北京大气污染PM2.5预测(LSTM)
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
data = pd.read_excel('./北京空气_2010.1.1-2014.12.31.xlsx')
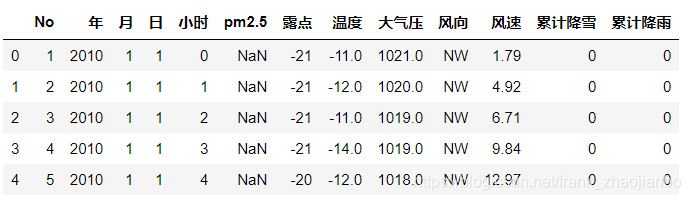
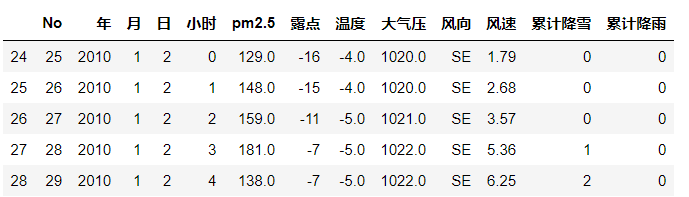
数据处理:把PM2.5 为null的数据都用相邻的数据填充,我们取2010年1月2日以后的数据。
data = data.iloc[24:].fillna(method = 'ffill')
把年,月,日 和小时 合并为一列。
import datetime
data['时间'] = data.apply(lambda x: datetime.datetime(year=x['年'],month =x['月'],day = x['日'],hour = x['小时']),axis = 1)
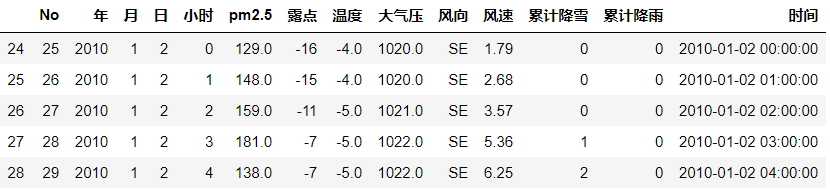
去掉 年,月,日 和小时,并且把 时间列 作为索引index
data.drop(columns=['No','年','月','日','小时'],inplace = True)
data = data.set_index('时间')
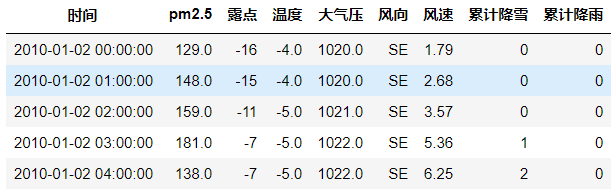
One-hot 编码 风向序列
data = data.join(pd.get_dummies(data.风向))
del data['风向']
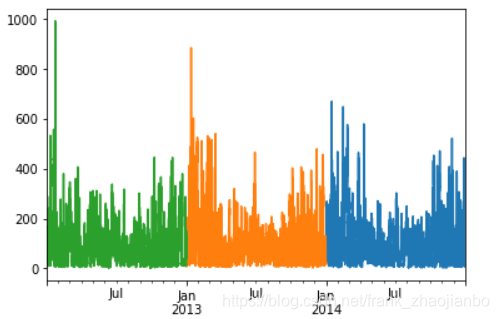
查看2012年到2014年的
data['pm2.5'][-365*24:].plot()
data['pm2.5'][-365*24*2:-365*24].plot()
data['pm2.5'][-365*24*3:-365*24*2].plot()
用前6天的数据预测第7天的大气PM2.5
sequence_length = 6*24
delay = 24
data_ = []
for i in range(len(data) - sequence_length - delay):data_.append(data.iloc[i: i + sequence_length + delay])
data_ = np.array([df.values for df in data_])
np.random.shuffle(data_)
x = data_[:, :-delay, :]
y = data_[:, -1, 0]
把数据的80%分成训练集合,20%分为测试集合。
split_boundary = int(data_.shape[0] * 0.8)
train_x = x[: split_boundary]
test_x = x[split_boundary:]train_y = y[: split_boundary]
test_y = y[split_boundary:]
对数据进行归一化操作
mean = train_x.mean(axis=0) #均值
std = train_x.std(axis=0) #标准差
train_x = (train_x - mean)/std
test_x = (test_x - mean)/std
定义模型
model_m = keras.Sequential()
model_m.add(layers.LSTM(32, input_shape=(train_x.shape[1:]), return_sequences=True))
model_m.add(layers.LSTM(32, return_sequences=True))
model_m.add(layers.LSTM(32))
model_m.add(layers.Dense(1))model_m.compile(optimizer=keras.optimizers.Adam(), loss='mae')
learning_rate_reduction = keras.callbacks.ReduceLROnPlateau(monitor='val_loss', patience=3, factor=0.5, min_lr=0.00001)
训练模型
history = model_m.fit(train_x, train_y,batch_size = 128,epochs=200,validation_data=(test_x, test_y),callbacks=[learning_rate_reduction])
保存模型
model_m.save("MULTI_LAYERS_LSTM.h5")
测试模型准确度
data_test = data[-24*6:]
data_test = (data_test - mean)/std
data_test = data_test.to_numpy()
data_test = np.expand_dims(data_test,0)
pm = model_m.predict(data_test)
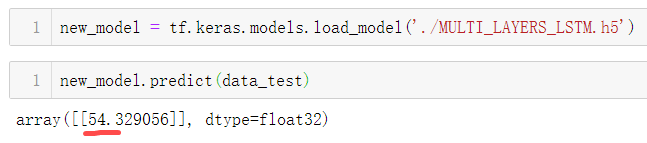
根据历史数据可知道 北京在2015年1月1日 24时,也就是2015年1月2日 0时的PM2.5 值为 51,我们预测的值为54.329.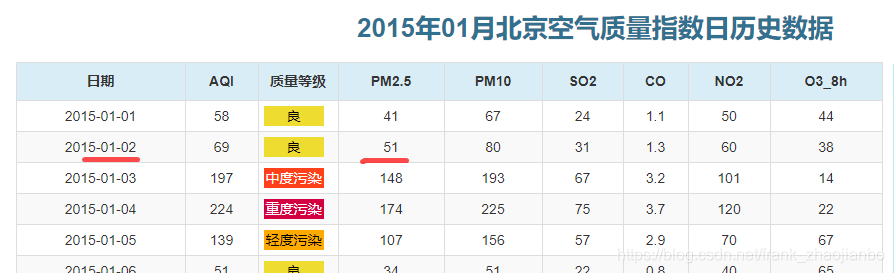
https://www.aqistudy.cn/historydata/daydata.php?city=%E5%8C%97%E4%BA%AC&month=2015-01
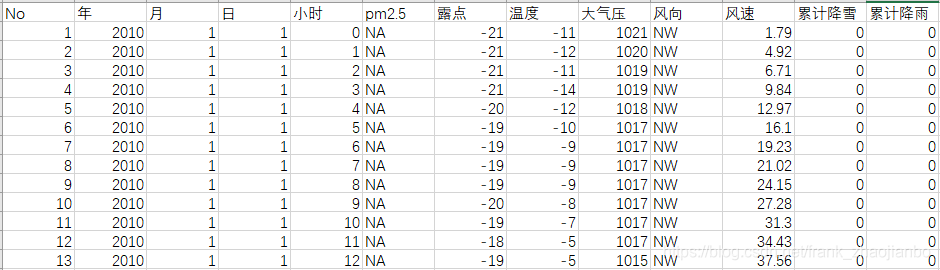
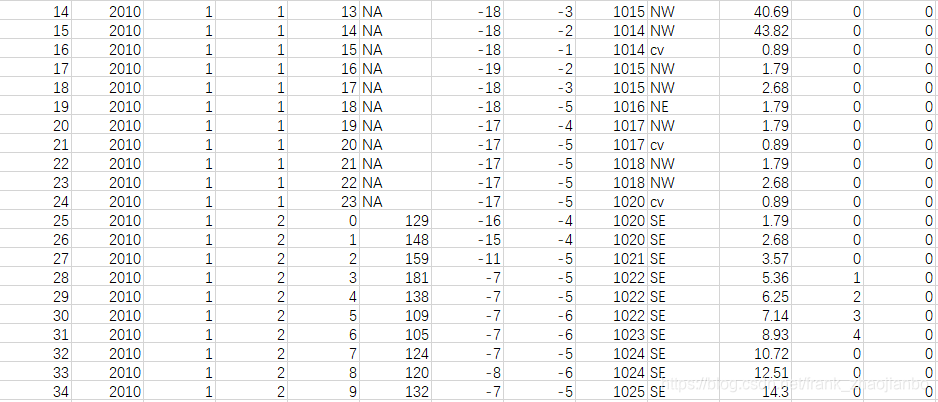
部分数据集