一种基于性能建模的HADOOP配置调优策略
1.摘要
作为分布式系统基础架构的Hadoop为应用程序提供了一组稳定可靠的接口。该文作者提出了一种基于集成学习建模的Hadoop配置参数调优的方法。实验结果表明,该性能模型可以准确预测MapReduce应用程序的运行时间。采用提出的Hadoop配置参数方法调优后,平均加速比分别为9.6倍和1.5倍,MapReduce应用的性能得到显着提升。
2.介绍
随着科学技术特别是信息技术的发展,引起了数据的爆炸式增长。大数据处理已经通过Hadoop实现。同时,Hadoop生态系统正在迅速成熟。具体来说,Hadoop是一种分布式系统基础架构,它透明地为应用程序提供一组稳定可靠的接口和运行时环境。在不了解底层实现细节的情况下,用户可以利用集群来开发和运行分布式应用程序。Hadoop中的计算机模型是MapReduce,由于函数式编程的设计思想,MapReduce模型使用map和reduce函数来实现并行计算任务。用户只需要实现map和reduce功能,并行计算涉及到底层系统的复杂细节,包括任务调度、数据通信、容错处理、负载均衡等操作,都由Hadoop框架负责。这种设计方法有效地降低了开发大数据应用的复杂度。但是,它在一定程度上限制了用户对集群资源的有效使用,集群中的应用性能普遍较差。
针对Hadoop配置参数空间巨大、难以进行有效调优的问题,本文提出了一种基于集成学习建模的Hadoop配置参数调优的方法H-Tune,可以显着提高MapReduce应用程序的性能。
MapReduce模型采用“分而治之”的原则,将一个MapReduce应用程序的数据处理过程划分为多个任务,并分配给多个节点并行执行。最后,对所有结果进行汇总,得到最终结果。
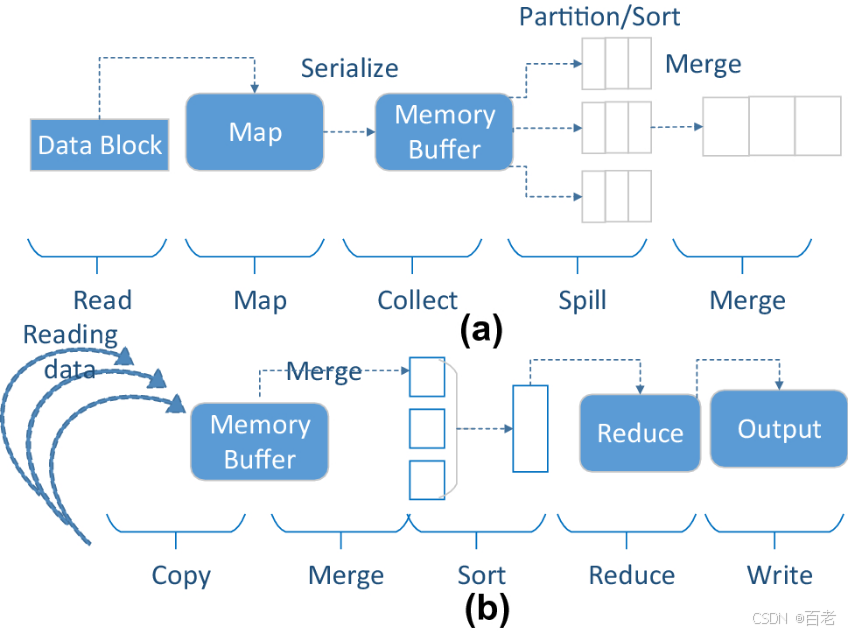
图1:a.Map工作流b.reduce工作流
在Reduce阶段,任务可以分为五个阶段:复制、合并、排序、减少和写入,如图1b所示。每个Reduce任务在多个Map任务的结果中都需要一个对应的文件分区。这些分区文件需要通过网络读取,这个过程称为复制阶段。这些分区文件首先写入内存缓冲区,当内存缓冲区利用率达到阈值时,将缓冲区的内容合并写入磁盘,这个过程称为合并阶段。然后,Reduce阶段使用用户定义的reduce()方法来处理组合数据。Reduce阶段的结果最终写入HDFS。
Hadoop封装了复杂的底层细节,并提供了丰富的配置参数来控制应用程序的底层行为。为了让用户在不了解底层细节的情况下实现精确的参数调优,需要对Hadoop参数与MapReduce应用性能之间的关系进行建模,以发现最优的配置参数组合。
3.基于集成学习建模的MapReduce性能建模
为了便于性能模型的构建和评估,本文首先设计了一套基于MapReduce流程的性能获取工具,该工具具有轻量级、非侵入性的特点,可以深入容器中采集应用程序各个阶段的运行情况。该工具无需修改Hadoop平台或MapReduce应用程序。同时,容器监视器以线程无关的方式运行,具有事件触发机制,只记录指定的性能事件,以尽量减少它们对集群中MapReduce作业的影响。
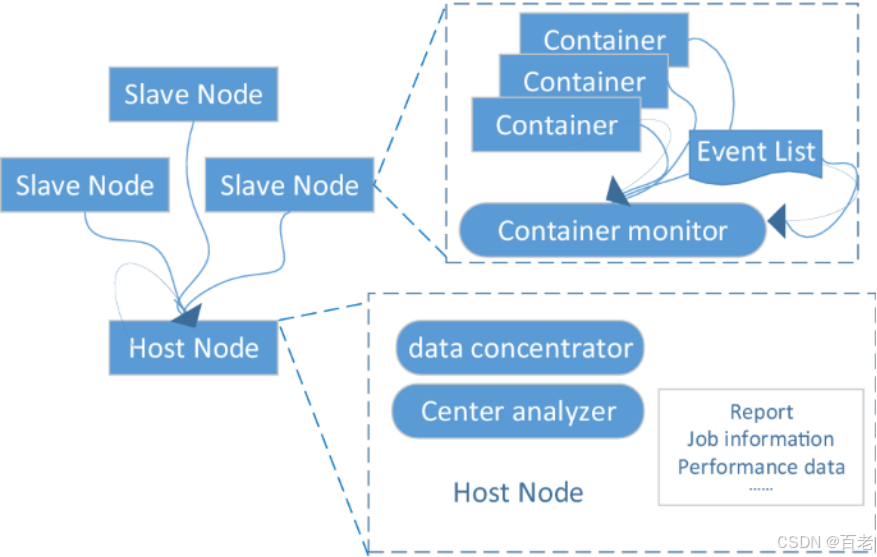
图2性能采集工具的结构
影响MapReduce应用程序性能的主要因素包括特定应用程序、输入数据、集群资源和Hadoop配置。该文重点关注特定应用程序、输入数据、Hadoop配置和MapReduce应用程序性能之间的关系。这是因为集群资源通常在给定集群内是固定的。因此,应用程序的性能可以表征为上述三个变量的函数:
性能=F(应用程序、数据、配置)
梯度提升回归树用于训练这些模型。梯度提升回归树是集成学习中典型的梯度提升算法。其本质是一系列决策树模型。“迭代”主要体现在梯度提升回归树的建立过程中,每个决策树模型的目的都是为了减少之前总模型的残差。一般来说,当前性能模型中损失函数的负梯度值可以作为提升树算法中回归模型的残差逼近(伪残差)。
训练集是通过反复运行MapReduce应用程序获得的,每次运行都使用随机Hadoop配置参数和随机输入数据集。为了避免在训练数据收集阶段花费太多时间,所采用的输入数据集的大小被限制在一定范围内。
4.结论
MapReduce是一种流行的大规模数据处理模型。Hadoop为MapReduce提供了一套稳定可靠的接口和运行环境,使用户能够在不了解底层细节的情况下开发MapReduce应用程序。本文提出了一种有效的Hadoop配置参数调优方法。首先,设计了一个轻量级的性能采集工具,用于采集大量MapReduce作业的运行信息。然后,基于收集到的数据,对MapReduce应用进行性能建模,包括应用底层处理阶段的建模和整体性能的建模。最后,基于性能模型,在优化空间中考虑并探索所有涉及的配置参数,以获得最佳的配置参数组合并部署到集群。
原文信息
[1] Jie, H. A performance modeling-based HADOOP configuration tuning strategy. Nanotechnol. Environ. Eng. (2022). https://doi.org/10.1007/s41204-021-00184-3 译制