实验设计与分析(第6版,Montgomery著,傅珏生译) 第9章三水平和混合水平析因设计与分式析因设计9.5节思考题9.1 R语言解题
本文是实验设计与分析(第6版,Montgomery著,傅珏生译) 第9章三水平和混合水平析因设计与分式析因设计9.5节思考题9.1 R语言解题。主要涉及方差分析。



YieldDesign <-expand.grid(A = gl(3, 1, labels = c("-", "0","+")),
B = gl(3, 1, labels = c("-", "0","+")) ,
yield = NA)
YieldDesign
YieldDesign$ord <- sample(1:9,9)
YieldDesign[order(YieldDesign$ord),]
ss.data.doe1 <- data.frame(repl = rep(1:4, each = 9),
rbind(YieldDesign[, -7], YieldDesign[, -7]))
> ss.data.doe1
repl A B yield ord
1 1 - - 0 7
2 1 0 - 4 6
3 1 + - 7 3
4 1 - 0 1 4
5 1 0 0 6 1
6 1 + 0 10 8
7 1 - + 2 9
8 1 0 + 9 5
9 1 + + 12 2
10 2 - - 2 7
11 2 0 - 6 6
12 2 + - 10 3
13 2 - 0 3 4
14 2 0 0 8 1
15 2 + 0 10 8
16 2 - + 5 9
17 2 0 + 10 5
18 2 + + 10 2
19 3 - - 5 7
20 3 0 - 7 6
21 3 + - 8 3
22 3 - 0 4 4
23 3 0 0 7 1
24 3 + 0 8 8
25 3 - + 4 9
26 3 0 + 8 5
27 3 + + 9 2
28 4 - - 4 7
29 4 0 - 5 6
30 4 + - 7 3
31 4 - 0 2 4
32 4 0 0 7 1
33 4 + 0 7 8
34 4 - + 6 9
35 4 0 + 5 5
36 4 + + 8 2
ss.data.doe1$yield <- c(0,4,7,1,6,10,2,9,12,2,6,10,3,8,10,5,10,10,5,7,8,4,7,8,4,8,9,4,5,7,2,7,7,6,5,8)
datos <- matrix(ss.data.doe1$yield, ncol=4,dimnames = list(paste("Recipe",1:9), c("Replication 1", "Replication 2", "Replication 3", "Replication 4")))
aggregate(yield ~ A+B,FUN = mean, data = ss.data.doe1)
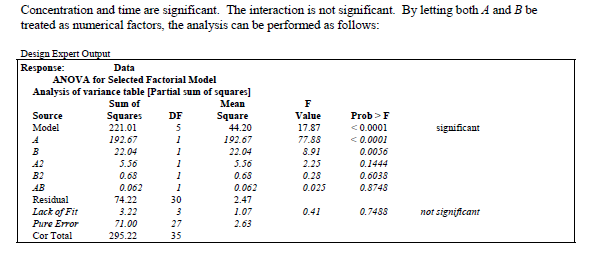
mod<-lm(yield~A*B, data=ss.data.doe1)
summary(mod)
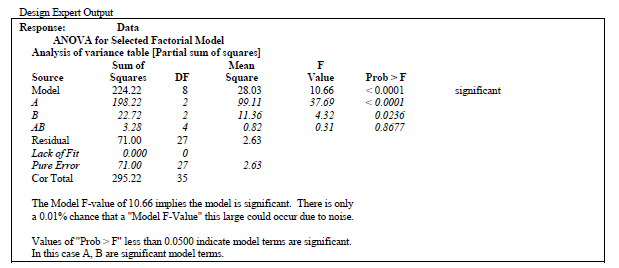
anova(mod)
> anova(mod)
Analysis of Variance Table
Response: yield
Df Sum Sq Mean Sq F value Pr(>F)
A 2 198.222 99.111 37.6901 1.533e-08 ***
B 2 22.722 11.361 4.3204 0.02356 *
A:B 4 3.278 0.819 0.3116 0.86767
Residuals 27 71.000 2.630
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1