容器化应用的救命稻草:K3s 备份和恢复中文指南
公众号关注 「奇妙的 Linux 世界」
设为「星标」,每天带你玩转 Linux !

在容器化应用的开发和部署过程中,Kubernetes 已经成为了主流的容器编排工具。然而,传统的 K8s 集群部署往往需要大量的资源和配置,对于小型团队或资源有限的个人开发者来说可能过于庞大和复杂。这时,K3s 作为一个轻量级的 Kubernetes 发行版,以其简单易用的特性逐渐崭露头角。
在 K3s 的使用过程中,备份和恢复是不可忽视的关键环节。正常的运维操作中,我们可能会面临节点故障、意外删除或错误配置等情况,这些都有可能导致应用的中断和数据的丢失。因此,掌握 K3s 的备份和恢复方法,可以有效地保障容器化应用的安全与稳定。
本文将介绍如何进行 K3s 集群的备份和恢复操作,并提供一些实用的技巧和建议。
K3s 数据存储类型
除了需要备份数据存储本身,还必须备份位于
/var/lib/rancher/k3s/server/token的 Server Token 文件。使用备份进行恢复时,你必须恢复此文件,或将 token 的值传递给--token选项。由于 Token 用于加密数据存储内的凭证数据,因此如果还原时没有使用相同的 Token 值,快照将无法使用。在文章末尾,介绍的灾难恢复场景中会用到 token 文件,也体现了备份 token 文件的重要性。
K3s 的备份和恢复方式取决于你使用的数据存储类型。根据不同的 K3s 安装方式,对应的数据存储类型也不同。
如果你采用的是默认(单节点,集群中只允许一个 master 节点)安装方式,K3s 数据存储采取嵌入式 SQLite 数据存储方案
如果你采用外部数据库实现 K3s 的高可用安装,K3s 的数据将存储在外部的数据库中
如果你采用嵌入式 etcd 实现 K3s 的高可用安装,那 K3s 数据将存储在由 K3s 启动的嵌入式 etcd 中
所以针对不同的数据存储类型,采取的备份和恢复方式也不同,本文将将详细介绍这三种数据存储类型如何备份和恢复。
使用嵌入式 SQLite 数据存储进行备份和恢复
K3s 内置了 SQLite 作为单节点模式下的数据库,这种模式下,K3s 启动之后会将数据存储在主机上的 /var/lib/rancher/k3s/server/db 目录中,所以只需针对这个目录进行备份和恢复即可。
备份
cp -rf /var/lib/rancher/k3s/server/db /opt/db恢复
systemctl stop k3s
rm -rf /var/lib/rancher/k3s/server/db
cp -rf /opt/db /var/lib/rancher/k3s/server/db
systemctl start k3s使用外部数据存储进行备份和恢复
当使用外部数据存储时,备份和恢复操作是在 K3s 之外处理的。对于 K3s 来说,只需要在数据库恢复之后,重启 K3s 服务即可。
K3s 支持 etcd、MySQL、MariaDB、PostgreSQL 作为外部数据存储的数据库,本示例使用 MySQL 作为示例来演示备份和恢复。
备份
mysqldump -uroot -p --all-databases --master-data > k3s-dbdump.db恢复
停止 K3s 服务:
systemctl stop k3s恢复 mysql 数据:
mysql -uroot -p < k3s-dbdump.db启动 K3s 服务:
systemctl start k3s使用嵌入式 etcd 数据存储进行备份和恢复
在本节中,你将学习如何创建 K3s 嵌入式 etcd 数据存储的备份,以及如何使用备份恢复集群。
创建快照
默认情况下,K3s 会在 00:00 和 12:00 自动创建快照,并保留 5 个快照。当然,你也可以禁用自动快照或者通过 k3s etcd-snapshot save 来手动创建快照。
快照目录默认为 ${data-dir}/server/db/snapshots。data-dir 的默认值为 /var/lib/rancher/k3s,你可以通过设置 --data-dir 标志来更改。
从快照恢复集群
当 K3s 从备份中恢复时,旧的数据目录将被移动到 ${data-dir}/server/db/etcd-old/。然后 K3s 将尝试通过创建一个新的数据目录来恢复快照,最后使用具有一个 etcd 成员的新 K3s 集群启动 etcd。
在此示例中有 3 个 K3s Server 节点,分别是 S1、S2和 S3,快照位于 S1 上:
在 S1 上,使用
--cluster-reset选项运行 K3s,同时指定--cluster-reset-restore-path:
ls /var/lib/rancher/k3s/server/db/snapshots/
on-demand-ip-172-31-3-36-1688025329systemctl stop k3sk3s server \--cluster-reset \--cluster-reset-restore-path=/var/lib/rancher/k3s/server/db/snapshots/on-demand-ip-172-31-3-36-1688025329在
S2和S3上,停止 K3s。然后删除数据目录/var/lib/rancher/k3s/server/db/:
systemctl stop k3s
rm -rf /var/lib/rancher/k3s/server/db/在
S1上,再次启动 K3s:
systemctl start k3sS1启动成功后,在S2和S3上,再次启动 K3s 以加入恢复后的集群:
systemctl start k3sS2 和 S3 虽然使用空的数据目录来启动 K3s 服务,但启动时会自动到 S1 去同步数据,从而完成 S2 和 S3 的恢复。
另外,k3s etcd-snapshot 子命令支持 S3 兼容的 API,这样我们可以将快照自动或手动的上传到 S3 中存储,并且用于 K3s 的数据恢复。
K3s 集群的灾难恢复
在介绍不同数据存储类型下的备份和恢复方法后,我们需要意识到这些方法仅适用于集群正常运行且所有的 K3s 文件和数据都存在的情况。然而,在许多灾难情况下(如 K3s 主机故障导致无法启动),我们需要进行更全面的备份和恢复。
为了展示更完善的备份和恢复方案,本节将演示使用 K3s 备份重新搭建 K3s 集群。为方便起见,我们采用单节点 K3s 安装模式,并安装了两个节点的 K3s 集群。其中,主机ip-172-31-3-36 为 K3s server 节点,ip-172-31-6-61 为 K3s agent 节点。我们成功部署了一个 Nginx Deployment 作为测试数据。安装完成后的环境如下所示:
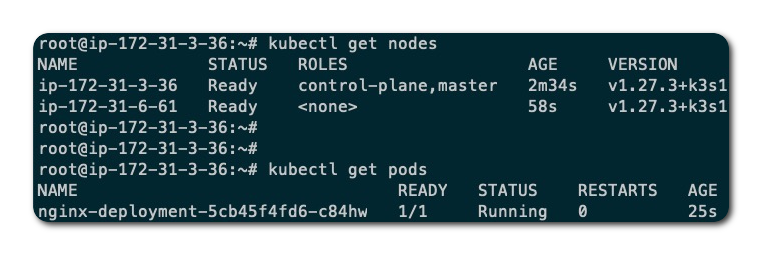
备份数据
在 ip-172-31-3-36 节点分别备份 SQLite 数据文件和 token 文件:

卸载 K3s server 和 agent
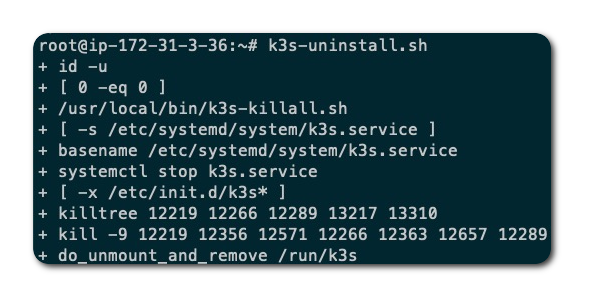
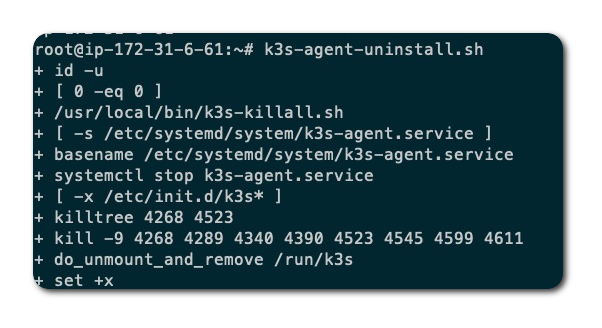
恢复 K3s server 和 agent
在 ip-172-31-3-36 节点恢复 SQLite 数据文件和 token 文件,然后根据备份的文件重新安装 K3s server:
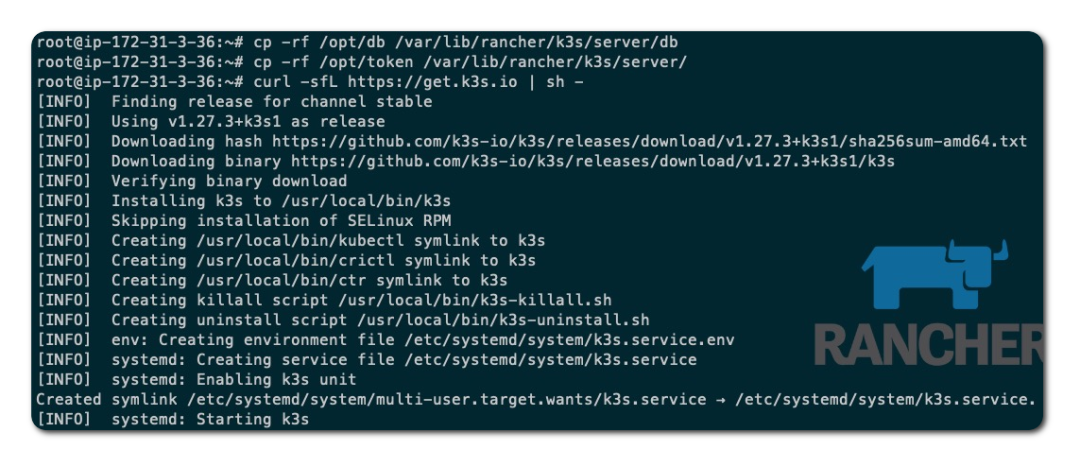
在 ip-172-31-6-61 节点执行加入 K3s 集群的命令:
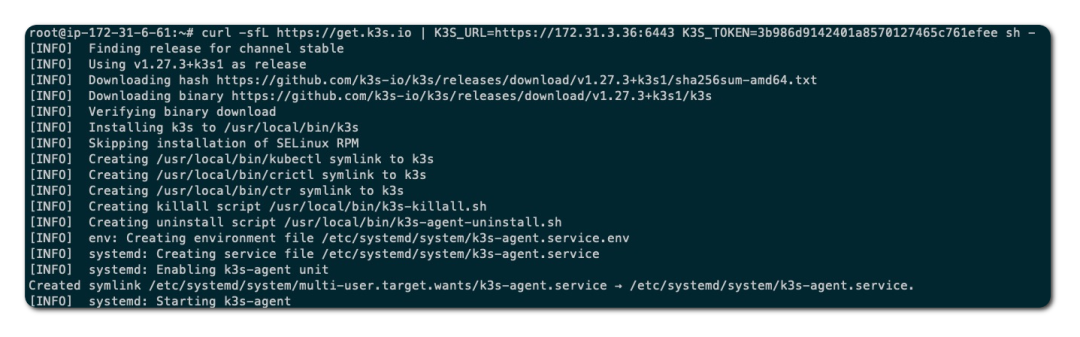
验证
当使用备份的数据文件和 token 文件重新安装 K3s 集群后,数据又恢复到了卸载之前:
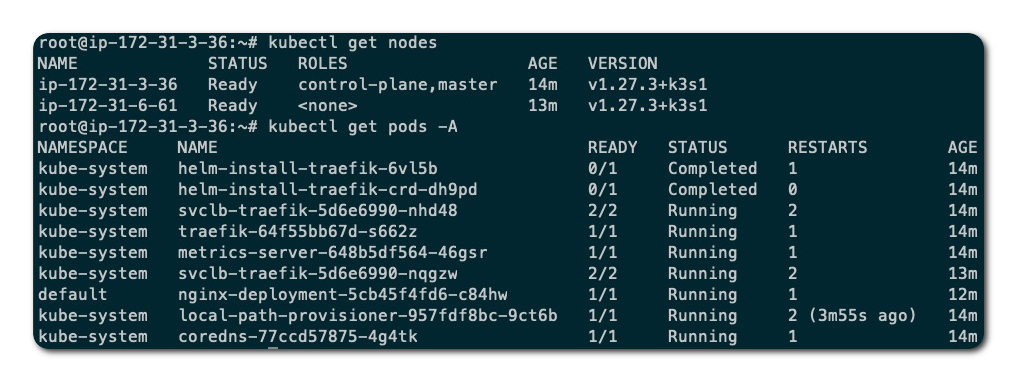
虽然只演示了单节点模式的灾难恢复,使用外部数据库和嵌入式 etcd 存储类型基本也大同小异。
总结
通过本文的指导,读者将能够全面了解 K3s 的备份和恢复操作,并能够根据自身需求制定适合的备份策略。这将有助于保障容器化应用的安全性和可靠性,提升开发和运维效率。无论是个人开发者还是小型团队,都可以轻松应对 K3s 备份和恢复的挑战,确保应用的安全运行。
本文转载自:「边缘计算k3s社区」,原文:https://url.hi-linux.com/36b35,版权归原作者所有。欢迎投稿,投稿邮箱: editor@hi-linux.com。

最近,我们建立了一个技术交流微信群。目前群里已加入了不少行业内的大神,有兴趣的同学可以加入和我们一起交流技术,在 「奇妙的 Linux 世界」 公众号直接回复 「加群」 邀请你入群。

你可能还喜欢
点击下方图片即可阅读

LazyVim: 又一个 Vim 使用者的福音
点击上方图片,『美团|饿了么』外卖红包天天免费领

更多有趣的互联网新鲜事,关注「奇妙的互联网」视频号全了解!