STL解析——list的使用
目录
1.简介
2.构造函数
3.迭代器
3.1封装
3.2迭代器分类
4.排序性能
4.1链式与数组
4.2缓存读取
1.简介
STL容器中提供的list容器也是一种顺序容器,底层实现方式是带头双向链表,这种实现方式能比单链表更高效的访问数据。
下面围绕部分重要接口的使用展开讲解。
2.构造函数
list的构造函数提供了空初始化、元素个数初始化、迭代器区间初始化等

这里只需注意迭代器区间初始化除了使用list容器的迭代器区间,也可使用其他类迭代器区间。代码演示如下:
void list_test01()
{//空初始化list<int> lt1;for (auto e : lt1){cout << e << ' ';}cout << endl << endl;//元素个数(size)初始化list<int> lt2(10, 1);for (auto e : lt2){cout << e << ' ';}cout << endl << endl;//迭代器区间初始化list<int> lt3(lt2.begin(), lt2.end());for (auto e : lt3){cout << e << ' ';}cout << endl;int arr[] = { 0,1,2,3,4 };list<int> lt4(arr, arr + 5);for (auto e : lt4){cout << e << ' ';}cout << endl << endl;}打印结果如下: 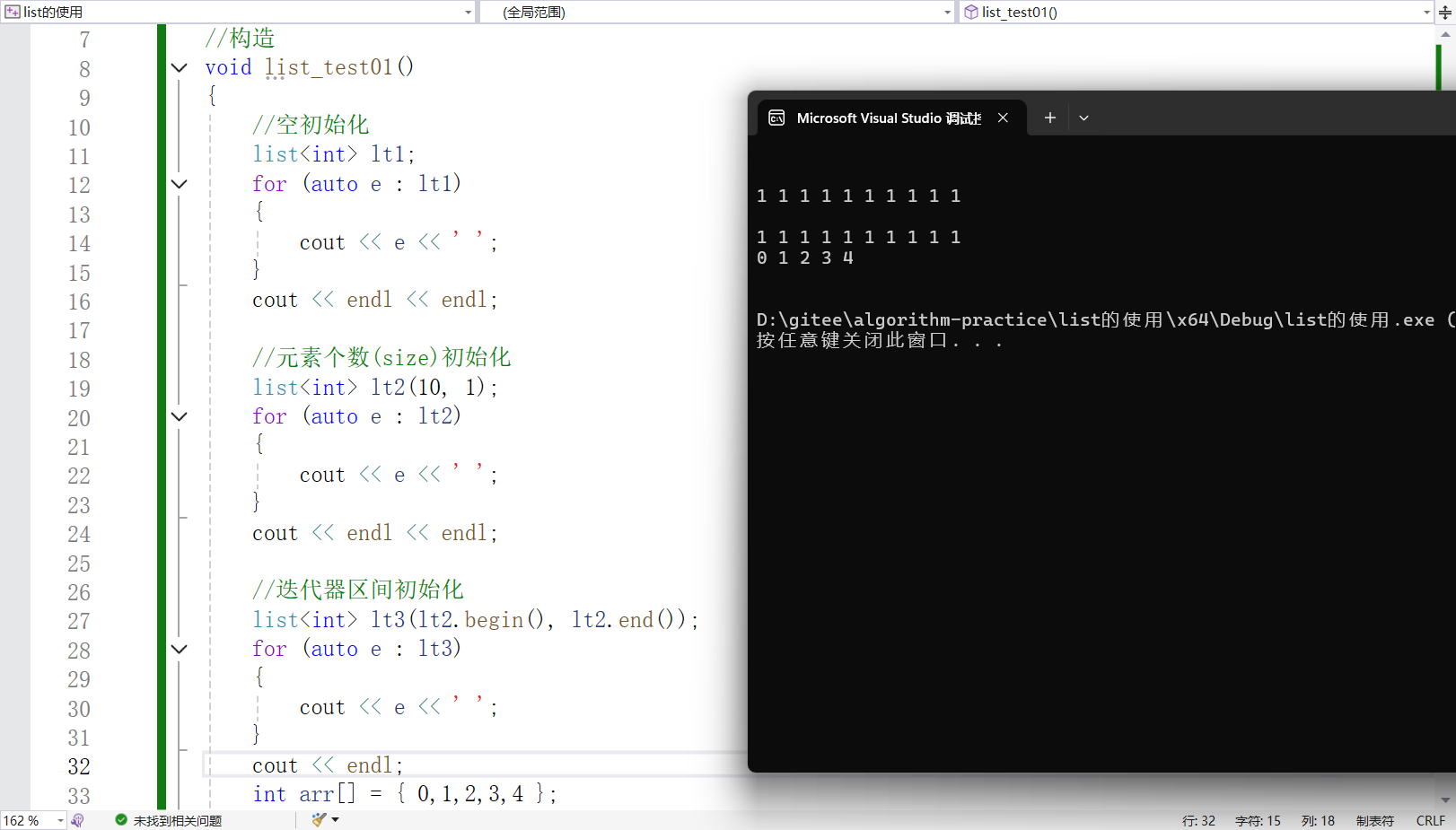
3.迭代器
3.1封装
之前我门在学习string和vector时,模拟实现的迭代器是一种指针,通过指针的加减和解引用能快速迭代容器内元素,但这仅是对string和vector底层仅是数组结构的迭代器实现方式。对于链表这种底层空间不连续的链式结构,通过指针是无法顺利迭代容器内元素的,但我们还是可以将迭代链表元素的方式封装成迭代器。
迭代器的功能是通过简单的加减和解引用方式来访问容器内元素,因此对于链表这种结构我们可以将迭代器创建为一种类,将访问链表的底层代码放入类中实现,再将迭代器类的运算符进行重载,进而封装成我们现在看到的迭代器。这种将底层复杂的方式抽象整合为一种统一的方式的思想,就体现了封装思想。
拿现实中例子举例,类似于移动支付未出现前的银行卡,各银行的底层识别方式不同,因此跨行操作及其不方便,但微信/支付宝的移动支付则是将这种底层识别封装为统一的支付款,减小了底层差异带来的影响。
拿list的迭代器区间初始化举例:
void list_test02()
{string s = "abcdef";vector<int> v1 = { 1,1,1,1,1,1,1 };list<int> l1 = { 0,0,0,0,0, };list<char> lt1(s.begin(), s.end());list<char> lt2(v1.begin(), v1.end());list<char> lt3(l1.begin(), l1.end());
}若没有封装迭代器,那么对于跨容器初始化我们需要对每种容器都进行实现方式,调用时及其不方便。但我们将各容器封装了迭代器,由此可进行统一的迭代器初始化。
3.2迭代器分类
在对之前文档进行查看时不难发现,不同函数的接口的迭代器名称不同:
像排序(sort)的随机迭代器

逆置(reverse)的双向迭代器

删除(remove)的单向迭代器

因此迭代器的分类大体如下:
(1)随机迭代器:随机迭代器的意思是能任意访问迭代器中任何位置,像vector和string底层为数组结构的迭代器就是随机迭代器。可以进行++,--,+,- 操作。
(2)双向迭代器:双向迭代器意思是可以向前或向后依次访问元素,但只能从一个数据访问到下一个或前一个数据,不能随意访问任意元素,像list这种双向链表就是双向迭代器。可以进行++和--。
(3)单向迭代器:只能向前依次访问数据,像数据结构中的单链表就是单向迭代器。只能进行++。

三种迭代器的关系类似功能继承,比如单向迭代器能用的地方双向迭代器也能用,而双向迭代器能用的地方,单向迭代器不一定能用。
以sort进行举例:
void list_test03()
{vector<int> v1 = { 10,2,3,5,1,9 };list<int> lt1 = { 10,2,3,5,1,9 };sort(v1.begin(), v1.end());sort(lt1.begin(), lt1.end());
}运行结果如下:

可以看到直接报错了。
4.排序性能
4.1链式与数组
list与vector都是顺序容器,list有自带的sort接口,vector排序主要使用函数库的sort函数,两个排序底层都是快排,按理来说两种容器的排序时间复杂度都是O(nlogn),但实际使用效率相同吗?根据下下面代码进行深入了解:
//排序效率
void list_test04()
{srand(time(0));const int N = 100000;list<int> lt1;vector<int> v;for (int i = 0; i < N; ++i){auto e = rand() + i;lt1.push_back(e);v.push_back(e);}int begin1 = clock();// 排序sort(v.begin(), v.end());int end1 = clock();int begin2 = clock();lt1.sort();int end2 = clock();printf("vector sort:%d\n", end1 - begin1);printf("list sort:%d\n", end2 - begin2);
}此代码最后会打印两种容器排序所需的实际时间(ms),运行(VS2022,X86,release环境)结果如下:
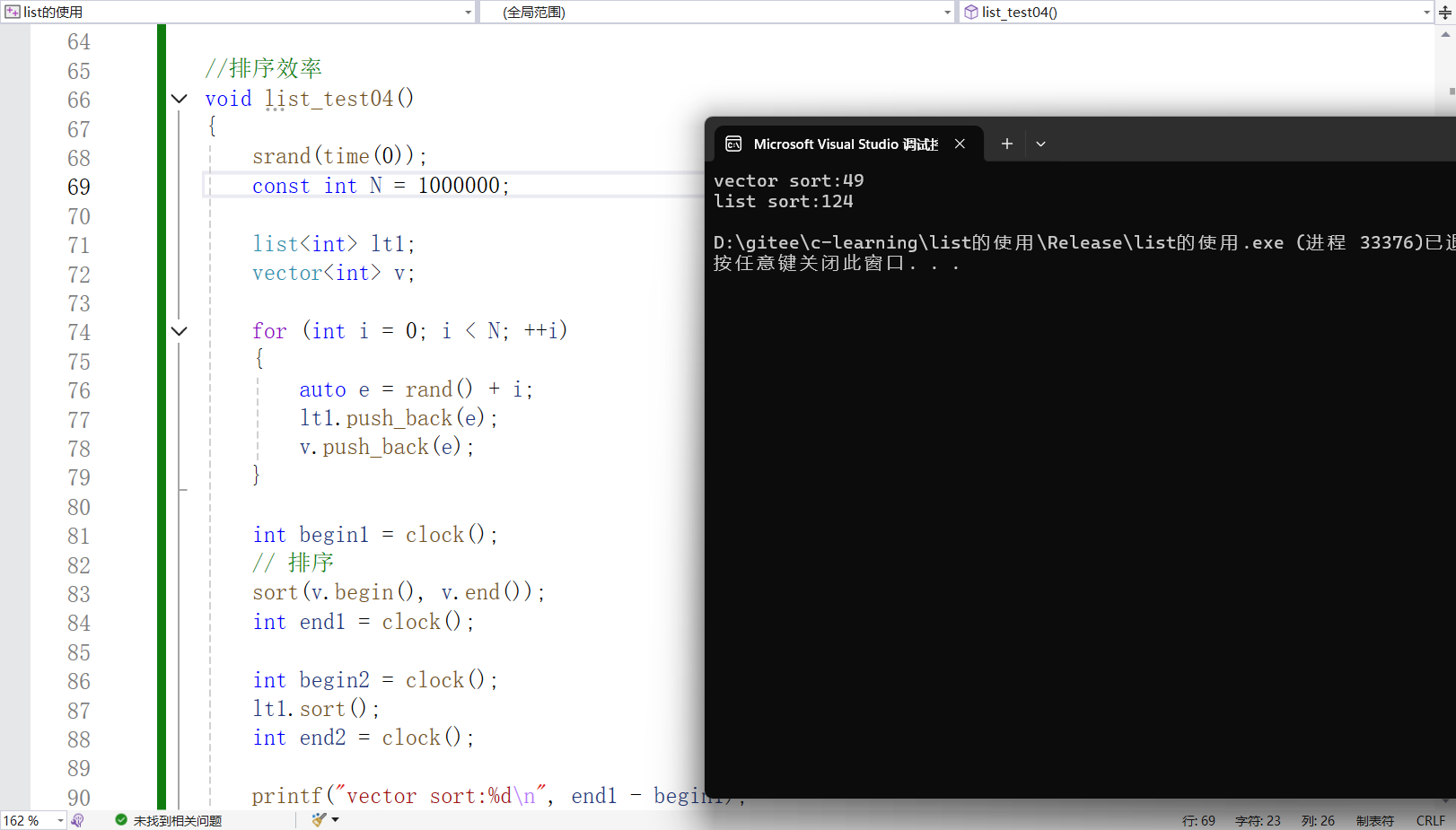
可以看到时间list的性能是比vector差很多的,那相同的时间复杂度为何差异如此之大呢?
4.2缓存读取
主要原因是和内存缓存有关,由于内存的读取性能较差,为了高效读取数据,在内存与cpu间设置了缓存器,缓存器的主要特点是内存小、读取速度快。对于数组这样的连续结构,会一次将多个字节数据储存在缓存器中,那么cpu对于vector数据的读取在缓存器中命中率更高,而list的数据不是连续内存存储,因此命中率会更低。由此导致了list与vector的时间效率不同。