HTTP部分详细讲解以及代码实现(二)
文章目录
- void process()的减负实现
- Web服务器中的有限 状态机
- HTTP有限状态机
- 从状态机
- 主状态机
- 主状态机三种状态,标识解析位置
- 总结
void process()的减负实现
//http_conn.cpp
void http_conn::process()
{HTTP_CODE read_ret = process_read();//NO_REQUEST,表示请求不完整,需要继续接收请求数据if (read_ret == NO_REQUEST){return;}bool write_ret = process_write(read_ret);if (!write_ret){return;}
}
可以看出,这里将process()的实现做了两个划分,我们将response改为write(因为回应的本质是向回写)然后并入process()中,使整个逻辑更加完整。
void的修饰不是强制的,你可以写成bool,int,或者自己宏定义,用于判断处理成功与否。
read和write分工操作其实是为了以后的线程池和epoll,这里按下不表。接下来,讲一下如何实现两个不同的功能
Web服务器中的有限 状态机
Web服务器中的有限状态机体现在两个方面:http和tcp
http有限状态机体现在业务逻辑处理
tcp有限状态机体现在对于连接情况的判断(代码层面不突出,本篇文章不涉及)
HTTP有限状态机
首先理解这个问题。HTTP协议并未提供头部字段的长度,判断头部结束依据是遇到一个空行,该空行只包含一对回车换行符。同时,如果一次读操作没有读入整个HTTP请求的头部,我们必须等待用户继续写数据再次读入(比如读到 GET /index.html HTT就结束了,必须维护这个状态,下一次必须继续读‘P’)。
即我们需要判定 当前解析的这一行是什么(请求行?请求头?消息体?),还需要判断解析一行是否结束!
首先根据上篇文章,HTTP报文解析需要的大致解析代码以及我们枚举出的情况,可以分为两个状态机(主状态机解决前半部分问题,从状态机解决后半部分问题)
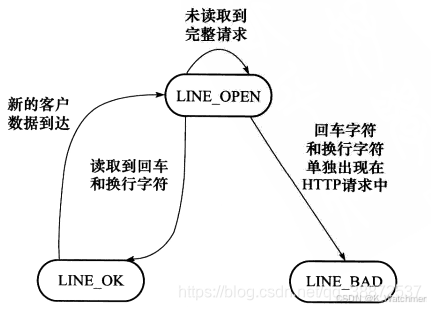
从状态机
从状态机负责读取报文的一行
在HTTP报文中,每一行的数据由\r\n作为结束字符,空行则是仅仅是字符\r\n。因此,可以通过查找\r\n将报文拆解成单独的行进行解析。从状态机负责读取buffer中的数据,将每行数据末尾的\r\n置为\0\0,并更新从状态机在buffer中读取的位置m_checked_idx,以此来驱动主状态机解析。
三种状态,标识解析一行的读取状态
LINE_OK,完整读取一行
LINE_BAD,报文语法有误
LINE_OPEN,读取的行不完整
如何理解从状态机
从状态机就是更加聚焦于一行行,着眼更加细致,他关心的是当前这一行读完整了/不完整/格式有误,亦即从状态机关注一行的解析状态。(那么显然这里可以想到其实每一个主状态机状态可能对应多轮的从状态改变,类似与包含关系),所以从状态机的函数会关注当前字符是什么,根据这个字符判断当前是读完了吗是格式错误吗等等。
流程如下:
1、从状态机从m_read_buf中逐字节读取,判断当前字节是否为\r
接下来的字符是\n,将\r\n修改成\0\0,将m_checked_idx指向下一行的开头,则返回LINE_OK
接下来达到了buffer末尾,表示buffer还需要继续接收,返回LINE_OPEN
否则,表示语法错误,返回LINE_BAD
2、当前字节不是\r,判断是否是\n (一般是上次读取到\r就到了buffer末尾,没有接收完整,再次接收时会出现这种情况)
如果前一个字符是\r,则将\r\n修改成\0\0,将m_checked_idx指向下一行的开头,则返回LINE_OK
3、当前字节既不是\r,也不是\n
表示接收不完整,需要继续接收,返回LINE_OPEN
从状态机实现代码
//返回值为行的读取状态,有LINE_OK,LINE_BAD,LINE_OPEN
http_conn::LINE_STATUS http_conn::parse_line()
{char temp;//m_read_idx指向缓冲区m_read_buf的数据末尾的下一个字节//m_checked_idx指向从状态机当前正在分析的字节for (; m_checked_idx < m_read_idx; ++m_checked_idx){//temp为将要分析的字节temp = m_read_buf[m_checked_idx];//如果当前是\r字符,则有可能会读取到完整行if (temp == '\r'){//下一个字符达到了buffer结尾,则接收不完整,需要继续接收if ((m_checked_idx + 1) == m_read_idx)return LINE_OPEN;//下一个字符是\n,将\r\n改为\0\0else if (m_read_buf[m_checked_idx + 1] == '\n'){m_read_buf[m_checked_idx++] = '\0';m_read_buf[m_checked_idx++] = '\0';return LINE_OK;}//如果都不符合,则返回语法错误return LINE_BAD;}//如果当前字符是\n,也有可能读取到完整行//一般是上次读取到\r就到buffer末尾了,没有接收完整,再次接收时会出现这种情况else if (temp == '\n'){//前一个字符是\r,则接收完整if (m_checked_idx > 1 && m_read_buf[m_checked_idx - 1] == '\r'){m_read_buf[m_checked_idx - 1] = '\0';m_read_buf[m_checked_idx++] = '\0';return LINE_OK;}return LINE_BAD;}}//并没有找到\r\n,需要继续接收return LINE_OPEN;
}
主状态机
主状态机负责对该行数据进行解析
主状态机初始状态是CHECK_STATE_REQUESTLINE,通过调用从状态机来驱动主状态机,在主状态机进行解析前,从状态机已经将每一行的末尾\r\n符号改为\0\0,以便于主状态机直接取出对应字符串进行处理。
//通过while循环 封装主状态机 对每一行进行循环处理
//此时 从状态机已经修改完毕 主状态机可以取出完整的行进行解析
http_conn::HTTP_CODE http_conn::process_read()
{//初始化从状态机的状态LINE_STATUS line_status = LINE_OK;HTTP_CODE ret = NO_REQUEST;char *text = 0;//判断条件,这里就是从状态机驱动主状态机while ((m_check_state == CHECK_STATE_CONTENT && line_status == LINE_OK) || ((line_status = parse_line()) == LINE_OK)){text = get_line();//m_start_line 是每一个数据行在m_read_buf中的起始位置//m_checked_idx 表示从状态机在m_read_buf中的读取位置m_start_line = m_checked_idx;LOG_INFO("%s", text);//三种状态转换逻辑switch (m_check_state){case CHECK_STATE_REQUESTLINE:{//解析请求行ret = parse_request_line(text);if (ret == BAD_REQUEST)return BAD_REQUEST;break;}case CHECK_STATE_HEADER:{//解析请求头ret = parse_headers(text);if (ret == BAD_REQUEST)return BAD_REQUEST;//作为get请求 则需要跳转到报文响应函数else if (ret == GET_REQUEST){return do_request();}break;}case CHECK_STATE_CONTENT:{//解析消息体ret = parse_content(text);//对于post请求 跳转到报文响应函数if (ret == GET_REQUEST)return do_request();//更新 跳出循环 代表解析完了消息体line_status = LINE_OPEN;break;}default:return INTERNAL_ERROR;}}return NO_REQUEST;
}
主状态机三种状态,标识解析位置
CHECK_STATE_REQUESTLINE ,解析请求行
主状态机的初始状态,调用parse_request_line函数解析请求行
解析函数从m_read_buf中解析HTTP请求行,获得请求方法、目标URL及HTTP版本号
解析完成后主状态机的状态变为CHECK_STATE_HEADER
//解析http请求行,获得请求方法,目标url及http版本号
http_conn::HTTP_CODE http_conn::parse_request_line(char *text)
{//请求行中最先含有空格和\t任一字符的位置并返回m_url = strpbrk(text, " \t");//没有目标字符 则代表报文格式有问题if (!m_url){return BAD_REQUEST;}//用于将前面的数据取出*m_url++ = '\0';//取出数据 确定请求方式char *method = text;if (strcasecmp(method, "GET") == 0)m_method = GET;else if (strcasecmp(method, "POST") == 0){m_method = POST;cgi = 1;}elsereturn BAD_REQUEST;//m_url此时跳过了第一个空格或者\t字符,但是后面还可能存在//不断后移找到请求资源的第一个字符m_url += strspn(m_url, " \t");//判断http的版本号m_version = strpbrk(m_url, " \t");if (!m_version)return BAD_REQUEST;*m_version++ = '\0';m_version += strspn(m_version, " \t");//目前社长项目仅支持http1.1if (strcasecmp(m_version, "HTTP/1.1") != 0)return BAD_REQUEST;//对请求资源的前七个字符进行判断//对某些带有http://的报文进行单独处理if (strncasecmp(m_url, "http://", 7) == 0){m_url += 7;m_url = strchr(m_url, '/');}//https的情况if (strncasecmp(m_url, "https://", 8) == 0){m_url += 8;m_url = strchr(m_url, '/');}//不符合规则的报文if (!m_url || m_url[0] != '/')return BAD_REQUEST;//当url为/时,显示欢迎界面if (strlen(m_url) == 1)strcat(m_url, "judge.html");//主状态机状态转移m_check_state = CHECK_STATE_HEADER;return NO_REQUEST;
}
CHECK_STATE_HEADER ,解析请求头
调用parse_headers函数解析请求头部信息
判断是空行还是请求头,若是空行,进而判断content-length是否为0,如果不是0,表明是POST请求,则状态转移到CHECK_STATE_CONTENT,否则说明是GET请求,则报文解析结束。
若解析的是请求头部字段,则主要分析connection字段,content-length字段,其他字段可以直接跳过,各位也可以根据需求继续分析。
connection字段判断是keep-alive还是close,决定是长连接还是短连接
content-length字段,这里用于读取post请求的消息体长度
//解析http请求的一个头部信息
http_conn::HTTP_CODE http_conn::parse_headers(char *text)
{//判断是空行还是请求头if (text[0] == '\0'){//具体判断是get还是post请求if (m_content_length != 0){//post请求需要改变主状态机的状态m_check_state = CHECK_STATE_CONTENT;return NO_REQUEST;}return GET_REQUEST;}//解析头部连接字段else if (strncasecmp(text, "Connection:", 11) == 0){text += 11;//跳过空格和\t字符text += strspn(text, " \t");if (strcasecmp(text, "keep-alive") == 0){//判断是否为长连接m_linger = true;}}//解析请求头 内容长度字段else if (strncasecmp(text, "Content-length:", 15) == 0){text += 15;text += strspn(text, " \t");m_content_length = atol(text);}//解析请求头部host字段else if (strncasecmp(text, "Host:", 5) == 0){text += 5;text += strspn(text, " \t");m_host = text;}else{LOG_INFO("oop!unknow header: %s", text);}return NO_REQUEST;
}
CHECK_STATE_CONTENT,解析消息体,仅用于解析POST请求
仅用于解析POST请求,调用parse_content函数解析消息体
用于保存post请求消息体,为后面的登录和注册做准备
//判断http请求是否被完整读入
http_conn::HTTP_CODE http_conn::parse_content(char *text)
{//判断是否读取了消息体if (m_read_idx >= (m_content_length + m_checked_idx)){text[m_content_length] = '\0';//POST请求中最后为输入的用户名和密码m_string = text;return GET_REQUEST;}return NO_REQUEST;
}
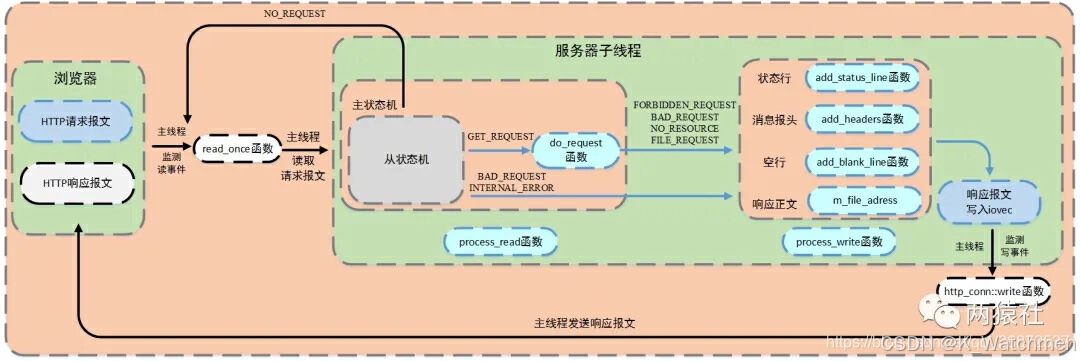
do_request() 具体处理函数
process_read返回值是对请求文件的分析结果,一部分是语法错误的BAD_REQUEST,一部分则是我们认可的规则然后作出的对应的响应。
do_request()的具体做法是将网站根目录和url文件拼接,然后通过stat判断文件属性。另外为了提高访问速度,通过mmap进行映射,将普通文件映射到内存逻辑地址
http_conn::HTTP_CODE http_conn::do_request()
{//将初始化的m_real_file赋值为网站根目录strcpy(m_real_file, doc_root);int len = strlen(doc_root);//printf("m_url:%s\n", m_url);//找到m_url中/的位置const char *p = strrchr(m_url, '/');//处理cgi//实现登录和注册校验if (cgi == 1 && (*(p + 1) == '2' || *(p + 1) == '3')){//根据标志判断是登录检测还是注册检测char flag = m_url[1];char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/");strcat(m_url_real, m_url + 2);strncpy(m_real_file + len, m_url_real, FILENAME_LEN - len - 1);free(m_url_real);//将用户名和密码提取出来//user=123&passwd=123char name[100], password[100];int i;for (i = 5; m_string[i] != '&'; ++i)name[i - 5] = m_string[i];name[i - 5] = '\0';int j = 0;for (i = i + 10; m_string[i] != '\0'; ++i, ++j)password[j] = m_string[i];password[j] = '\0';if (*(p + 1) == '3'){//如果是注册,先检测数据库中是否有重名的//没有重名的,进行增加数据char *sql_insert = (char *)malloc(sizeof(char) * 200);strcpy(sql_insert, "INSERT INTO user(username, passwd) VALUES(");strcat(sql_insert, "'");strcat(sql_insert, name);strcat(sql_insert, "', '");strcat(sql_insert, password);strcat(sql_insert, "')");if (users.find(name) == users.end()){m_lock.lock();int res = mysql_query(mysql, sql_insert);users.insert(pair<string, string>(name, password));m_lock.unlock();if (!res)strcpy(m_url, "/log.html");elsestrcpy(m_url, "/registerError.html");}elsestrcpy(m_url, "/registerError.html");}//如果是登录,直接判断//若浏览器端输入的用户名和密码在表中可以查找到,返回1,否则返回0else if (*(p + 1) == '2'){if (users.find(name) != users.end() && users[name] == password)strcpy(m_url, "/welcome.html");elsestrcpy(m_url, "/logError.html");}}//如果请求资源为/0,表示跳转注册界面if (*(p + 1) == '0'){char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/register.html");//将网站目录和/register.html进行拼接,更新到m_real_file中strncpy(m_real_file + len, m_url_real, strlen(m_url_real));free(m_url_real);}//如果请求资源为/1,表示跳转登录界面else if (*(p + 1) == '1'){char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/log.html");strncpy(m_real_file + len, m_url_real, strlen(m_url_real));free(m_url_real);}else if (*(p + 1) == '5'){char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/picture.html");//将网站目录和/log.html进行拼接,更新到m_real_file中strncpy(m_real_file + len, m_url_real, strlen(m_url_real));free(m_url_real);}else if (*(p + 1) == '6'){char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/video.html");strncpy(m_real_file + len, m_url_real, strlen(m_url_real));free(m_url_real);}else if (*(p + 1) == '7'){char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/fans.html");strncpy(m_real_file + len, m_url_real, strlen(m_url_real));free(m_url_real);}elsestrncpy(m_real_file + len, m_url, FILENAME_LEN - len - 1);if (stat(m_real_file, &m_file_stat) < 0)return NO_RESOURCE;if (!(m_file_stat.st_mode & S_IROTH))return FORBIDDEN_REQUEST;if (S_ISDIR(m_file_stat.st_mode))return BAD_REQUEST;int fd = open(m_real_file, O_RDONLY);m_file_address = (char *)mmap(0, m_file_stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0);close(fd);return FILE_REQUEST;
}
当前项目进度的.h头文件
总结
目前为止,我们仅仅是完成了http的部分功能,我们是暂且假设有这么个缓冲区m_read_buf让我们读。其实整个http的接收与分析部分已经完成,
目前没有涉及到 线程 io的概念
仅列出 我们需要实现什么功能 至于怎么实现,当对整个流程了解的时候,how to do的方式就是百花齐放
我得看法:这里面现在只有读取客户端的请求,解析请求,然后得到请求状态,