算法刷题笔记——动态规划篇
动态规划理论基础
动态规划,简称DP,如果某一问题有很多重叠子问题,使用动态规划是最有效的。
所以动态规划中每一个状态一定是由上一个状态推导出来的,这一点就区分于贪心,贪心没有状态推导,而是从局部直接选最优的,
动态规划的解题步骤
动态规划问题,拆解为如下五步曲,这五步都搞清楚了,才能说把动态规划真的掌握了
- 确定dp数组(dp table)以及下标的含义
- 确定递推公式
- dp数组如何初始化
- 确定遍历顺序
- 举例推导dp数组
一些情况是递推公式决定了dp数组要如何初始化
找问题的最好方式就是把dp数组打印出来,看看究竟是不是按照自己思路推导的
做动规的题目,写代码之前一定要把状态转移在dp数组的上具体情况模拟一遍,心中有数,确定最后推出的是想要的结果。
然后再写代码,如果代码没通过就打印dp数组,看看是不是和自己预先推导的哪里不一样。
如果打印出来和自己预先模拟推导是一样的,那么就是自己的递归公式、初始化或者遍历顺序有问题了。
如果和自己预先模拟推导的不一样,那么就是代码实现细节有问题。
这样才是一个完整的思考过程,而不是一旦代码出问题,就毫无头绪的东改改西改改,最后过不了,或者说是稀里糊涂的过了。
斐波那契数
这里我们要用一个一维dp数组来保存递归的结果
确定dp数组以及下标的含义
dp[i]的定义为:第i个数的斐波那契数值是dp[i]
确定递推公式
题目已经把递推公式直接给我们了:状态转移方程 dp[i] = dp[i - 1] + dp[i - 2];
dp数组如何初始化
题目中把如何初始化也直接给我们了,如下:
dp[0] = 0;
dp[1] = 1;
确定遍历顺序
从递归公式dp[i] = dp[i - 1] + dp[i - 2];中可以看出,dp[i]是依赖 dp[i - 1] 和 dp[i - 2],那么遍历的顺序一定是从前到后遍历的
举例推导dp数组
按照这个递推公式dp[i] = dp[i - 1] + dp[i - 2],我们来推导一下,当N为10的时候,dp数组应该是如下的数列:
0 1 1 2 3 5 8 13 21 34 55
如果代码写出来,发现结果不对,就把dp数组打印出来看看和我们推导的数列是不是一致的。
class Solution {
public:int fib(int n) {//dp[i]:第i个斐波那契的值为dp[i]//dp[i]=dp[i-1]+dp[i-2]//dp[0]=0,dp[1]=1//从前向后//0,1,1,2,3,5,8if(n<=1){return n;}vector<int> dp(n+1);dp[0]=0;dp[1]=1;for(int i=2;i<=n;i++){dp[i]=dp[i-1]+dp[i-2];}return dp[n];}
};
爬楼梯
爬到第一层楼梯有一种方法,爬到二层楼梯有两种方法。
那么第一层楼梯再跨两步就到第三层 ,第二层楼梯再跨一步就到第三层。
所以到第三层楼梯的状态可以由第二层楼梯 和 到第一层楼梯状态推导出来,那么就可以想到动态规划了。
题目中说了n是一个正整数,没说n有为0的情况。
所以本题不应该讨论dp[0]的初始化
class Solution {
public:
// - 确定dp数组(dp table)以及下标的含义 dp[i]达到第i阶有dp[i]种方法
// - 确定递推公式 dp[i]=dp[i-1]+dp[i-2]
// - dp数组如何初始化 dp[1]=1,dp[2]=2
// - 确定遍历顺序
// - 举例推导dp数组 1 1 3 5 7int climbStairs(int n) {if(n<=1){return n;}vector<int> dp(n+1);dp[1]=1;dp[2]=2;for(int i=3;i<=n;i++){dp[i]=dp[i-1]+dp[i-2];}return dp[n];}
};
使用最小花费爬楼梯
可以有两个途径得到dp[i],一个是dp[i-1] 一个是dp[i-2]。
dp[i - 1] 跳到 dp[i] 需要花费 dp[i - 1] + cost[i - 1]。
dp[i - 2] 跳到 dp[i] 需要花费 dp[i - 2] + cost[i - 2]。
那么究竟是选从dp[i - 1]跳还是从dp[i - 2]跳呢?
一定是选最小的,所以dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2]);
新题目描述中明确说了 “你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。” 也就是说 到达 第 0 个台阶是不花费的,但从 第0 个台阶 往上跳的话,需要花费 cost[0]。
所以初始化 dp[0] = 0,dp[1] = 0;
class Solution {
public:
//dp[i]:到达下标i的位置所需要的花费为dp[i]
//dp[i]=main(dp[i-1]+cost[i-1],dp[i-2]+cost[i-2])
// dp[0] = 0,dp[1] = 0;
//从前到后遍历cost数组int minCostClimbingStairs(vector<int>& cost) {vector<int> dp(cost.size()+1);dp[0]=0;dp[1]=0;for(int i=2;i<=cost.size();i++){dp[i]=min(dp[i-1]+cost[i-1],dp[i-2]+cost[i-2]);}return dp[cost.size()];}
};
不同路径
机器人从(0 , 0) 位置出发,到(m - 1, n - 1)终点。
按照动规五部曲来分析:
确定dp数组(dp table)以及下标的含义
dp[i][j] :表示从(0 ,0)出发,到(i, j) 有dp[i][j]条不同的路径。
确定递推公式
想要求dp[i][j],只能有两个方向来推导出来,即dp[i - 1][j] 和 dp[i][j - 1]。
此时在回顾一下 dp[i - 1][j] 表示啥,是从(0, 0)的位置到(i - 1, j)有几条路径,dp[i][j - 1]同理。
那么很自然,dp[i][j] = dp[i - 1][j] + dp[i][j - 1],因为dp[i][j]只有这两个方向过来。
dp数组的初始化
如何初始化呢,首先dp[i][0]一定都是1,因为从(0, 0)的位置到(i, 0)的路径只有一条,那么dp[0][j]也同理。
确定遍历顺序
这里要看一下递推公式dp[i][j] = dp[i - 1][j] + dp[i][j - 1],dp[i][j]都是从其上方和左方推导而来,那么从左到右一层一层遍历就可以了。
class Solution {
public://dp[i][j]:表示从(0,0)出发到(i,j),有dp[i][j]条不同的路径//dp[i][j]=dp[i-1][j]+dp[i][j-1]//dp[i][0]=1,dp[0][j]=1;//从左往右int uniquePaths(int m, int n) {vector<vector<int>> dp(m,vector(n,0));for(int i=0;i<m;i++){dp[i][0]=1;}for(int j=0;j<n;j++){dp[0][j]=1;}for(int i=1;i<m;i++){for(int j=1;j<n;j++){dp[i][j]=dp[i-1][j]+dp[i][j-1];}}return dp[m-1][n-1];}
};
不同路径 II
有障碍的话,其实就是标记对应的dp table(dp数组)保持初始值(0)就可以了。
确定dp数组(dp table)以及下标的含义
dp[i][j] :表示从(0 ,0)出发,到(i, j) 有dp[i][j]条不同的路径。
确定递推公式
递推公式和62.不同路径一样,dp[i][j] = dp[i - 1][j] + dp[i][j - 1]。
但这里需要注意一点,因为有了障碍,(i, j)如果就是障碍的话应该就保持初始状态(初始状态为0)。
初始化
如果(i, 0) 这条边有了障碍之后,障碍之后(包括障碍)都是走不到的位置了,所以障碍之后的dp[i][0]应该还是初始值0。
class Solution {
public:
//dp[i][j]:表示从(0,0)出发到(i,J)有dp[i][j]条不同的路径
//dp[i][j]=dp[i-1][j]+dp[i][j-1]
//如果(i, 0) 这条边有了障碍之后,障碍之后(包括障碍)都是走不到的位置了,所以障碍之后的dp[i][0]应该还是初始值0。int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {int m=obstacleGrid.size();int n=obstacleGrid[0].size();if(obstacleGrid[m-1][n-1]==1||obstacleGrid[0][0]==1){return 0;}vector<vector<int>> dp(m,vector<int>(n,0));for(int i=0;i<m&&obstacleGrid[i][0]==0;i++){dp[i][0]=1;}for(int j=0;j<n&&obstacleGrid[0][j]==0;j++){dp[0][j]=1;}for(int i=1;i<m;i++){for(int j=1;j<n;j++){if(obstacleGrid[i][j]==1){continue;}dp[i][j]=dp[i-1][j]+dp[i][j-1];}}return dp[m-1][n-1];}
};
整数拆分
确定dp数组(dp table)以及下标的含义
dp[i]:分拆数字i,可以得到的最大乘积为dp[i]。
确定递推公式
其实可以从1遍历j,然后有两种渠道得到dp[i].
一个是j * (i - j) 直接相乘。
一个是j * dp[i - j],相当于是拆分(i - j),对这个拆分不理解的话,可以回想dp数组的定义。
j怎么就不拆分呢?
j是从1开始遍历,拆分j的情况,在遍历j的过程中其实都计算过了。那么从1遍历j,比较(i - j) * j和dp[i - j] * j 取最大的。递推公式:dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
也可以这么理解,j * (i - j) 是单纯的把整数拆分为两个数相乘,而j * dp[i - j]是拆分成两个以及两个以上的个数相乘。
如果定义dp[i - j] * dp[j] 也是默认将一个数强制拆成4份以及4份以上了。
所以递推公式:dp[i] = max({dp[i], (i - j) * j, dp[i - j] * j});
那么在取最大值的时候,为什么还要比较dp[i]呢?
放入dp[i]是因为dp[i]最后的值应该时当i固定j循环时,每一整轮的最大值,而不是每次j变化的最大值
dp的初始化
严格从dp[i]的定义来说,dp[0] dp[1] 就不应该初始化,也就是没有意义的数值。
拆分0和拆分1的最大乘积是多少,这是无解的。
这里我只初始化dp[2] = 1,从dp[i]的定义来说,拆分数字2,得到的最大乘积是1,这个没有任何异议!
确定遍历顺序
确定遍历顺序,先来看看递归公式:dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
dp[i] 是依靠 dp[i - j]的状态,所以遍历i一定是从前向后遍历,先有dp[i - j]再有dp[i]。
枚举j的时候,是从1开始的。从0开始的话,那么让拆分一个数拆个0,求最大乘积就没有意义了。
j的结束条件是 j < i - 1 ,其实 j < i 也是可以的,不过可以节省一步,例如让j = i - 1,的话,其实在 j = 1的时候,这一步就已经拆出来了,重复计算,所以 j < i - 1
至于 i是从3开始,这样dp[i - j]就是dp[2]正好可以通过我们初始化的数值求出来。
class Solution {
public:
//dp[i]:拆分数字i,可以得到的最大乘积为dp[i]
//dp[i]=max(j*dp[i-j],j*(i-j))
//dp[2]=1
//从前往后int integerBreak(int n) {vector<int> dp(n+1);dp[2]=1;for(int i=3;i<=n;i++){for(int j=1;j<i-1;j++){dp[i]=max(dp[i],max(j*dp[i-j],j*(i-j)));}}return dp[n];}
};不同的二叉搜索树
dp[3],就是 元素1为头结点搜索树的数量 + 元素2为头结点搜索树的数量 + 元素3为头结点搜索树的数量
元素1为头结点搜索树的数量 = 右子树有2个元素的搜索树数量 * 左子树有0个元素的搜索树数量
元素2为头结点搜索树的数量 = 右子树有1个元素的搜索树数量 * 左子树有1个元素的搜索树数量
元素3为头结点搜索树的数量 = 右子树有0个元素的搜索树数量 * 左子树有2个元素的搜索树数量
确定dp数组(dp table)以及下标的含义
dp[i] : 1到i为节点组成的二叉搜索树的个数为dp[i]。
也可以理解是i个不同元素节点组成的二叉搜索树的个数为dp[i] ,都是一样的。
以下分析如果想不清楚,就来回想一下dp[i]的定义
确定递推公式
在上面的分析中,其实已经看出其递推关系, dp[i] += dp[以j为头结点左子树节点数量] * dp[以j为头结点右子树节点数量]
j相当于是头结点的元素,从1遍历到i为止。
所以递推公式:dp[i] += dp[j - 1] * dp[i - j]; ,j-1 为j为头结点左子树节点数量,i-j 为以j为头结点右子树节点数量
dp数组如何初始化
初始化,只需要初始化dp[0]就可以了,推导的基础,都是dp[0]。
那么dp[0]应该是多少呢?
从定义上来讲,空节点也是一棵二叉树,也是一棵二叉搜索树,这是可以说得通的。
从递归公式上来讲,dp[以j为头结点左子树节点数量] * dp[以j为头结点右子树节点数量] 中以j为头结点左子树节点数量为0,也需要dp[以j为头结点左子树节点数量] = 1, 否则乘法的结果就都变成0了。
所以初始化dp[0] = 1
确定遍历顺序
首先一定是遍历节点数,从递归公式:dp[i] += dp[j - 1] * dp[i - j]可以看出,节点数为i的状态是依靠 i之前节点数的状态。
那么遍历i里面每一个数作为头结点的状态,用j来遍历。
class Solution {
public://dp[i]:1到i为结点组成的二叉搜索树的个数为dp[i]// dp[i] += dp[以j为头结点左子树节点数量] * dp[以j为头结点右子树节点数量]//dp[i] += dp[j - 1] * dp[i - j]; ,j-1 为j为头结点左子树节点数量,i-j 为以j为头结点右子树节点数量//dp[0]=1//节点数为i的状态是依靠 i之前节点数的状态。那么遍历i里面每一个数作为头结点的状态,用j来遍历。int numTrees(int n) {vector<int> dp(n+1);dp[0]=1;for(int i=1;i<=n;i++){for(int j=1;j<=i;j++){dp[i]+=dp[j-1]*dp[i-j];}}return dp[n];}
};
01背包问题理论基础
有n件物品和一个最多能背重量为w 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。
每一件物品其实只有两个状态,取或者不取,所以可以使用回溯法搜索出所有的情况,那么时间复杂度就是 o ( 2 n ) o(2^n) o(2n),这里的n表示物品数量。
所以暴力的解法是指数级别的时间复杂度。进而才需要动态规划的解法来进行优化!
确定dp数组以及下标的含义
对于背包问题,有一种写法, 是使用二维数组,即dp[i][j] 表示从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。
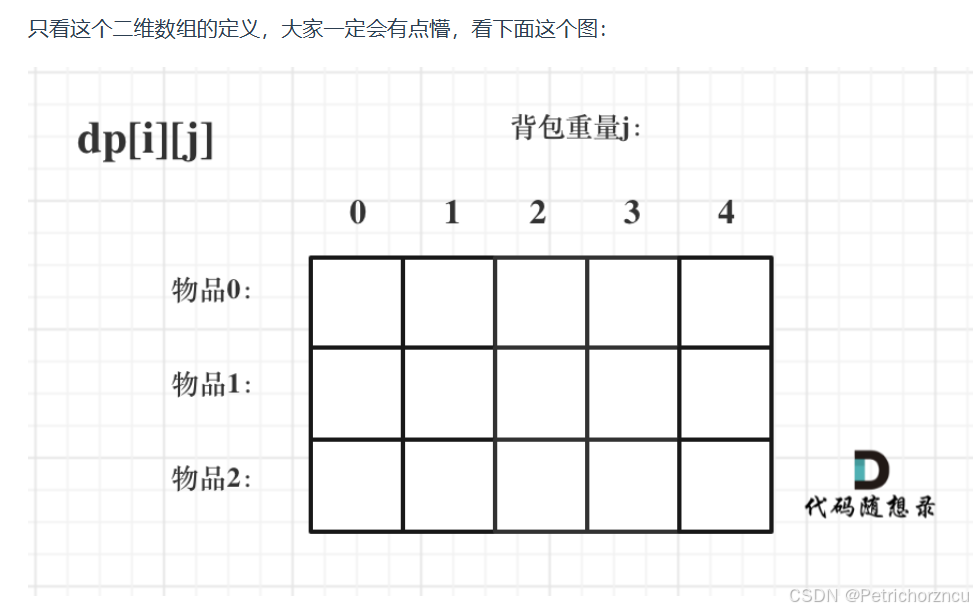
确定递推公式
再回顾一下dp[i][j]的含义:从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。
那么可以有两个方向推出来dp[i][j],
不放物品i:由dp[i - 1][j]推出,即背包容量为j,里面不放物品i的最大价值,此时dp[i][j]就是dp[i - 1][j]。(其实就是当物品i的重量大于背包j的重量时,物品i无法放进背包中,所以背包内的价值依然和前面相同。)
放物品i:由dp[i - 1][j - weight[i]]推出,dp[i - 1][j - weight[i]] 为背包容量为j - weight[i]的时候不放物品i的最大价值,那么dp[i - 1][j - weight[i]] + value[i] (物品i的价值),就是背包放物品i得到的最大价值
所以递归公式: dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
dp数组如何初始化
关于初始化,一定要和dp数组的定义吻合,否则到递推公式的时候就会越来越乱。
首先从dp[i][j]的定义出发,如果背包容量j为0的话,即dp[i][0],无论是选取哪些物品,背包价值总和一定为0。
状态转移方程 dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]); 可以看出i 是由 i-1 推导出来,那么i为0的时候就一定要初始化。
dp[0][j],即:i为0,存放编号0的物品的时候,各个容量的背包所能存放的最大价值。
那么很明显当 j < weight[0]的时候,dp[0][j] 应该是 0,因为背包容量比编号0的物品重量还小。
当j >= weight[0]时,dp[0][j] 应该是value[0],因为背包容量放足够放编号0物品。
确定遍历顺序
有两个遍历的维度:物品与背包重量
先遍历 物品还是先遍历背包重量呢?
其实都可以!! 但是先遍历物品更好理解。
//二维dp数组实现
#include <bits/stdc++.h>
using namespace std;int n, bagweight;// bagweight代表行李箱空间
void solve() {vector<int> weight(n, 0); // 存储每件物品所占空间vector<int> value(n, 0); // 存储每件物品价值for(int i = 0; i < n; ++i) {cin >> weight[i];}for(int j = 0; j < n; ++j) {cin >> value[j];}// dp数组, dp[i][j]代表行李箱空间为j的情况下,从下标为[0, i]的物品里面任意取,能达到的最大价值vector<vector<int>> dp(weight.size(), vector<int>(bagweight + 1, 0));// 初始化, 因为需要用到dp[i - 1]的值// j < weight[0]已在上方被初始化为0// j >= weight[0]的值就初始化为value[0]for (int j = weight[0]; j <= bagweight; j++) {dp[0][j] = value[0];}for(int i = 1; i < weight.size(); i++) { // 遍历科研物品for(int j = 0; j <= bagweight; j++) { // 遍历行李箱容量// 如果装不下这个物品,那么就继承dp[i - 1][j]的值if (j < weight[i]) dp[i][j] = dp[i - 1][j];// 如果能装下,就将值更新为 不装这个物品的最大值 和 装这个物品的最大值 中的 最大值// 装这个物品的最大值由容量为j - weight[i]的包任意放入序号为[0, i - 1]的最大值 + 该物品的价值构成else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);}}cout << dp[weight.size() - 1][bagweight] << endl;
}int main() {while(cin >> n >> bagweight) {solve();}return 0;
}
01背包理论基础(滚动数组)
对于背包问题其实状态都是可以压缩的。
在使用二维数组的时候,递推公式:dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
其实可以发现如果把dp[i - 1]那一层拷贝到dp[i]上,表达式完全可以是:dp[i][j] = max(dp[i][j], dp[i][j - weight[i]] + value[i]);
与其把dp[i - 1]这一层拷贝到dp[i]上,不如只用一个一维数组了,只用dp[j](一维数组,也可以理解是一个滚动数组)。
这就是滚动数组的由来,需要满足的条件是上一层可以重复利用,直接拷贝到当前层。
dp[i][j] 表示从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。
确定dp数组的定义
在一维dp数组中,dp[j]表示:容量为j的背包,所背的物品价值可以最大为dp[j]。
一维dp数组的递推公式
dp[j]为 容量为j的背包所背的最大价值,那么如何推导dp[j]呢?
dp[j]可以通过dp[j - weight[i]]推导出来,dp[j - weight[i]]表示容量为j - weight[i]的背包所背的最大价值。
dp[j - weight[i]] + value[i] 表示 容量为 j - 物品i重量 的背包 加上 物品i的价值。(也就是容量为j的背包,放入物品i了之后的价值即:dp[j])
此时dp[j]有两个选择,一个是取自己dp[j] 相当于 二维dp数组中的dp[i-1][j],即不放物品i,一个是取dp[j - weight[i]] + value[i],即放物品i,指定是取最大的,毕竟是求最大价值
所以递归公式为:
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
可以看出相对于二维dp数组的写法,就是把dp[i][j]中i的维度去掉了。
一维dp数组如何初始化
关于初始化,一定要和dp数组的定义吻合,否则到递推公式的时候就会越来越乱。
dp[j]表示:容量为j的背包,所背的物品价值可以最大为dp[j],那么dp[0]就应该是0,因为背包容量为0所背的物品的最大价值就是0。
那么dp数组除了下标0的位置,初始为0,其他下标应该初始化多少呢?
看一下递归公式:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
dp数组在推导的时候一定是取价值最大的数,如果题目给的价值都是正整数那么非0下标都初始化为0就可以了。
这样才能让dp数组在递归公式的过程中取的最大的价值,而不是被初始值覆盖了。
那么我假设物品价值都是大于0的,所以dp数组初始化的时候,都初始为0就可以了。
一维dp数组遍历顺序
和二维dp的写法中,遍历背包的顺序是不一样的!
二维dp遍历的时候,背包容量是从小到大,而一维dp遍历的时候,背包是从大到小。
为什么呢?
倒序遍历是为了保证物品i只被放入一次!。但如果一旦正序遍历了,那么物品0就会被重复加入多次!
举一个例子:物品0的重量weight[0] = 1,价值value[0] = 15
如果正序遍历
dp[1] = dp[1 - weight[0]] + value[0] = 15
dp[2] = dp[2 - weight[0]] + value[0] = 30
此时dp[2]就已经是30了,意味着物品0,被放入了两次,所以不能正序遍历。
为什么倒序遍历,就可以保证物品只放入一次呢?
倒序就是先算dp[2]
dp[2] = dp[2 - weight[0]] + value[0] = 15 (dp数组已经都初始化为0)
dp[1] = dp[1 - weight[0]] + value[0] = 15
所以从后往前循环,每次取得状态不会和之前取得状态重合,这样每种物品就只取一次了。
那么问题又来了,为什么二维dp数组遍历的时候不用倒序呢?
因为对于二维dp,dp[i][j]都是通过上一层即dp[i - 1][j]计算而来,本层的dp[i][j]并不会被覆盖!
(如何这里读不懂,大家就要动手试一试了,空想还是不靠谱的,实践出真知!)
再来看看两个嵌套for循环的顺序,代码中是先遍历物品嵌套遍历背包容量,那可不可以先遍历背包容量嵌套遍历物品呢?
不可以!
因为一维dp的写法,背包容量一定是要倒序遍历(原因上面已经讲了),如果遍历背包容量放在上一层,那么每个dp[j]就只会放入一个物品,即:背包里只放入了一个物品。
倒序遍历的原因是,本质上还是一个对二维数组的遍历,并且右下角的值依赖上一层左上角的值,因此需要保证左边的值仍然是上一层的,从右向左覆盖。
(这里如果读不懂,就再回想一下dp[j]的定义,或者就把两个for循环顺序颠倒一下试试!)
所以一维dp数组的背包在遍历顺序上和二维其实是有很
首先要明白二维数组的递推过程,然后才能看懂二维变一维的过程。
假设目前有背包容量为10,可以装的最大价值, 记为g(10)。
即将进来的物品重量为6。价值为9。
那么此时可以选择装该物品或者不装该物品。
如果不装该物品,显然背包容量无变化,这里对应二维数组,其实就是取该格子上方的格子复制下来,就是所说的滚动下来,直接g【10】 = g【10】,这两个g【10】要搞清楚,右边的g【10】是上一轮记录的,也就是对应二维数组里上一层的值,而左边是新的g【10】,也就是对应二维数组里下一层的值。
如果装该物品,则背包容量= g(10-6) = g(4) + 9 ,也就是 g(10) = g(4) + 6 ,这里的6显然就是新进来的物品的价值,g(10)就是新记录的,对应二维数组里下一层的值,而这里的g(4)是对应二维数组里上一层的值,通俗的来讲:你要找到上一层也就是上一状态下 背包容量为4时的能装的最大价值,用它来更新下一层的这一状态,也就是加入了价值为9的物品的新状态。
这时候如果是正序遍历会怎么样? g(10) = g(4) + 6 ,这个式子里的g(4)就不再是上一层的了,因为你是正序啊,g(4) 比g(10)提前更新,那么此时程序已经没法读取到上一层的g(4)了,新更新的下一层的g(4)覆盖掉了,这里也就是为啥有题解说一件物品被拿了两次的原因。
分割等和子集
这道题目是要找是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
那么只要找到集合里能够出现 sum / 2 的子集总和,就算是可以分割成两个相同元素和子集了。
只有确定了如下四点,才能把01背包问题套到本题上来。
- 背包的体积为sum / 2
- 背包要放入的商品(集合里的元素)重量为 元素的数值,价值也为元素的数值
- 背包如果正好装满,说明找到了总和为sum / 2 的子集。
- 背包中每一个元素是不可重复放入。
确定dp数组以及下标的含义
01背包中,dp[j] 表示: 容量为j的背包,所背的物品价值最大可以为dp[j]。
本题中每一个元素的数值既是重量,也是价值。
套到本题,dp[j]表示 背包总容量(所能装的总重量)是j,放进物品后,背的最大重量为dp[j]。
确定递推公式
01背包的递推公式为:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
本题,相当于背包里放入数值,那么物品i的重量是nums[i],其价值也是nums[i]。
所以递推公式:dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]);
dp数组如何初始化
在01背包,一维dp如何初始化,已经讲过,
从dp[j]的定义来看,首先dp[0]一定是0。
如果题目给的价值都是正整数那么非0下标都初始化为0就可以了,如果题目给的价值有负数,那么非0下标就要初始化为负无穷。
这样才能让dp数组在递推的过程中取得最大的价值,而不是被初始值覆盖了。
本题题目中 只包含正整数的非空数组,所以非0下标的元素初始化为0就可以了。
确定遍历顺序
如果使用一维dp数组,物品遍历的for循环放在外层,遍历背包的for循环放在内层,且内层for循环倒序遍历!
class Solution {
public:bool canPartition(vector<int>& nums) {int sum=0;vector<int> dp(10001,0);for(int i=0;i<nums.size();i++){sum+=nums[i];}if(sum%2==1){return false;}int target=sum/2;for(int i=0;i<nums.size();i++){for(int j=target;j>=nums[i];j--){dp[j]=max(dp[j],dp[j-nums[i]]+nums[i]);}}if(dp[target]==target){return true;}return false;}
};
最后一块石头的重量II
本题其实就是尽量让石头分成重量相同的两堆,相撞之后剩下的石头最小,这样就化解成01背包问题了。
本题物品的重量为stones[i],物品的价值也为stones[i]。
对应着01背包里的物品重量weight[i]和 物品价值value[i]。
确定dp数组以及下标的含义
dp[j]表示容量(这里说容量更形象,其实就是重量)为j的背包,最多可以背最大重量为dp[j]。
确定递推公式
01背包的递推公式为:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
本题则是:dp[j] = max(dp[j], dp[j - stones[i]] + stones[i]);
dp数组如何初始化
既然 dp[j]中的j表示容量,那么最大容量(重量)是多少呢,就是所有石头的重量和。
因为提示中给出1 <= stones.length <= 30,1 <= stones[i] <= 1000,所以最大重量就是30 * 1000 。
而我们要求的target其实只是最大重量的一半,所以dp数组开到15000大小就可以了。
确定遍历顺序
如果使用一维dp数组,物品遍历的for循环放在外层,遍历背包的for循环放在内层,且内层for循环倒序遍历!
class Solution {
public:int lastStoneWeightII(vector<int>& stones) {vector<int> dp(15001,0);int sum=0;for(int i=0;i<stones.size();i++){sum+=stones[i];}int target=sum/2;for(int i=0;i<stones.size();i++){for(int j=target;j>=stones[i];j--){dp[j]=max(dp[j],dp[j-stones[i]]+stones[i]);}}return sum-dp[target]-dp[target];}
};
在第一次写这个代码时我写的是int sum出错了,当我把他改成int sum=0时结果才正确
原因:sum 是一个局部变量,但如果你没有给它赋初值,它的初始值将是未定义的。这意味着 sum 可能包含任何随机值,取决于内存中该位置的内容。
目标和
假设加法的总和为x,那么减法对应的总和就是sum - x。
所以我们要求的是 x - (sum - x) = target
x = (target + sum) / 2
此时问题就转化为,装满容量为x的背包,有几种方法。
这里的x,就是bagSize,也就是我们后面要求的背包容量。
大家看到(target + sum) / 2 应该担心计算的过程中向下取整有没有影响。
确定dp数组以及下标的含义
dp[j] 表示:填满j(包括j)这么大容积的包,有dp[j]种方法
其实也可以使用二维dp数组来求解本题,dp[i][j]:使用 下标为[0, i]的nums[i]能够凑满j(包括j)这么大容量的包,有dp[i][j]种方法。
确定递推公式
有哪些来源可以推出dp[j]呢?
只要搞到nums[i],凑成dp[j]就有dp[j - nums[i]] 种方法。
例如:dp[j],j 为5,
已经有一个1(nums[i]) 的话,有 dp[4]种方法 凑成 容量为5的背包。
已经有一个2(nums[i]) 的话,有 dp[3]种方法 凑成 容量为5的背包。
已经有一个3(nums[i]) 的话,有 dp[2]种方法 凑成 容量为5的背包
已经有一个4(nums[i]) 的话,有 dp[1]种方法 凑成 容量为5的背包
已经有一个5 (nums[i])的话,有 dp[0]种方法 凑成 容量为5的背包
那么凑整dp[5]有多少方法呢,也就是把 所有的 dp[j - nums[i]] 累加起来。
dp[j]+=dp[j-nums[i]]
dp数组如何初始化
从递推公式可以看出,在初始化的时候dp[0] 一定要初始化为1,因为dp[0]是在公式中一切递推结果的起源,如果dp[0]是0的话,递推结果将都是0。
确定遍历顺序
对于01背包问题一维dp的遍历,nums放在外循环,target在内循环,且内循环倒序。
class Solution {
public:int findTargetSumWays(vector<int>& nums, int target) {int sum=0;for(int i=0;i<nums.size();i++){sum+=nums[i];}if(abs(target)>sum){return 0;}if((target+sum)%2==1){return 0;}int bagSize=(target+sum)/2;vector<int> dp(bagSize+1);dp[0]=1;for(int i=0;i<nums.size();i++){for(int j=bagSize;j>=nums[i];j--){dp[j]+=dp[j-nums[i]];}}return dp[bagSize];}
};
一和零
本题中strs 数组里的元素就是物品,每个物品都是一个!
而m 和 n相当于是一个背包,两个维度的背包。
理解成多重背包的同学主要是把m和n混淆为物品了,感觉这是不同数量的物品,所以以为是多重背包。
但本题其实是01背包问题!
只不过这个背包有两个维度,一个是m 一个是n,而不同长度的字符串就是不同大小的待装物品。
确定dp数组(dp table)以及下标的含义
dp[i][j]:最多有i个0和j个1的strs的最大子集的大小为dp[i][j]。
确定递推公式
dp[i][j] 可以由前一个strs里的字符串推导出来,strs里的字符串有zeroNum个0,oneNum个1。
dp[i][j] 就可以是 dp[i - zeroNum][j - oneNum] + 1。
然后我们在遍历的过程中,取dp[i][j]的最大值。
所以递推公式:dp[i][j] = max(dp[i][j], dp[i - zeroNum][j - oneNum] + 1);
此时大家可以回想一下01背包的递推公式:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
对比一下就会发现,字符串的zeroNum和oneNum相当于物品的重量(weight[i]),字符串本身的个数相当于物品的价值(value[i])。
这就是一个典型的01背包! 只不过物品的重量有了两个维度而已。
dp数组如何初始化
在动态规划:关于01背包问题,你该了解这些!(滚动数组) (opens new window)中已经讲解了,01背包的dp数组初始化为0就可以。
因为物品价值不会是负数,初始为0,保证递推的时候dp[i][j]不会被初始值覆盖。
确定遍历顺序
在动态规划:关于01背包问题,你该了解这些!(滚动数组) (opens new window)中,我们讲到了01背包为什么一定是外层for循环遍历物品,内层for循环遍历背包容量且从后向前遍历!
那么本题也是,物品就是strs里的字符串,背包容量就是题目描述中的m和n。
class Solution {
public:int findMaxForm(vector<string>& strs, int m, int n) {vector<vector<int>> dp(m+1,vector<int>(n+1,0));for(string str:strs){int oneNum=0,zeroNum=0;for(char c:str){if(c=='0'){zeroNum++;}else{oneNum++;}}for(int i=m;i>=zeroNum;i--){for(int j=n;j>=oneNum;j--){dp[i][j]=max(dp[i][j],dp[i-zeroNum][j-oneNum]+1);}}}return dp[m][n];}
};
动态规划:完全背包理论基础
完全背包和01背包问题唯一不同的地方就是,每种物品有无限件
01背包中二维dp数组的两个for遍历的先后循序是可以颠倒了,一维dp数组的两个for循环先后循序一定是先遍历物品,再遍历背包容量。
在完全背包中,对于一维dp数组来说,其实两个for循环嵌套顺序是无所谓的
因为dp[j] 是根据 下标j之前所对应的dp[j]计算出来的。 只要保证下标j之前的dp[j]都是经过计算的就可以了。
#include <iostream>
#include <vector>
using namespace std;//先遍历背包,再遍历物品
void test_CompletePack(vector<int> weight,vector<int> value,int bagWeight){vector<int> dp(bagWeight+1,0);for(int j=0;j<=bagWeight;j++){for(int i=0;i<weight.size();i++){if(j-weight[i]>=0){dp[j]=max(dp[j],dp[j-weight[i]]+value[i]);}}}std::cout << dp[bagWeight] << std::endl;
}
int main(){int N,V;cin>>N>>V;vector<int> weight;vector<int> value;for(int i=0;i<N;i++){int w;int v;cin>>w>>v;weight.push_back(w);value.push_back(v);}test_CompletePack(weight,value,V);return 0;
}
零钱兑换II
但本题和纯完全背包不一样,纯完全背包是凑成背包最大价值是多少,而本题是要求凑成总金额的物品组合个数!
组合不强调元素之间的顺序,排列强调元素之间的顺序。
确定dp数组以及下标的含义
dp[j]:凑成总金额j的货币组合数为dp[j]
确定递推公式
dp[j] 就是所有的dp[j - coins[i]](考虑coins[i]的情况)相加。
所以递推公式:dp[j] += dp[j - coins[i]];
求装满背包有几种方法,公式都是:dp[j] += dp[j - nums[i]];
dp数组如何初始化
首先dp[0]一定要为1,dp[0] = 1是 递归公式的基础。如果dp[0] = 0 的话,后面所有推导出来的值都是0了。
遍历顺序
本题要求凑成总和的组合数,元素之间明确要求没有顺序。
所以纯完全背包是能凑成总和就行,不用管怎么凑的。
本题是求凑出来的方案个数,且每个方案个数是为组合数。
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
class Solution {
public:int change(int amount, vector<int>& coins) {vector<int> dp(amount+1,0);dp[0]=1;for(int i=0;i<coins.size();i++){for(int j=coins[i];j<=amount;j++){dp[j]+=dp[j-coins[i]];}}return dp[amount];}
};
组合总和 Ⅳ
本题题目描述说是求组合,但又说是可以元素相同顺序不同的组合算两个组合,其实就是求排列!
弄清什么是组合,什么是排列很重要。
组合不强调顺序,(1,5)和(5,1)是同一个组合。
排列强调顺序,(1,5)和(5,1)是两个不同的排列。
确定dp数组以及下标的含义
dp[i]: 凑成目标正整数为i的排列个数为dp[i]
确定递推公式
dp[i](考虑nums[j])可以由 dp[i - nums[j]](不考虑nums[j]) 推导出来。
因为只要得到nums[j],排列个数dp[i - nums[j]],就是dp[i]的一部分。
求装满背包有几种方法,递推公式一般都是dp[i] += dp[i - nums[j]];
dp数组如何初始化
因为递推公式dp[i] += dp[i - nums[j]]的缘故,dp[0]要初始化为1,这样递归其他dp[i]的时候才会有数值基础。
至于dp[0] = 1 有没有意义呢?
其实没有意义,所以我也不去强行解释它的意义了,因为题目中也说了:给定目标值是正整数! 所以dp[0] = 1是没有意义的,仅仅是为了推导递推公式。
至于非0下标的dp[i]应该初始为多少呢?
初始化为0,这样才不会影响dp[i]累加所有的dp[i - nums[j]]。
确定遍历顺序
个数可以不限使用,说明这是一个完全背包。
得到的集合是排列,说明需要考虑元素之间的顺序。
本题要求的是排列,那么这个for循环嵌套的顺序可以有说法了。
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
所以本题遍历顺序最终遍历顺序:target(背包)放在外循环,将nums(物品)放在内循环,内循环从前到后遍历。
class Solution {
public:
//dp[i]:凑成目标正整数为i的排列个数为dp[i]
//dp[i]+=dp[i-nums[i]]int combinationSum4(vector<int>& nums, int target) {vector<int> dp(target+1,0);dp[0]=1;for(int j=0;j<=target;j++){for(int i=0;i<nums.size();i++){if(j-nums[i]>=0&&dp[j]<INT_MAX-dp[j-nums[i]]){dp[j]+=dp[j-nums[i]];}}}return dp[target];}
};
爬楼梯
1阶,2阶,… m阶就是物品,楼顶就是背包。
每一阶可以重复使用,例如跳了1阶,还可以继续跳1阶。
问跳到楼顶有几种方法其实就是问装满背包有几种方法。
确定dp数组以及下标的含义
dp[i]:爬到有i个台阶的楼顶,有dp[i]种方法。
确定递推公式
在动态规划:494.目标和 (opens new window)、 动态规划:518.零钱兑换II (opens new window)、动态规划:377. 组合总和 Ⅳ (opens new window)中我们都讲过了,求装满背包有几种方法,递推公式一般都是dp[i] += dp[i - nums[j]];
本题呢,dp[i]有几种来源,dp[i - 1],dp[i - 2],dp[i - 3] 等等,即:dp[i - j]
那么递推公式为:dp[i] += dp[i - j]
dp数组如何初始化
既然递归公式是 dp[i] += dp[i - j],那么dp[0] 一定为1,dp[0]是递归中一切数值的基础所在,如果dp[0]是0的话,其他数值都是0了。
下标非0的dp[i]初始化为0,因为dp[i]是靠dp[i-j]累计上来的,dp[i]本身为0这样才不会影响结果
确定遍历顺序
这是背包里求排列问题,即:1、2 步 和 2、1 步都是上三个台阶,但是这两种方法不一样!
所以需将target放在外循环,将nums放在内循环。
每一步可以走多次,这是完全背包,内循环需要从前向后遍历。
dp[i]:爬完i级楼梯有dp[i]种方法
dp[i]+=dp[i-j]
#include<iostream>
#include<vector>
using namespace std;
int main(){int n,m;while(cin>>n>>m){vector<int> dp(n+1,0);dp[0]=1;for(int j=1;j<=n;j++){for(int i=1;i<=m;i++){if((j-i)>=0){dp[j]+=dp[j-i];}}}cout << dp[n] << endl;}}
零钱兑换
确定dp数组以及下标的含义
dp[j]:凑足总额为j所需钱币的最少个数为dp[j]
确定递推公式
凑足总额为j - coins[i]的最少个数为dp[j - coins[i]],那么只需要加上一个钱币coins[i]即dp[j - coins[i]] + 1就是dp[j](考虑coins[i])
所以dp[j] 要取所有 dp[j - coins[i]] + 1 中最小的。
递推公式:dp[j] = min(dp[j - coins[i]] + 1, dp[j]);
dp数组如何初始化
首先凑足总金额为0所需钱币的个数一定是0,那么dp[0] = 0;
其他下标对应的数值呢?
考虑到递推公式的特性,dp[j]必须初始化为一个最大的数,否则就会在min(dp[j - coins[i]] + 1, dp[j])比较的过程中被初始值覆盖。
确定遍历顺序
本题求钱币最小个数,那么钱币有顺序和没有顺序都可以,都不影响钱币的最小个数。
所以本题并不强调集合是组合还是排列。
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
所以本题的两个for循环的关系是:外层for循环遍历物品,内层for遍历背包或者外层for遍历背包,内层for循环遍历物品都是可以的!
那么我采用coins放在外循环,target在内循环的方式。
本题钱币数量可以无限使用,那么是完全背包。所以遍历的内循环是正序
综上所述,遍历顺序为:coins(物品)放在外循环,target(背包)在内循环。且内循环正序。
class Solution {
public:int coinChange(vector<int>& coins, int amount) {vector<int> dp(amount + 1, INT_MAX);dp[0] = 0;for (int i = 0; i < coins.size(); i++) {for (int j = coins[i]; j <= amount; j++) {if (dp[j - coins[i]] != INT_MAX) {dp[j] = min(dp[j - coins[i]] + 1, dp[j]);}}}if (dp[amount] == INT_MAX) {return -1;}return dp[amount];}
};
完全平方数
完全平方数就是物品(可以无限件使用),凑个正整数n就是背包,问凑满这个背包最少有多少物品?
确定dp数组(dp table)以及下标的含义
dp[j]:和为j的完全平方数的最少数量为dp[j]
确定递推公式
dp[j] 可以由dp[j - i * i]推出, dp[j - i * i] + 1 便可以凑成dp[j]。
此时我们要选择最小的dp[j],所以递推公式:dp[j] = min(dp[j - i * i] + 1, dp[j]);
dp数组如何初始化
dp[0]表示 和为0的完全平方数的最小数量,那么dp[0]一定是0。
从递归公式dp[j] = min(dp[j - i * i] + 1, dp[j]);中可以看出每次dp[j]都要选最小的,所以非0下标的dp[j]一定要初始为最大值,这样dp[j]在递推的时候才不会被初始值覆盖。
确定遍历顺序
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
所以本题外层for遍历背包,内层for遍历物品,还是外层for遍历物品,内层for遍历背包,都是可以的!
class Solution {
public:
//dp[n]:装满容量为n的物品所需要的最少数量为dp[n]
//dp[j]=min(dp[j-i*i],dp[j]);int numSquares(int n) {vector<int> dp(n+1,INT_MAX);dp[0]=0;for(int i=1;i*i<=n;i++){for(int j=i*i;j<=n;j++){dp[j]=min(dp[j-i*i]+1,dp[j]);}}return dp[n];}
};
单词拆分
确定dp数组以及下标的含义
dp[i] : 字符串长度为i的话,dp[i]为true,表示可以拆分为一个或多个在字典中出现的单词。
确定递推公式
如果确定dp[j] 是true,且 [j, i] 这个区间的子串出现在字典里,那么dp[i]一定是true。(j < i )。
所以递推公式是 if([j, i] 这个区间的子串出现在字典里 && dp[j]是true) 那么 dp[i] = true。
dp数组如何初始化
从递推公式中可以看出,dp[i] 的状态依靠 dp[j]是否为true,那么dp[0]就是递推的根基,dp[0]一定要为true,否则递推下去后面都都是false了。
确定遍历顺序
题目中说是拆分为一个或多个在字典中出现的单词,所以这是完全背包。
求排列数就是外层for遍历背包,内层for循环遍历物品。
class Solution {
public:bool wordBreak(string s, vector<string>& wordDict) {unordered_set<string> wordSet(wordDict.begin(),wordDict.end());vector<bool> dp(s.size()+1,false);dp[0]=true;for(int j=1;j<=s.size();j++){for(int i=0;i<j;i++){string word=s.substr(i,j-i);if(wordSet.find(word)!=wordSet.end()&&dp[i]){dp[j]=true;}}}return dp[s.size()];}
};
多重背包
有N种物品和一个容量为V 的背包。第i种物品最多有Mi件可用,每件耗费的空间是Ci ,价值是Wi 。求解将哪些物品装入背包可使这些物品的耗费的空间 总和不超过背包容量,且价值总和最大。
多重背包和01背包是非常像的, 为什么和01背包像呢?
每件物品最多有Mi件可用,把Mi件摊开,其实就是一个01背包问题了。
01背包里面在加一个for循环遍历一个每种商品的数量。 和01背包还是如出一辙的。
打家劫舍
当前房屋偷与不偷取决于 前一个房屋和前两个房屋是否被偷了。
所以这里就更感觉到,当前状态和前面状态会有一种依赖关系,那么这种依赖关系都是动规的递推公式。
确定dp数组(dp table)以及下标的含义
dp[i]:考虑下标i(包括i)以内的房屋,最多可以偷窃的金额为dp[i]。
确定递推公式
决定dp[i]的因素就是第i房间偷还是不偷。
如果偷第i房间,那么dp[i] = dp[i - 2] + nums[i] ,即:第i-1房一定是不考虑的,找出 下标i-2(包括i-2)以内的房屋,最多可以偷窃的金额为dp[i-2] 加上第i房间偷到的钱。
如果不偷第i房间,那么dp[i] = dp[i - 1],即考 虑i-1房,(注意这里是考虑,并不是一定要偷i-1房,这是很多同学容易混淆的点)
然后dp[i]取最大值,即dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
dp数组如何初始化
从递推公式dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);可以看出,递推公式的基础就是dp[0] 和 dp[1]
从dp[i]的定义上来讲,dp[0] 一定是 nums[0],dp[1]就是nums[0]和nums[1]的最大值即:dp[1] = max(nums[0], nums[1]);
确定遍历顺序
dp[i] 是根据dp[i - 2] 和 dp[i - 1] 推导出来的,那么一定是从前到后遍历!
class Solution {
public:
//dp[i]:考虑下标i(包括i)以内的房屋,最多可以偷窃的金额为dp[i]。int rob(vector<int>& nums) {if(nums.size()==0){return 0;}if(nums.size()==1){return nums[0];}vector<int> dp(nums.size());dp[0]=nums[0];dp[1]=max(nums[0],nums[1]);for(int i=2;i<nums.size();i++){dp[i]=max(dp[i-2]+nums[i],dp[i-1]);}return dp[nums.size()-1];}
};
打家劫舍II
这道题目和198.打家劫舍 (opens new window)是差不多的,唯一区别就是成环了。
对于一个数组,成环的话主要有如下三种情况:
情况一:考虑不包含首尾元素
情况二:考虑包含首元素,不包含尾元素
情况三:考虑包含尾元素,不包含首元素
注意我这里用的是"考虑",例如情况三,虽然是考虑包含尾元素,但不一定要选尾部元素! 对于情况三,取nums[1] 和 nums[3]就是最大的。
而情况二 和 情况三 都包含了情况一了,所以只考虑情况二和情况三就可以了。
class Solution {
public:int rob(vector<int>& nums) {if(nums.size()==0){return 0;}if(nums.size()==1){return nums[0];}int result1=robrange(nums,0,nums.size()-2);int result2=robrange(nums,1,nums.size()-1);return max(result1,result2);}int robrange(vector<int>& nums,int start,int end){if(start==end){return nums[start];}vector<int> dp(nums.size());dp[start]=nums[start];dp[start+1]=max(nums[start],nums[start+1]);for(int i=start+2;i<=end;i++){dp[i]=max(dp[i-2]+nums[i],dp[i-1]);}return dp[end];}
};
打家劫舍 III
对于树的话,首先就要想到遍历方式,前中后序(深度优先搜索)还是层序遍历(广度优先搜索)。
本题一定是要后序遍历,因为通过递归函数的返回值来做下一步计算。
与198.打家劫舍,213.打家劫舍II一样,关键是要讨论当前节点抢还是不抢。
如果抢了当前节点,两个孩子就不能动,如果没抢当前节点,就可以考虑抢左右孩子(注意这里说的是“考虑”)
动态规划其实就是使用状态转移容器来记录状态的变化,这里可以使用一个长度为2的数组,记录当前节点偷与不偷所得到的的最大金钱。
这道题目算是树形dp的入门题目,因为是在树上进行状态转移,我们在讲解二叉树的时候说过递归三部曲,那么下面我以递归三部曲为框架,其中融合动规五部曲的内容来进行讲解。
确定递归函数的参数和返回值
这里我们要求一个节点 偷与不偷的两个状态所得到的金钱,那么返回值就是一个长度为2的数组。
所以dp数组(dp table)以及下标的含义:下标为0记录不偷该节点所得到的的最大金钱,下标为1记录偷该节点所得到的的最大金钱。
所以本题dp数组就是一个长度为2的数组!
那么有同学可能疑惑,长度为2的数组怎么标记树中每个节点的状态呢?
别忘了在递归的过程中,系统栈会保存每一层递归的参数。
确定终止条件
在遍历的过程中,如果遇到空节点的话,很明显,无论偷还是不偷都是0,所以就返回
确定遍历顺序
首先明确的是使用后序遍历。 因为要通过递归函数的返回值来做下一步计算。
通过递归左节点,得到左节点偷与不偷的金钱。
通过递归右节点,得到右节点偷与不偷的金钱。
确定单层递归的逻辑
如果是偷当前节点,那么左右孩子就不能偷,val1 = cur->val + left[0] + right[0]; (如果对下标含义不理解就再回顾一下dp数组的含义)
如果不偷当前节点,那么左右孩子就可以偷,至于到底偷不偷一定是选一个最大的,所以:val2 = max(left[0], left[1]) + max(right[0], right[1]);
最后当前节点的状态就是{val2, val1}; 即:{不偷当前节点得到的最大金钱,偷当前节点得到的最大金钱}
class Solution {
public:int rob(TreeNode* root) {vector<int> result=robTree(root);return max(result[0],result[1]);}// 长度为2的数组,0:不偷,1:偷vector<int> robTree(TreeNode* cur){if(cur==nullptr){return vector<int>{0,0};}vector<int> left=robTree(cur->left);vector<int> right=robTree(cur->right);// 偷cur,那么就不能偷左右节点。int val1=cur->val+left[0]+right[0];// 不偷cur,那么可以偷也可以不偷左右节点,则取较大的情况int val2=max(left[0],left[1])+max(right[0],right[1]);return{val2,val1};}
};
买卖股票的最佳时机
确定dp数组(dp table)以及下标的含义
dp[i][0] 表示第i天持有股票所得最多现金 ,这里可能有同学疑惑,本题中只能买卖一次,持有股票之后哪还有现金呢?
其实一开始现金是0,那么加入第i天买入股票现金就是 -prices[i], 这是一个负数。
dp[i][1] 表示第i天不持有股票所得最多现金
注意这里说的是“持有”,“持有”不代表就是当天“买入”!也有可能是昨天就买入了,今天保持持有的状态
确定递推公式
如果第i天持有股票即dp[i][0], 那么可以由两个状态推出来
第i-1天就持有股票,那么就保持现状,所得现金就是昨天持有股票的所得现金 即:dp[i - 1][0]
第i天买入股票,所得现金就是买入今天的股票后所得现金即:-prices[i]
那么dp[i][0]应该选所得现金最大的,所以dp[i][0] = max(dp[i - 1][0], -prices[i]);
如果第i天不持有股票即dp[i][1], 也可以由两个状态推出来
第i-1天就不持有股票,那么就保持现状,所得现金就是昨天不持有股票的所得现金 即:dp[i - 1][1]
第i天卖出股票,所得现金就是按照今天股票价格卖出后所得现金即:prices[i] + dp[i - 1][0]
同样dp[i][1]取最大的,dp[i][1] = max(dp[i - 1][1], prices[i] + dp[i - 1][0]);
dp数组如何初始化
由递推公式 dp[i][0] = max(dp[i - 1][0], -prices[i]); 和 dp[i][1] = max(dp[i - 1][1], prices[i] + dp[i - 1][0]);可以看出
其基础都是要从dp[0][0]和dp[0][1]推导出来。
那么dp[0][0]表示第0天持有股票,此时的持有股票就一定是买入股票了,因为不可能有前一天推出来,所以dp[0][0] -= prices[0];
dp[0][1]表示第0天不持有股票,不持有股票那么现金就是0,所以dp[0][1] = 0;
确定遍历顺序
从递推公式可以看出dp[i]都是由dp[i - 1]推导出来的,那么一定是从前向后遍历。
class Solution {
public:int maxProfit(vector<int>& prices) {int length=prices.size();if(length==0){return 0;}vector<vector<int>> dp(length,vector<int>(2));dp[0][0]=-prices[0];dp[0][1]=0;for(int i=1;i<length;i++){dp[i][0]=max(dp[i-1][0],-prices[i]);dp[i][1]=max(dp[i-1][1],dp[i-1][0]+prices[i]);}return dp[length-1][1];}
};
买卖股票的最佳时机II
本题股票可以买卖多次了(注意只有一只股票,所以再次购买前要出售掉之前的股票)
动规五部曲中,这个区别主要是体现在递推公式上,其他都和121. 买卖股票的最佳时机一样一样的。
这里重申一下dp数组的含义:
dp[i][0] 表示第i天持有股票所得现金。
dp[i][1] 表示第i天不持有股票所得最多现金
如果第i天持有股票即dp[i][0], 那么可以由两个状态推出来
第i-1天就持有股票,那么就保持现状,所得现金就是昨天持有股票的所得现金 即:dp[i - 1][0]
第i天买入股票,所得现金就是昨天不持有股票的所得现金减去 今天的股票价格 即:dp[i - 1][1] - prices[i]
注意这里和121. 买卖股票的最佳时机唯一不同的地方,就是推导dp[i][0]的时候,第i天买入股票的情况。
在121. 买卖股票的最佳时机中,因为股票全程只能买卖一次,所以如果买入股票,那么第i天持有股票即dp[i][0]一定就是 -prices[i]。
而本题,因为一只股票可以买卖多次,所以当第i天买入股票的时候,所持有的现金可能有之前买卖过的利润。
那么第i天持有股票即dp[i][0],如果是第i天买入股票,所得现金就是昨天不持有股票的所得现金 减去 今天的股票价格 即:dp[i - 1][1] - prices[i]。
再来看看如果第i天不持有股票即dp[i][1]的情况, 依然可以由两个状态推出来
第i-1天就不持有股票,那么就保持现状,所得现金就是昨天不持有股票的所得现金 即:dp[i - 1][1]
第i天卖出股票,所得现金就是按照今天股票价格卖出后所得现金即:prices[i] + dp[i - 1][0]
class Solution {
public:int maxProfit(vector<int>& prices) {int len=prices.size();vector<vector<int>> dp(len,vector<int>(2,0));dp[0][0]=-prices[0];dp[0][1]=0;for(int i=1;i<len;i++){dp[i][0]=max(dp[i-1][0],dp[i-1][1]-prices[i]);dp[i][1]=max(dp[i-1][1],dp[i-1][0]+prices[i]);}return dp[len-1][1];}
};
买卖股票的最佳时机III
关键在于至多买卖两次,这意味着可以买卖一次,可以买卖两次,也可以不买卖。
接来下我用动态规划五部曲详细分析一下:
确定dp数组以及下标的含义
一天一共就有五个状态,
没有操作 (其实我们也可以不设置这个状态)
第一次持有股票
第一次不持有股票
第二次持有股票
第二次不持有股票
dp[i][j]中 i表示第i天,j为 [0 - 4] 五个状态,dp[i][j]表示第i天状态j所剩最大现金。
需要注意:dp[i][1],表示的是第i天,买入股票的状态,并不是说一定要第i天买入股票,这是很多同学容易陷入的误区。
例如 dp[i][1] ,并不是说 第i天一定买入股票,有可能 第 i-1天 就买入了,那么 dp[i][1] 延续买入股票的这个状态。
确定递推公式
达到dp[i][1]状态,有两个具体操作:
操作一:第i天买入股票了,那么dp[i][1] = dp[i-1][0] - prices[i]
操作二:第i天没有操作,而是沿用前一天买入的状态,即:dp[i][1] = dp[i - 1][1]
那么dp[i][1]究竟选 dp[i-1][0] - prices[i],还是dp[i - 1][1]呢?
一定是选最大的,所以 dp[i][1] = max(dp[i-1][0] - prices[i], dp[i - 1][1]);
同理dp[i][2]也有两个操作:
操作一:第i天卖出股票了,那么dp[i][2] = dp[i - 1][1] + prices[i]
操作二:第i天没有操作,沿用前一天卖出股票的状态,即:dp[i][2] = dp[i - 1][2]
所以dp[i][2] = max(dp[i - 1][1] + prices[i], dp[i - 1][2])
同理可推出剩下状态部分:
dp[i][3] = max(dp[i - 1][3], dp[i - 1][2] - prices[i]);
dp[i][4] = max(dp[i - 1][4], dp[i - 1][3] + prices[i]);
dp数组如何初始化
第0天没有操作,这个最容易想到,就是0,即:dp[0][0] = 0;
第0天做第一次买入的操作,dp[0][1] = -prices[0];
第0天做第一次卖出的操作,这个初始值应该是多少呢?
此时还没有买入,怎么就卖出呢? 其实大家可以理解当天买入,当天卖出,所以dp[0][2] = 0;
第0天第二次买入操作,初始值应该是多少呢?应该不少同学疑惑,第一次还没买入呢,怎么初始化第二次买入呢?
第二次买入依赖于第一次卖出的状态,其实相当于第0天第一次买入了,第一次卖出了,然后再买入一次(第二次买入),那么现在手头上没有现金,只要买入,现金就做相应的减少。
所以第二次买入操作,初始化为:dp[0][3] = -prices[0];
同理第二次卖出初始化dp[0][4] = 0;
确定遍历顺序
从递归公式其实已经可以看出,一定是从前向后遍历,因为dp[i],依靠dp[i - 1]的数值。
class Solution {
public:int maxProfit(vector<int>& prices) {if(prices.size()==0){return 0;}vector<vector<int>> dp(prices.size(),vector<int>(5,0));dp[0][0]=0;dp[0][1]=-prices[0];dp[0][2]=0;dp[0][3]=-prices[0];dp[0][4]=0;for(int i=1;i<prices.size();i++){dp[i][0]=dp[i-1][0];dp[i][1]=max(dp[i-1][1],dp[i-1][0]-prices[i]);dp[i][2]=max(dp[i-1][2],dp[i-1][1]+prices[i]);dp[i][3]=max(dp[i-1][3],dp[i-1][2]-prices[i]);dp[i][4]=max(dp[i-1][4],dp[i-1][3]+prices[i]);}return dp[prices.size()-1][4];}
};
买卖股票的最佳时机IV
确定dp数组以及下标的含义
在动态规划:123.买卖股票的最佳时机III中,我是定义了一个二维dp数组,本题其实依然可以用一个二维dp数组。
使用二维数组 dp[i][j] :第i天的状态为j,所剩下的最大现金是dp[i][j]
j的状态表示为:
0 表示不操作
1 第一次买入
2 第一次卖出
3 第二次买入
4 第二次卖出
…
大家应该发现规律了吧 ,除了0以外,偶数就是卖出,奇数就是买入。
题目要求是至多有K笔交易,那么j的范围就定义为 2 * k + 1 就可以了。
所以二维dp数组的C++定义为:
vector<vector> dp(prices.size(), vector(2 * k + 1, 0));
确定递推公式
还要强调一下:dp[i][1],表示的是第i天,买入股票的状态,并不是说一定要第i天买入股票,这是很多同学容易陷入的误区。
达到dp[i][1]状态,有两个具体操作:
操作一:第i天买入股票了,那么dp[i][1] = dp[i - 1][0] - prices[i]
操作二:第i天没有操作,而是沿用前一天买入的状态,即:dp[i][1] = dp[i - 1][1]
选最大的,所以 dp[i][1] = max(dp[i - 1][0] - prices[i], dp[i - 1][1]);
同理dp[i][2]也有两个操作:
操作一:第i天卖出股票了,那么dp[i][2] = dp[i - 1][1] + prices[i]
操作二:第i天没有操作,沿用前一天卖出股票的状态,即:dp[i][2] = dp[i - 1][2]
所以dp[i][2] = max(dp[i - 1][1] + prices[i], dp[i - 1][2])
同理可以类比剩下的状态,代码如下:
for (int j = 0; j < 2 * k - 1; j += 2) {
dp[i][j + 1] = max(dp[i - 1][j + 1], dp[i - 1][j] - prices[i]);
dp[i][j + 2] = max(dp[i - 1][j + 2], dp[i - 1][j + 1] + prices[i]);
}
本题和动态规划:123.买卖股票的最佳时机III (opens new window)最大的区别就是这里要类比j为奇数是买,偶数是卖的状态。
dp数组如何初始化
第0天没有操作,这个最容易想到,就是0,即:dp[0][0] = 0;
第0天做第一次买入的操作,dp[0][1] = -prices[0];
第0天做第一次卖出的操作,这个初始值应该是多少呢?
此时还没有买入,怎么就卖出呢? 其实大家可以理解当天买入,当天卖出,所以dp[0][2] = 0;
第0天第二次买入操作,初始值应该是多少呢?应该不少同学疑惑,第一次还没买入呢,怎么初始化第二次买入呢?
第二次买入依赖于第一次卖出的状态,其实相当于第0天第一次买入了,第一次卖出了,然后在买入一次(第二次买入),那么现在手头上没有现金,只要买入,现金就做相应的减少。
所以第二次买入操作,初始化为:dp[0][3] = -prices[0];
第二次卖出初始化dp[0][4] = 0;
所以同理可以推出dp[0][j]当j为奇数的时候都初始化为 -prices[0]
代码如下:
for (int j = 1; j < 2 * k; j += 2) {
dp[0][j] = -prices[0];
}
在初始化的地方同样要类比j为偶数是卖、奇数是买的状态。
确定遍历顺序
从递归公式其实已经可以看出,一定是从前向后遍历,因为dp[i],依靠dp[i - 1]的数值。
class Solution {
public:int maxProfit(int k, vector<int>& prices) {vector<vector<int>> dp(prices.size(), vector<int>(2 * k + 1, 0));for (int j = 1; j < 2 * k; j += 2) {dp[0][j] = -prices[0];}for (int i = 1; i < prices.size(); i++) {for (int j = 0; j < 2 * k - 1; j += 2) {dp[i][j + 1] = max(dp[i - 1][j + 1], dp[i - 1][j] - prices[i]);dp[i][j + 2] =max(dp[i - 1][j + 2], dp[i - 1][j + 1] + prices[i]);}}return dp[prices.size()-1][2*k];}
};
最佳买卖股票时机含冷冻期
确定dp数组以及下标的含义
dp[i][j],第i天状态为j,所剩的最多现金为dp[i][j]。
出现冷冻期之后,状态其实是比较复杂,例如今天买入股票、今天卖出股票、今天是冷冻期,都是不能操作股票的。
具体可以区分出如下四个状态:
状态一:持有股票状态(今天买入股票,或者是之前就买入了股票然后没有操作,一直持有)
不持有股票状态,这里就有两种卖出股票状态
状态二:保持卖出股票的状态(两天前就卖出了股票,度过一天冷冻期。或者是前一天就是卖出股票状态,一直没操作)
状态三:今天卖出股票
状态四:今天为冷冻期状态,但冷冻期状态不可持续,只有一天!
j的状态为:
0:状态一
1:状态二
2:状态三
3:状态四
很多题解为什么讲的比较模糊,是因为把这四个状态合并成三个状态了,其实就是把状态二和状态四合并在一起了。
确定递推公式
达到买入股票状态(状态一)即:dp[i][0],有两个具体操作:
操作一:前一天就是持有股票状态(状态一),dp[i][0] = dp[i - 1][0]
操作二:今天买入了,有两种情况
前一天是冷冻期(状态四),dp[i - 1][3] - prices[i]
前一天是保持卖出股票的状态(状态二),dp[i - 1][1] - prices[i]
那么dp[i][0] = max(dp[i - 1][0], dp[i - 1][3] - prices[i], dp[i - 1][1] - prices[i]);
达到保持卖出股票状态(状态二)即:dp[i][1],有两个具体操作:
操作一:前一天就是状态二
操作二:前一天是冷冻期(状态四)
dp[i][1] = max(dp[i - 1][1], dp[i - 1][3]);
达到今天就卖出股票状态(状态三),即:dp[i][2] ,只有一个操作:
昨天一定是持有股票状态(状态一),今天卖出
即:dp[i][2] = dp[i - 1][0] + prices[i];
达到冷冻期状态(状态四),即:dp[i][3],只有一个操作:
昨天卖出了股票(状态三)
dp[i][3] = dp[i - 1][2];
dp数组如何初始化
这里主要讨论一下第0天如何初始化。
如果是持有股票状态(状态一)那么:dp[0][0] = -prices[0],一定是当天买入股票。
保持卖出股票状态(状态二),这里其实从 「状态二」的定义来说 ,很难明确应该初始多少,这种情况我们就看递推公式需要我们给他初始成什么数值。
如果i为1,第1天买入股票,那么递归公式中需要计算 dp[i - 1][1] - prices[i] ,即 dp[0][1] - prices[1],那么大家感受一下 dp[0][1] (即第0天的状态二)应该初始成多少,只能初始为0。想一想如果初始为其他数值,是我们第1天买入股票后 手里还剩的现金数量是不是就不对了。
今天卖出了股票(状态三),同上分析,dp[0][2]初始化为0,dp[0][3]也初始为0。
确定遍历顺序
从递归公式上可以看出,dp[i] 依赖于 dp[i-1],所以是从前向后遍历。
class Solution {
public:int maxProfit(vector<int>& prices) {int n=prices.size();if(n==0){return 0;}vector<vector<int>> dp(n,vector<int>(4,0));dp[0][0]=-prices[0];for(int i=1;i<prices.size();i++){dp[i][0]=max(dp[i-1][0],max(dp[i-1][1]-prices[i],dp[i-1][3]-prices[i]));dp[i][1]=max(dp[i-1][1],dp[i-1][3]);dp[i][2]=dp[i-1][0]+prices[i];dp[i][3]=dp[i-1][2];}return max(dp[n-1][3],max(dp[n-1][1],dp[n-1][2]));}
};
最长递增子序列
dp[i]的定义
本题中,正确定义dp数组的含义十分重要。
dp[i]表示i之前包括i的以nums[i]结尾的最长递增子序列的长度
为什么一定表示 “以nums[i]结尾的最长递增子序” ,因为我们在 做 递增比较的时候,如果比较 nums[j] 和 nums[i] 的大小,那么两个递增子序列一定分别以nums[j]为结尾 和 nums[i]为结尾, 要不然这个比较就没有意义了,不是尾部元素的比较那么 如何算递增呢。
状态转移方程
位置i的最长升序子序列等于j从0到i-1各个位置的最长升序子序列 + 1 的最大值。
所以:if (nums[i] > nums[j]) dp[i] = max(dp[i], dp[j] + 1);
注意这里不是要dp[i] 与 dp[j] + 1进行比较,而是我们要取dp[j] + 1的最大值。
dp[i]的初始化
每一个i,对应的dp[i](即最长递增子序列)起始大小至少都是1.
确定遍历顺序
dp[i] 是有0到i-1各个位置的最长递增子序列 推导而来,那么遍历i一定是从前向后遍历。
j其实就是遍历0到i-1,那么是从前到后,还是从后到前遍历都无所谓,只要吧 0 到 i-1 的元素都遍历了就行了。 所以默认习惯 从前向后遍历。
class Solution {
public:int lengthOfLIS(vector<int>& nums) {if(nums.size()<=1){return nums.size();}int result=0;vector<int> dp(nums.size(),1);for(int i=1;i<nums.size();i++){for(int j=0;j<i;j++){if(nums[i]>nums[j]){dp[i]=max(dp[j]+1,dp[i]);}}if(dp[i]>result){result=dp[i];}}return result;}
};
最长连续递增子序列
确定dp数组(dp table)以及下标的含义
dp[i]:以下标i为结尾的连续递增的子序列长度为dp[i]。
注意这里的定义,一定是以下标i为结尾,并不是说一定以下标0为起始位置。
确定递推公式
如果 nums[i] > nums[i - 1],那么以 i 为结尾的连续递增的子序列长度 一定等于 以i - 1为结尾的连续递增的子序列长度 + 1 。
即:dp[i] = dp[i - 1] + 1;
注意这里就体现出和动态规划:300.最长递增子序列 的区别!
因为本题要求连续递增子序列,所以就只要比较nums[i]与nums[i - 1],而不用去比较nums[j]与nums[i] (j是在0到i之间遍历)。
既然不用j了,那么也不用两层for循环,本题一层for循环就行,比较nums[i] 和 nums[i - 1]。
dp数组如何初始化
以下标i为结尾的连续递增的子序列长度最少也应该是1,即就是nums[i]这一个元素。
所以dp[i]应该初始1;
确定遍历顺序
从递推公式上可以看出, dp[i + 1]依赖dp[i],所以一定是从前向后遍历。
class Solution {
public:int lengthOfLIS(vector<int>& nums) {if(nums.size()<=1){return nums.size();}int result=0;vector<int> dp(nums.size(),1);for(int i=1;i<nums.size();i++){for(int j=0;j<i;j++){if(nums[i]>nums[j]){dp[i]=max(dp[j]+1,dp[i]);}}if(dp[i]>result){result=dp[i];}}return result;}
};
最长重复子数组
确定dp数组(dp table)以及下标的含义
dp[i][j] :以下标i - 1为结尾的A,和以下标j - 1为结尾的B,最长重复子数组长度为dp[i][j]。 (特别注意: “以下标i - 1为结尾的A” 标明一定是 以A[i-1]为结尾的字符串 )
此时细心的同学应该发现,那dp[0][0]是什么含义呢?总不能是以下标-1为结尾的A数组吧
其实dp[i][j]的定义也就决定着,我们在遍历dp[i][j]的时候i 和 j都要从1开始。
确定递推公式
根据dp[i][j]的定义,dp[i][j]的状态只能由dp[i - 1][j - 1]推导出来。
即当A[i - 1] 和B[j - 1]相等的时候,dp[i][j] = dp[i - 1][j - 1] + 1;
根据递推公式可以看出,遍历i 和 j 要从1开始!
dp数组如何初始化
根据dp[i][j]的定义,dp[i][0] 和dp[0][j]其实都是没有意义的!
但dp[i][0] 和dp[0][j]要初始值,因为 为了方便递归公式dp[i][j] = dp[i - 1][j - 1] + 1;
所以dp[i][0] 和dp[0][j]初始化为0。
举个例子A[0]如果和B[0]相同的话,dp[1][1] = dp[0][0] + 1,只有dp[0][0]初始为0,正好符合递推公式逐步累加起来。
确定遍历顺序
外层for循环遍历A,内层for循环遍历B。
那又有同学问了,外层for循环遍历B,内层for循环遍历A。不行么?
也行,一样的,我这里就用外层for循环遍历A,内层for循环遍历B了。
同时题目要求长度最长的子数组的长度。所以在遍历的时候顺便把dp[i][j]的最大值记录下来。
class Solution {
public:int findLength(vector<int>& nums1, vector<int>& nums2) {vector<vector<int>> dp(nums1.size()+1,vector<int>(nums2.size()+1,0));int result=0;for(int i=1;i<=nums1.size();i++){for(int j=1;j<=nums2.size();j++){if(nums1[i-1]==nums2[j-1]){dp[i][j]=dp[i-1][j-1]+1;}if(dp[i][j]>result){result=dp[i][j];}}}return result;}
};
最长重复子数组要求连续的匹配,而最长公共子序列允许不连续匹配。
最长公共子序列
确定dp数组(dp table)以及下标的含义
dp[i][j]:长度为[0, i - 1]的字符串text1与长度为[0, j - 1]的字符串text2的最长公共子序列为dp[i][j]
有同学会问:为什么要定义长度为[0, i - 1]的字符串text1,定义为长度为[0, i]的字符串text1不香么?
这样定义是为了后面代码实现方便,如果非要定义为长度为[0, i]的字符串text1也可以,我在 动态规划:718. 最长重复子数组中的「拓展」里 详细讲解了区别所在,其实就是简化了dp数组第一行和第一列的初始化逻辑。
确定递推公式
主要就是两大情况: text1[i - 1] 与 text2[j - 1]相同,text1[i - 1] 与 text2[j - 1]不相同
如果text1[i - 1] 与 text2[j - 1]相同,那么找到了一个公共元素,所以dp[i][j] = dp[i - 1][j - 1] + 1;
如果text1[i - 1] 与 text2[j - 1]不相同,那就看看text1[0, i - 2]与text2[0, j - 1]的最长公共子序列 和 text1[0, i - 1]与text2[0, j - 2]的最长公共子序列,取最大的。
即:dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
dp数组如何初始化
先看看dp[i][0]应该是多少呢?
test1[0, i-1]和空串的最长公共子序列自然是0,所以dp[i][0] = 0;
同理dp[0][j]也是0。
其他下标都是随着递推公式逐步覆盖,初始为多少都可以,那么就统一初始为0。
确定遍历顺序
从递推公式,可以看出,有三个方向可以推出dp[i][j],
那么为了在递推的过程中,这三个方向都是经过计算的数值,所以要从前向后,从上到下来遍历这个矩阵。
不同的子序列
子序列系列的题可以分为有序序列、连续、相等序列、总和序列等。
- 要求有序(递增或递减)或连续往往都是以下标结尾,相等且不连续往往都是区间。(有序"或"连续" dp【i】都是以 nums【i-1】结尾, 其余都是 nums【0, i-1】, 二维同理)
- 因为前者如果失序或者不连续了需要从头再来,而后者可以在之前的保存的状态上接着操作。
确定dp数组(dp table)以及下标的含义
在s【0, i-1】的子序列中,有多少个t【0, j - 1】的匹配,由于是完全匹配,实际匹配到的s的子序列结尾必须以t【j - 1】为结尾,但是这里s【i - 1】并不一定在这个子序列里
dp【i】【j】 为在s的前i个元素(即s【0, i - 1】)中,有多少个t【0, j - 1】的匹配(以t【j - 1】为结尾)
假设 t=“bag” 两种转移情况分别为:
// 当此元素相等时, 则求s的前面有多少个"ba" + 前面有多少个完整"bag"
// 若此元素不相等, 则求s的前面有多少个"bag"
确定递推公式
这一类问题,基本是要分析两种情况
s[i - 1] 与 t[j - 1]相等
s[i - 1] 与 t[j - 1] 不相等
当s[i - 1] 与 t[j - 1]相等时,dp[i][j]可以有两部分组成。
- 使用 s[i-1] 来匹配 t[j-1]:
当 s[i-1] 和 t[j-1] 相等时,这意味着可以将 s[i-1] 用作 t[j-1] 的匹配。在这种情况下,除了当前的字符 s[i-1] 之外,剩下的部分是前 i-1 个字符必须能够形成前 j-1 个字符。
因此,我们用状态 dp[i-1][j-1] 来表示这种情况,它提供了在不考虑当前字符(s[i-1])的情况下能形成 t 的前 j-1 个字符的组合数量。
- 不使用 s[i-1] 来匹配 t[j-1]:
如果我们选择不将 s[i-1] 用于匹配 t[j-1],那么我们需要依赖前 i-1 个字符来形成 t 的前 j 个字符。这相当于在 s 中忽略当前字符 s[i-1] 的影响。
在这种情况下,我们的组合数就是 dp[i-1][j]。
s字符串跟t字符串如果增添了一个相同的字符,那么你现在以这个字符串结尾的s字符串中出现以这个字符串结尾的t字符串的个数就会有两个来源,一就是原本不加这个字符,s字符串以s【i-2】结尾时出现t字符串以t【j-2】结尾的个数,也就是dp【i-1】【j-1】的值,就不需要考虑s【i-1】跟t【j-1】。二就是由于t新增添了这个字符,s字符串以s【i-2】结尾时t字符串以t【j-1】的结尾的个数。也就是dp【i-1】【j】。
dp数组如何初始化
从递推公式dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]; 和 dp[i][j] = dp[i - 1][j]; 中可以看出dp[i][j] 是从上方和左上方推导而来,如图:,那么 dp[i][0] 和dp[0][j]是一定要初始化的。
dp[i][0]表示什么呢?
dp[i][0] 表示:以i-1为结尾的s可以随便删除元素,出现空字符串的个数。
那么dp[i][0]一定都是1,因为也就是把以i-1为结尾的s,删除所有元素,出现空字符串的个数就是1。
再来看dp[0][j],dp[0][j]:空字符串s可以随便删除元素,出现以j-1为结尾的字符串t的个数。
那么dp[0][j]一定都是0,s如论如何也变成不了t。
最后就要看一个特殊位置了,即:dp[0][0] 应该是多少。
dp[0][0]应该是1,空字符串s,可以删除0个元素,变成空字符串t。
确定遍历顺序
从递推公式dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]; 和 dp[i][j] = dp[i - 1][j]; 中可以看出dp[i][j]都是根据左上方和正上方推出来的。
class Solution {
public:int numDistinct(string s, string t) {vector<vector<uint64_t>> dp(s.size()+1,vector<uint64_t>(t.size()+1));for(int i=0;i<s.size();i++){dp[i][0]=1;}for(int j=1;j<t.size();j++){dp[0][j]=0;}for(int i=1;i<=s.size();i++){for(int j=1;j<=t.size();j++){if(s[i-1]==t[j-1]){dp[i][j]=dp[i-1][j-1]+dp[i-1][j];}else{dp[i][j]=dp[i-1][j];}}}return dp[s.size()][t.size()];}
};
两个字符串的删除操作
确定dp数组(dp table)以及下标的含义
dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word2,想要达到相等,所需要删除元素的最少次数。
这里dp数组的定义有点点绕,大家要撸清思路。
确定递推公式
当word1[i - 1] 与 word2[j - 1]相同的时候
当word1[i - 1] 与 word2[j - 1]不相同的时候
当word1[i - 1] 与 word2[j - 1]相同的时候,dp[i][j] = dp[i - 1][j - 1];
当word1[i - 1] 与 word2[j - 1]不相同的时候,有三种情况:
情况一:删word1[i - 1],最少操作次数为dp[i - 1][j] + 1
情况二:删word2[j - 1],最少操作次数为dp[i][j - 1] + 1
情况三:同时删word1[i - 1]和word2[j - 1],操作的最少次数为dp[i - 1][j - 1] + 2
那最后当然是取最小值,所以当word1[i - 1] 与 word2[j - 1]不相同的时候,递推公式:dp[i][j] = min({dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1});
因为 dp[i][j - 1] + 1 = dp[i - 1][j - 1] + 2,所以递推公式可简化为:dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);
这里可能不少录友有点迷糊,从字面上理解 就是 当 同时删word1[i - 1]和word2[j - 1],dp[i][j-1] 本来就不考虑 word2[j - 1]了,那么我在删 word1[i - 1],是不是就达到两个元素都删除的效果,即 dp[i][j-1] + 1。
dp数组如何初始化
从递推公式中,可以看出来,dp[i][0] 和 dp[0][j]是一定要初始化的。
dp[i][0]:word2为空字符串,以i-1为结尾的字符串word1要删除多少个元素,才能和word2相同呢,很明显dp[i][0] = i。
确定遍历顺序
从递推公式 dp[i][j] = min(dp[i - 1][j - 1] + 2, min(dp[i - 1][j], dp[i][j - 1]) + 1); 和dp[i][j] = dp[i - 1][j - 1]可以看出dp[i][j]都是根据左上方、正上方、正左方推出来的。
所以遍历的时候一定是从上到下,从左到右,这样保证dp[i][j]可以根据之前计算出来的数值进行计算。
class Solution {
public:int minDistance(string word1, string word2) {vector<vector<int>> dp(word1.size()+1,vector<int>(word2.size()+1));for(int i=0;i<=word1.size();i++){dp[i][0]=i;}for(int j=0;j<=word2.size();j++){dp[0][j]=j;}for(int i=1;i<=word1.size();i++){for(int j=1;j<=word2.size();j++){if(word1[i-1]==word2[j-1]){dp[i][j]=dp[i-1][j-1];}else{dp[i][j] = min({dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1});}}}return dp[word1.size()][word2.size()];}
};
编辑距离
确定dp数组(dp table)以及下标的含义
dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]。
确定递推公式
在确定递推公式的时候,首先要考虑清楚编辑的几种操作
操作一:word1删除一个元素,那么就是以下标i - 2为结尾的word1 与 j-1为结尾的word2的最近编辑距离 再加上一个操作。
即 dp[i][j] = dp[i - 1][j] + 1;
操作二:word2删除一个元素,那么就是以下标i - 1为结尾的word1 与 j-2为结尾的word2的最近编辑距离 再加上一个操作。
即 dp[i][j] = dp[i][j - 1] + 1;
word2添加一个元素,相当于word1删除一个元素,例如 word1 = “ad” ,word2 = “a”,word1删除元素’d’ 和 word2添加一个元素’d’,变成word1=“a”, word2=“ad”, 最终的操作数是一样!
操作三:替换元素,word1替换word1[i - 1],使其与word2[j - 1]相同,此时不用增删加元素。
可以回顾一下,if (word1[i - 1] == word2[j - 1])的时候我们的操作 是 dp[i][j] = dp[i - 1][j - 1] 对吧。
那么只需要一次替换的操作,就可以让 word1[i - 1] 和 word2[j - 1] 相同。
所以 dp[i][j] = dp[i - 1][j - 1] + 1;
综上,当 if (word1[i - 1] != word2[j - 1]) 时取最小的,即:dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
dp数组如何初始化
再回顾一下dp[i][j]的定义:
dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]。
那么dp[i][0] 和 dp[0][j] 表示什么呢?
dp[i][0] :以下标i-1为结尾的字符串word1,和空字符串word2,最近编辑距离为dp[i][0]。
那么dp[i][0]就应该是i,对word1里的元素全部做删除操作,即:dp[i][0] = i;
同理dp[0][j] = j;
class Solution {
public:int minDistance(string word1, string word2) {vector<vector<int>> dp(word1.size()+1,vector<int>(word2.size()+1,0));for(int i=0;i<=word1.size();i++) dp[i][0]=i;for(int j=0;j<=word2.size();j++) dp[0][j]=j;for(int i=1;i<=word1.size();i++){for(int j=1;j<=word2.size();j++){if(word1[i-1]==word2[j-1]){dp[i][j]=dp[i-1][j-1];}else{dp[i][j]=min({dp[i][j-1],dp[i-1][j],dp[i-1][j-1]})+1;}}}return dp[word1.size()][word2.size()];}
};
确定dp数组(dp table)以及下标的含义
如果大家做了很多这种子序列相关的题目,在定义dp数组的时候 很自然就会想题目求什么,我们就如何定义dp数组。
绝大多数题目确实是这样,不过本题如果我们定义,dp[i] 为 下标i结尾的字符串有 dp[i]个回文串的话,我们会发现很难找到递归关系。
dp[i] 和 dp[i-1] ,dp[i + 1] 看上去都没啥关系。
我们在判断字符串S是否是回文,那么如果我们知道 s[1],s[2],s[3] 这个子串是回文的,那么只需要比较 s[0]和s[4]这两个元素是否相同,如果相同的话,这个字符串s 就是回文串。
那么此时我们是不是能找到一种递归关系,也就是判断一个子字符串(字符串下标范围[i,j])是否回文,依赖于,子字符串(下标范围[i + 1, j - 1])) 是否是回文。
所以为了明确这种递归关系,我们的dp数组是要定义成一位二维dp数组。
布尔类型的dp[i][j]:表示区间范围[i,j] (注意是左闭右闭)的子串是否是回文子串,如果是dp[i][j]为true,否则为false。
确定递推公式
在确定递推公式时,就要分析如下几种情况。
整体上是两种,就是s[i]与s[j]相等,s[i]与s[j]不相等这两种。
当s[i]与s[j]不相等,那没啥好说的了,dp[i][j]一定是false。
当s[i]与s[j]相等时,这就复杂一些了,有如下三种情况
情况一:下标i 与 j相同,同一个字符例如a,当然是回文子串
情况二:下标i 与 j相差为1,例如aa,也是回文子串
情况三:下标:i 与 j相差大于1的时候,例如cabac,此时s[i]与s[j]已经相同了,我们看i到j区间是不是回文子串就看aba是不是回文就可以了,那么aba的区间就是 i+1 与 j-1区间,这个区间是不是回文就看dp[i + 1][j - 1]是否为true。
result就是统计回文子串的数量。
注意这里我没有列出当s[i]与s[j]不相等的时候,因为在下面dp[i][j]初始化的时候,就初始为false。
dp数组如何初始化
dp[i][j]可以初始化为true么? 当然不行,怎能刚开始就全都匹配上了。
所以dp[i][j]初始化为false。
确定遍历顺序
遍历顺序可有有点讲究了。
首先从递推公式中可以看出,情况三是根据dp[i + 1][j - 1]是否为true,在对dp[i][j]进行赋值true的。
dp[i + 1][j - 1] 在 dp[i][j]的左下角,如图:
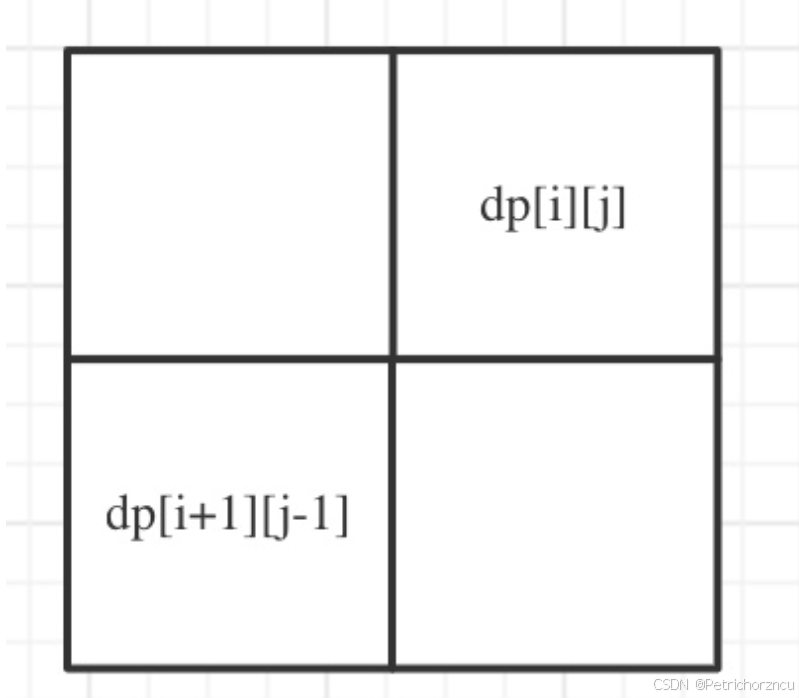
如果这矩阵是从上到下,从左到右遍历,那么会用到没有计算过的dp[i + 1][j - 1],也就是根据不确定是不是回文的区间[i+1,j-1],来判断了[i,j]是不是回文,那结果一定是不对的。
所以一定要从下到上,从左到右遍历,这样保证dp[i + 1][j - 1]都是经过计算的。
有的代码实现是优先遍历列,然后遍历行,其实也是一个道理,都是为了保证dp[i + 1][j - 1]都是经过计算的。
class Solution {
public:int countSubstrings(string s) {vector<vector<bool>> dp(s.size(),vector<bool>(s.size(),false));int result=0;for(int i=s.size();i>=0;i--){//行for(int j=i;j<s.size();j++){//列if(s[i]==s[j]){if(j-i<=1){dp[i][j]=true;result++;}else if(dp[i+1][j-1]){dp[i][j]=true;result++;}}}}return result;}
};
最长回文子序列
回文子串是要连续的,回文子序列可不是连续的! 回文子串,回文子序列都是动态规划经典题目。
确定dp数组(dp table)以及下标的含义
dp[i][j]:字符串s在[i, j]范围内最长的回文子序列的长度为dp[i][j]。
确定递推公式
在判断回文子串的题目中,关键逻辑就是看s[i]与s[j]是否相同。
如果s[i]与s[j]相同,那么dp[i][j] = dp[i + 1][j - 1] + 2;
如果s[i]与s[j]不相同,说明s[i]和s[j]的同时加入 并不能增加[i,j]区间回文子序列的长度,那么分别加入s[i]、s[j]看看哪一个可以组成最长的回文子序列。
加入s[j]的回文子序列长度为dp[i + 1][j]。
加入s[i]的回文子序列长度为dp[i][j - 1]。
那么dp[i][j]一定是取最大的,即:dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
dp数组如何初始化
首先要考虑当i 和j 相同的情况,从递推公式:dp[i][j] = dp[i + 1][j - 1] + 2; 可以看出 递推公式是计算不到 i 和j相同时候的情况。
所以需要手动初始化一下,当i与j相同,那么dp[i][j]一定是等于1的,即:一个字符的回文子序列长度就是1。
其他情况dp[i][j]初始为0就行,这样递推公式:dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]); 中dp[i][j]才不会被初始值覆盖。
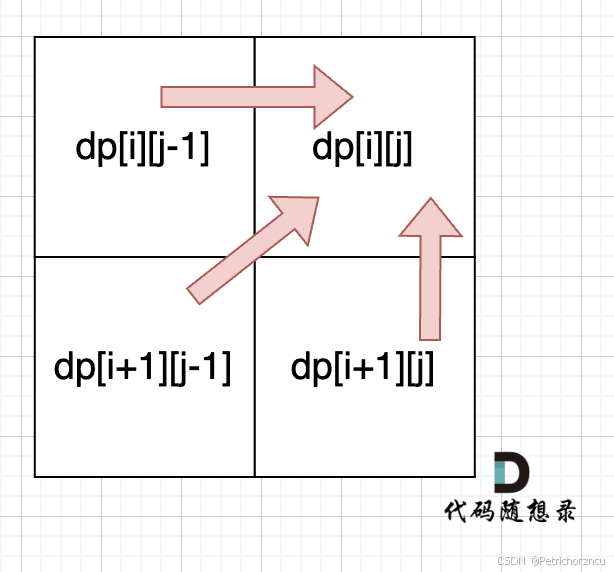
确定遍历顺序
从递归公式中,可以看出,dp[i][j] 依赖于 dp[i + 1][j - 1] ,dp[i + 1][j] 和 dp[i][j - 1],如图:
所以遍历i的时候一定要从下到上遍历,这样才能保证下一行的数据是经过计算的。
j的话,可以正常从左向右遍历。
class Solution {
public:int longestPalindromeSubseq(string s) {vector<vector<int>> dp(s.size(),vector<int>(s.size(),0));for(int i=0;i<s.size();i++){dp[i][i]=1;}for(int i=s.size()-1;i>=0;i--){for(int j=i+1;j<s.size();j++){if(s[i]==s[j]){dp[i][j]=dp[i+1][j-1]+2;}else{dp[i][j]=max(dp[i+1][j],dp[i][j-1]);}}}return dp[0][s.size()-1];}
};