机器学习——使用多个决策树
使用单一决策树的弱点之一是决策树对数据中的微小变化非常敏感,一个使算法不那么敏感或更健壮的解决方案,不是建立一个决策树,而是要建立大量的决策树,我们称之为树合奏。
在这个例子中,我们一直在使用最好的特性来分割,在根部结节原来是耳朵形状,分成两个子集,然后在数据的这两个子集上构建进一步的子树,但事实证明,如果你只拿十个例子中的一个换一只猫,所以除了尖尖的耳朵,圆脸和胡须都消失,这只新猫有软软的圆脸胡须,只需改变一个训练示例,最高信息增益功能分裂成为胡须功能代替耳形特征,结果就是,你在左边和右边得到的数据子集,子树变得完全不同,当继续递归地运行决策树学习算法时,在左边和右边构建完全不同的子树,所以,仅仅改变一个训练例子就能导致算法在根节点进行不同的分割,从而得到完全不同的树。也就是说,如果不仅训练单个决策树,而是训练一大堆决策树,会得到更加准确的效果,这就是我们所说的树集成。
如果有三个树集成,每一个都是合理的区分猫和非猫的方法。如果有一个新的测试样本需要分类,你要做的是在这个新样本中运行这三棵树,并让它们对最终预测进行投票。比如,这个测试样本有尖尖的耳朵,不是圆形的脸型,并且有胡须,所以第一棵树会得到这样的推断,推测它是一只猫,第二棵树的推断会沿着这条路径,因此预测它不是一只猫,第三颗树沿着相同的路径,推测它是一只猫。这三棵树的预测不同,所以实际上我们会让它们投票,这三棵树的预测中多数票是猫,所以这些树的最终预测是:这是一只猫。这恰好是正确的预测。
使用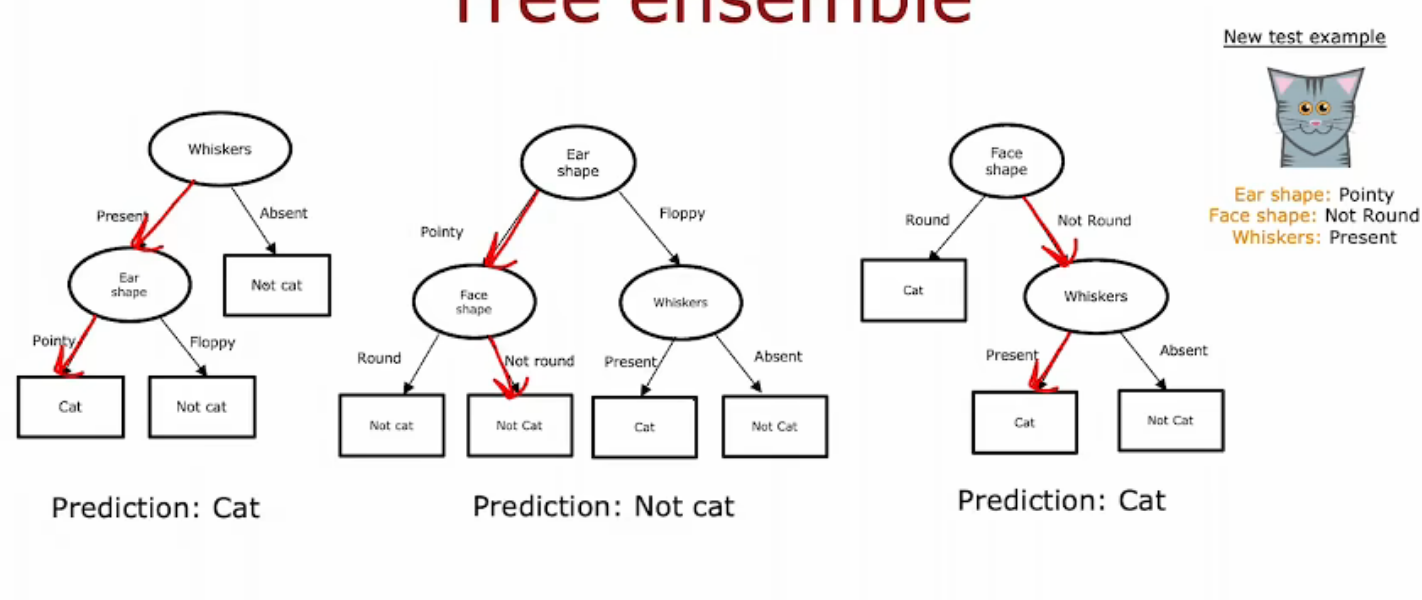
使用树集成的原因是由于拥有大量的决策树,并让它们进行投票,这使得整体算法对任何单棵树的影响变得不那么敏感。