Java基础—正则表达式
目录
- 一、概念
- 1、用途
- 2、解释Matcher类中的group()方法
- 3、Matcher类中group()和group(0)方法的区别
- 二、各种元字符
- 1、转义符
- 1.1、\
- 2、定位符
- 2.1、^
- 2.2、$
- 3、限定符
- 3.1、*
- 3.2、+
- 3.3、?
- 3.4、{n}
- 3.5、{n,}
- 3.6、{n,m}
- 3.7、?(非贪婪模式)
- 4、范围字符
- 4.1、x|y
- 4.2、[xyz]
- 4.3、[^xyz]
- 4.4、[a-z]
- 5、特殊字符
- 5.1、$
- 5.2、( )
- 5.3、*、+、?、\、^、|
- 5.4、.
- 5.5、[
- 6、非打印字符
- 6.1、\b
- 6.2、\B
- 6.3、\d
- 6.4、\D
- 6.5、\n
- 6.6、\r
- 6.7、\f
- 6.8、\t
- 6.9、\v
- 6.10、\s
- 6.11、\S
- 6.12、\w
- 6.13、\W
- 7、普通匹配、非获取匹配、零宽断言
- 7.1、普通匹配:(pattern)
- 7.2、非获取匹配:(?:pattern)
- 7.3、零宽断言
- 7.3.1、概念
- 7.3.2、正向先行断言:(?=pattern)
- 7.3.3、负向先行断言:(?!pattern)
- 7.3.4、正向后行断言:(?<=pattern)
- 7.3.5、负向后行断言:(?<!pattern)
- 7.3.6、综合运用示例
- 8、反向引用
- 8.1、内部引用
- 8.2、外部引用
- 三、常用方法
- 1、常用类
- 2、Pattern的编译方法
- 2.1、接收一个参数
- 2.2、接收两个参数
- 3、Pattern的整体匹配方法
- 4、Pattern类、Matcher类的分组查找、取值方法
- 5、Pattern 类的分割方法
- 6、Matcher 类的查找方法
- 6.1、find()方法
- 6.2、matches()方法
- 6.3、lookingAt()方法
- 7、Matcher 类的替换方法
- 7.1、replaceAll()方法
- 7.2、replaceFirst()方法
- 8、使用正则表达式的其他情况
- 8.1、String类中的replaceAll()和replaceFirst()方法
- 8.2、String类中的matches()方法
- 8.3、String类中的split()方法
- 四、使用示例
一、概念
1、用途
正则表达式是一种用于匹配和操作文本的强大工具,它是由一系列字符和特殊字符组成的模式,用于描述要匹配的文本模式。
2、解释Matcher类中的group()方法
结论: 在Matcher类中有一个普通成员变量-数组groups,每一次执行matcher.find()方法,程序都会将匹配结果放到matcher对象的groups中,包括:全量正则表达式的匹配结果、正则表达式中第1个小括号的匹配结果……,但是仅仅会在不同位置中放置上述匹配结果对应字符串中的起始下标和结束下标(比真实下标大1),我们可以根据两个下标取出匹配结果字符串
我们来解释下groups数组中下标位置是如何放置的~
关于正则表达式可以匹配到的全量结果所对应文本字符串中的起始下标和结束下标会被分别放在groups数组下标0和1的位置。
关于正则表达式中第1个括号包含的结果,对应文本字符串中的起始下标和结束下标会被分别放在groups数组下标2和3的位置。
关于正则表达式中第2个括号包含的结果,对应文本字符串中的起始下标和结束下标会被分别放在groups数组下标4和5的位置。
以此类推
关于上面的解释,我通过代码来解释一下,先看示例代码:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "<img src='1.jpg' /><img src='2.jpg' /><img src='3.jpg' />";String regex = "<img src='(.+?)' />";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println("全量内容:" + matcher.group(0));System.out.println("括号1内容:" + matcher.group(1));System.out.println("——————————————————————————————");}}
}
我们来看一下结果:
全量内容:<img src='1.jpg' />
括号1内容:1.jpg
——————————————————————————————
全量内容:<img src='2.jpg' />
括号1内容:2.jpg
——————————————————————————————
全量内容:<img src='3.jpg' />
括号1内容:3.jpg
——————————————————————————————
现在具体分析一下,当进入matcher.group()方法之后,可以看到下图,其中紫色的groups就是Matcher对象中的普通成员数组变量,即:int[] groups;
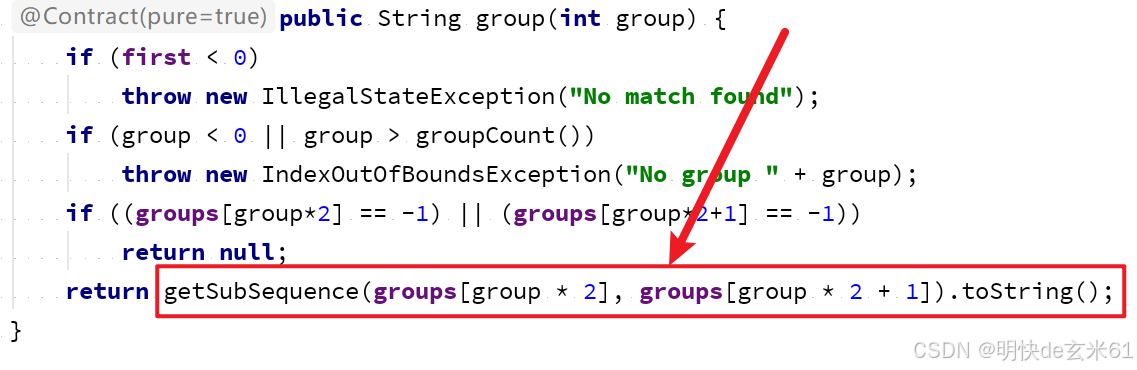
我们点击getSubSequence方法,可以看到下图,该方法可以根据2个下标查询“被匹配字符串”中的数据内容

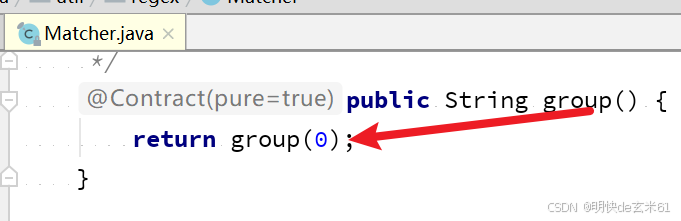
3、Matcher类中group()和group(0)方法的区别
两者是一样的,group()方法底层就是group(0)方法,如下图:
二、各种元字符
1、转义符
1.1、\
我之前整理过一些特殊字符,关于特殊字符的详细解释,大家可以看下这个文章,如果大家想在正则表达式中以字符串表示这些特殊符号,可以对它们进行转义
* . ? + ^ $ | \ / [ ] ( ) { }
注意: 在 java 中两个 \ 才代表一个转义符,然后讲解下需要对“特殊字符”进行转义的做法
- 普通情况:对于上面那些需要转义的字符,转义之后就代表普通的字符串了,具体写法是
\\需要转义的字符,例如:\\* - 特殊情况:如果我们想表示一个字符串
\,需要使用4个转义符才能表示一个正常的字符串\,即\\\\;其中前面两个\代表一个转义符,后面两个\代表一个转义符,使用前面转义符将后面的转义符进行转义,最终表示一个字符串\
2、定位符
2.1、^
含义: 匹配输入字符串的开始位置
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "hello world";String regex = "^hello world";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
hello world
2.2、$
含义: 匹配输入字符串的结束位置
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "hello world";String regex = "hello world$";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
hello world
3、限定符
3.1、*
含义: 匹配前面的子表达式零次或多次,等价于{0,}
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "z zo zoo";// 0次或者多次匹配字符oString regex = "zo*";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
z
zo
zoo
3.2、+
含义: 匹配前面的子表达式一次或多次,等价于 {1,}
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "z zo zoo";// 一次或者多次匹配字符oString regex = "zo+";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
zo
zoo
3.3、?
含义: 匹配前面的子表达式零次或一次,等价于 {0,1}
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "do does";String regex = "do(es)?";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
do
does
3.4、{n}
含义: 匹配前面的子表达式 n 次,其中 n 是一个非负整数
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "Bob food";String regex = "o{2}";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
oo
3.5、{n,}
含义: 至少匹配前面的子表达式 n 次,其中n 是一个非负整数
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "Bob foooood";// 'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'String regex = "o{2,}";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
ooooo
3.6、{n,m}
含义: 最少匹配前面的子表达式 n 次且最多匹配 m 次。其中 m 和 n 均为非负整数,其中 n <= m
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "Bob fooooood";String regex = "o{1,3}";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
o
ooo
ooo
3.7、?(非贪婪模式)
含义: 默认匹配模式都是贪婪匹配,目的是尽可能多的匹配所搜索的字符串。当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串。
拓展: (.+)默认是贪婪匹配,即最大匹配;(.+?)为惰性匹配,即最小匹配。
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "Bob foood";// 贪婪模式(默认模式)System.out.println("贪婪模式(默认模式)打印结果:");String regex1 = "o{1,3}";Pattern pattern1 = Pattern.compile(regex1);Matcher matcher1 = pattern1.matcher(str);while (matcher1.find()) {System.out.println(matcher1.group());}// 非贪婪模式System.out.println("\n非贪婪模式打印结果:");String regex2 = "o{1,3}?";Pattern pattern2 = Pattern.compile(regex2);Matcher matcher2 = pattern2.matcher(str);while (matcher2.find()) {System.out.println(matcher2.group());}}
}
结果:
贪婪模式(默认模式)打印结果:
o
ooo非贪婪模式打印结果:
o
o
o
o
4、范围字符
4.1、x|y
含义: 匹配 x 或 y,其中x或者y都可以是子表达式
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "zood food";String regex = "(z|f)ood";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
zood
food
4.2、[xyz]
含义: 字符集合。匹配所包含的任意一个字符。这里面有一点比较有趣,大部分特殊字符在里面都会当做普通字符,不具有转义含义(除转义符\、[、]之外,这些符号依然需要进行转义,其中转义符需要使用四个\,[和]分别使用\\[和\\]表示)
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "*\\[";// 代表字符*、.、\、[、]几个字符String regex = "[*.\\\\\\[\\]]";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
*
\
[
4.3、[^xyz]
含义: 字符匹配未包含的任意字符
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "1456";String regex = "[^123]";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
4
5
6
4.4、[a-z]
含义: 匹配指定范围内的任意字符,表示一个区间;比如a-z、A-Z、0-9等
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "China";String regex = "[a-z]";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
h
i
n
a
5、特殊字符
5.1、$
含义: 匹配输入字符串的结尾位置
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "Hi China";String regex = "China$";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
China
5.2、( )
含义: 括号中间可以写子表达式,括起来之后子表达式将会被当做一个整体,括号用来标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "boring tiring";String regex = "(bor|tir)ing";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
boring
tiring
5.3、*、+、?、\、^、|
- *:匹配前面的子表达式零次或多次
- +:匹配前面的子表达式一次或多次
- ?:匹配前面的子表达式零次或一次,或指明一个非贪婪限定符
- \:将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符
- ^:匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。
- {:标记限定符表达式的开始,比如:
{3}、{4,} - |:指明两项之间的一个选择
综上所述:上述几个特殊符号在转义符和限定符中都已经讲过了,这里不在赘述
5.4、.
含义: 匹配除换行符 \n 之外的任何单字符
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "hi\nhi";String regex = ".";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
h
i
h
i
5.5、[
含义: 标记一个中括号表达式的开始
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "hello";String regex = "[a-z]";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
h
e
l
l
o6、非打印字符
6.1、\b
含义: 匹配一个单词边界,也就是指单词和空格间的位置。
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "never verb";// 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'String regex = "er\\b";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
er
6.2、\B
含义: 匹配非单词边界
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "never verb";// 'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'String regex = "er\\B";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
er
6.3、\d
含义: 匹配一个数字字符,等价于 [0-9]
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "123hello";String regex = "\\d";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
1
2
3
6.4、\D
含义: 匹配一个非数字字符。等价于 [^0-9]
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "123hello";String regex = "\\D";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
h
e
l
l
o
6.5、\n
含义: 匹配一个换行符
6.6、\r
含义: 匹配一个回车符
6.7、\f
含义: 匹配一个换页符
6.8、\t
含义: 匹配一个制表符
6.9、\v
含义: 匹配一个垂直制表符
6.10、\s
含义: 匹配任何空白字符,包括空格( )、换页符(\f)、换行符(\n)、回车符(\r)制表符(\t)、垂直制表符(\v)。即等价于 [ \f\n\r\t\v]
6.11、\S
含义: 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]
6.12、\w
含义: 匹配字母、数字、下划线。等价于[A-Za-z0-9_]
6.13、\W
含义: 匹配非字母、数字、下划线,等价于 [^A-Za-z0-9_]
7、普通匹配、非获取匹配、零宽断言
7.1、普通匹配:(pattern)
含义: 匹配 pattern 并获取这一匹配
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "123456read123hello";String regex = "([1-9])([a-z])";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println("整体:" + matcher.group(0));System.out.println("第1个括号:" + matcher.group(1));System.out.println("第2个括号:" + matcher.group(2));}}
}
结果:
整体:6r
第1个括号:6
第2个括号:r
整体:3h
第1个括号:3
第2个括号:h
7.2、非获取匹配:(?:pattern)
含义: 匹配 pattern 但不获取匹配结果,也就是无法通过matcher.group(X)方法获取到括号里面的结果,但是在匹配的时候会消耗字符,下次在执行matcher.find()方法就不会再经过这些字符了;这点和零宽断言不太一样
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "industry~ industries~";String regex = "industr(?:y|ies)(.)";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group(0));// 这里会打印.匹配到的内容,而不会打印非捕获匹配的结果,也就是(?:y|ies)的内容不会打印,而(.)的会打印,但是(?:y|ies)也消耗了指针System.out.println(matcher.group(1));}}
}
结果:
industry~
~
industries~
~
7.3、零宽断言
7.3.1、概念
正则表达式中的零宽断言是一种特殊的结构,它在匹配的时候不会消耗字符,只是对匹配位置进行条件判断。这对于一些复杂的模式匹配非常有用,因为它允许你在匹配位置前面或后面添加条件,从而更精确地控制匹配。
正则表达式的先行断言和后行断言一共有 4 种形式:
- (?=pattern):零宽正向先行断言
- (?!pattern): 零宽负向先行断言
- (?<=pattern):零宽正向后行断言
- (?<!pattern):零宽负向后行断言
针对零宽、断言、正向、负向、先行、后行解释一下:
- 零宽(Zero-width): 只匹配位置,零宽意味着断言在匹配时不会"消耗"字符串,它只是对位置进行条件判断,不包括匹配位置之前或之后的字符在匹配结果中。
- 断言:用于查找在某些内容之前或之后的东西,比如零宽正向先行断言:使用reg(?=exp)表示,它断言自身出现的位置的后面能匹配表达式exp。类似于一种猜测~
- 正向(Positive): 匹配括号中的表达式,即只有当条件成立时,匹配才成功。
- 负向(Negative): 不匹配括号中的表达式,即只有当条件不成立时,匹配才成功。
- 先行(Lookahead): 引擎先于指针之前,尝试判断指针后面是否匹配该表达式。比如:re(?=gular),断言在gular前面肯定有
re - 后行(Lookbehind):引擎会尝试匹配指针已扫过的字符,扫描后于指针到达该字符。比如:(?<=\w)re,断言在\w之后会出现re
关于如何区分正向、负向、先行、后行,我们来分析一下:
正向、负向:
有 ! 号的形式表示不匹配,负向;将 ! 号换成 = 号,就表示匹配、正向。
正向就表示匹配括号中的表达式,负向表示不匹配。
先行、后行:
后行断言 (?<=pattern)、(?<!pattern) 中有一个小于号,把小于号去掉,就是先行断言。
正则表达式引擎在执行字符串和表达式匹配时,会从头到尾(从前到后)连续扫描字符串中的字符,设想有一个扫描指针指向字符边界处并随匹配过程移动。先行断言,是当扫描指针位于某处时,引擎会尝试匹配指针还未扫过的字符,先于指针到达该字符,故称为先行。后行断言,引擎会尝试匹配指针已扫过的字符,后于指针到达该字符,故称为后行。
7.3.2、正向先行断言:(?=pattern)
含义: 正向:匹配;先行:先于指针之前,尝试判断指针后面是否匹配该表达式
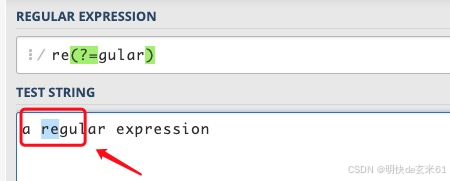
将表达式改为 re(?=gular).,将会匹配 reg,元字符 . 匹配了 g,括号这一砣匹配了 e 和 g 之间的位置。
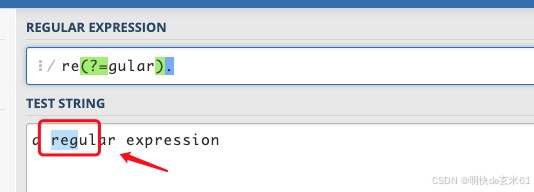
对比: 相比于非获取匹配:(?:pattern)来说,而正向先行断言:(?=pattern) 匹配时不会"消耗"字符串,也就是不让让指针后移,不消耗指针,位置还不变,只是先行判断了而已
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "a regular expression";// re后面是gular,但是该断言不会消耗指针,因此最后一个.对应regular种的字母gString regex = "re(?=gular).";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
reg
7.3.3、负向先行断言:(?!pattern)
含义: 负向:不匹配;先行:先于指针之前,尝试判断指针后面是否匹配该表达式
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "regex represents regular expression";String regex = "re(?!g)";// 该表达式限定了 re 右边的位置,这个位置后面不是字符 gPattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
re
re
re
7.3.4、正向后行断言:(?<=pattern)
含义: 代表字符串中的一个位置,紧接该位置之前的字符序列能够匹配 pattern
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "regex represents regular expression";// 在 re 前面应该是一个单词字符String regex = "(?<=\\w)re";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
re
re
7.3.5、负向后行断言:(?<!pattern)
含义: 代表字符串中的一个位置,紧接该位置之前的字符序列不能匹配 pattern
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "regex represents regular expression";// 在 re 前面不是单词字符String regex = "(?<!\\w)re";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
re
re
re
7.3.6、综合运用示例
示例:
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {// 作用:判断是否包含thatString str1 = "this is runoob test";String str2 = "that this is runoob test";String str3 = "hello thatthis is runoob test";String str4 = "this and that is runoob test";// 这四种做法均可String regex = "^(.(?<!that))*this(.(?<!that))*$";
// String regex = "^(.(?<!that))*this((?!that).)*$";
// String regex = "^((?!that).)*this(.(?<!that))*$";
// String regex = "^((?!that).)*this((?!that).)*$";Pattern pattern = Pattern.compile(regex);System.out.println(pattern.matcher(str1).matches());System.out.println(pattern.matcher(str2).matches());System.out.println(pattern.matcher(str3).matches());System.out.println(pattern.matcher(str4).matches());}
}
结果:
true
false
false
false
8、反向引用
8.1、内部引用
含义:
对一个正则表达式模式或部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。缓冲区编号从 1 开始,最多可存储 99 个捕获的子表达式。每个缓冲区都可以使用 \n 访问,其中 n 为一个标识特定缓冲区的一位或两位十进制数。
这种写法只能对应普通匹配,不对应非捕获匹配和零宽断言写法(在上面已经介绍过)
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {// 作用:查找文本中两个相同的相邻单词的匹配项String str = "Is is the cost of of gasoline going up up?";String regex = "\\b([a-z]+) \\1\\b";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);while (matcher.find()) {System.out.println(matcher.group());}}
}
结果:
of of
up up
8.2、外部引用
含义: 上面已经讲解了在正则表达式内部如何使用反向引用(写法:\n),下面说一下在正则表达式外部如何使用反向引用($n),其中n是正整数
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {// 作用:将重复的字符进行去重,只留下一个String str = "我我我要学学java";String regex = "(.)\\1+";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);// $1代表上面的\\1String content = matcher.replaceAll("$1");System.out.println(content);}
}
结果:
我要学java
三、常用方法
1、常用类
- Pattern 类:pattern 对象是一个正则表达式的编译表示。
- Matcher 类:Matcher 对象是对输入字符串进行解释和匹配操作的引擎。
- PatternSyntaxException类:非强制异常类,它表示一个正则表达式模式中的语法错误
2、Pattern的编译方法
2.1、接收一个参数
// 最常见的就是接收一个参数
Pattern pattern = Pattern.compile(regex);
2.2、接收两个参数
含义: 第1个参数依然是正则表达式字符串,第2个参数是一些补充功能(最常用的是忽略大小写配置),关于第2个参数的更多作用请看:java.util.Pattern的几种模式详细解析
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "A b C d";String regex1 = "[a-z]";// 默认情况下不忽略大小写Pattern pattern1 = Pattern.compile(regex1);Matcher matcher1 = pattern1.matcher(str);System.out.println("不忽略大小写:");while (matcher1.find()) {System.out.println(matcher1.group());}String regex2 = "[a-z]";// 配置第二个参数的值为“Pattern.CASE_INSENSITIVE”,用以忽略大小写Pattern pattern2 = Pattern.compile(regex2, Pattern.CASE_INSENSITIVE);Matcher matcher2 = pattern2.matcher(str);System.out.println("忽略大小写:");while (matcher2.find()) {System.out.println(matcher2.group());}}
}
结果:
不忽略大小写:
b
d
忽略大小写:
A
b
C
d
3、Pattern的整体匹配方法
含义: 判断正则表达式是否匹配字符串的全部内容,即整体匹配。并且使用该方法时正则表达式中不需要再前后添加^和$定位符,原因是默认就是整体匹配~
示例:
import java.util.regex.Pattern;public class Test {public static void main(String[] args) throws Exception {String str = "I am noob from runoob.com.";String regex = ".*runoob.*";System.out.println(Pattern.matches(regex, str));}
}
结果:
true
4、Pattern类、Matcher类的分组查找、取值方法
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) {// 按指定模式在字符串查找String line = "This order was placed for QT3000! OK?";String pattern = "(\\D*)(\\d+)(.*)";// 创建 Pattern 对象Pattern r = Pattern.compile(pattern);// 现在创建 matcher 对象Matcher m = r.matcher(line);if (m.find()) {// m.group()等同于m.group(0),可以看group()方法底层就是group(0)System.out.println("Found value: " + m.group(0));System.out.println("Found value: " + m.group(1));System.out.println("Found value: " + m.group(2));System.out.println("Found value: " + m.group(3));} else {System.out.println("NO MATCH");}}
}
示例:
Found value: This order was placed for QT3000! OK?
Found value: This order was placed for QT
Found value: 3000
Found value: ! OK?
5、Pattern 类的分割方法
含义: 按照正则表达式进行字符串分割
示例:
import java.util.regex.Pattern;public class Test {public static void main(String[] args) {String str = "hello world,hello china";String regex = " |,";Pattern pattern = Pattern.compile(regex);String[] arr = pattern.split(str);for (String s : arr) {System.out.println(s);}}
}
结果:
hello
world
hello
china
6、Matcher 类的查找方法
6.1、find()方法
含义: 找到一次匹配结果,便会返回true,之后我们就可以执行代码,然后使用while循环多次调用find()方法进行查找,直到查找完成(即find()方法返回false即可),该用法之前多次讲解,这里不在赘述
6.2、matches()方法
含义: 上面讲解的Pattern.matches()方法底层就是Matcher 类的matches()方法,作用都是执行整体匹配的,我们看下Pattern.matches()方法的源代码

6.3、lookingAt()方法
含义: 正则表达式是否与字符串的开头匹配,不要求完全匹配
示例:
import java.util.regex.Pattern;public class Test {public static void main(String[] args) {String str1 = "food";String str2 = "i love food";String regex = "foo";Pattern pattern = Pattern.compile(regex);System.out.printf("%s是否以%s开头:%s", str1, regex, pattern.matcher(str1).lookingAt());System.out.printf("\n%s是否以%s开头:%s", str2, regex, pattern.matcher(str2).lookingAt());}
}
结果:
food是否以foo开头:true
i love food是否以foo开头:false
7、Matcher 类的替换方法
7.1、replaceAll()方法
含义: 替换字符串中和正则表达式匹配的每个地方
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) {String str = "hello world, hello china";String regex = "hello";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);String result = matcher.replaceAll("hi");System.out.println(result);}
}
结果:
hi world, hi china
7.2、replaceFirst()方法
含义: 替换字符串中和正则表达式匹配的第1个地方
示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) {String str = "hello world, hello china";String regex = "hello";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(str);String result = matcher.replaceFirst("hi");System.out.println(result);}
}
结果:
hi world, hello china
8、使用正则表达式的其他情况
8.1、String类中的replaceAll()和replaceFirst()方法
含义: String类的replaceAll()和replaceFirst()方法中第1个参数可以使用正则表达式;其实这两个方法底层也是使用Pattern和Matcher类的方法

示例:
public class Test {public static void main(String[] args) {String str = "hello world, hello china";String regex = "hello";System.out.println(str.replaceAll(regex, "hi"));System.out.println(str.replaceFirst(regex, "hi"));}
}
结果:
hi world, hi china
hi world, hello china
8.2、String类中的matches()方法
含义: String类的matches()方法中的参数可以使用正则表达式;其实这个方法底层也是使用Pattern和Matcher类的方法

示例:
public class Test {public static void main(String[] args) {String str = "hello world";String regex = "hello.*";System.out.println(str.matches(regex));}
}
结果:
true
8.3、String类中的split()方法
含义: String类的split()方法中的参数可以使用正则表达式;其实这个方法底层也是使用Pattern和Matcher类的方法

示例:
public class Test {public static void main(String[] args) {String str = "hello world,hello china";String regex = " |,";for (String s : str.split(regex)) {System.out.println(s);}}
}
结果:
hello
world
hello
china
四、使用示例


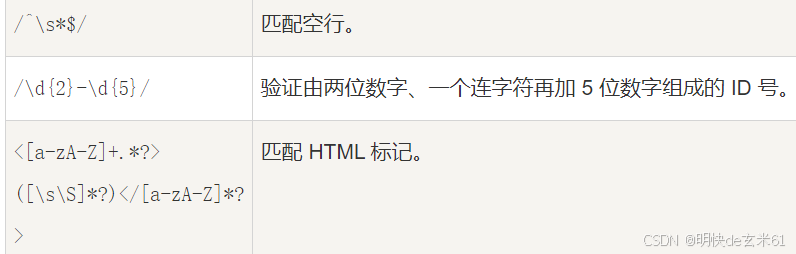
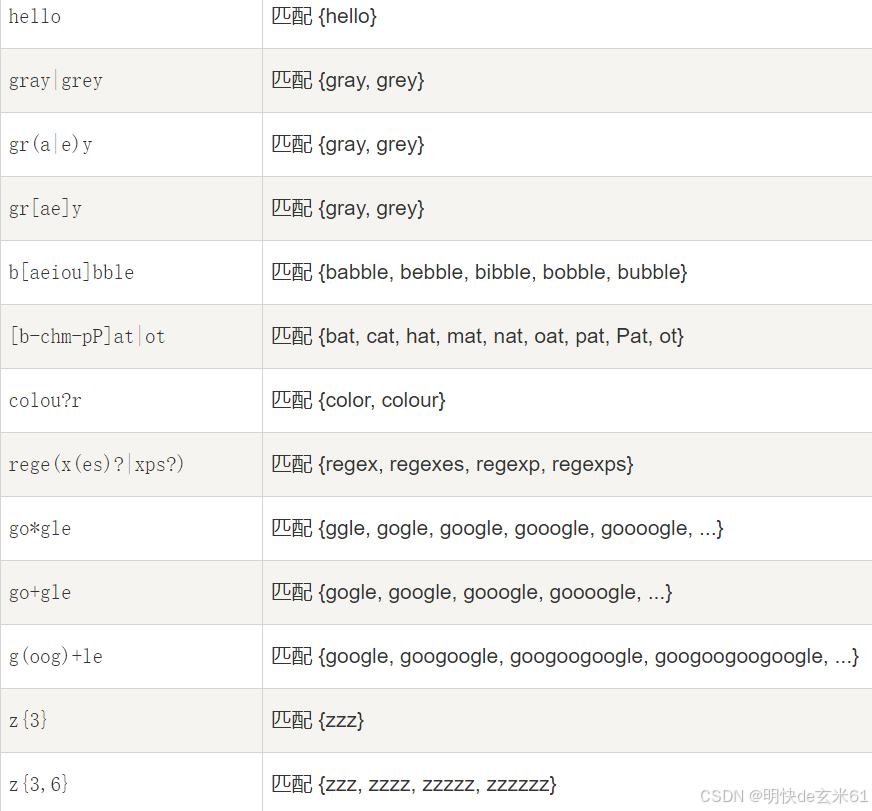

- 中文:
[\u4E00-\u9FA5] - 车牌号:
^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$ - 微信号:
^[a-zA-Z][-_a-zA-Z0-9]{5,19}$(微信号正则要求:6至20位,以字母开头,字母,数字,减号,下划线) - QQ号码:
^[1-9][0-9]{4,10}$(QQ号正则要求:5至11位) - 密码强度:
^.*(?=.{6,})(?=.*\d)(?=.*[A-Z])(?=.*[a-z])(?=.*[!@#$%^&*? ]).*$(密码强度正则要求:最少6位,包括至少1个大写字母,1个小写字母,1个数字,1个特殊字符) - 用户名:
^[a-zA-Z0-9_-]{4,16}$(用户名正则要求:4到16位(字母,数字,下划线,减号)) - 邮箱:
^(([^<>()[\]\\.,;:\s@\"]+(\.[^<>()[\]\\.,;:\s@\"]+)*)|(\".+\"))@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\])|(([a-zA-Z\-0-9]+\.)+[a-zA-Z]{2,}))$,也可以看UserConstants.java最后一个EMAIL_PATTERN值 - 手机号码:
^0{0,1}(13[0-9]|15[0-9]|14[0-9]|18[0-9])[0-9]{8}$ - 文件名称:
[a-zA-Z0-9_\-\|\.\u4e00-\u9fa5]+