C语言的字节对齐
一、基本概念
1. 什么是自然对齐
对于一个存储在内存中的变量,如果它的内存地址等于该变量长度的整数倍,则称该变量是自然对齐的。
例子:对于32位的CPU,如果一个int型变量A的地址是0x00000004,A是自然对齐。
2. 关于CPU存取数据的效率问题
假设有一片连续的内存地址,如下图:

每个地址上可存储1个字节的数据。
例子:以32位的CPU为例,32位的CPU,默认是4字节[32 / 8 = 4]对齐。
当整型数据A的存储起始地址为0x2,则它在内存中的数据占据了4个单元,分别对应地址0x2~0x5。CPU对该数据的读取操作如下:
(1) CPU先读取地址0x0~0x3,读出0x2和0x3地址上的数据,一个short类型[2字节]的数
据。
(2) 再读地址0x4~0x7,读出0x4和0x5地址上的数据,一个short类型[2字节]的数据。
(3) 最后将前面两次读取到的数据进行组合,得到原始的int类型数据。
注:实际上读了两次[访问两次内存]才读到真正的数据
如果A的存储起始地址为0x3,则它在内存中存储的地址为0x3~0x6。CPU对该数据的读取操作如下:
(1) CPU先读取地址0x0~0x3,读出0x3地址上的数据,一个char类型[1字节]的数据。
(2) 接着访问内存地址0x4~0x7,这里就有两种情况,取决于CPU的读取策略。
A. 先读出0x4上的一个char,B. 再读出0x5~0x6上的一个short;
A. 先读出0x4~0x5上的一个short,B. 再读出0x6上的一个char。
(3) 最后将前面三次读取到的数据进行组合,得到原始的int类型数据。
注:实际上读了三次[访问三次内存]才读到真正的数据
如果A存储在自然对其的地址上[如:0x4, 0x8……],CPU只需要读取一次即可。
对比以上三种情况进行分析可以,变量在内存中存储的位置影响CPU的存储效率。
3. 编译器如何处理字节对齐
C语言的数据类型可分为标准数据类型和构造数据类型。标准数据类型的存储地址为其长度的整数倍即可实现对齐。而对于构造的数据类型:结构体、共用体和数组,对齐的原则是:
(1) 对于数组,因为数组里元素的数据类型都是一样的,所以,第一个元素对齐之后,后面剩余元素自然就对齐了。
(2) 共用体,按照长度最大的成员进行对齐。
(3) 结构体,因为结构体里的数据成员类型可以是不同的,所以,每一个成员都需要对齐。
4. 常见的字节对齐方式
有:1字节对齐,2字节对齐,4字节对齐。其中1字节对齐是最小的字节对齐方式。
例如:32位的CPU,是:32/8=4字节对齐,因此比如32位的gcc编译器也是4字节对齐。
重点讨论结构体类型的对齐。
二、讨论结构体类型变量的大小
1. C语言的__attribute__选项
__attribute__选项可以设置函数的属性(Function Attribute),变量属性(Variable Attribute),类型属性( Type Attribute)。对于C语言中的结构体类型来说,经常使用该选项来指定结构体类型的字节对齐属性。传入选项中的参数有:aligned(N)、packed。
2. 对齐规则
首先,每个成员都先自身对齐(假设数据长度是N字节对齐,则存储地址%N = 0);其次是结构体的总长度要对齐(总长 = 最大长度数据成员的最小整数倍,total(len) = max(data_type) *n )。所以会有填补空间的情况(使用空字符进行填充,ASCII值为0的NULL)。
3. 示例
3.1 例子1
32位的CPU,默认按4字节对齐。
| struct persion { char sex; int age; char name[10]; };
struct persion per_01;
int main(void) { printk("sizeof(per_01) = %ld\n", sizeof(per_01));
while (1) { ; }
return 0; } |
程序结果:main: sizeof(per_01) = 20
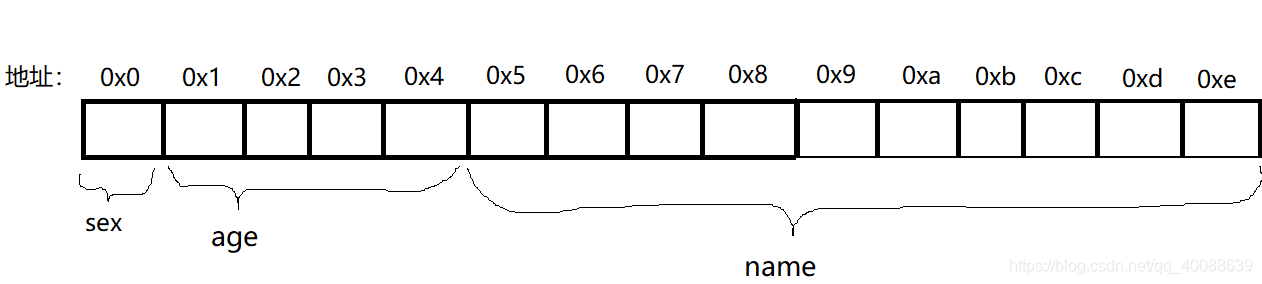
分析:首先考虑的是各个元素自身的对齐,CPU按4字节对齐来访问数据,也就是数据要放在:Address % 4=0,所以,假设第一个元素起始地址位是0x0,只占1个字节,为了能够让第二个成员对齐,在sex的后面会有3个填充的字节;那么第二个元素就得放0x4上,占4个连续的内存空间;第三个元素放0x8上,占10个连续的内存空间地址;最后,再考虑整个结构体的对齐,name后有也有2个填充的字节,整个结构体变量共占用20个字节连续的内存空间(可以这么理解:CPU会读5次,每次读4字节,5 x 4 =20),其中有5个空间(3+2)是无用的空间。该结构体变量的各个成员在内存中的存储情况如下图。

再分析CPU读取结构体成员的过程:
(1) 读地址0x0~0x3,读到sex。
(2) 偏移量为4,读地址0x4~0x7,可读到age。
(3) 偏移量为8,读起始地址0x8,可读到name。
以上是理论的分析,接下来,可将每个成员的首地址以及偏移量打印出来,程序如下:
| struct persion { char sex; int age; char name[10]; };
struct persion per_01;
int main(void) { printk("&per_01.sex = %p, offset(sex) = %ld", &per_01.sex, offsetof(struct persion, sex)); printk("&per_01.age = %p, offset(age) = %ld", &per_01.age, offsetof(struct persion, age)); printk("per_01.name = %p, offset(name) = %ld", per_01.name, offsetof(struct persion, name)); while (1) { ; }
return 0; } |
运行结果:
| main: &per_01.sex = 0xbfc2480c, offset(sex) = 0 main: &per_01.age = 0xbfc24810, offset(age) = 4 main: &per_01.name = 0xbfc24814, offset(name) = 8 |
3.1.1 小结
(1) 填充会有两种情况:在数据成员之间填充,目的是为了能让下一个成员能对齐;而在最尾的成员之后填充,考虑的是整个结构体的对齐,在不使用参数__attribute__的情况下,总长 = 最大长度数据成员的最小整数倍。
(2) 填充的空间算是浪费掉的空间,但是相对于目前计算机的存储技术而言,这一点空间算不上什么,这就是典型的“以牺牲空间来换取时间上的效率”。
(3) 每次运行程序,打印出来的数据成员地址可能不一样,但是地址排布规律是一样的。
| main: &per_01.sex = 0xbfc24800, offset(sex) = 0 main: &per_01.age = 0xbfc24804, offset(age) = 4 main: &per_01.name = 0xbfc24808, offset(name) = 8
main: &per_01.sex = 0xbfc2480c, offset(sex) = 0 main: &per_01.age = 0xbfc24810, offset(age) = 4 main: &per_01.name = 0xbfc24814, offset(name) = 8 |
(4) 偏移量,指的是第一个元素之后,第二个元素开始,相对于首地址[实际上就是第一个元
素的地址]的偏移量,用当前元素的地址减去首地址就得到偏移量,可以直接用库函数offsetof()求得。
| 0xbfc24810 - 0xbfc2480c = 4 0xbfc24814 - 0xbfc2480c = 8 |
3.2 例子2
使用参数__attribute__,如果传入的参数是aligned(N)。
场景1:N比结构体成员中最大数据长度的成员还要小,则要按最大数据成员的长度来对齐[各个成员的对齐情况以及整个结构体的长度对齐]。指定2字节对齐,结构体成员中有int数据类型(32位CPU,默认4字节对齐),示例程序如下:
| struct persion { char sex; int age; char name[10]; };
struct persion_02 { char sex; int age; char name[10]; }__attribute__ ((aligned(2)));
struct persion per_01; struct persion_02 per_02; int main(void) { printk("sizeof(per_01) = %ld\n", sizeof(per_01)); printk ("&per_01.sex = %p, offset(sex) = %ld", &per_01.sex, offsetof(struct persion, sex)); printk ("&per_01.age = %p, offset(age) = %ld", &per_01.age, offsetof(struct persion, age)); printk ("per_01.name = %p, offset(name) = %ld", per_01.name, offsetof(struct persion, name)); printk ("*****************************************************************");
printk ("sizeof(per_02) = %ld\n", sizeof(per_02)); printk ("&per_02.sex = %p, offset(sex) = %ld", &per_02.sex, offsetof(struct persion_02, sex)); printk ("&per_02.age = %p, offset(age) = %ld", &per_02.age, offsetof(struct persion_02, age)); printk ("per_02.name = %p, offset(name) = %ld", per_02.name, offsetof(struct persion_02, name)); while (1) { ; }
return 0; } |
程序运行结果:
| main: sizeof(per_01) = 20
main: &per_01.sex = 0xbfc24820, offset(sex) = 0 main: &per_01.age = 0xbfc24824, offset(age) = 4 main: per_01.name = 0xbfc24828, offset(name) = 8 main: ********************************************************************
main: sizeof(per_02) = 20 main: &per_02.sex = 0xbfc2480c, offset(sex) = 0 main: &per_02.age = 0xbfc24810, offset(age) = 4 main: per_02.name = 0xbfc24814, offset(name) = 8 |
注:对于该例子,1字节或者2字节对齐,得到的结果都是一样的,都按4字节来对齐。
场景2: N就比结构体成员中最大数据长度的成员还要大,
假设是64位的CPU,默认是8字节对齐。那么传入的参数是aligned(8)。则:各个成员的对齐情况是自然对齐;整个结构体的长度是N对齐,示例程序如下:
| struct persion { char sex; int age; char name[10]; };
struct persion_02 { char sex; int age; char name[10]; }__attribute__ ((aligned(8))); //aligned(N),N=8
struct persion per_01; struct persion_02 per_02;
int main(void) { printk("sizeof(per_01) = %ld\n", sizeof(per_01)); printk ("&per_01.sex = %p, offset(sex) = %ld", &per_01.sex, offsetof(struct persion, sex)); printk ("&per_01.age = %p, offset(age) = %ld", &per_01.age, offsetof(struct persion, age)); printk ("per_01.name = %p, offset(name) = %ld", per_01.name, offsetof(struct persion, name)); printk ("******************************************************************");
printk ("sizeof(per_02) = %ld\n", sizeof(per_02)); printk ("&per_02.sex = %p, offset(sex) = %ld", &per_02.sex, offsetof(struct persion_02, sex)); printk ("&per_02.age = %p, offset(age) = %ld", &per_02.age, offsetof(struct persion_02, age)); printk ("per_02.name = %p, offset(name) = %ld", per_02.name, offsetof(struct persion_02, name));
while (1) { ; }
return 0; } |
程序运行结果:
| main: &per_01.sex = 0xbfc24828, offset(sex) = 0 main: &per_01.age = 0xbfc2482c, offset(age) = 4 main: per_01.name = 0xbfc24830, offset(name) = 8 main: ********************************************************************
main: sizeof(per_02) = 24 main: &per_02.sex = 0xbfc24810, offset(sex) = 0 main: &per_02.age = 0xbfc24814, offset(age) = 4 main: per_02.name = 0xbfc24818, offset(name) = 8 |
8字节对齐,则在最后一个数据成员后,补了6个空字符。在第一个数据成员后,填充了3个空字符。可以取出地址上的值,进行验证。下面程序打印第一个字节之后,填充的三个空字符的ASCII值。
| struct persion { char sex; int age; char name[10]; };
struct persion_02 { char sex; int age; char name[10]; }__attribute__ ((aligned(8)));
struct persion per_01; struct persion_02 per_02={ 'm', 26, "jone" };
int main(void) { char *sex_dat = NULL; int *age_dat = NULL;
printk("sizeof(per_01) = %ld\n", sizeof(per_01)); printk("&per_01.sex = %p, offset(sex) = %ld", &per_01.sex, offsetof(struct persion, sex)); printk("&per_01.age = %p, offset(age) = %ld", &per_01.age, offsetof(struct persion, age)); printk("per_01.name = %p, offset(name) = %ld", per_01.name, offsetof(struct persion, name)); printk("****************************************************************");
printk("sizeof(per_02) = %ld\n", sizeof(per_02)); printk("&per_02.sex = %p, offset(sex) = %ld", &per_02.sex, offsetof(struct persion_02, sex)); printk("&per_02.age = %p, offset(age) = %ld", &per_02.age, offsetof(struct persion_02, age)); printk("per_02.name = %p, offset(name) = %ld", per_02.name, offsetof(struct persion_02, name));
sex_dat = &per_02.sex; age_dat = &per_02.age;
printk("*(sex_dat) = %c", *(sex_dat)); printk("*(sex_dat + 1) = 0x%02x", *(sex_dat + 1)); printk("*(sex_dat + 1) = 0x%02x", *(sex_dat + 2)); printk("*(sex_dat + 1) = 0x%02x", *(sex_dat + 3));
printk("*(age_dat) = %d", *(age_dat));
while (1) { ; }
return 0; }
|
程序运行结果:
| main: sizeof(per_01) = 20 main: &per_01.sex = 0xbfc24824, offset(sex) = 0 main: &per_01.age = 0xbfc24828, offset(age) = 4 main: per_01.name = 0xbfc2482c, offset(name) = 8 main: ********************************************************************
main: sizeof(per_02) = 24 main: &per_02.sex = 0xbfc234b8, offset(sex) = 0 main: &per_02.age = 0xbfc234bc, offset(age) = 4 main: per_02.name = 0xbfc234c0, offset(name) = 8
main: *(sex_dat) = m main: *(sex_dat + 1) = 0x00 main: *(sex_dat + 1) = 0x00 main: *(sex_dat + 1) = 0x00 main: *(age_dat) = 26 |
内存排布图示:没按实际的来画,但是分布规律相同。

3.3 例子3
使用参数__attribute__,如果传入的参数是packed。告诉编译器,在编译过程中取消优化对齐。所以,实际占用多少字节就是多少字节,不会有填充。示例程序如下:
| #if 0 struct persion { char sex; int age; char name[10]; }__attribute__ ((aligned(1))); #else struct persion { char sex; int age; char name[10]; }__attribute__ ((packed));
#endif struct persion per_01;
int main(void) { printk("sizeof(per_01) = %ld\n", sizeof(per_01)); printk("&per_01.sex = %p, offset(sex) = %ld", &per_01.sex, offsetof(struct persion, sex)); printk("&per_01.age = %p, offset(age) = %ld", &per_01.age, offsetof(struct persion, age)); printk("per_01.name = %p, offset(name) = %ld", per_01.name, offsetof(struct persion, name));
while (1) { ; }
return 0; } |
运行结果:
| main: sizeof(per_01) = 15
main: &per_01.sex = 0xbfc2480c, offset(sex) = 0 main: &per_01.age = 0xbfc2480d, offset(age) = 1 main: per_01.name = 0xbfc24811, offset(name) = 5
|
通过分析打印的地址信息,是可以知道,编译器并没有做内存上的对齐优化。
内存排布图示(数据成员没有对齐,也没有填充),没按实际的来画,但是分布规律相同。
4. 和字节对齐相关的预处理指令
成对使用:告诉编译器,按照N个字节对齐。
| #pragma pack(N) //N字节对齐 ……………………… #pragma pack() //取消N字节对齐
|
示例程序:
| #if 0 /* 两种一样的情况 */ struct persion { char sex; int age; char name[10]; }__attribute__ ((packed)); #else
#pragma pack(1) struct persion { char sex; int age; char name[10]; };
#pragma pack()
#endif
struct persion per_01;
int main(void) { printk("sizeof(per_01) = %ld\n", sizeof(per_01)); printk("&per_01.sex = %p, offset(sex) = %ld", &per_01.sex, offsetof(struct persion, sex)); printk("&per_01.age = %p, offset(age) = %ld", &per_01.age, offsetof(struct persion, age)); printk("per_01.name = %p, offset(name) = %ld", per_01.name, offsetof(struct persion, name));
while (1) { ; }
return 0; }
|
运行结果:
| main: sizeof(per_01) = 15 main: &per_01.sex = 0xbfc2480c, offset(sex) = 0 main: &per_01.age = 0xbfc2480d, offset(age) = 1 main: per_01.name = 0xbfc24811, offset(name) = 5 |
注意:和使用参数__aligned__(1)的区别[是否存在最大长度大于1的数据成员]。
5. 定义结构体类型时如何节省空间
一般性的原则是:相同类型的要靠到一起(在定义的时候,可以做简单的计算)。
例子1:32位的CPU,默认是4字节对齐。
| struct dat_type_01 { char dat_a; int dat_c; short dat_b; };
struct dat_type_02 { int dat_c; char dat_a; short dat_b; };
struct dat_type_01 dat_01; struct dat_type_02 dat_02;
int main(void) { printk("sizeof(per_01) = %ld", sizeof(dat_01)); printk("&dat_01.dat_a = %p, offset(dat_a) = %ld", &dat_01.dat_a, offsetof(struct dat_type_01, dat_a)); printk("&dat_01.dat_b = %p, offset(dat_b) = %ld", &dat_01.dat_b, offsetof(struct dat_type_01, dat_b)); printk("&dat_01.dat_c = %p, offset(dat_c) = %ld", &dat_01.dat_c, offsetof(struct dat_type_01, dat_c)); printk ("***********************************************");
printk ("sizeof(dat_02) = %ld", sizeof(dat_02));
printk("&dat_02.dat_c = %p, offset(dat_c) = %ld", &dat_02.dat_c, offsetof(struct dat_type_02, dat_c)); printk("&dat_02.dat_a = %p, offset(dat_a) = %ld", &dat_02.dat_a, offsetof(struct dat_type_02, dat_a)); printk("&dat_02.dat_b = %p, offset(dat_b) = %ld", &dat_02.dat_b, offsetof(struct dat_type_02, dat_b));
while (1) { ; }
return 0; } |
运行结果:
| main: sizeof(per_01) = 12 main: &dat_01.dat_a = 0xbfc24814, offset(dat_a) = 0 main: &dat_01.dat_b = 0xbfc2481c, offset(dat_b) = 8 main: &dat_01.dat_c = 0xbfc24818, offset(dat_c) = 4 main: *********************************************** main: sizeof(dat_02) = 8 main: &dat_02.dat_c = 0xbfc2480c, offset(dat_c) = 0 main: &dat_02.dat_a = 0xbfc24810, offset(dat_a) = 4 main: &dat_02.dat_b = 0xbfc24812, offset(dat_b) = 6 |
注:数据成员的排序,影响到内存排布。第一种情况,填充了5个空字符,而第二种情况,只填充了1个空字符。
| 0 1 2 3 4 5 6 7 8 9 10 11 char int short
0 1 2 3 4 5 6 7 int char short |
6. 什么是显示提醒
程序中,补上char类型的数据,起到提醒的作用,所以子啊源码中,一般都是用”reserved”做标识符,reserved译为”保留的”,在项目源码中定义的结构体经常碰到。实际上,可以不用补上,编译器会自动分配出空间,也就是填充空间。
示例程序:32位CPU,默认4字节对齐。
| struct dat_type_01 { char dat_a; int dat_c; short dat_b; };
struct dat_type_02 { char dat_a; char reserved_array_01[3]; int dat_c; short dat_b; char reserved_array_02[2]; };
struct dat_type_01 dat_01; struct dat_type_02 dat_02;
int main(void) { printk("sizeof(per_01) = %ld", sizeof(dat_01)); printk("&dat_01.dat_a = %p, offset(dat_a) = %ld", &dat_01.dat_a, offsetof(struct dat_type_01, dat_a)); printk("&dat_01.dat_b = %p, offset(dat_b) = %ld", &dat_01.dat_b, offsetof(struct dat_type_01, dat_b)); printk("&dat_01.dat_c = %p, offset(dat_c) = %ld", &dat_01.dat_c, offsetof(struct dat_type_01, dat_c)); printk("***********************************************");
printk("sizeof(dat_02) = %ld", sizeof(dat_02)); printk("&dat_02.dat_a = %p, offset(dat_a) = %ld", &dat_02.dat_a, offsetof(struct dat_type_02, dat_a)); printk("&dat_02.dat_b = %p, offset(dat_b) = %ld", &dat_02.dat_b, offsetof(struct dat_type_02, dat_b)); printk("&dat_02.dat_c = %p, offset(dat_c) = %ld", &dat_02.dat_c, offsetof(struct dat_type_02, dat_c));
while (1) { ; }
return 0; } |
运行结果:
| main: sizeof(per_01) = 12 main: &dat_01.dat_a = 0xbfc24818, offset(dat_a) = 0 main: &dat_01.dat_b = 0xbfc24820, offset(dat_b) = 8 main: &dat_01.dat_c = 0xbfc2481c, offset(dat_c) = 4 main: *********************************************** main: sizeof(dat_02) = 12 main: &dat_02.dat_a = 0xbfc2480c, offset(dat_a) = 0 main: &dat_02.dat_b = 0xbfc24814, offset(dat_b) = 8 main: &dat_02.dat_c = 0xbfc24810, offset(dat_c) = 4 |
7. 结构体的数据成员是连续存放的吗
不一定,取决于:(1)结构体类型的定义情况 (2)内存字节对齐情况。
8. 小结
(1) 对于结构体,首先考虑的是每个数据成员的自然对其,其次,是整个结构体长度的对齐。最好是画个示意图,能更清楚地分析内存排布情况。
(2) 一般来说,对齐的事交给编译器就好了。