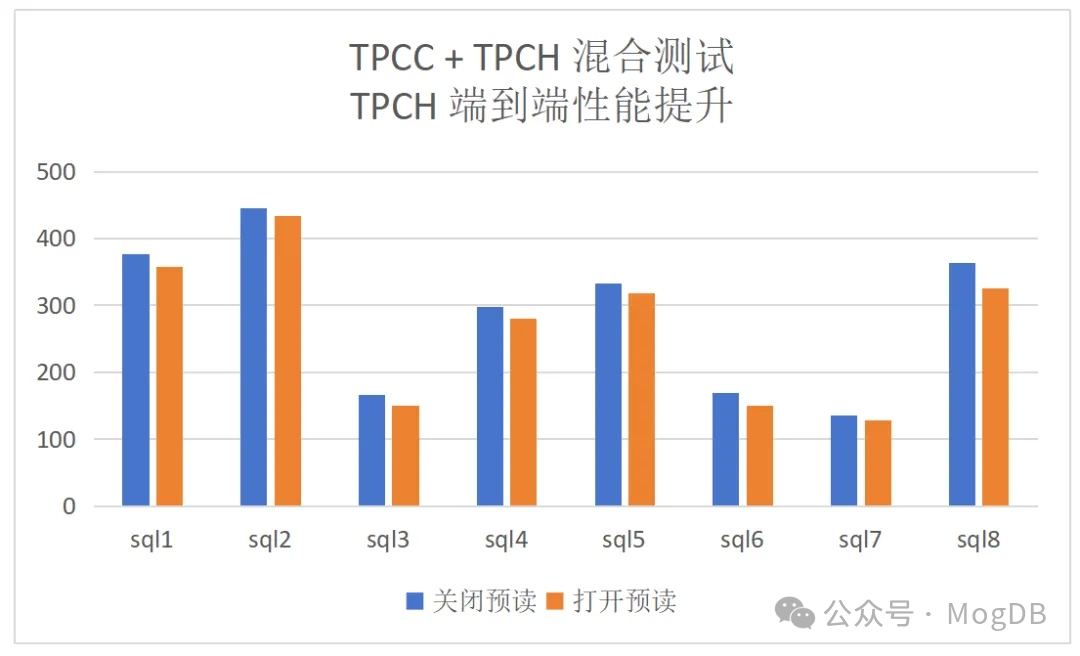
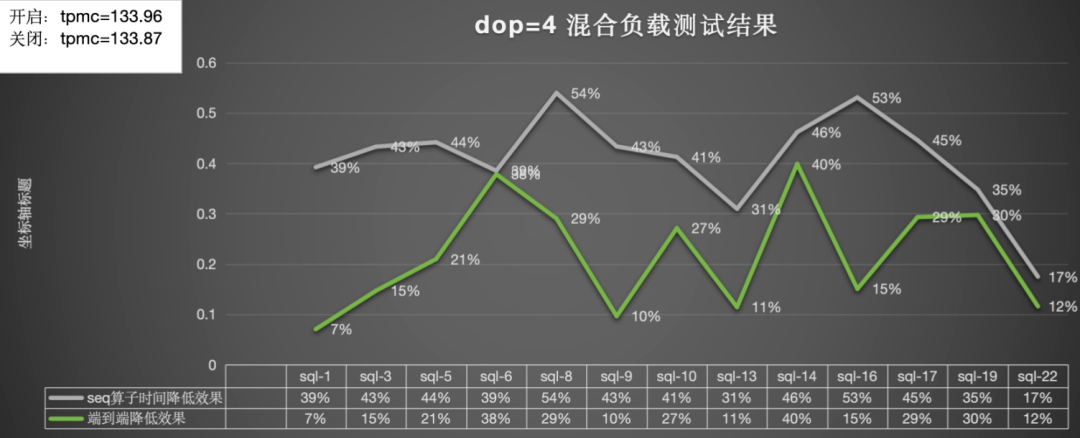
混合负载(tpcc+tpch)的情况下性能提升的结果和对TPMC的影响:
MogDB Ustore测试效果
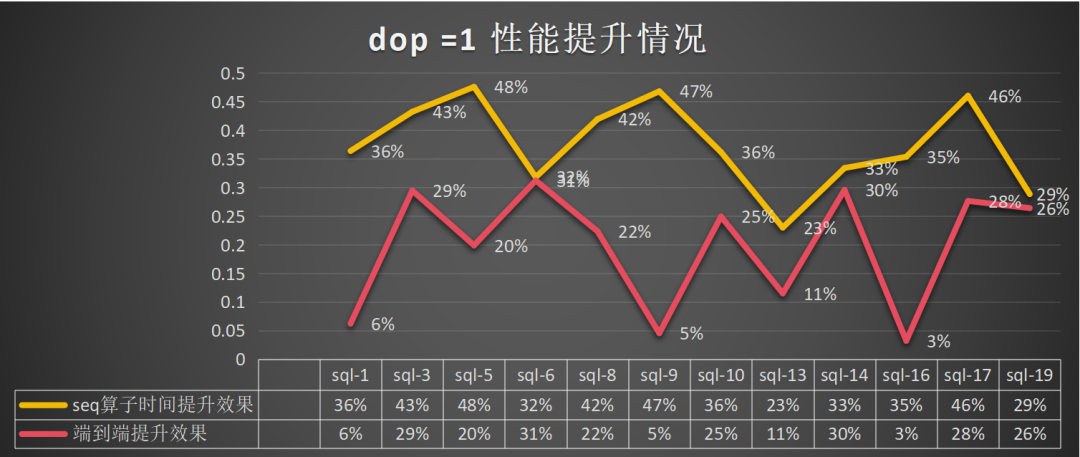
dop=1:总体算子提升为41%,端到端的提升为19%:
dop=4:总体算子提升为43%,端到端的提升为21%:
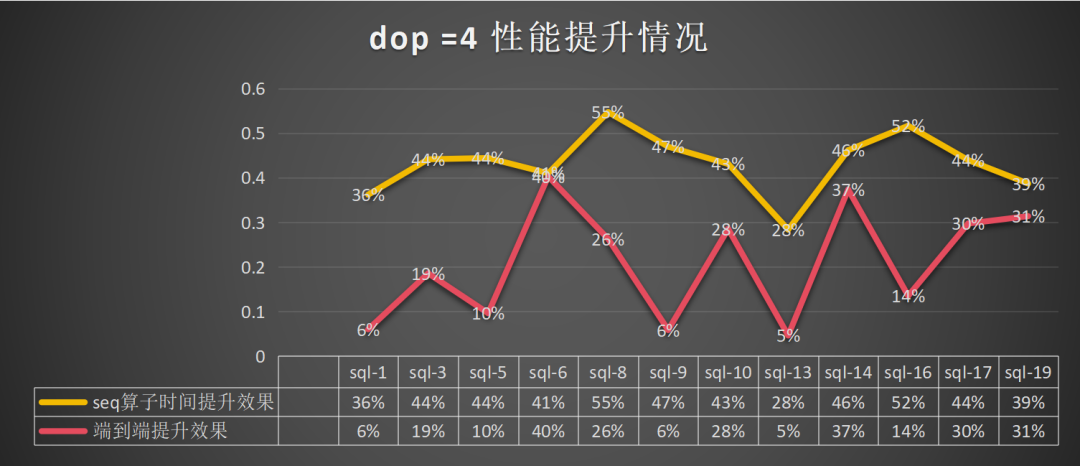
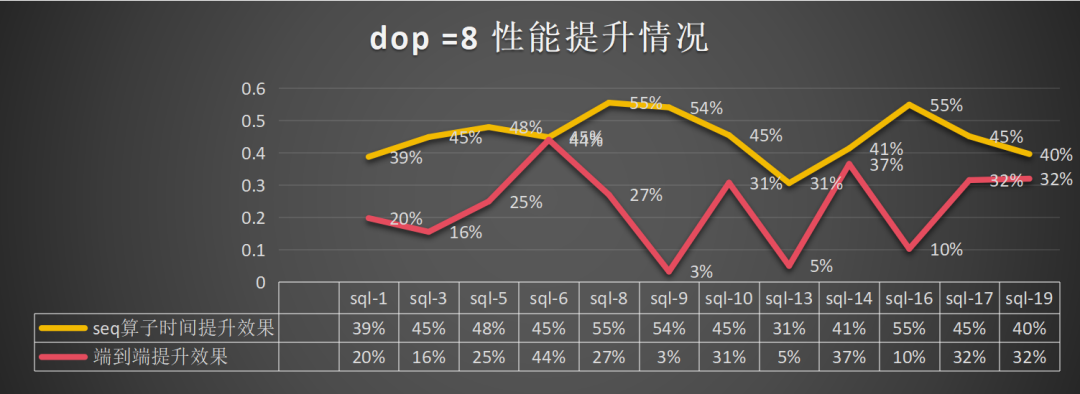
dop=8:总体算子提升为45%,端到端的提升为23%:
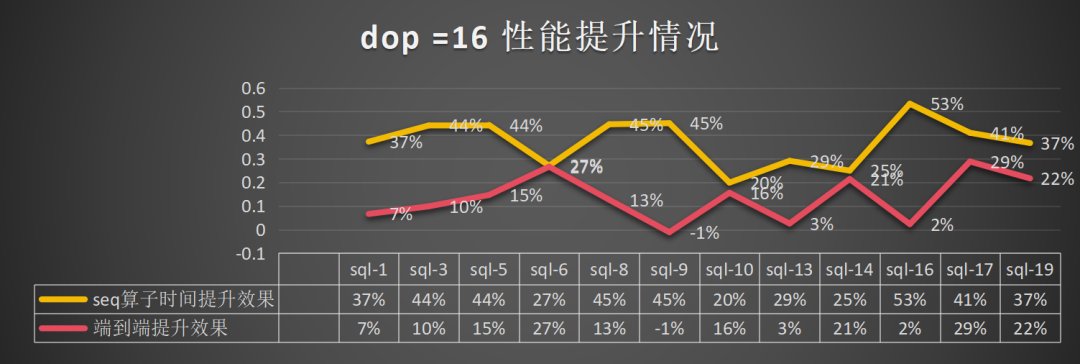
dop=16:总体算子提升为37%,端到端的提升为13%:
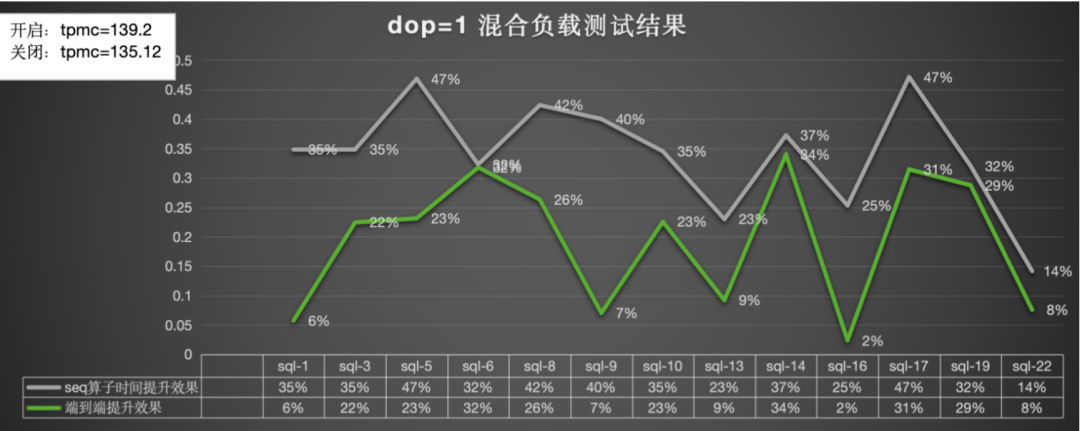
混合负载(tpcc+tpch)的情况下性能提升的结果和对TPMC的影响:
dop=1:总体算子提升为32%,端到端的提升为19%,tpmc效果提升3%,tpmc不受预读影响:
dop=4:总体算子提升为38%,端到端的提升为22%,tpmc效果提升2%,tpmc不受预读影响:
关于作者
李真旭,网名Roger,前Oracle ACE。拥有超过十多年的Oracle运维管理使用经验,参与过众多移动、电信、联通、银行等大型数据库交付项目,具有丰富的运维管理经验;对数据库管理运行机制、锁机制、优化机制等具有深入理解,擅长数据库的performance tunning、troubleshooting以及异常恢复,帮助众多中大型客户解决了无数疑难问题,累计恢复的数据总量超过1个PB。
END
数据驱动,成就未来,云和恩墨,不负所托!
云和恩墨创立于2011年,是业界领先的“智能的数据技术提供商”。公司以“数据驱动,成就未来”为使命,致力于将创新的数据技术产品和解决方案带给全球的企业和组织,帮助客户构建安全、高效、敏捷且经济的数据环境,持续增强客户在数据洞察和决策上的竞争优势,实现数据驱动的业务创新和升级发展。
自成立以来,云和恩墨专注于数据技术领域,根据不断变化的市场需求,创新研发了系列软件产品,涵盖数据库、数据库存储、数据库云管和数据智能分析等领域。这些产品已经在集团型、大中型、高成长型客户以及行业云场景中得到广泛应用,证明了我们的技术和商业竞争力,展现了公司在数据技术端到端解决方案方面的优势。