PyTorch——损失函数与反向传播(8)
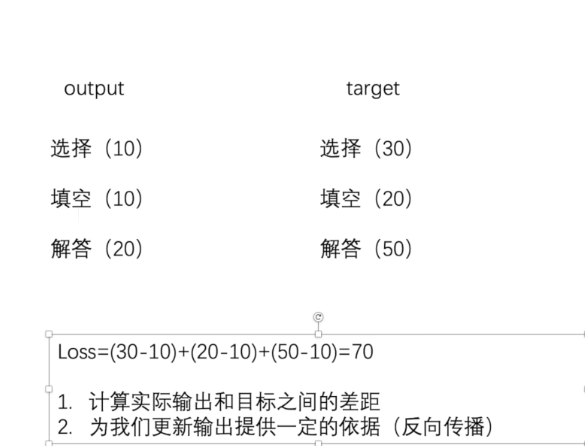
Loss Functions 越小越好
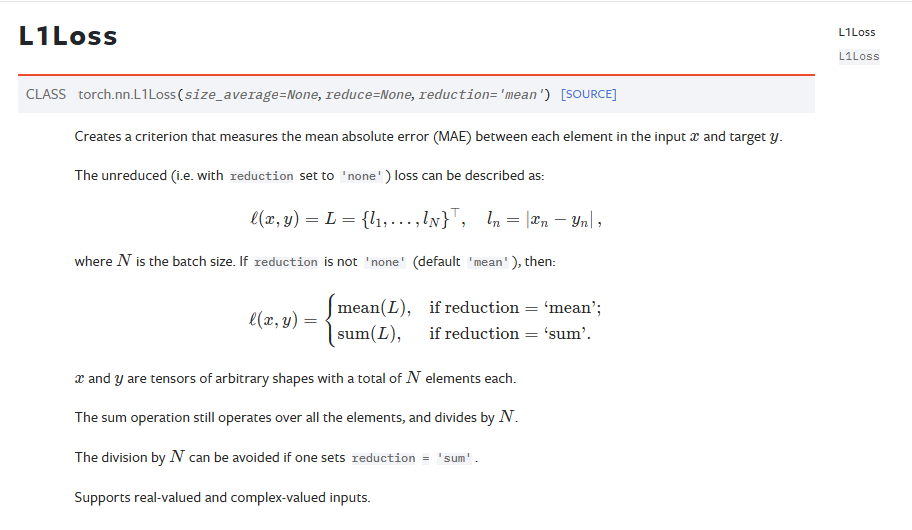
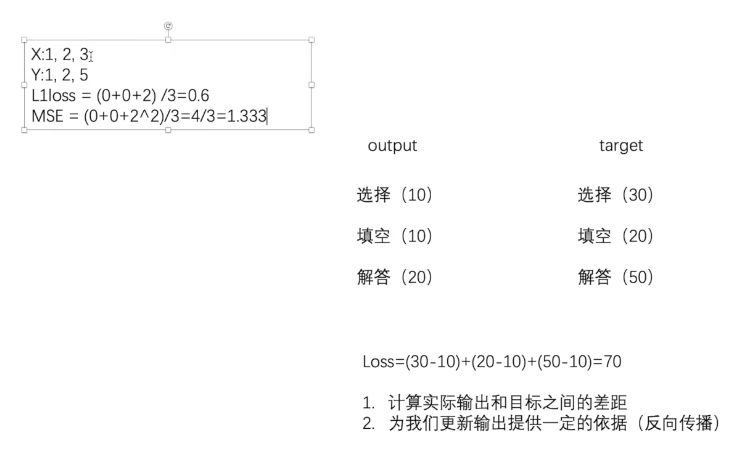
L1loss

MSELoss 损失函数


CrossEntyopyLoss 损失函数
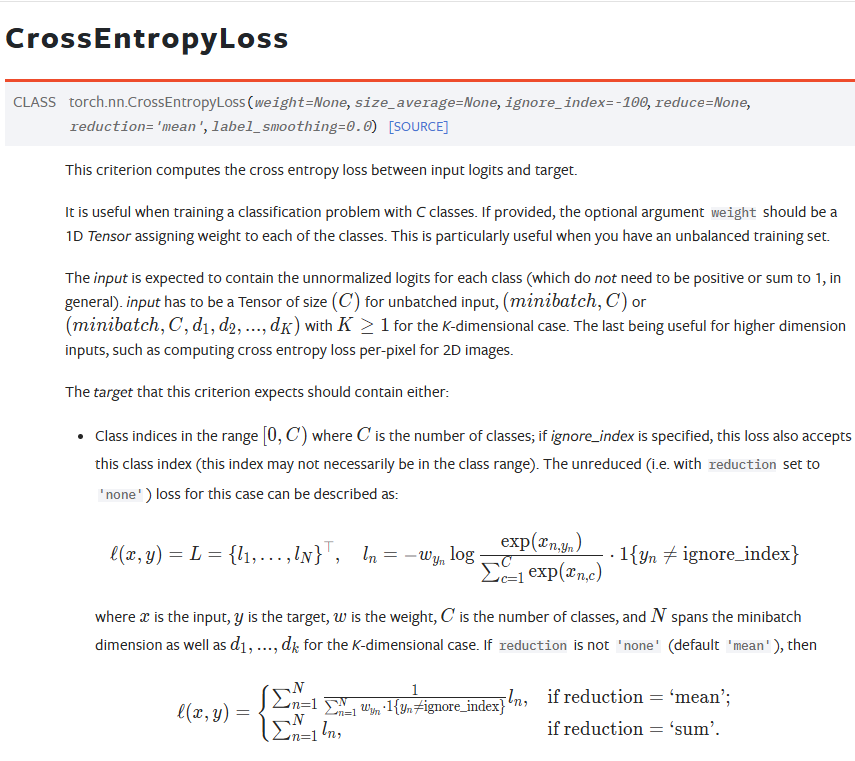

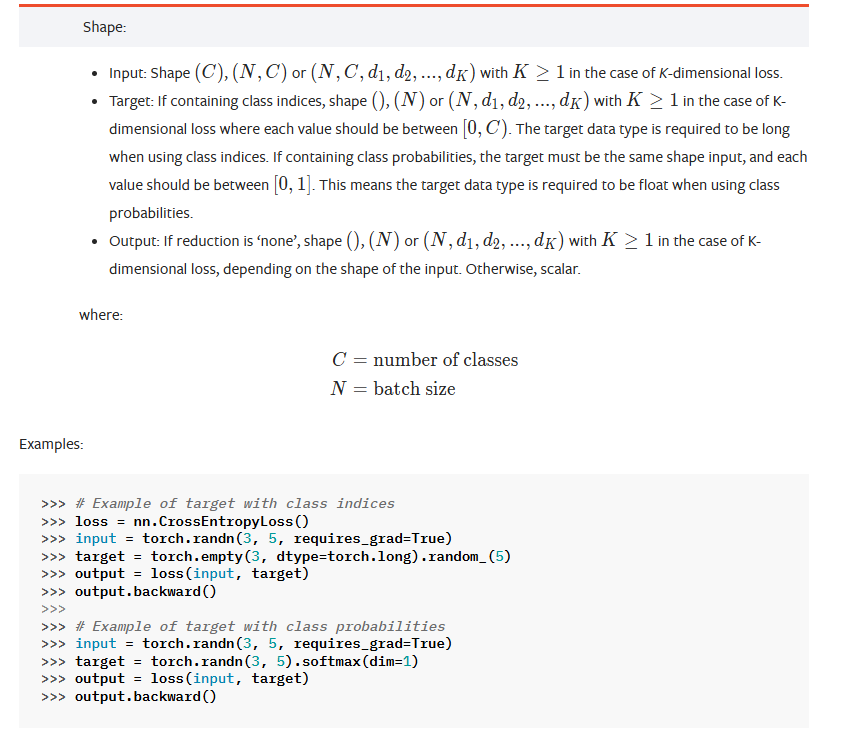
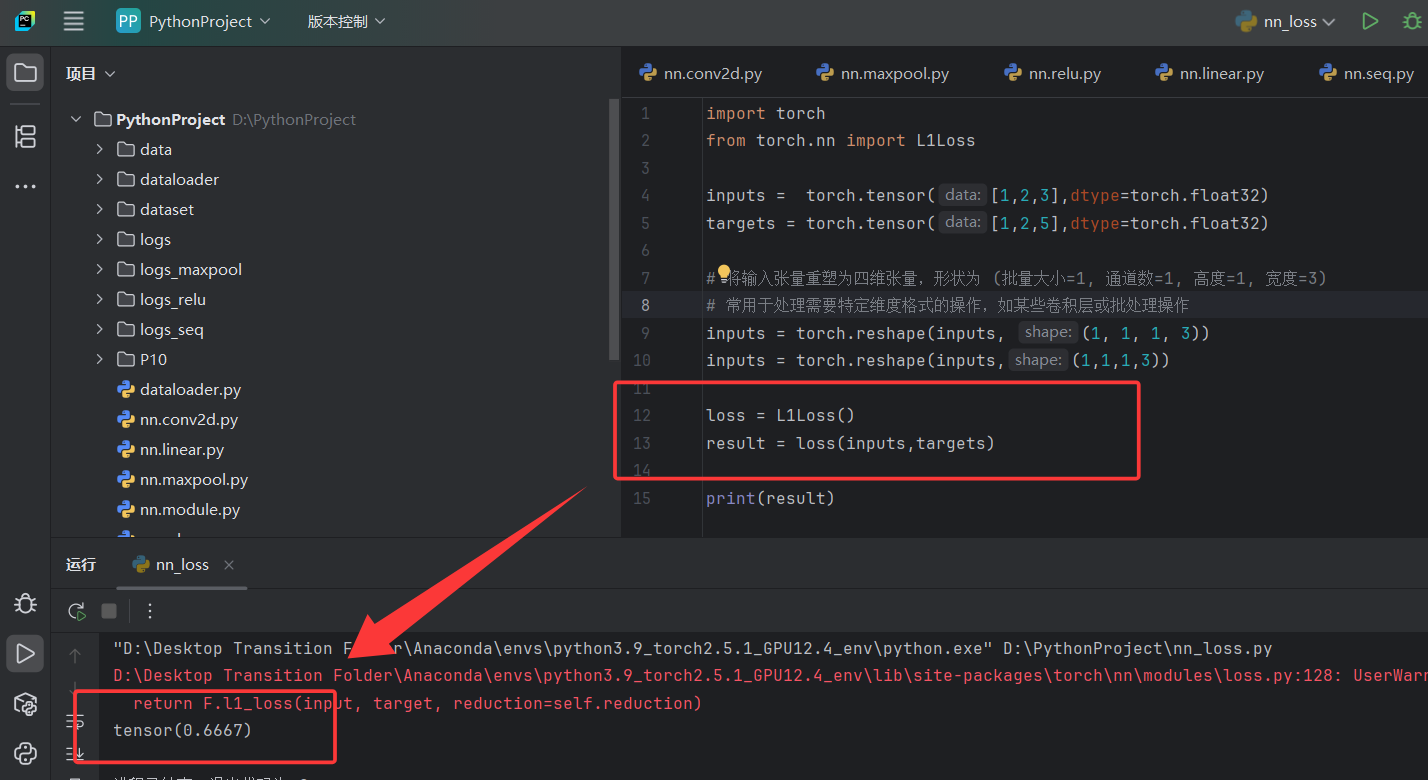
import torch
from torch.nn import L1Loss
from torch import nn# 创建输入和目标张量,用于后续的损失计算
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)# 将输入张量重塑为四维张量,形状为 (批量大小=1, 通道数=1, 高度=1, 宽度=3)
# 这一操作是为了满足某些损失函数对输入维度的要求
# 例如在图像任务中,数据通常以四维张量形式存在
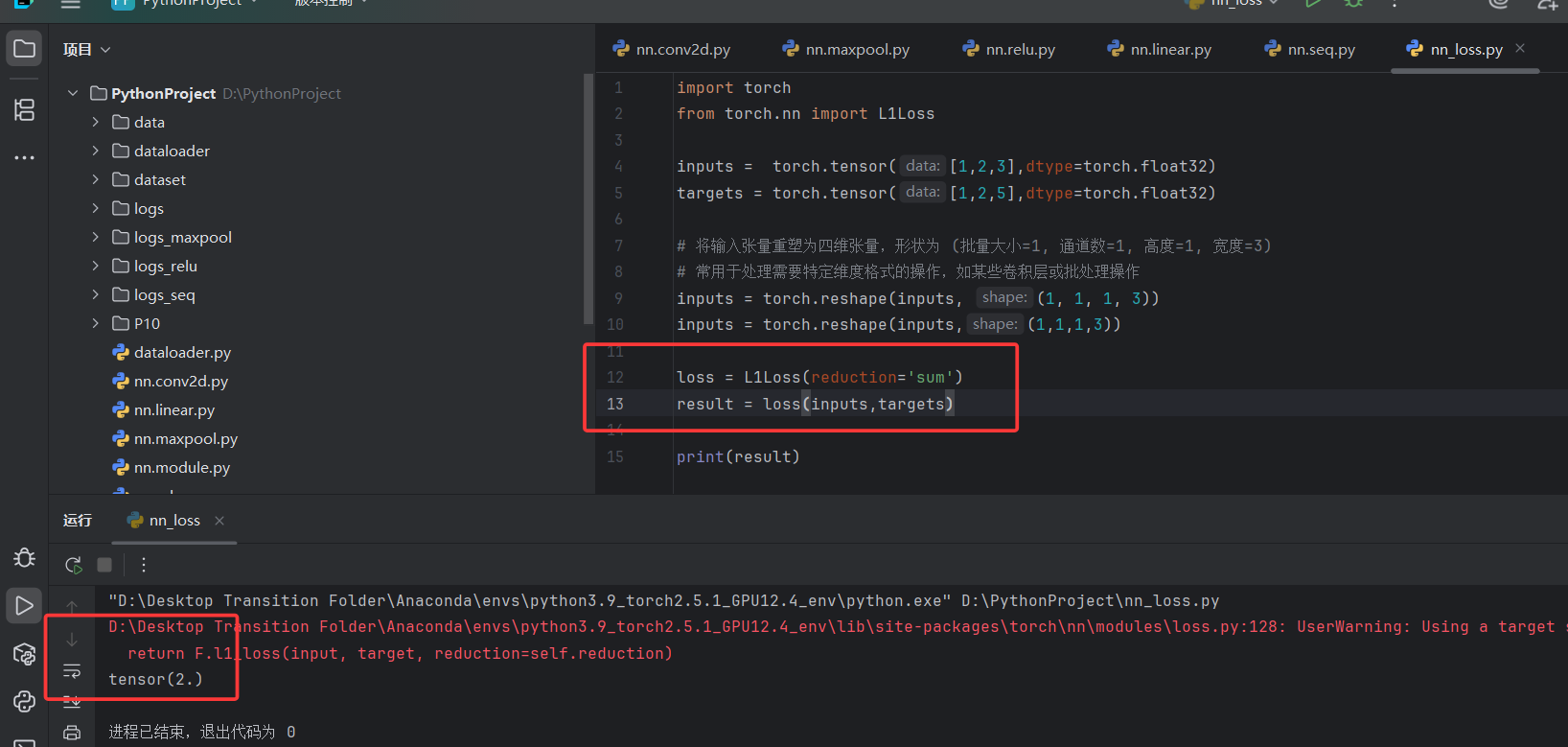
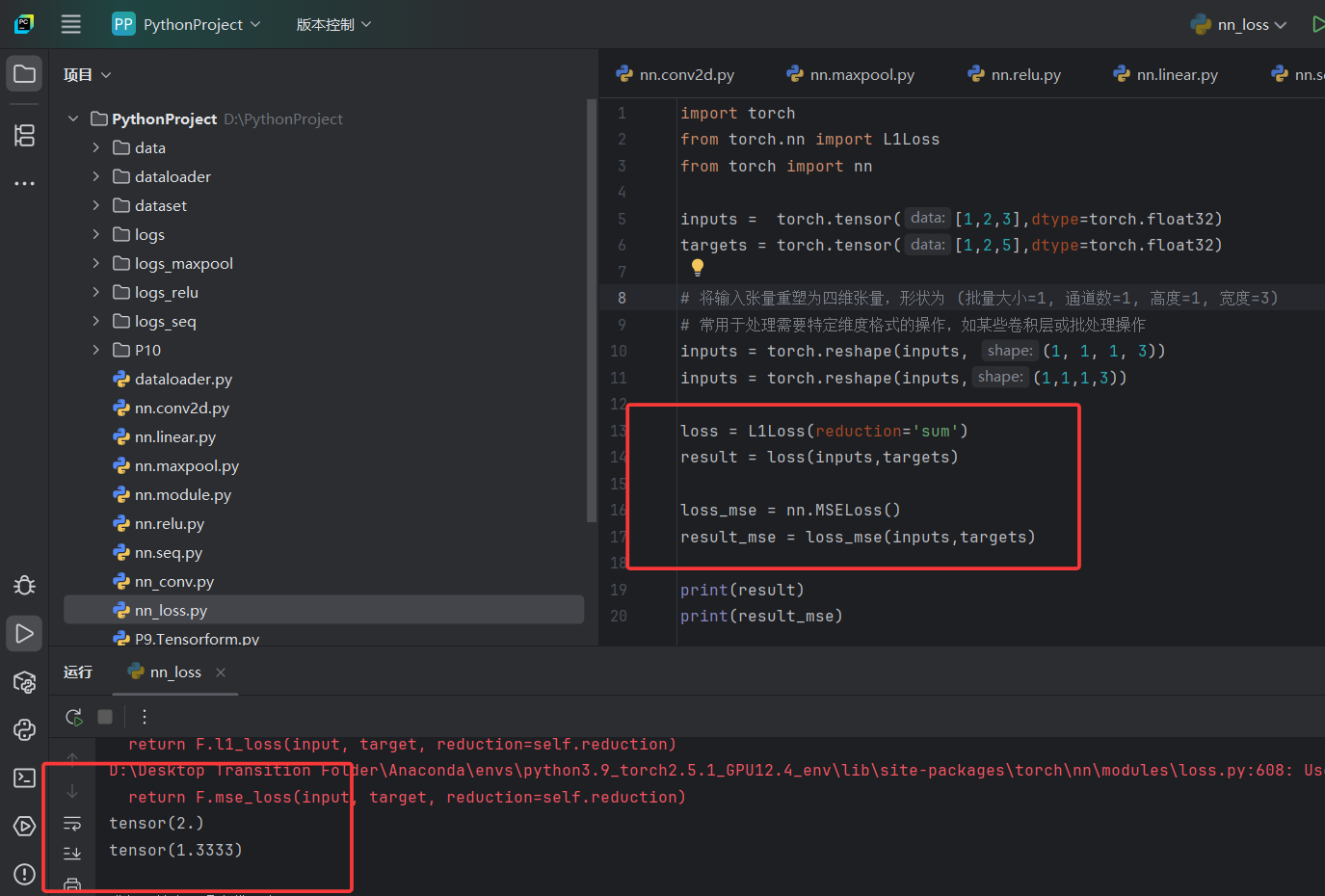
inputs = torch.reshape(inputs, (1, 1, 1, 3))# 计算L1损失(平均绝对误差),使用sum reduction策略
# 这里会计算每个对应元素的绝对差,然后求和得到总损失
loss = L1Loss(reduction='sum')
result = loss(inputs, targets)# 计算MSE损失(均方误差)
# 计算每个对应元素的平方差的平均值
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets)print(f"L1 Loss (Sum): {result}") # 输出L1损失结果
print(f"MSE Loss: {result_mse}") # 输出MSE损失结果# 创建用于交叉熵损失计算的输入和目标
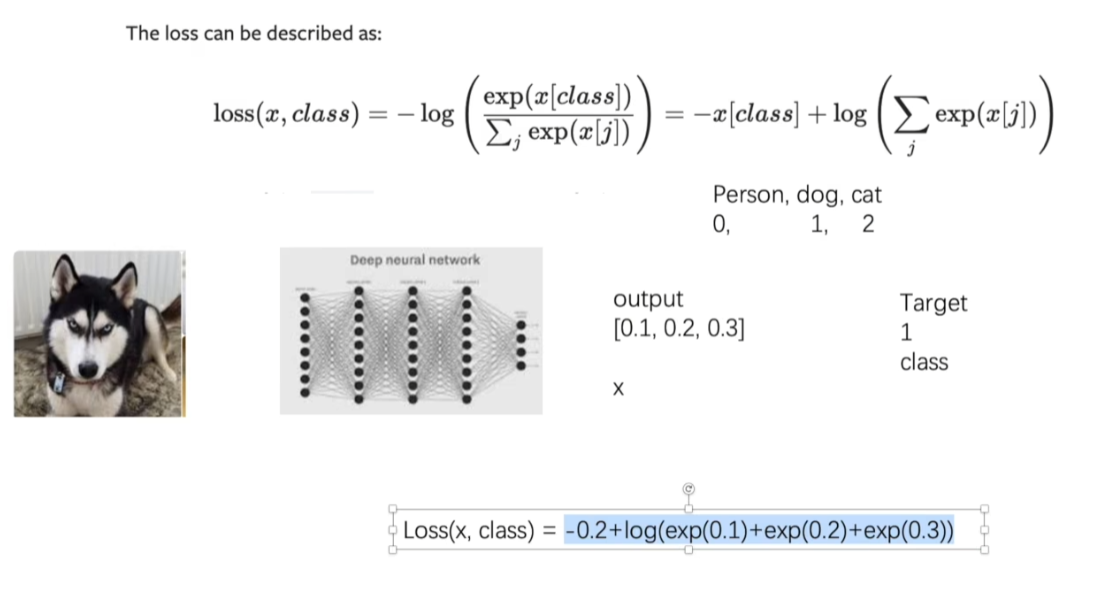
# 输入x表示三个类别的预测分数
# 目标y表示真实类别标签(这里是类别1)
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])# 将输入x重塑为形状(1, 3),表示批量大小为1,有3个类别
x = torch.reshape(x, (1, 3))# 计算交叉熵损失
# 交叉熵损失结合了softmax激活和负对数似然损失
# 它衡量的是预测概率分布与真实分布之间的差异
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)print(f"Cross Entropy Loss: {result_cross}") # 输出交叉熵损失结果
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader# 加载CIFAR10测试数据集,将图像转换为Tensor格式
dataset = torchvision.datasets.CIFAR10("./data", train=False, transform=torchvision.transforms.ToTensor(),download=True)
# 创建数据加载器,设置批量大小为64
dataloader = DataLoader(dataset, batch_size=64)# 定义一个名为TY的神经网络模型类
class TY(nn.Module):def __init__(self):super(TY, self).__init__()# 定义神经网络结构self.model1 = Sequential(Conv2d(3, 32, 5, padding=2), # 卷积层:输入3通道,输出32通道,卷积核5x5,填充2MaxPool2d(2), # 最大池化层:池化窗口2x2Conv2d(32, 32, 5, padding=2), # 卷积层:输入32通道,输出32通道,卷积核5x5,填充2MaxPool2d(2), # 最大池化层Conv2d(32, 64, 5, padding=2), # 卷积层:输入32通道,输出64通道,卷积核5x5,填充2MaxPool2d(2), # 最大池化层Flatten(), # 将多维张量展平为一维向量Linear(1024, 64), # 全连接层:输入1024维,输出64维Linear(64, 10), # 全连接层:输入64维,输出10维(对应10个类别))def forward(self, x):# 定义数据在前向传播中的流动过程x = self.model1(x)return x# 定义交叉熵损失函数,用于多分类问题
loss = nn.CrossEntropyLoss()
# 实例化模型
ty = TY()
# 遍历数据加载器中的每个批次数据
for data in dataloader:# 获取图像数据和对应的标签imgs, targets = data# 将图像数据输入模型,得到预测结果outputs = ty(imgs)# 计算预测结果与真实标签之间的损失result_loss = loss(outputs, targets)# 打印每个批次的损失值print(result_loss)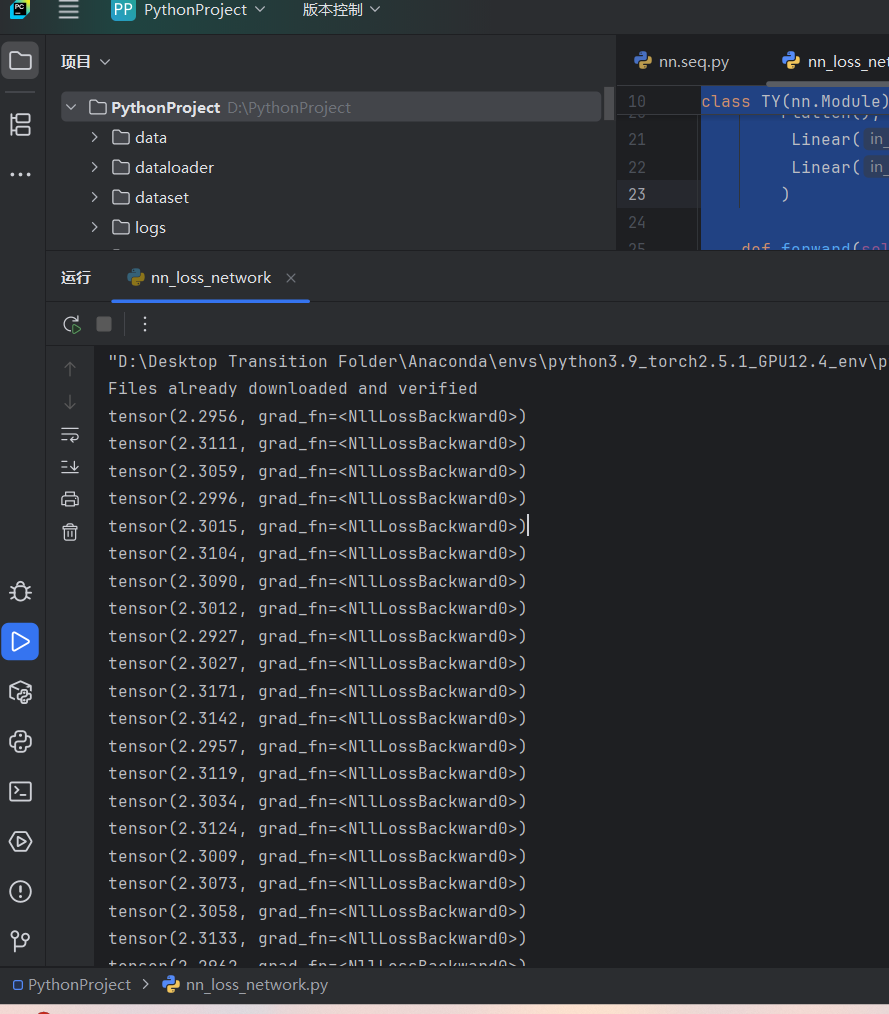

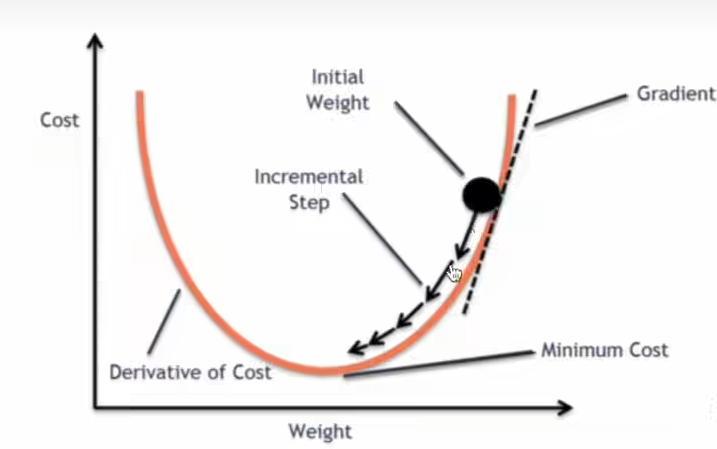
梯度下降 grad descent